
DB 엔진 용어
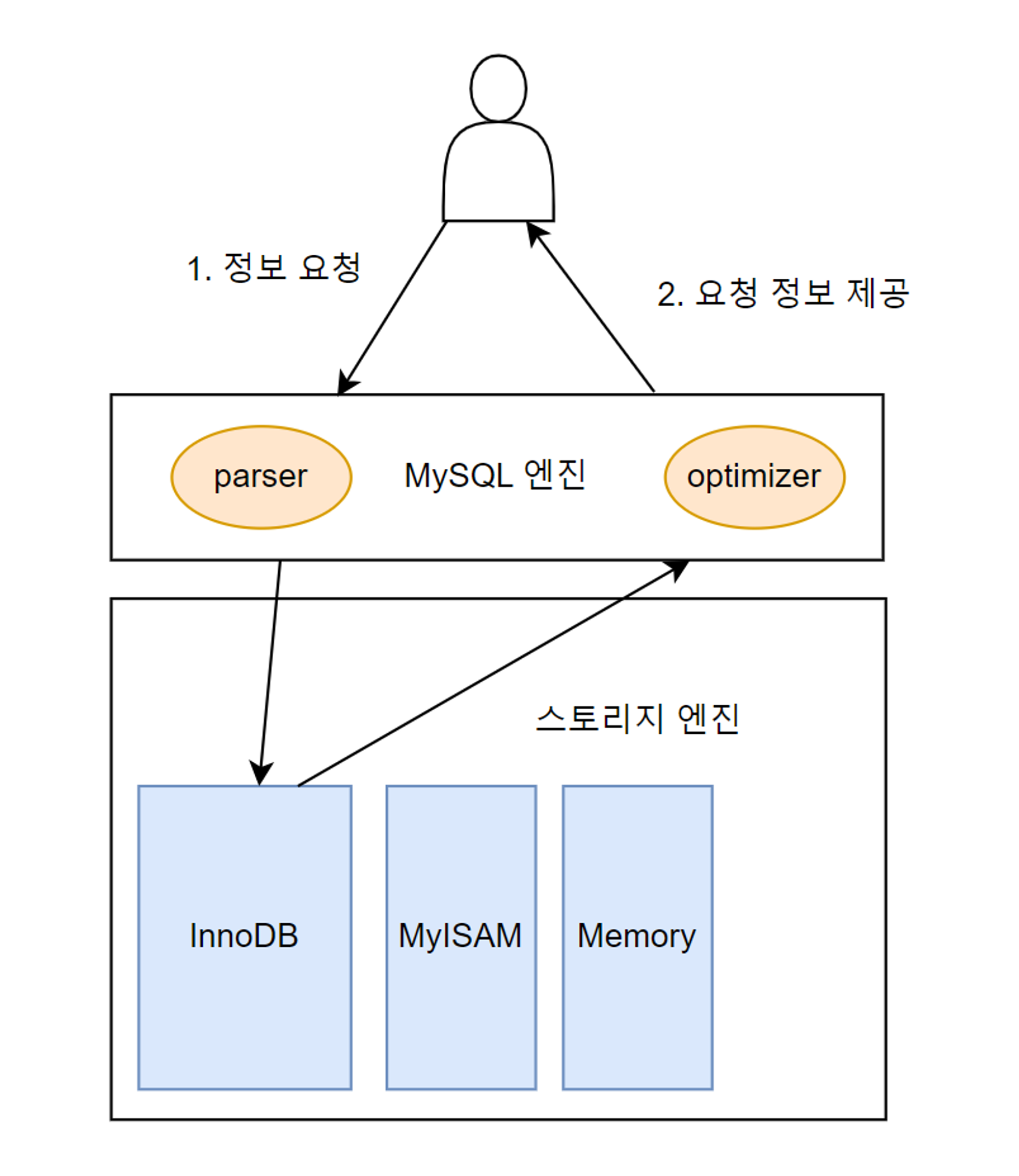
사용자는 DB에서 원하는 데이터를 가져오고자 SQL문을 실행한다. 실행된 SQL문은 MySQL 엔진에서 문법 에러 여부, DB에 존재하는 테이블 대상으로 SQL문을 작성했는지와 같은 세부 사항들을 다양한 문법 및 구문으로 검사한다(parser가 수행). 이후 사용자가 요청한 데이터를 빠르고 효율적으로 찾아가는 전략적 계획을 수립한다(optimizer 가 수행). 이 계획을 토대로 스토리지 엔진에 위치한 데이터까지 도달한 뒤 해당 데이터를 MySQL 엔진으로 전달한다. MySQL 엔진은 전달된 데이터에서 불필요한 부분을 필터링(제거, 변경)하고 필요한 연산을 수행한 뒤 사용자에게 최종 결과를 알려준다.
