오늘(11.30) 접수 마감인 원티드의 프리온보딩 11월 챌린지를 알게 되어서 급하게 작성하는 사전과제!
조금 어려워 보이지만 사전과제가 공부용으로도 좋아보여서 후다닥 해 보려고 한다.
동기와 비동기 프로그래밍의 차이점
- 동기와 비동기는 프로세스의 수행 순서 보장에 대한 매커니즘이다. 즉 처리해야 하는 작업들을 어떠한 흐름으로 처리할 것이냐에 대한 관점이다.
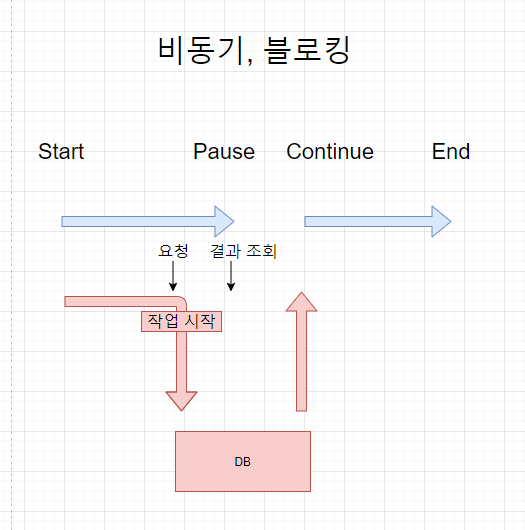
동기(Synchronous)
- 동기는 동시에 일어난다는 뜻이다. 요청과 그 결과가 동시에 일어난다는 약속인데, 요청을 하면 시간이 얼마나 걸리던지 상관없이 요청한 자리에서 결과가 나와야 한다.
비동기(Asynchronous)
- 비동기는 동시에 일어나지 않는다는 뜻이다. 요청한 결과가 요청한 자리에서 꼭 나오지는 않을 것이라는 약속이다.
동기와 비동기 방식의 장단점
동기 방식
장점
- 동기 방식은 이해와 구현이 쉽다. 자바나 C++로 프로그래밍을 처음 배울 때를 생각해보면 된다.
- 코드가 작성된 순서대로 실행되기 때문에 설계 흐름을 이해하기 쉽다.
단점
- 앞서 진행되고 있는 요청에 대한 결과가 나올 때까지 아무것도 못 하고 기다려야 한다. 즉 시간에 대한 비용이 크고 자원을 효율적으로 사용하지 못한다.
비동기 방식
장점
- 동기 방식과 달리 앞서 진행되고 있는 요청에 대한 결과를 기다리지 않고 다음 작업을 수행할 수 있다. 그래서 같은 시간동안 자원을 효율적으로 사용할 수 있다.
단점
- 동기 방식에 비해 이해와 구현이 어렵다. 코드가 작성된 순서대로 실행되지 않기 때문에 설계 흐름을 이해하기 어렵다.
- 대표적인 언어가 자바스크립트이다. 자바스크립트의 비동기 이벤트 방식을 이해하지 못하면 나중에 실행될 줄 알았던 코드가 왜 지금 실행되어 오작동을 하는지 모를 일이 생긴다.
동기와 비동기는 어떤 작업 혹은 연관된 작업을 처리하고자 하는 시각의 차이이지 어느 한 쪽이 절대적으로 좋은 것은 아니다.
때문에 구현해야 하는 프로그램의 목적에 따라 적절한 방식을 선택하면 된다.
블로킹과 논블로킹의 차이점
- 블로킹과 논블로킹은 처리되어야 하는 작업이 전체적인 작업 흐름을 막는 지에 대한 관점이다.
