🟨 SQL 소개
📍 SQL과 RDB는 무엇인가
- SQL 학습 목적
- RDBMS/SQL 개요
SQL 학습 목적
우리는 지금 데이터로 다양한 data product를 만드는 방법에 대해 배우고 있음. data product란 데이터 분석 레포트일수도, 특정한 기능을 수행하는 머신러닝 모델일수도 있음.
즉, 데이터 분석가와 데이터 과학자가 데이터로 만들어내는 다양한 산출물을 포괄하는 명칭임.
data product를 만들기 위한 첫 단계는 데이터베이스에서 데이터를 가져오는 것. 데이터 베이스에서 원하는 데이터를 골라서 가져올 때 SQL을 주로 사용함. 데이터 베이스에서 데이터를 가져오는데 초점을 두고 배우지만 데이터를 쌓고 수정하고 삭제하는 등 데이터 베이스를 관리하는데에도 SQL을 사용할 수 있음.
SQL 학습 목적 3가지
1) 원하는 형태로 데이터를 가져올 수 있음
- ex) 팀 별 교육시간 평균을 구하고 싶을 때
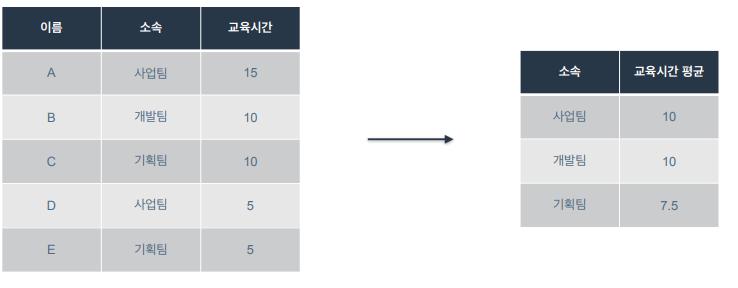
2) 효율적으로 데이터를 가져올 수 있음
- ex) 기획팀의 교육시간 합계를 구하고 싶을 때
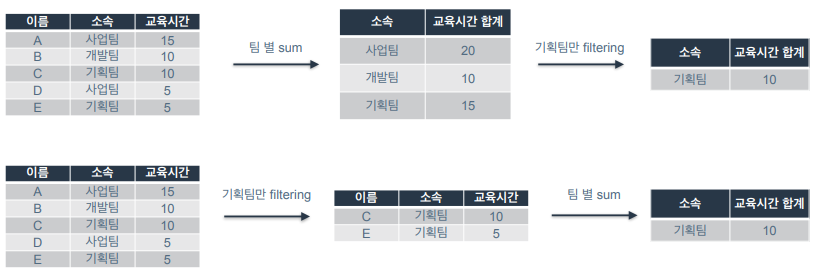
- 두 가지 방법이 존재 ➡️ 팀별로 교육시간 합계를 구한 뒤 기획팀 필터링하기/기획팀만 필터링 한 뒤 교육시간 더하기
- 후자가 더 효율적이며 인프라 비용 더 아낄 수 있음. 데이터 크기가 커질수록 쿼리 비용에서 차이가 커짐.
3) 간단한 데이터 분석을 수행할 수 있음
- ex) 팀 별 교육시간의 기초통계량 추출
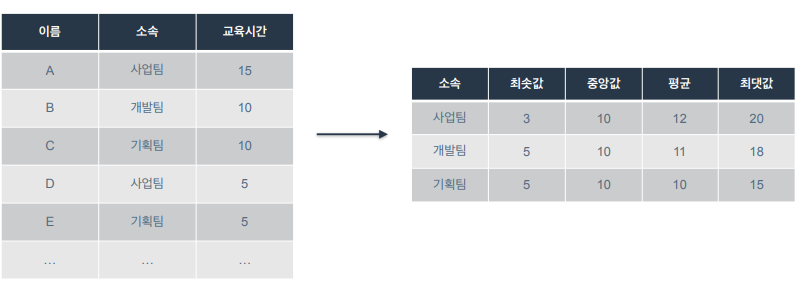
RDBM/SQL 개요
-
데이터 베이스는 데이터를 쌓고 관리하는 방식에 따라 크게 두가지로 나눌 수 있음
1) 관계형 데이터베이스(Relational DB, RDBMS)
-
가장 일반적으로 쓰이는 데이터베이스
-
데이터를 표 형태로 쌓음
-
예시) MySQL, ORCLE, PostgreSQL, MSSQL 등
2) 비-관계형 데이터베이스(Not Only SQL, NoSQL)
-
관계형 데이터베이스와 반대되는 개념(관계형 데이터베이스에 반발하는 이름으로 NoSQL이라는 이름이 붙음)
-
NoSQL의 하위 개념으로 Key-value Score, Document DB, Graph DB, Column-family 등 다양한 형태의 데이터베이스가 존재
-
표 형태가 아니라 예시처럼 기준이 되는 key에 따라 접근할 수 있는 형태

-
예시) MongoDB, cassandra DB 등
-
RDBMS와 NoSQL 비교
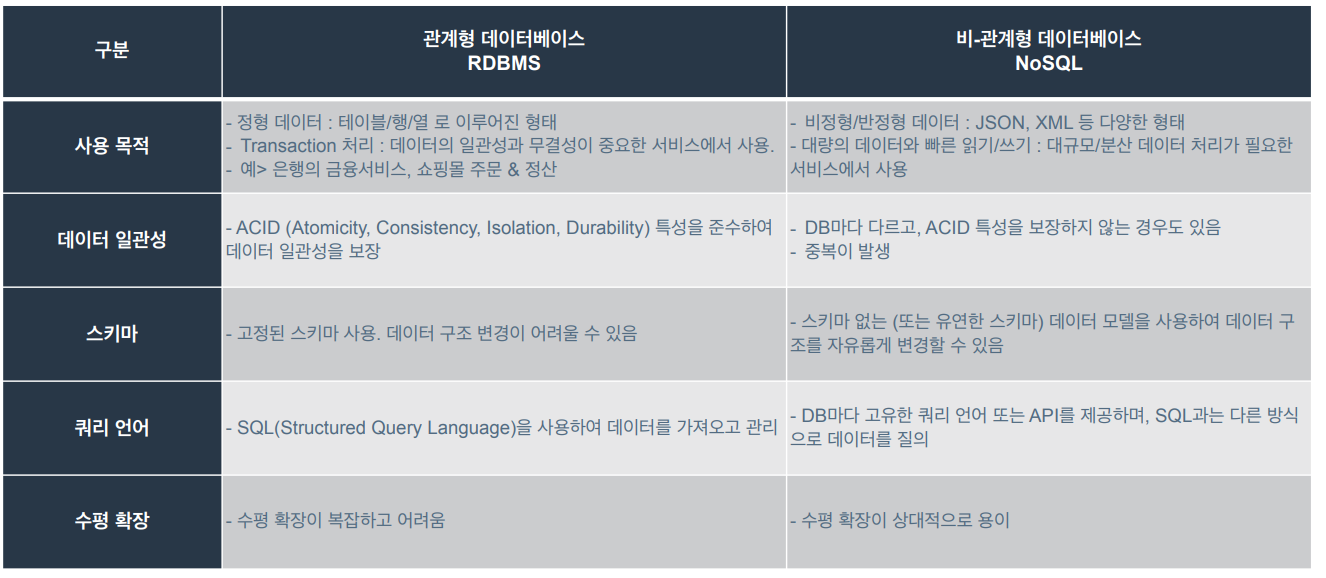
-
transaction은 데이터베이스 상태를 변화시키는 논리적 실행 단위라고 생각하면 됨. 데이터를 수정하거나 삭제하는 등의 상태 변환이 있을 수 있음.
ex) 은행 데이터베이스를 생각하면, 계좌이체가 발생하면 돈을 보낸 사람은 그 금액만큼 빼줘야하고 받은 사람은 그만큼 돈을 더해줘야함. 이 2개의 작업이 하나의 transaction안에서 이루어짐.
-
데이터 일관성은 데이터베이스에서 transaction이 안전하게 수행된다는걸 보장하기 위한 성질을 의미하고 구성요소 앞글자만 따서 ACID라고 부름.