스토리지 엔진
스토리지 엔진(InnoDB, MyISAM 등)은 사용자가 요청한 SQL문을 토대로 DB에 저장된 디스크나 메모리에서 필요한 데이터를 가져오는 역할을 수행한다.
일반적으로 온라인상의 트랜잭션 발생으로 데이터를 처리하는 OLTP(online transaction processing) 환경이 대다수인 만큼 주로 InnoDB 엔진을 사용한다. 그 밖에도 대량의 쓰기 트랜잭션이 발생하면 MyISAM 엔진을, 메모리 데이터를 로드하여 빠르게 읽는 효과를 내려면 Memory 엔진을 사용하는 식으로 응용하여 스토리지 엔진을 선택할 수 있다. 다음 명령을 통해 MySQL, MariaDB 10.5에서 기본 제공하는 스토리지 엔진 목록을 확인할 수 있다.
SELECT ENGINE, TRANSACTIONS, COMMENT
FROM information_Schema.engines;MySQL 엔진
MySQL 엔진은 사용자가 요청한 SQL문을 넘겨받은 뒤 SQL 문법 검사와 적절한 오브젝트 활용 검사를 하고, SQL 문을 최소 단위로 분리하여 원하는 데이터를 빠르게 찾는 경로를 모색하는 역할을 수행한다. 이후 스토리지 엔진으로부터 전달받은 데이터를 대상으로 가공 및 연산 작업을 수행한다.
SQL 프로세스 용어
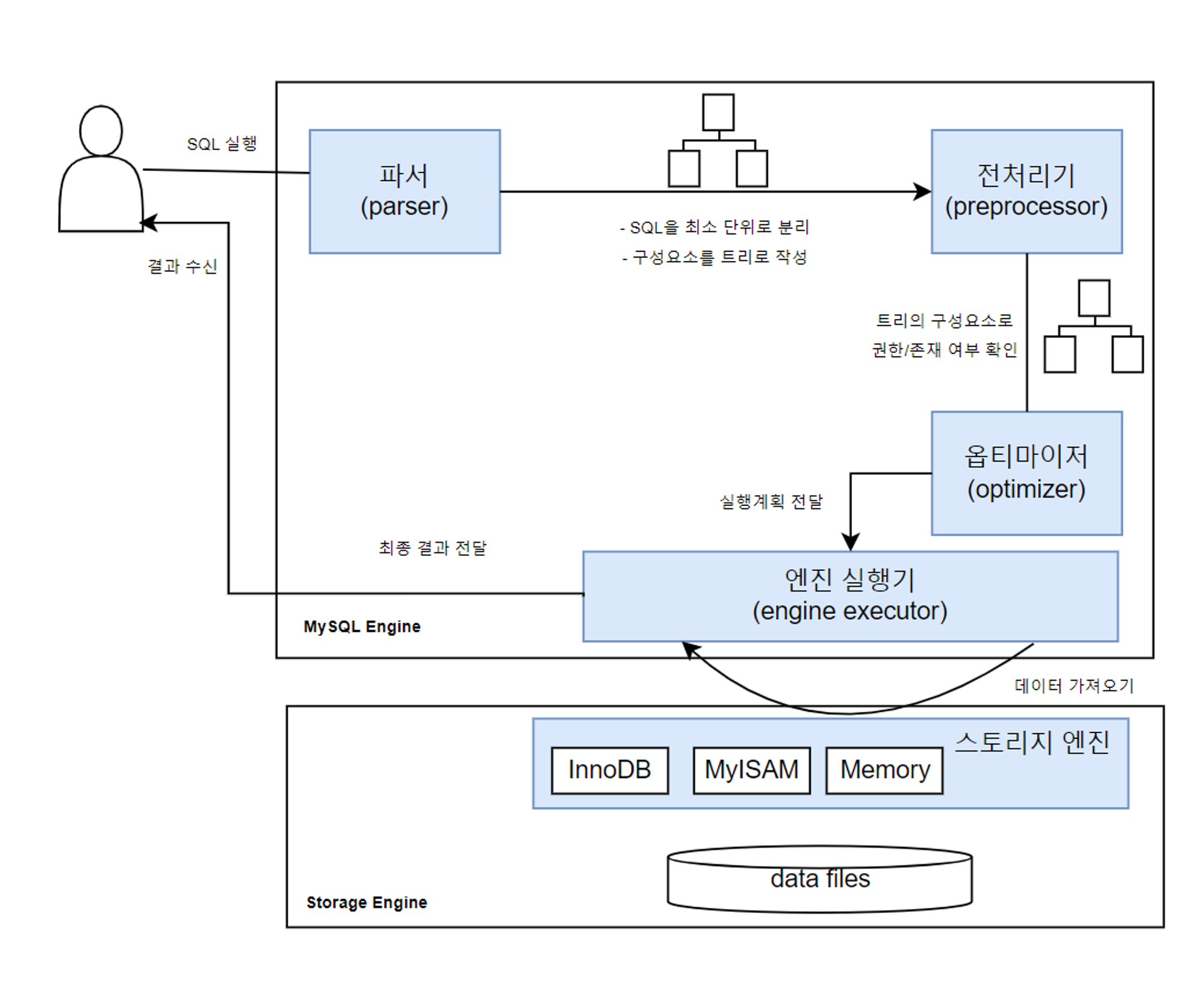
- 사용자가 SQL문을 수행하면, 파서는 MySQL이 이해할 수 있는 최소 단위로 구성요소를 분리하고 해당 구성요소를 트리로 만든다. 트리를 만드는 과정에서 문법 오류가 있는지 검토한다. 최소 단위는 <,> 등의 기호나 SQL 키워드로 분리한다. 문법 에러시 실행이 종료된다.