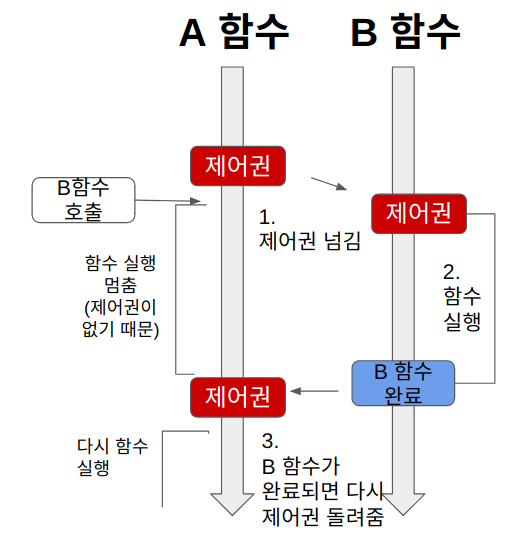
블로킹
- A 메서드가 B 메서드를 호출하면 A가 가지고 있던 제어권을 B에게 넘겨준다.
- 자신의 작업을 진행하다가 다른 주체의 작업이 시작되면 자신의 작업을 멈추고 해당 작업을 기다렸다가 다시 자신의 작업을 시작한다.
- 다른 주체의 작업을 기다리는 동안 아무것도 하지 않으므로 자원이 낭비된다.
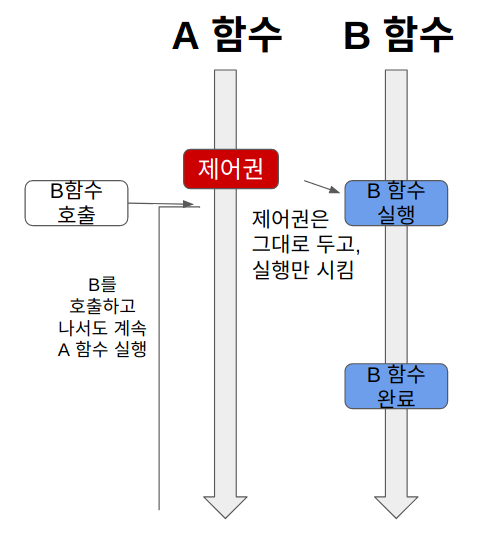
논블로킹
- A 메서드가 B 메서드를 호출해도 A가 가지고 있던 제어권을 B에게 넘기지 않는다.
- 다른 주체의 작업에 관련 없이 자신의 작업을 한다.
- 자원을 효율적으로 사용할 수 있다.
동기와 비동기 & 블로킹과 논블로킹 조합
- 동기와 비동기 & 블로킹과 논블로킹은 개념이 서로 다르기 때문에 서로 조합하는 것이 가능하다.
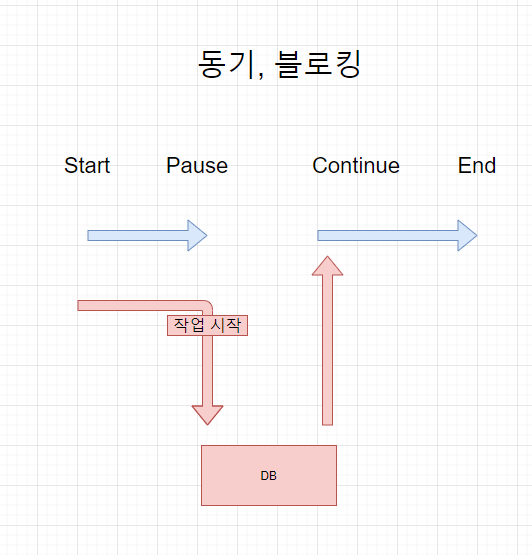
Sync-Blocking
- 함수는 다른 함수의 리턴값을 고려해서 동작한다. (동기)
- 함수는 다른 함수에게 제어권을 넘겨주고 대기한다. (블로킹)
예:
JDBC를 이용해 DB에 쿼리 질의를 날린다
메서드에서 다른 메서드를 호출하여 결과값을 즉시 받아온다
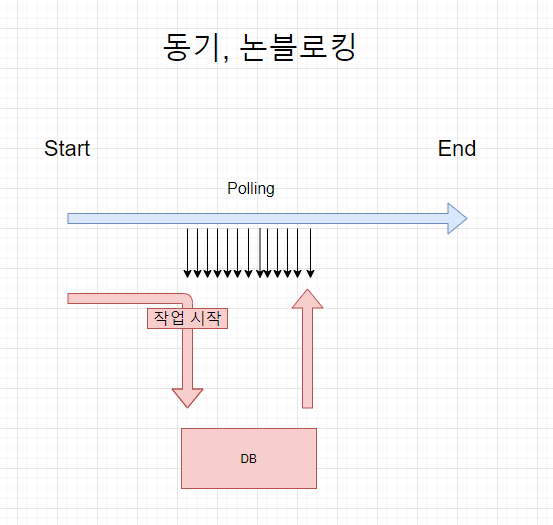
Sync-NonBlocking
- 함수는 다른 함수의 리턴값을 고려해서 동작한다. (동기)
- 함수는 다른 함수에게 제어권을 주지 않고 자신의 코드를 계속 실행한다. (논 블로킹)