-
스키마는 데이터베이스 내에서 데이터가 어떤 구조로 저장되어 있는지를 의미
ex) 테이블 스키마는 테이블이 어떤 컬럼으로 구성되고 각 컬럼의 타입은 무엇인지 의미
-
수평확장은 데이터베이스에 데이터가 감당할 수 없을정도로 많아졌을 때, 데이터베이스를 여러 개로 늘려서 문제를 해결하는 방식
NoSQL은 데이터가 중복으로 저장되는 경우가 존재하고 이런 경우 수평확장이 상대적으로 용이함.
SQL
-
SQL(Structured Query Language) : 관계형 데이터베이스를 사용하기 위한 표준언어
-
테이블은 행과 열로 이루어진 하나의 2차원 표를 의미
테이블끼리 공통되는 키를 갖고있다면 결합도 가능
🟨 SQL 기초 구문
📍 데이터 조회: SELECT, FROM, WHERE
실습환경
SQL 서버를 직접 띄우는 방법도 있지만, 처음 사용하면 복잡할 수도 있음. 따라서 웹에서 코드 실습을 할 수 있는 환경을 소개
강사님께서는 https://sqlfiddle.com/ 소개해주셨음.
그러나, 2023년 말에 웹페이지 구성이나 진행 방식이 완전히 바뀐 탓에 현재 비슷한 기능을 가지고 있는 유사 서비스 이용
https://www.db-fiddle.com/
https://www.jdoodle.com/execute-sql-online/
https://sqliteonline.com/
데이터 조회
-
쿼리를 RDBMS에 날리면 결과를 얻을 수 있음.
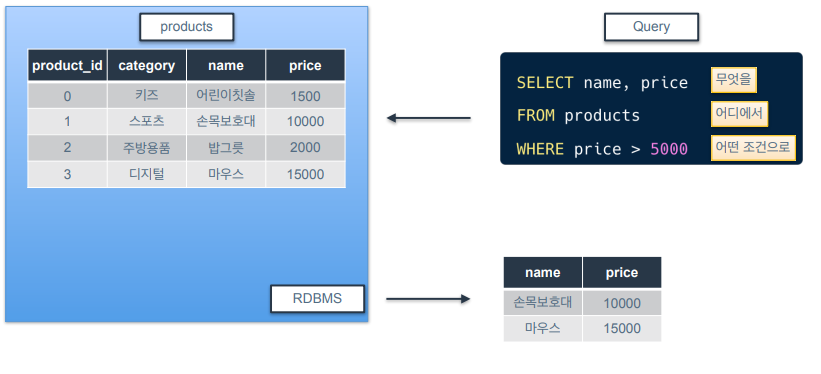
-
쿼리에서 기본 뼈대가 되는 표현 3가지 ➡️ SELECT, FROM, WHERE
1) SELECT - 무엇을 가져올지 지정하는 표현
2) FROM - 어디에서 가져올지 지정하는 표현
3) WHERE - 어떤 조건으로 가져올지 지정하는 표현
SELECT는 열을 선택하기 위한 목적이라면 WHERE은 행을 선택하기 위한 목적
-
간단한 쿼리 작성 예시
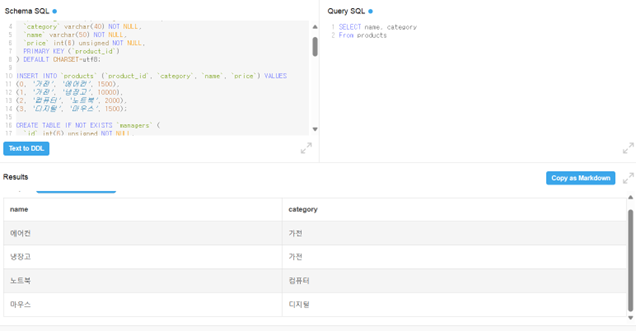
- products 테이블에서 name, category를 가져오는데 name, category 순서로 가져왔으니 결과도 해당 순서로 나옴.
데이터 조회 - SELECT
- 모든 컬럼을 가져오고 싶다면 SELECT * (그러나 테이블이 크면 불필요한 리소스 사용할 수도 있음)
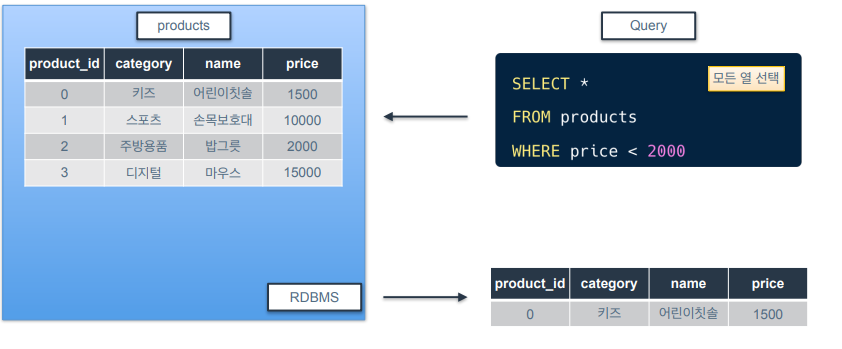
데이터 조회 - WHERE
-
WHERE은 다음에 오는 조건을 만족하는 행만 반환.
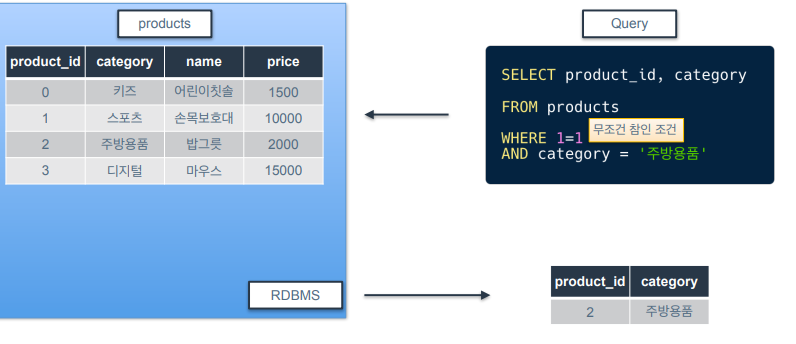
-
1=1 조건은 항상 참이여서 영향을 주지 못함.
그러나, 왜 사용하는건지?
➡️ WHERE에 여러 조건이 있을 때 조건들을 편하게 삭제,추가하기 위해서 1=1같이 무조건 참인 조건을 넣어둠
(실습) 1=1 조건 쓰는 이유 예시
SELECT product_id, category
FROM products
WHERE 1=1
AND category = '주방용품'
AND price > 5000여기서 1=1 조건을 없애면 아래와 같은 코드가 됨.
SELECT product_id, category
FROM products
WHERE category = '주방용품'
AND price > 5000여기서 조건 하나를 없애고 싶다면 아래 코드처럼 해줘야하는데 번거로움.
SELECT product_id, category
FROM products
WHERE price > 50001=1 을 사용하는 경우라면, 사용하지 않는 조건을 주석처리만 해주면 됨.
데이터 조회 - FROM
-
FROM은 어디에서를 나타내는 키워드.
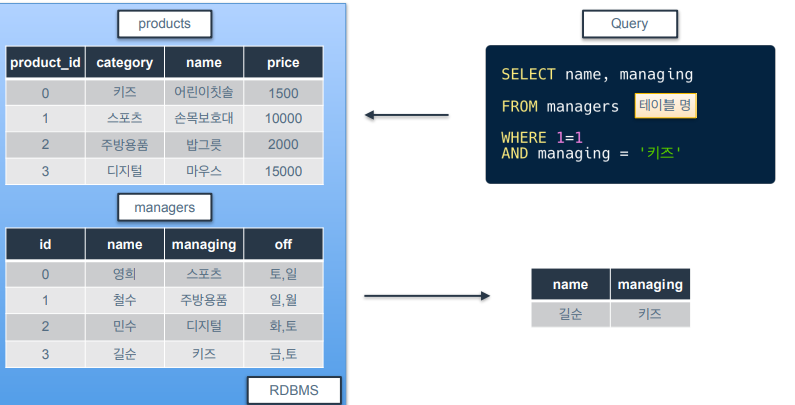
- managers 테이블에서 name, managing 컬럼 가져오고, managing컬럼값이 '키즈'인 경우만 가져옴.