- 전처리기는 존재하지 않는 열 포함 여부, 조회 권한 여부 등의 유효성을 검증한다.
- 옵티마이저는 최소 시간, 효율적인 비용의 경로로 데이터를 검색하는 실행 계획을 수립한다.
- 엔진 실행기는 계획을 토대로 스토리지 엔진을 호출해 데이터를 가져온다. 이후 데이터를 가공하여 사용자가 원하는 결과를 전달한다.
파서
파서는 MySQL 엔진에 포함되는 오브젝트로, SQL문을 최소 단위로 분리하고 트리를 만든다. 문법 검사도 수행한다.
전처리기
MySQL 엔진에 포함되는 오브젝트로, 파서에서 생성한 트리를 토대로 SQL문의 구조적 문제를 파악한다.
옵티마이저
- 전달된 파서 트리를 토대로 필요하지 않은 조건 제거, 연산 과정 단순화
- 테이블 접근 순서, 인덱스 사용 여부, 사용 인덱스 선택, 정렬시 인덱스/임시 테이블 중 사용 결정과 같은 실행 계획 수립
실행 계획 수립은 시간과 하드웨어 리소스를 점유하므로, 해당 요소들에 제한을 두어야 한다. 한편, 옵티마이저의 계획이 항상 최상의 계획이 아니므로 사용자의 관여가 필요할 수 있다.
엔진 실행기
MySQL 엔진과 스토리지 엔진 영역 모두에 걸치는 오브젝트로, 옵티마이저에서 수립한 실행 계획을 참고하여 스토리지 엔진에서 데이터를 가져온다. 데이터 가공(필터링 등) 작업 역시 수행한다. MySQL 엔진의 부하를 줄이려면 스토리지 엔진에서 가져오는 데이터양을 줄이는 게 중요하다.
DB 오브젝트 용어
오브젝트는 데이터베이스를 구성하는 요소(객체)들을 의미한다.
테이블
데이터를 저장하는 오브젝트로 행과 열의 정보를 담는다. 테이블에서는 저장 방식과 구조에 따라 스토리지 엔진을 정의할 수 있다.
로우
테이블에서 동일 구조의 데이터 항목들의 집합을 가리킨다. 모든 행의 집합을 하나의 테이블이라고 할 수 있다. 행 수가 많아지면 파티셔닝 기법으로 성능 향상을 도모할 수 있다.
기본 키
특정 행을 대표하는 열을 가리키는 용어로, 다른 행과 중복되지 않는 값을 가진다. MySQL/MariaDB에서 기본 키는 클러스터형 인덱스로 작동한다. 이는 기본 키의 구성 열 순서를 기준으로 물리적 스토리지에 데이터가 쌓인다는 뜻이다. 즉, 비슷한 기본 키 값들이 근거리에 적재되므로 기본 키를 활용하여 인덱스 스캔을 수행하면 테이블 데이터를 더 빠르게 접근할 수 있다.
인덱스 주의사항
기본키와 똑같은 인덱스를 생성하면 인덱스가 저장되는 물리적 공간이 낭비되고 데이터의 CUD에 따른 인덱스 정렬의 오버헤드가 발생한다.
CREATE TABLE student (
id INT(11) NOT NULL,
name VARCHAR(14) NOT NULL,
birth DATE NOT NULL,
phone_number VARCHAR(16) NOT NULL,
major_code VARCHAR(3) NOT NULL,
PRIMARY KEY (id),
INDEX_I_id (id)
)위 예제에서 기본 키와 I_id 인덱스를 똑같은 id 열로 생성하고 있다. 이런 인덱스는 불필요한 공간 낭비와 정렬 오버헤드가 발생하므로 삭제해야 한다.