- 비동기, 블로킹 조합처럼 작업 효율이 좋지 않은 편이다. 논블로킹으로 자신의 작업을 계속하고 있지만 다른 작업과의 동기를 위해 계속해서 다른 작업이 끝났는지 조회한다.
예:
Polling - 컨텍스트 스위칭이 지속적으로 발생해 지연이 발생한다.
Async-Blocking
- 함수는 다른 함수의 리턴 값을 고려하지 않고 동작한다. (비동기)
- 함수는 다른 함수에게 제어권을 넘겨주고 대기한다. (블로킹)
- 비동기, 블로킹 조합은 결국 다른 작업이 끝날 때를 기다려야 하기 때문에 동기, 블로킹과 비슷한 작업 효율이 나온다. 즉 그리 좋은 효율이 나오지 않는다.
- 개발자가 유도해서 이 상황을 만드는 것보다 비동기, 논블로킹 작업을 실행하였지만 자기도 모르게 블로킹 작업을 실행했을 때 이러한 결과가 나온다.
예:
비동기, 논블로킹 작업을 호출하고 자신의 작업을 하던 도중 호출한 작업의 결과 값을 조회하려고 했을 때(블로킹 메서드 실행)
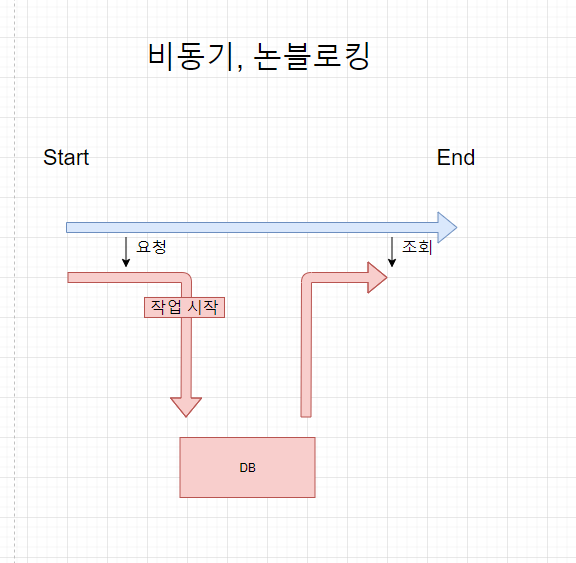
Async-NonBlocking
- 함수는 다른 함수의 리턴 값을 고려하지 않고 동작한다. (비동기)
- 함수는 다른 함수에게 제어권을 주지 않고 자신의 코드를 계속 실행한다. (논 블로킹)
- 함수가 다른 함수를 호출할 때 제어권을 주지 않고 자신의 코드를 계속 실행한다. 함수가 다른 함수를 호출할 때 콜백함수를 함께 줘서 다른 함수는 자신의 작업을 처리하면 콜백 함수를 실행한다.