데이터 조회 - LIMIT
-
결과물을 몇개까지 반환할지 개수를 제한하는 키워드
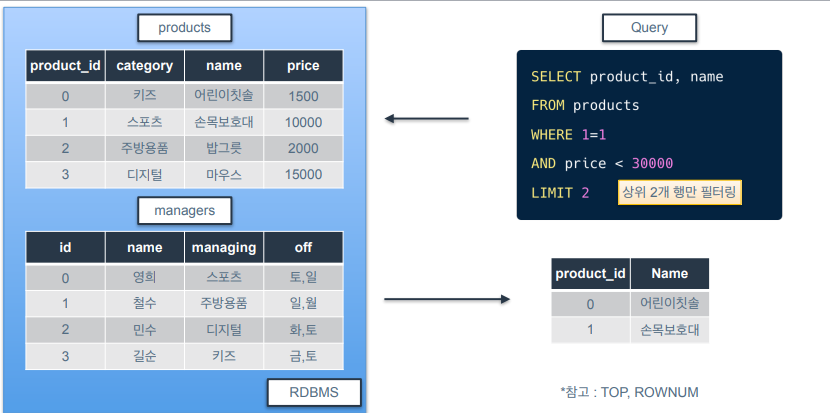
- MySQL에서는 LIMIT이고 msSQL에서는 TOP, ORACLE에서는 ROWNUM을 사용
📍 비교 연산자와 논리 연산자
비교 연산자는 왼쪽과 오른쪽의 값을 비교하는데 쓰임
비교 연산자 : =
-
catogory가 '주방용품'인거만 필터링
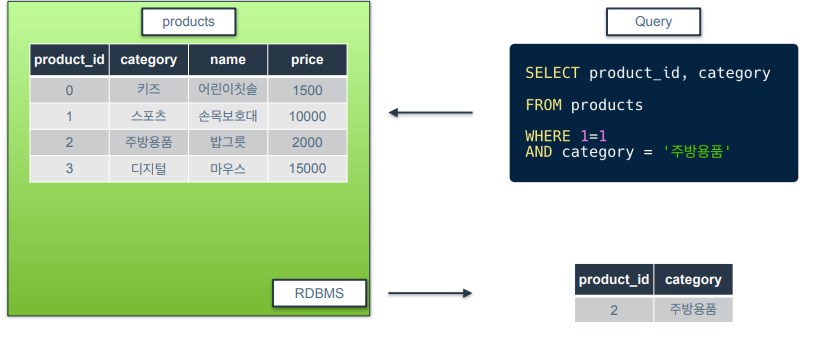
-
(실습) price가 2000인거만 필터링
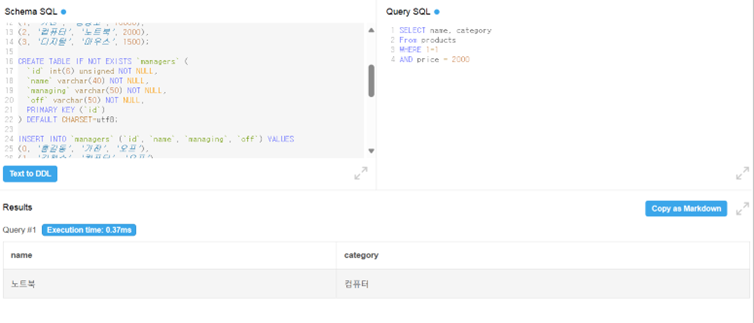
비교 연산자 : >,<,>=,<=
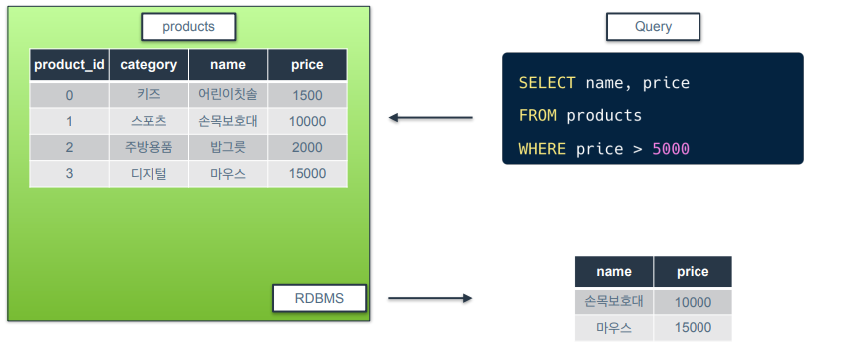
- 왼쪽값이 오른쪽값보다 작은지, 큰지, 작거나 같은지, 크거나 같은지 비교
비교 연산자 : <>, !=
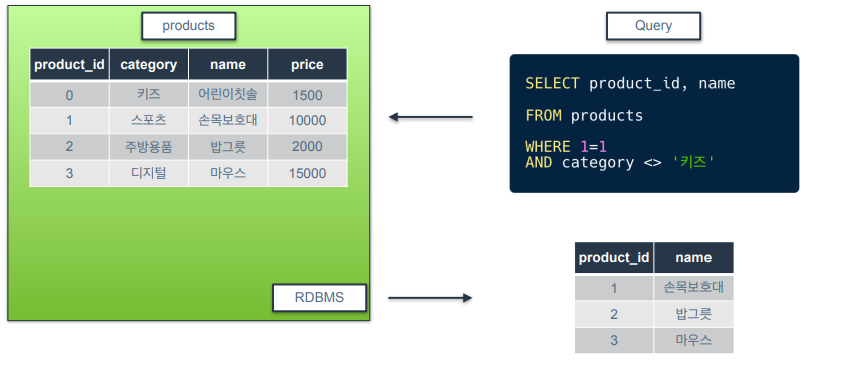
-
같지 않음 연산자
-
<>와 !=는 같은 의미
논리 연산자 : AND
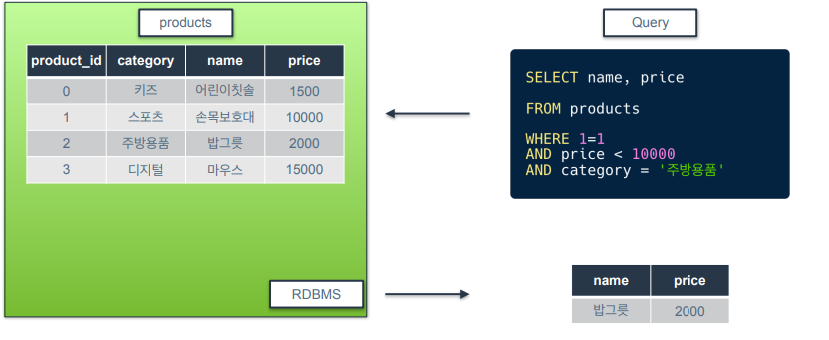
- 두 개 이상의 조건이 모두 참일 때 참 반환
논리 연산자 : OR
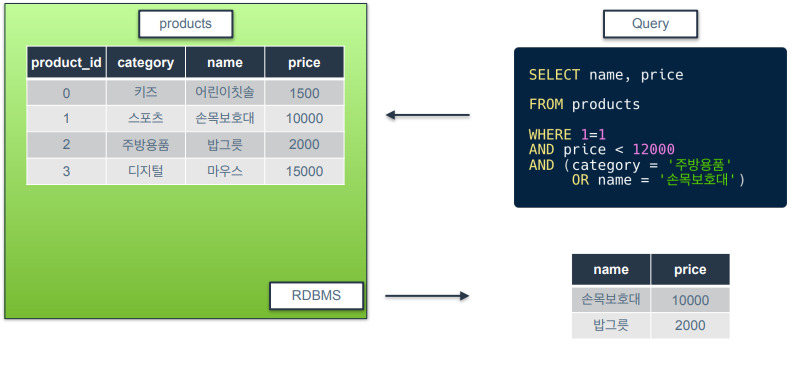
-
조건이 하나만 참이어도 참 반환
-
우선, price가 12000 아래인 거를 필터링하고, 그 다음 category가 주방용품이거나 name이 손목보호대인 행을 필터링
논리 연산자 : NOT
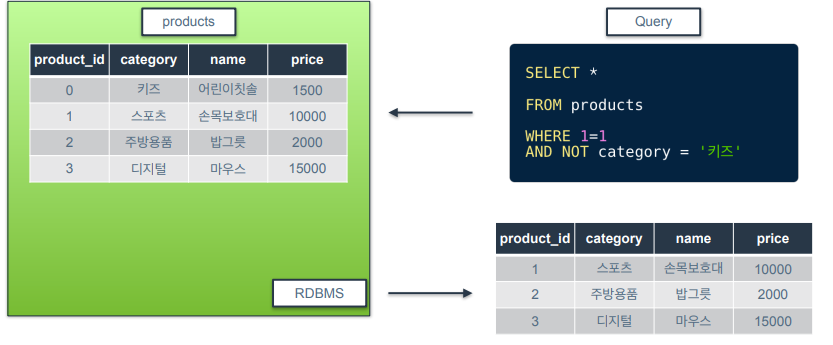
-
참/거짓을 뒤집을 때 사용
-
category가 키즈가 아닌 행들만 필터링
논리 연산자 : IN
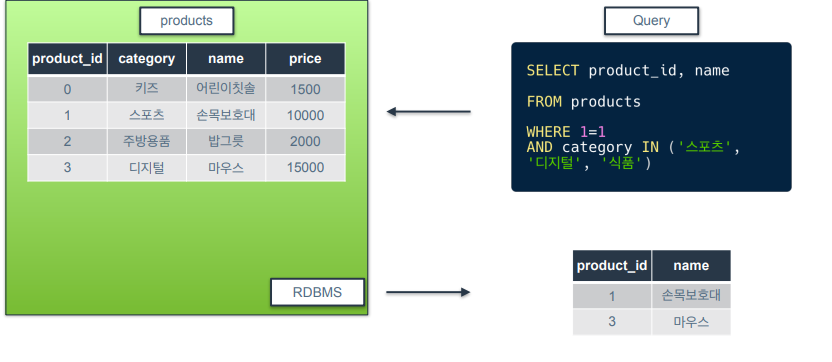