외래 키
외부에 있는 테이블을 항상 참조하며, 외부 테이블의 데이터가 변경되면 함께 영향을 받는 관계를 설정하는 키이다.
인덱스
인덱스는 DB에서 키값으로 실제 데이터 위치를 식별하고 데이터 접근 속도를 높이고자 생성되는, 키 기준으로 정렬된 오브젝트이다. 저장된 데이터를 검색할 일이 많을 때 인덱스를 설계하고 생성하는 일은 중요하다. 인덱스를 생성하려는 열의 속성에 따라 고유/비고유 인덱스로 나눌 수 있으며 흔히 거론되는 인덱스는 비고유 인덱스이다.
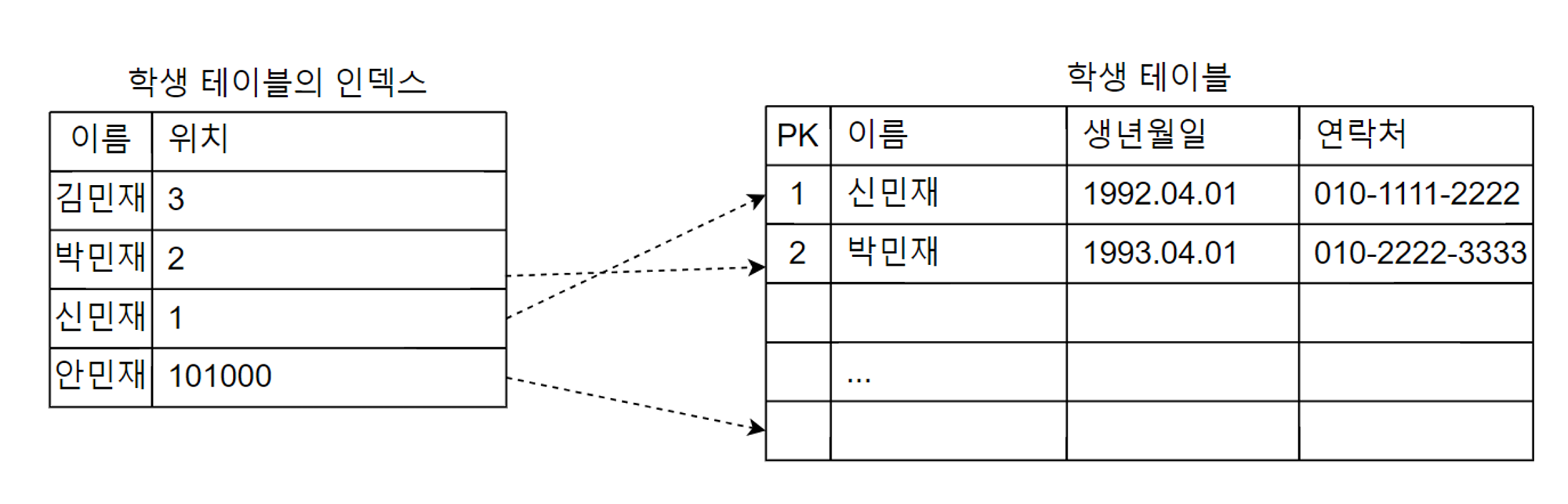
고유 인덱스
고유 인덱스란 인덱스를 구성하는 열들의 데이터가 유일하다는 의미이다. 차례로 정렬되는 인덱스 열의 데이터는 서로 중복되지 않고 유일성을 유지한다. 중복이 없는 열들을 고유 인덱스로 생성하려 한다면 불필요한 중복 검증 과정이 추가되니 주의해야 한다.
ALTER TABLE student
ADD UNIQUE INDEX phone_number_index (phone_number);기본 키와 고유 인덱스의 차이점
두 개념이 유사하여 혼란스러울 수 있다. 기본 키에는 NULL을 입력할 수 없지만 고유 인덱스는 가능하다.
비고유 인덱스
고유 인덱스에서 데이터 유일 속성만 제외한 키이다. 데이터가 신규 입력되어 인덱스가 재정렬되더라도 인덱스 열의 중복 체크를 거치지 않고 단순 정렬 작업을 수행한다.
ALTER TABLE student
ADD INDEX name_index (name);뷰
뷰는 가상의 테이블로 이해할 수 있다. 테이블의 일정 부분을 뷰로 만들어 조회할 수 있게 설정 가능하다. 원본 테이블의 데이터가 변경되면 뷰에서도 바로 변경된 데이터를 조회할 수 있다. 이를 통해 보안성을 강화할 수 있다. 한편, 여러 테이블을 병합해서 활용할 때도 성능을 고려한 최적의 뷰를 생성해 일관된 성능을 제공할 수 있다.
CREATE VIEW v_student AS
SELECT id, name
FROM student;참고