- 다른 주체에게 작업을 맡겨놓고 자신이 하던 일을 계속할 수 있기 때문에 해야 할 작업이 대규모이고, 동기가 필요하지 않을 때 효과적이다.
예:
AJAX 요청 / JS 비동기 콜백
대규모 사용자에게 푸시메세지 전송
다양한 외부 API를 한번에 호출할 때
자바에서 비동기 프로그래밍을 사용하는 방법
Callback
CompletionHandler를 구현한 방법
- CompletionHandler는 비동기 I/O 작업의 결과를 처리하기 위해 만들어졌으며, 콜백 객체를 만드는 데 사용된다.
- 구현 시 유의사항으로는 다른 스레드와 공유하는 변수 등에 접근할 경우
race condition이 발생할 수 있으므로, 반드시synchronized 블록등의 기법을 통해 자원을동기화해서 사용해야 한다는 것이 있다.
import java.nio.channels.CompletionHandler;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class CallbackExample1 {
private static ExecutorService executorService;
// CompletionHandler를 구현한다.
private static final CompletionHandler<String, Void> completionHandler = new CompletionHandler<>() {
// 작업 1이 성공적으로 종료된 경우 불리는 콜백 (작업 2)
@Override
public void completed(String result, Void attachment) {
log("작업 2 시작 (작업 1의 결과: " + result + ")");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log("작업 2 종료");
}
// 작업 1이 실패했을 경우 불리는 콜백
@Override
public void failed(Throwable exc, Void attachment) {
log("작업 1 실패: " + exc.toString());
}
};
public static void main(String[] args) {
executorService = Executors.newCachedThreadPool();
// 작업 1
executorService.submit(() -> {
log("작업 1 시작");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log("작업 1 종료");
String result = "Alice";
if (result.equals("Alice")) { // 작업 성공
completionHandler.completed(result, null);
} else { // 작업 실패
completionHandler.failed(new IllegalStateException(), null);
}
});
// 별개로 돌아가는 작업 3
log("작업 3 시작");
try {
Thread.sleep(1500);
} catch (InterruptedException e) {
e.printStackTrace();
}
log("작업 3 종료");
}
private static void log(String content) {
System.out.println(Thread.currentThread().getName() + "> " + content);
}
}함수형 인터페이스
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.function.Consumer;
public class CallbackExample2 {
private static ExecutorService executorService;
public static void main(String[] args) {
executorService = Executors.newCachedThreadPool();
// execute 함수의 인자로 callback의 구현체를 넣는다.
execute(parameter -> {
log("작업 2 시작 (작업 1의 결과: " + parameter + ")");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log("작업 2 종료");
});
// 별개로 돌아가는 작업 3
log("작업 3 시작");
try {
Thread.sleep(1500);
} catch (InterruptedException e) {
e.printStackTrace();
}
log("작업 3 종료");
}
public static void execute(Consumer<String> callback) {
executorService.submit(() -> {
log("작업 1 시작");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
String result = "Alice";
log("작업 1 종료");
// 작업을 마친 후 인자로 받아온 callback의 구현체를 비동기로 실행한다.
callback.accept(result);
});
}
private static void log(String content) {
System.out.println(Thread.currentThread().getName() + "> " + content);
}
}함수형 인터페이스 참고
Runnable
인자와 리턴값이 모두 없다.Supplier<R>, Callable<R>
인자는 없고, R 타입의 객체를 리턴한다.Consumer<T>
T 타입의 인자를 받고, 아무것도 리턴하지 않는다.Function<T, R>
T 타입의 인자를 받고, R 타입의 객체를 리턴한다.@FunctionalInterface를 통해 커스텀 함수형 인터페이스를 만들 수도 있다.
Future
Future객체를 사용한 비동기 처리 방식은 다른 주체에게 작업을 맡긴 상태에서 본 주체 쪽에서 작업이 끝났는지 물어보면서 직접 확인하는 방식이다.- 확인하는 방법으로는 2가지가 있다.