- 왼쪽값이 오른쪽에 포함될 때만을 반환
논리 연산자 : NOT IN
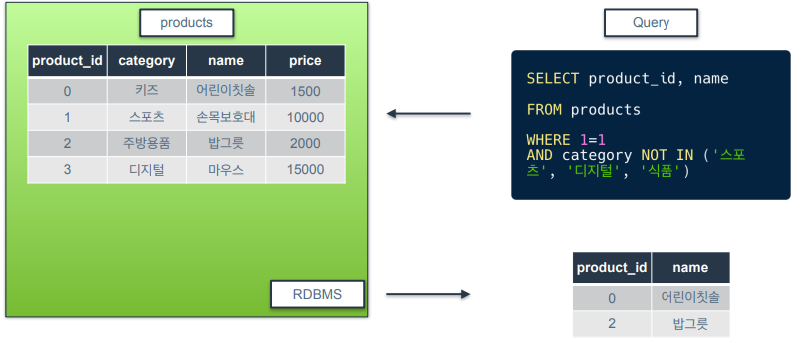
- 포함되지 않는 행들만 반환
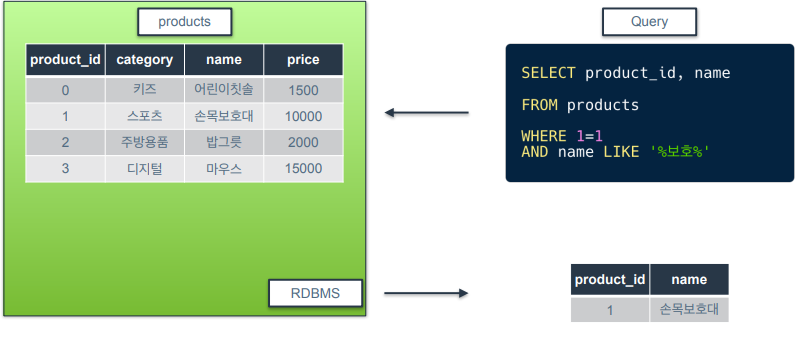
논리 연산자 : LIKE
-
문자열의 패턴을 검색하는데 사용됨
-
% 기호는 모든 문자열이라는 기호
-
예제 쿼리 의미는 '보호'라는 문자열 앞뒤로 무슨 문자가 오든지 보호라는 문자열을 포함하고 있으면 반환하라는 의미
-
만약 밥% 이라면 ➡️ 밥 뒤에는 아무 문자열이 와도되지만 밥으로 시작해야한다는 의미(ex. 공기밥이라는 문자열이 있다면 그건 반환 x)
-
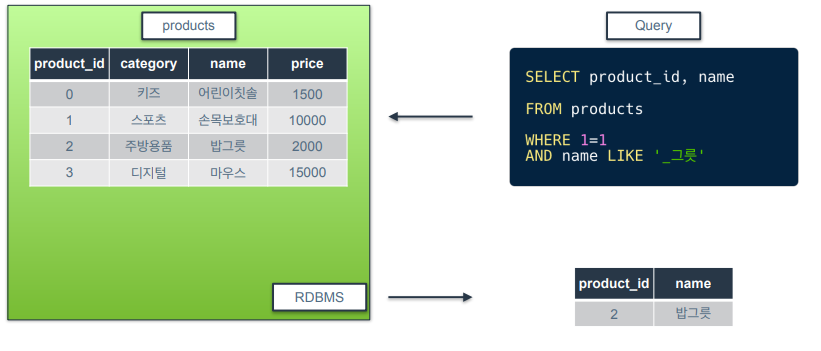
_그릇 ➡️ _기호는 한 개의 문자열이라는 의미. 그릇 문자 앞에 단 하나의 문자열이 오는 경우만 반환하라는 의미
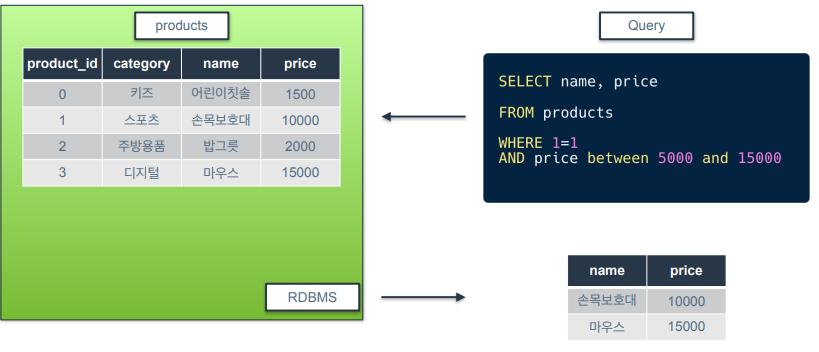
논리 연산자 : BETWEEN
-
예제 쿼리는 price가 5000이상 15000이하만 필터링하라는 의미
-
결과를 보면 BETWEEN은 범위의 양쪽 끝값도 포함한다는 것을 알 수 있음
-
숫자뿐만 아니라 문자열에 대해서도 적용 가능
논리 연산자 : IS NULL
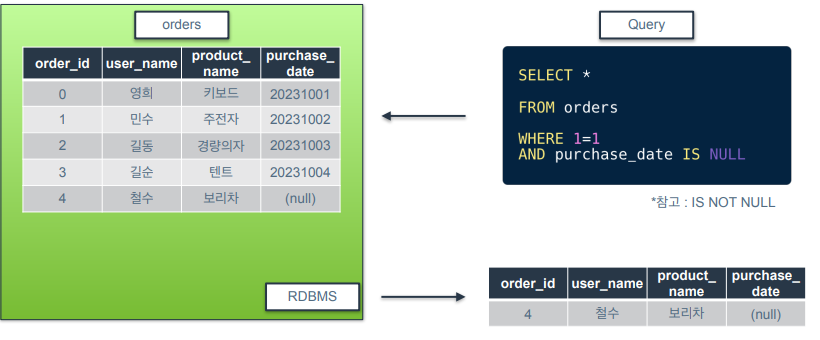
- 컬럼값이 비어있는지를 검사
➡️ 특정 컬럼이 비어있는 행만 뽑으려면 IS NULL, 비어있지 않은 행만 뽑으려면 IS NOT NULL
📍 정렬과 집계
정렬 : ORDER BY
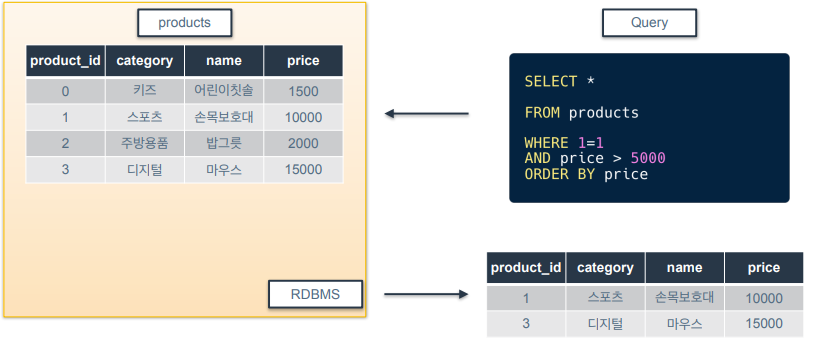
- 데이터 정렬은 특정 열의 값을 기준으로 데이터를 오름/내림 차순으로 정렬하는 거를 말함.
-
예제 쿼리는 price가 5000원 넘는 걸 필터링하고 가격순으로 오름차순 되도록 정렬함.
-
ORDER BY 정렬하고자하는 컬럼명 ➡️ 이렇게 형태로 적어주면 됨
-
컬럼명 옆에 DESC 써주면 내림차순. 안써주면 기본은 오름차순.
- ASC는 오름차순 의미인데 생략해도 됨
-
정렬은 숫자뿐만 아니라 문자열 컬럼에 대해서도 적용 가능
➡️ 한글은 가나다 순, 영어는 알파벳 순 -
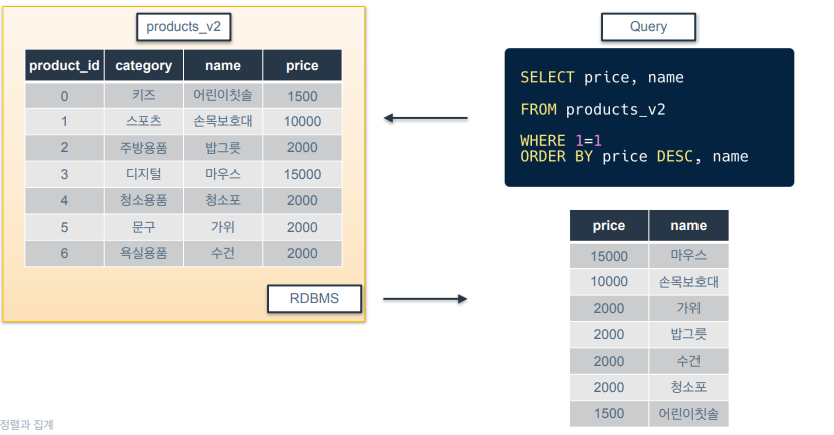
정렬을 여러번 하는 경우가 있는데 price로 1차로 정렬하고, 가격이 같을 때 이름으로 정렬하겠다는 의미. price는 내림차순 정렬하고 이름은 오름차순 정렬.
-
ORDER BY 뒤에 컬럼명 대신 숫자를 쓴 경우는 SELECT 구문에서 선택한 컬럼 순서를 의미.
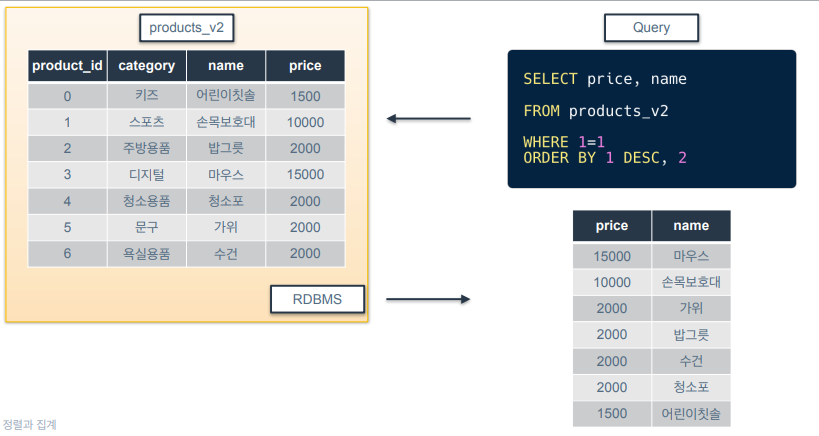
- price로 내림차순 정렬하고, 가격이 같은거는 name으로 정렬한다는 의미
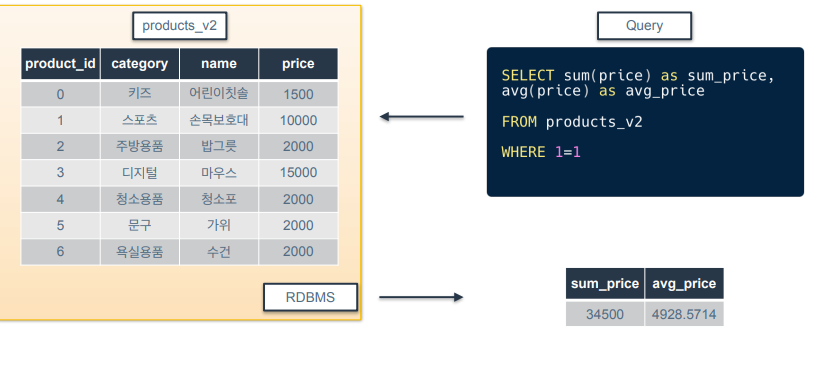
집계 : SUM
-
집계 함수란 여러 행으로부터 하나의 결과값을 반환하는 함수
ex) 평균, 합계, 최대, 최소 -
예시 쿼리는 price 컬럼에 대해 sum(합계)과 avg(평균) 수행한 결과를 보여줌.
-
참고로, 컬럼명 뒤에 as를 붙이고 이름 적으면 결과값이 새로운 컬럼명으로 나옴
-
as는 집계함수에서만 사용할 수 있는 건 아님
-
집계 : COUNT
-
COUNT는 조건에 맞는 행 수를 반환함.
-
COUNT(1)은 컬럼값이 null인거와 관계없이 행 수를 세어 결과를 보여줌. COUNT(*)도 동일.
-
COUNT(컬럼명)하면 null값은 제외하고 카운팅.
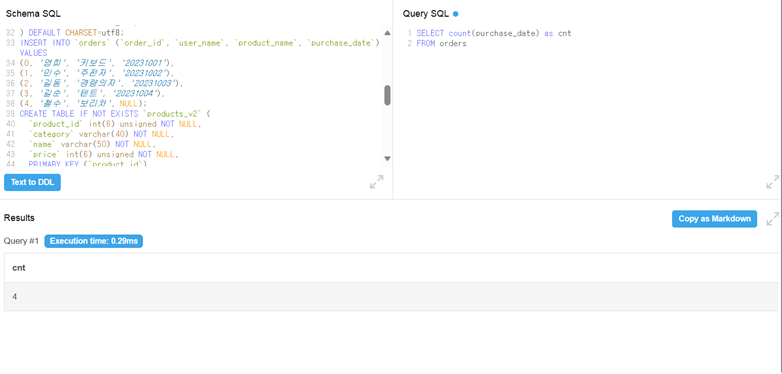
- orders 테이블에서 purchase_data 마지막 값이 null이기 때문에 COUNT했을 때 5가 아닌 4가 반환.
-
COUNT는 컬럼에 중복값 여부를 체크하지 않는데, 특정 컬럼명 앞에 distinct를 붙이면 해당 컬럼의 중복이 없는 개수를 카운팅.
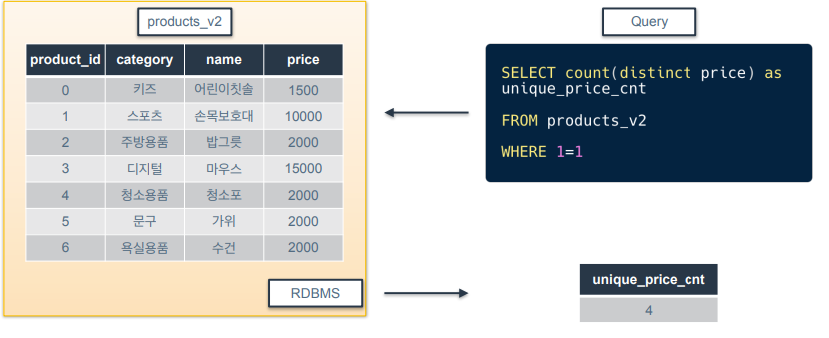
- 예제 쿼리에서는 중복을 제거한 price 개수를 카운트해서 unique_price_cnt로 나오게 한 거
➡️ price는 1500, 2000, 10000, 150000 존재하므로 4가 반환
- 예제 쿼리에서는 중복을 제거한 price 개수를 카운트해서 unique_price_cnt로 나오게 한 거
-
WHERE 뒤에 조건이 있다면 그 조건 수행한 뒤에 집계함수 적용.