1.isDone()이나isCanceled()메소드로 블로킹 없이 작업을 완료했는지의 여부만 확인하는 방법
2.get()으로 작업이 완료될 때까지 블로킹된 상태로 대기하는 방법
* 오래 걸리는 작업을 다른 주체에게 맡겨 두고get()을 호출하기 전까지 이 쪽에서 할 일을 하다가, 작업을 마치면get()을 호출해 작업의 결과를 받아오는 식으로 사용한다.get()메소드를 통해Future 객체에 담긴(담길) 작업 결과를 얻을 수 있다.참고:
Future에 작업을 등록할 때, 등록되는 작업이Runnable인지Callable인지 잘 확인해야 한다.Runnable은 아무것도 리턴하지 않기 때문에get()을 호출했을 때null이 나올 수 있다.
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class FutureExample {
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
// 작업1 Callable이 리턴한 값을 future에 담는다.
Future<String> future = executorService.submit(() -> {
log("작업 1 시작");
Thread.sleep(1000);
log("작업 1 종료");
return "Alice";
});
log("작업 2 시작 (작업 1 종료 대기)");
String result = "";
try {
// 논블로킹으로 작업 1이 종료되었는지 확인한다.
log("작업 1 종료 여부: " + future.isDone());
// 블로킹 상태에서 작업 1이 끝날 때까지 대기한다.
result = future.get();
// 논블로킹으로 작업 1이 종료되었는지 확인한다.
log("작업 1 종료 여부: " + future.isDone());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
log("작업 1의 결과: " + result);
log("작업 2 종료");
}
private static void log(String content) {
System.out.println(Thread.currentThread().getName() + "> " + content);
}
}FutureTask
- Future의 구현체인 FutureTask를 이용해서 구현하는 것도 가능하다.
// FutureTask를 생성한다. 비동기로 수행할 작업을 짜 넣는다.
FutureTask<String> futureTask = new FutureTask<>(() -> {
System.out.println(Thread.currentThread().getName() + "> 작업 1 시작");
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName() + "> 작업 1 종료");
return "Alice";
});
// FutureTask를 수행하는 스레드를 시작한다.
executorService.submit(futureTask);
// 작업 결과는 Future와 같은 방식으로 얻어온다.
futureTask.get();CompletableFuture
Future는 결국 다른 주체의 작업 결과를 얻어오려면 잠시라도 블로킹 상태에 들어갈 수밖에 없기 때문에 사용하는 데 한계가 있다. 그래서 등장한 게CompletableFuture이다.CompletableFuture를 사용하면 이전 작업의 결과를get()을 통해 블로킹으로 가져올 필요 없이,then...()함수를 통해 논블로킹을 유지하며 바로 사용할 수 있다.- 이 방식이 가장 효율적이고 또 익숙한 방식이기도 하다.
import java.util.concurrent.*;
public class FutureExample {
public static void main(String[] args) {
new Thread(() -> {
try {
CompletableFuture
.supplyAsync(FutureExample::work1)
.thenAccept(FutureExample::work2)
.get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}).start();
work3();
}
private static String work1() {
log("작업 1 시작");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log("작업 1 종료");
return "Alice";
}
private static void work2(String result) {
log("작업 1의 결과: " + result);
log("작업 2 시작");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log("작업 2 종료");
}
private static void work3() {
log("작업 3 시작");
try {
Thread.sleep(1500);
} catch (InterruptedException e) {
e.printStackTrace();
}
log("작업 3 종료");
}
private static void log(String content) {
System.out.println(Thread.currentThread().getName() + "> " + content);
}
}메시지 큐
메시지 큐란?
메시지 큐(Message Queue)는 프로세스 또는 프로그램 간에 데이터를 교환할 때 사용하는 통신 방법 중에 하나로,메시지 지향 미들웨어(Message Oriented Middleware:MOM)를 구현한 시스템을 의미한다.메시지 지향 미들웨어 :
비동기 메시지를 사용하는 응용 프로그램들 사이에서 데이터를 송수신하는 것을 의미한다. 여기서 메시지란 요청, 응답, 오류 메시지 혹은 단순한 정보 등의 작은 데이터가 될 수 있다.