집계 : GROUP BY
-
집계는 전체 테이블 대상으로 할 수도 있지만 그룹으로 묶어서 하는 경우도 많음.
-
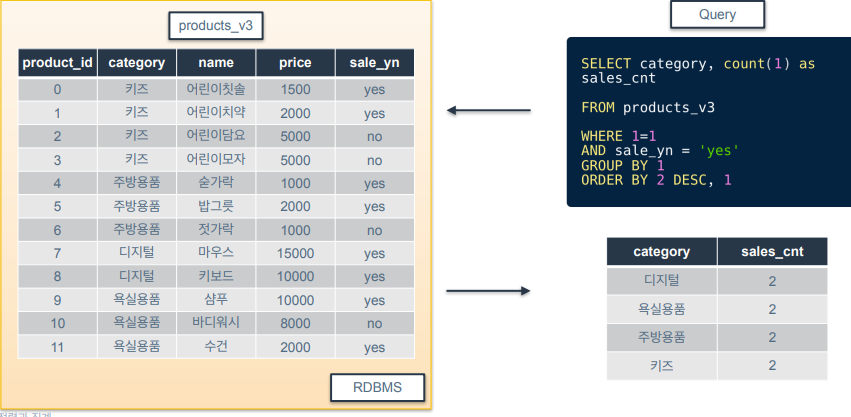
예제 쿼리를 보면 카테고리 별 판매중인 상품 수를 카운팅 하는거.
-
GROUP BY 1은 category로 group by 의미.
-
COUNT는 GROUP BY한 뒤 적용됨.
-
그 후 sales_cnt로 내림차순 정렬하고 category로 오름차순 정렬.
-
-
GROUP BY는 2개 이상의 컬럼에 대해서도 가능
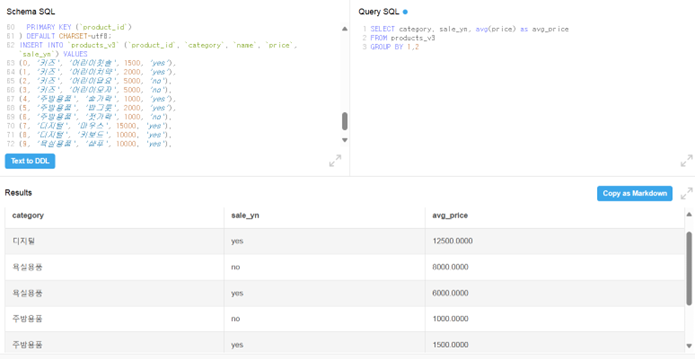
- category, sale_yn(판매여부)로 그룹화를 먼저하고 각 그룹별로 평균 가격을 구함.
HAVING
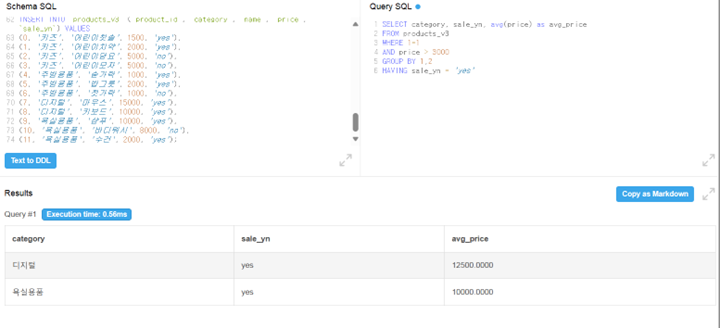
- WHERE과 헷갈릴 수 있는 표현으로 HAVING이 존재
➡️ 차이점 : WHERE은 그룹화 전에 필터링하는 것이고 HAVING은 그룹화된 결과에 대해서 필터링을 함
- 가격이 3000원 이상인 것의 평균 가격을 구하면 판매중인 상품과 아닌게 섞여있음. HAVING을 사용하여 판매중인 상품만 필터링
📍 기초 SQL 함수
CONCAT
-
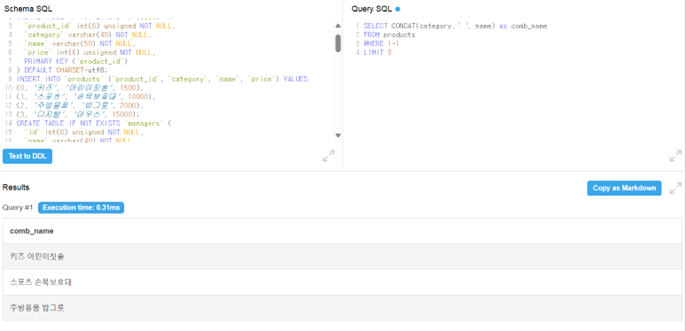
문자열을 다루는 함수
-
여러 컬럼의 문자열 값들을 하나의 컬럼으로 합치기 위해 사용
-
주로 문자열에 쓰이지만 문자열 아니여도 사용 가능(ex. 공백을 넣는 경우)
-
숫자 타입을 넣어도 문자열 타입으로 변한한 뒤 문자열을 합쳐줌
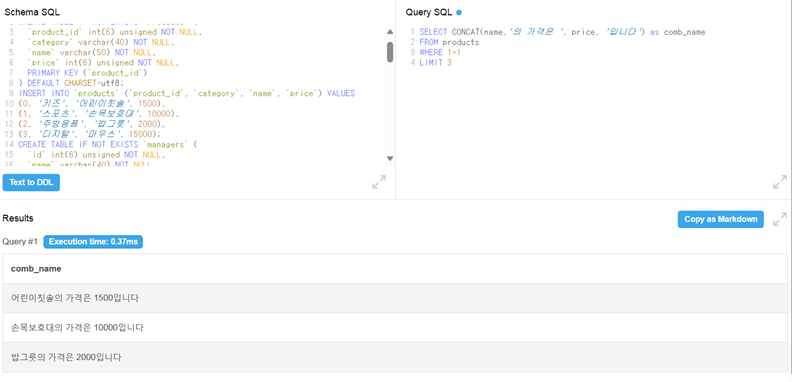
- price는 정수 타입인데 잘 합쳐진 것을 확인할 수 있음
SUBSTRING
-
문자열을 다루는 함수
-
문자열에서 일부분만 추출하는 함수. 문자열을 잘라서 부분만을 변환하는 함수.
-
3개의 파라미터를 받음 ➡️ (추출 원하는 컬럼명, 시작 위치, 추출 원하는 길이)
-
예제 쿼리는 name 컬럼의 첫번째 값부터 시작해서 길이 2만큼 문자열을 추출
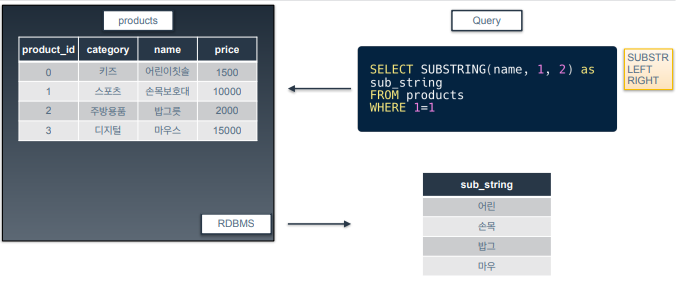
-
MySQL에서는 SUBSTRING이고 다른 DB에서는 SUBSTR 이기도함.
-
LEFT는 왼쪽부터 문자열을 잘라서 추출, RIGHT는 오른쪽부터 문자열 잘라서 추출
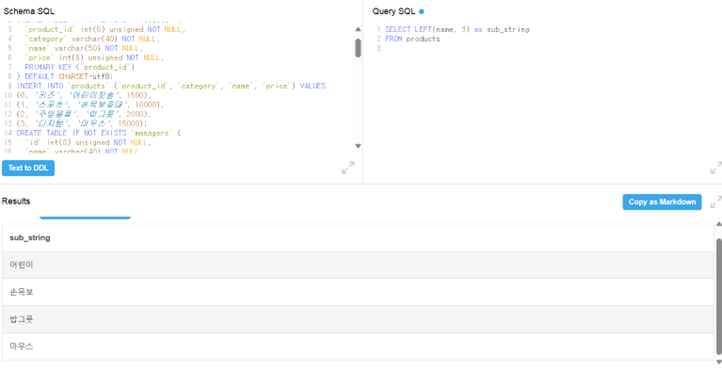
- name 컬럼에서 왼쪽부터 길이 3짜리로 추출된 것을 확인할 수 있음
-
UPPER, LOWER 함수(각각 영어를 대문자, 소문자로 통일 시키는 함수)
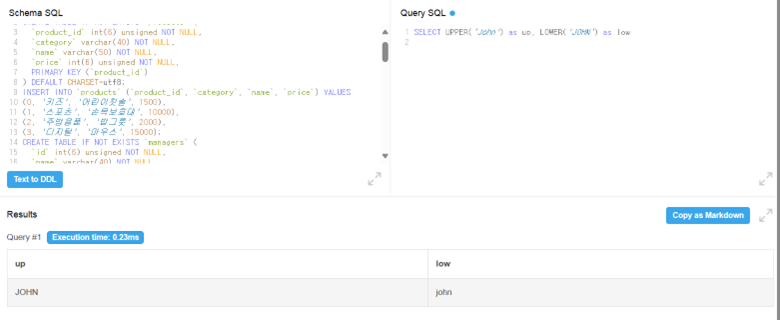
-
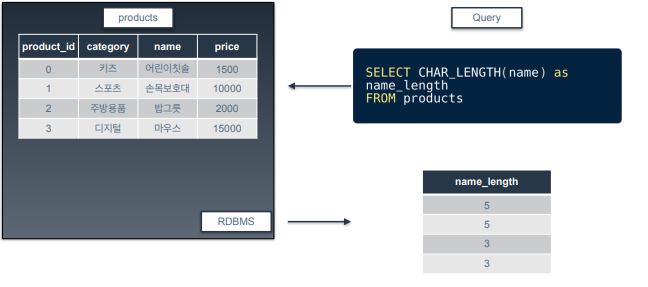
CHAR_LENGTH
-
문자열의 길이를 반환하는 함수
-
예제 쿼리에서는 name(상품명)의 길이를 반환
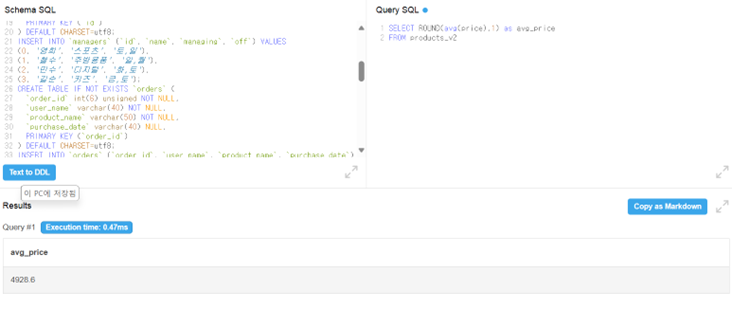
ROUND
-
반올림을 하는 함수. 몇 번째 자리까지 남길지 두번째 파라미터로 넣어줄 수 있음.
- 소수점 아래 첫번째 자리까지 남기겠다는 의미. 그러면 소수점 아래 두번째 자리에서 반올림 하게 되는 것.
-
예제 쿼리는 가격의 평균이 소수점으로 나온 경우 반올림해서 보여주는 경우
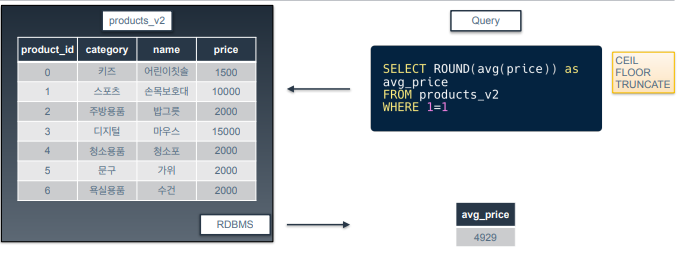
-
비슷한 함수로 소수점 이하 수가 얼마이든간에 올림하는 CEIL이 있음. 내림은 FLOOR
-
TRUNCATE는 특정 자리 수 이하를 버리는 함수
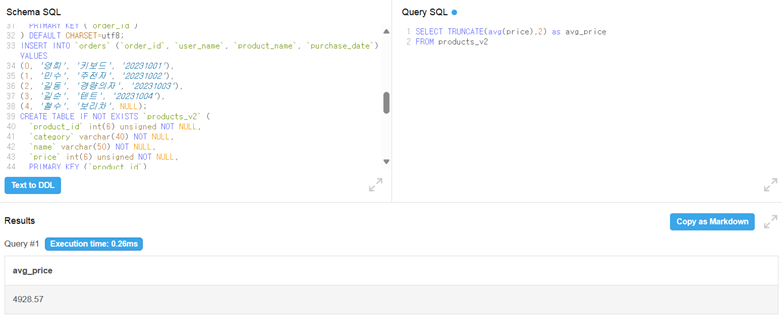
- 소수점 아래 2번째 자리까지만 나오게 한 예시
-
ABS
- 절대값 함수
MOD
-
나머지를 구하는 함수
-
MOD(분자, 분모)
-
예제 쿼리는 price를 product_id로 나눈 나머지를 구하는 거.
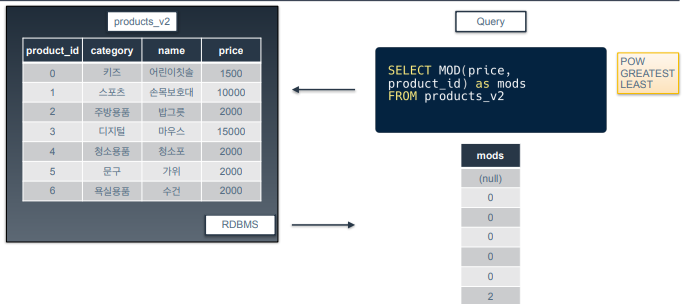
-
첫번째 결과는 0으로 나누었기 때문에 null.
-
비슷한 함수 중 POW는 2개의 인자를 받아서 x의 y승을 구하는 함수, GREATEST는 인자로 들어오는 수 중에서 최대값을 반환. LEAST는 최소값을 반환.
-
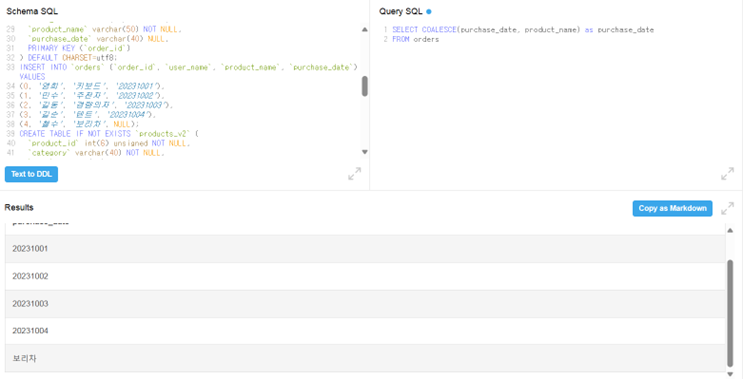
COALESCE
-
'병합하다'라는 뜻
-
null 값을 채우기 위해 사용. 한 컬럼 값이 비어있을 때 빈 값을 특정값이나 같은 행의 다른 컬럼으로 채울 수도 있음.
-
orders 테이블에서 purchase_date 마지막 값이 null 이었는데 같은 행의 product_name으로 채움.
📍 (Optional) DDL, DML
DDL, DML 개요
지금까지는 데이터베이스 내 테이블이 여러 개 있다고 가정하고 각 테이블에서 쿼리를 통해 원하는 데이터를 가져오는 방법에 대해 배웠음.
지금부터는 데이터베이스 내 테이블을 만들고 조작하는 DDL과 DML에 대해 배울 예정.