- 메시지 큐는 메시지를 임시로 저장하는 간단한 버퍼라고 생각하면 된다. 메시지를 전송 및 수신하기 위해 중간에 메시지 큐를 두는 것이다.
- 메시지 전송 시
생산자(Producer)로 취급되는 컴포넌트가 메시지를 메시지 큐에 추가한다. 해당 메시지는소비자(Consumer)로 취급되는 또 다른 컴포넌트가 메시지를 검색하고 이를 사용해 어떤 작업을 수행할 때까지 메시지 큐에 저장된다. 각 메시지는하나의 소비자에 의해 한 번만 처리될 수 있는데, 이러한 이유로 메시지 큐를 이용하는 방식을일대일 통신이라고 부른다.
메시지 큐를 사용하는 경우
- 대용량 데이터를 처리하기 위한 배치 작업이나, 채팅 서비스, 비동기 데이터를 처리할 때 사용한다.
- 프로세스 단위로 처리하는 웹 요청이나 일반적인 프로그램을 만들어서 사용하는데 사용자가 많아지거나 데이터가 많아지면 요청에 대한 응답을 기다리는 수가 증가하다가 나중에는 대기 시간이 지연되어서 서비스가 정상적으로 되지 못하는 상황이 오기 때문에 기존에 분산되어 있던 데이터 처리를 한 곳에 집중하면서 메세지 브로커를 두어서 필요한 프로그램에 작업을 분산시키는 방법을 하는 것이 그 목적이다.
사용 예 1: 이메일 전송
- 웹사이트에서 이메일을 보낼 때 즉각적으로 전송될 것이라고 기대하는 경우는 드물다. 보통 조금 기다리면 전송될 것이라고 생각하기 때문에 어느 정도의 응답 지연이 허용되며, 어플리케이션의 핵심 기능은 아닌 경우이므로 메시지 큐는 이런 경우 도움이 될 수 있다.
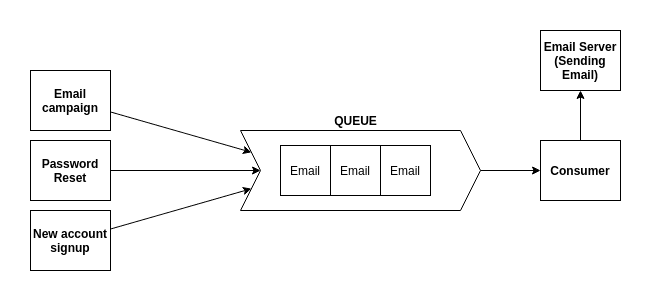
- 비밀번호 재설정을 위해 이메일을 발급하는 서비스, 회원가입을 위해 이메일을 발급하는 서비스 등은 메시지(이메일)를 큐에 넣을 수 있다.
- 이메일 전송 전용 서비스는 이메일이 어느 서비스로부터 생산되었는지와는 관계없이, 메시지 큐의 메시지를 하나씩 소비하고, 그저 이메일이 전송되어야 할 곳으로 이메일을 전송한다.
- 이와 같은 접근 방식은 메시지 큐에 들어오는 메시지 수가 너무 많아지는 경우 이메일 전송 전용 서비스 인스턴스를 더 둠으로써 확장할 수 있으므로 확장성이 뛰어나다.
사용 예 2: 블로그 포스팅
- 블로그 사용자가 게시글에 업로드한 이미지의 용량이 매우 큰 경우를 생각해보자.
- 블로그 서비스의 응답 시간을 저해하지 않으면서 사용자들에게 유연성을 제공하는 방법으로, 사용자가 업로드한 모든 이미지를 게시 과정에서 즉각 처리하는 것이 아닌, 사후처리하며 최적화하는 방법이 있다. 사용자 경험에 약간의 영향을 미칠 수는 있지만, 최적화는 응용 프로그램에서 가장 중요한 것은 아니며 작업을 즉시 수행할 필요도 없다. 메시지 큐는 이러한 상황에서도 사용될 수 있다.
- 사용자가 고용량의 이미지가 포함된 블로그 포스팅을 한다.
이미지는 저장소에 전송된다. - 업로드된 이미지에 대한 정보가 포함된 메시지를 이미지 최적화 서비스의 메시지 큐에 담는다.
- 이미지 최적화 서비스는 저장소에서 이미지를 가져와 최적화하고, 2번에서 저장해놨던 이미지를 대체한다.
- 사용자가 고용량의 이미지가 포함된 블로그 포스팅을 한다.
메시지 큐를 사용하는 이유
비동기(Asynchronous)
- 메시지 큐는 생산된 메시지의 저장, 전송에 대해 동기화 처리를 진행하지 않고, 큐에 넣어 두기 때문에 나중에 처리할 수 있다. 여기서, 기존 동기화 방식은 많은 메시지(데이터)가 전송될 경우 병목이 생길 수 있고, 뒤에 들어오는 요청에 대한 응답이 지연될 것이다.
낮은 결합도(Decoupling)
- 생산자 서비스와 소비자 서비스가 독립적으로 행동하게 됨으로써 서비스 간 결합도가 낮아진다.
확장성(Scalable)
- 다수의 프로세스들이 큐에 메시지를 보낼 수 있다.
- 생산자 서비스 혹은 소비자 서비스를 원하는 대로 확장할 수 있기 때문에 확장성이 좋다.
탄력성(Resilience)
- 일부가 실패해도 전체가 그 영향을 받지 않는다.
- 소비자 서비스가 다운되더라도 어플리케이션이 중단되는 것은 아니다. 메시지는 메시지 큐에 남아 있다. 소비자 서비스가 다시 시작될 때마다 추가 설정이나 작업을 수행하지 않고도 메시지 처리를 시작할 수 있다.
보장성(Guarantees)
- 작업이 처리된걸 확인할 수 있다.
- 메시지 큐는 큐에 보관되는 모든 메시지가 결국 소비자 서비스에게 전달된다는 일반적인 보장을 제공한다.
과잉(Redundancy)
- 실패할 경우 재실행이 가능하다.
여기서 얻을 수 있는 결론은 서버가 사용자에게 얼마나 빠르고 안정적으로 정보를 전달할 수 있는 지에 초점을 맞춘 기술이라고 볼 수 있다.
메시지 큐 종류
ActiveMQ(JMS)
- MOM을 자바에서 지원하는 표준 API이다.
- JMS는 다른 자바 애플리케이션들끼리 통신이 가능하지만 다른 MOM의 통신은 불가능하다.
- (AMQP, SMTP 같은) ActiveMQ의 JMS 라이브러리를 사용한 자바 애플리케이션들끼리 통신이 가능 하지만 다른 자바 애플리케이션(Non ActiveMQ)의 JMS와는 통신할 수 없다.
RabbitMQ
- AMQP(Advanced Message Queuing Protocol)를 구현한 오픈소스 메시지 브로커이다.
- AMQP는 MQ를 오픈 소스에 기반한 표준 프로토콜이다. 프로토콜만 맞다면 다른 AMQP를 사용한 애플리케이션끼리 통신이 가능하고 플러그인을 통해서 SMTP, STOMP 프로토콜과의 확장이 가능하다.
Kafka
- Apache Kafka는 LinkedIn이 개발하고 Apache Software Foundation에 기부한 오픈 소스 스트림 프로세싱 소프트웨어 플랫폼이다.
- 높은 처리량을 요구하는 실시간 데이터 피드 처리나 대기 시간이 짧은 플랫폼을 제공하는 것을 목표로 하며 TCP 기반 프로토콜을 사용한다.
- 클러스터를 중심으로 Producer와 Consumer가 데이터를 Push하고 Pull하는 구조를 가진다.
참고