-
DDL은 Data Definition Language로 데이터베이스 구조를 정의하고 관리하는데 사용
-
DDL는 크게 3가지 구문이 존재
1) CREATE - 테이블/뷰(일종의 가상 테이블.기존 테이블의 일부분만을 보여주고 싶거나 다른 테이블과 결합하여 보여주고 싶을 때 사용)/인덱스(데이터베이스에서 원하는 데이터를 빨리 찾기 위해서 만든 색인) 생성
2) ALTER - 테이블 컬럼 추가, 삭제, 컬럼명 변경 등 데이터베이스 내 객체를 변경하기 위한 문구
3) DROP - 데이터베이스 내 데이터를 삭제하는 구문
-
DML은 Data Manipulation Language로 데이터를 쿼리해서 가져오거나 조작하는데 사용
1) SELECT - 데이터 원하는 형태로 가져오는 거
2) INSERT - 생성되어 있는 테이블에 데이터를 삽입하기 위해 사용
3) UPDATE - 이미 들어간 데이터를 수정하기 위해 사용
4) DELETE - 테이블 전체 삭제가 아닌 특정값 삭제
CREATE
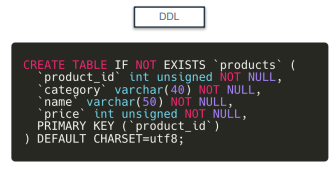
-
테이블을 생성하는 구문 ➡️ CREATE TABLE
-
IF NOT EXISTS : 존재하지 않을 때만 생성한다는 의미
-
CREATE TABLE IF NOT EXISTS '테이블 명' 형식으로!
-
괄호 안에는 컬럼명과 컬럼 타입, null값이 들어가도 되는지 정의
-
unsigned는 음수를 쓰지 않겠다는 의미
-
varchar은 가변길이 문자열 의미. 길이조절해서 저장할 수 있는 타입
-
primary key는 테이블 내 모든 행에 적용되는 고유한 아이디 의미. 각 행에 대한 주민번호 같은거라고 생각
-
DEFAULT CHARSET 은 테이블의 기본 문자를 지정하는거. 한글 데이터를 입력하고 싶기 때문에 예시에서는 UTF8지정.
-
SQL 구문을 콘솔 하나에서 여러 개 사용하는 경우엔 맨 마지막에 세미콜론 작성해야함.
CHAR / VARCHAR

-
CHAR은 고정공간을 차지함. CHAR(6)에서 6은 어떤 길이의 문자열을 받는지 의미.
-
VARCHAR은 데이터에 따라 차지하는 공간이 다름. 입력되는 글자 길이에 따라 공간을 다르게 할당.
-
VARCHAR은 문자 길이보다 1byte를 더 쓰는걸 볼 수 있는데, 문자 길이가 몇인지를 기록해둬야 하기 때문임.
-
둘 중 어떤거 쓰는게 좋을까?
➡️ 고정된 문자열이면 CHAR. VARCHAR은 문자열 길이를 1 추가해서 넣기도하고 문자열 길이를 계산하는 시간이 걸려서 시간이 더 오래걸릴 수 있음. 문자열 길이가 다르게 들어오는 경우에는 VARCHAR.
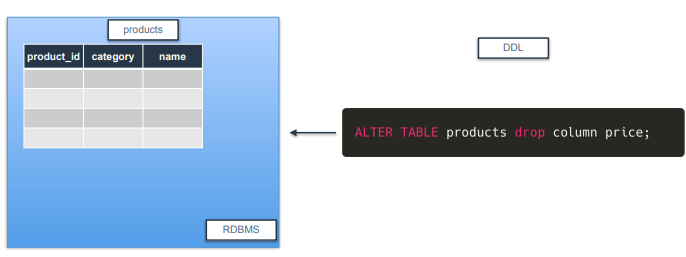
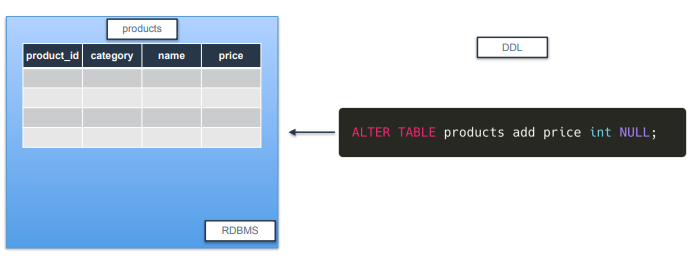
ALTER
-
컬럼을 삭제/추가할 수 있음.
-
예제는 products 테이블에서 price 컬럼을 지우겠다는 의미
-
지운 행을 추가할 수도 있음.
-
이외에도 ALTER 구문써서 컬럼명 바꾸거나 컬럼 타입을 바꿀 수도 있음.
-
실습에서 price에 null값이 들어가면 안되게 설정을 해놓았는데 여기에 null을 넣을 수 있는 int타입으로 변경해보겠음.
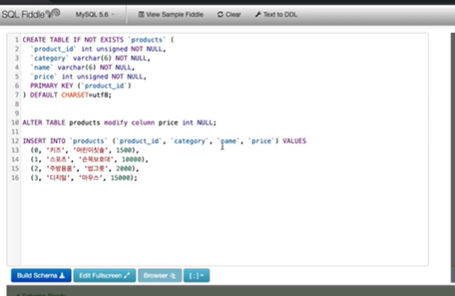
-
ALTER TABLE products modify column price int NULL 부분
-
modify사용하긴 했는데 버전마다 다를 수도 있음
-
-
컬럼명 바꾸는 실습
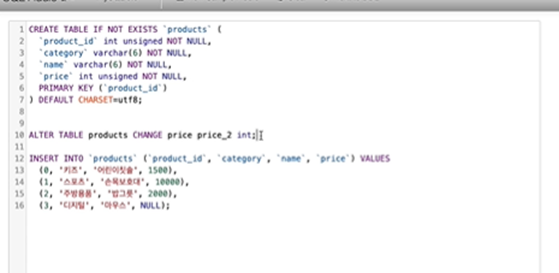
-
ALTER TABLE products CHANGE price price_2 int 부분
-
price ➡️ price_2로 변경
-
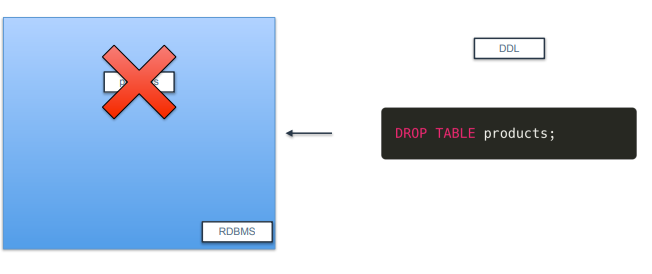
DROP
-
RDBMS 내에 객체를 삭제하는 구문
-
예제에서는 products라는 테이블을 삭제
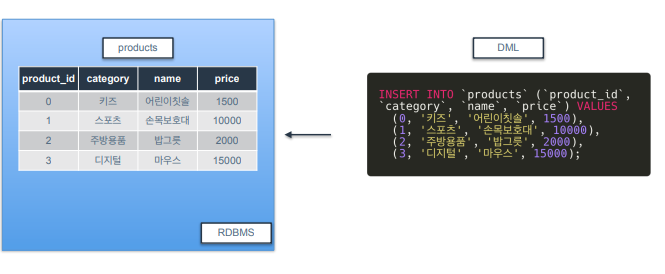
INSERT
-
CREATE로 테이블을 생성하고 INSERT로 데이터를 삽입.
-
INSERT IN 테이블명 (컬럼명) VALUES (실제 넣고 싶은 값) 형태
UPDATE
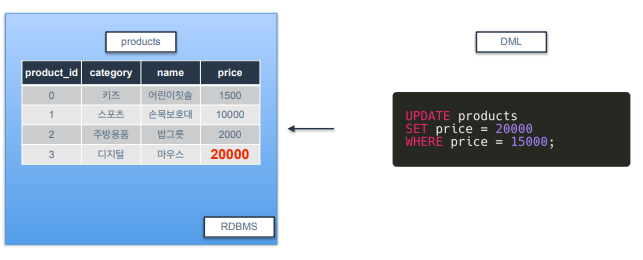
-
테이블 내 삽입된 값들을 수정
-
예제는 products라는 테이블에 가격이 15000원인 행 찾아서 20000으로 바꾸는 거.
DELETE
-
테이블 내에서 특정 레코드를 삭제하는 역할
-
예제는 products 테이블에서 가격이 15000원인 행을 삭제하는 거.

