🟨 여러 테이블 결합하여 사용하기
지금까지는 하나의 테이블을 가지고 어떻게 원하는 데이터를 추출할 수 있는지 다양한 SQL 쿼리를 배웠음.
이번에는 여러 테이블을 결합하여 데이터를 추출하는 방법에 대해 배울 것임.
📍 다양한 JOINS
다양한 JOIN 개요
-
JOIN은 두 개 이상의 테이블을 특정 key를 기준으로 결합하는 것
-
예시) products 테이블만 보면 상품의 담당자를 알 수 없음. 상품 별 담당자를 알고 싶을 때 managers 테이블과 JOIN 을 사용함.
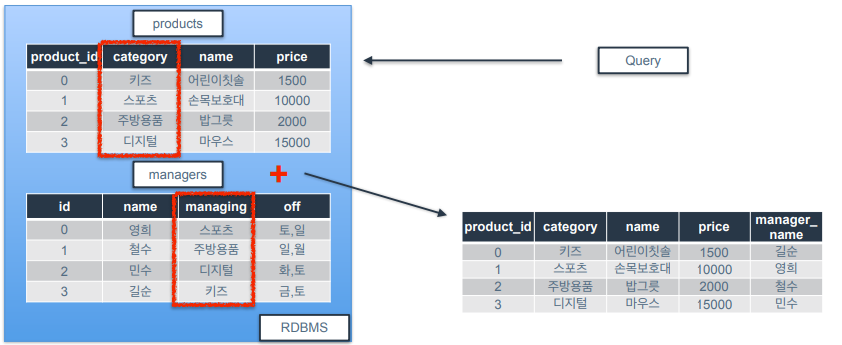
-
그런데 왜 테이블을 쪼개 놓는 것일까?
1) 데이터를 관리하기 쉽고 효율적으로 저장할 수 있기 때문
- 만약 컬럼을 공유하고 있는 두 개의 테이블이 있다고 해보자.
컬럼의 값에 변경이 있을 경우 두 개의 값을 모두 변경해주어야 하는데 쪼개져 있는 경우 하나의 테이블에서 컬럼값을 변경하고 JOIN을 활용할 수 있음.
2) JOIN 연산을 통해 수많은 활용사례가 나올 수 있음
- 만약 컬럼을 공유하고 있는 두 개의 테이블이 있다고 해보자.
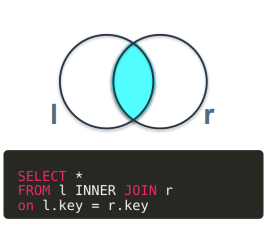
INNER JOIN
FROM 테이블 명(기준이 되는 테이블 명) INNER JOIN 테이블 명(교집합을 구할 대상 테이블 명) ON 컬럼 명(어떤 컬럼을 기준으로 결합할지)-
두 개의 테이블에서 일치하는 행만 가져와서 결합하는 JOIN 유형.
-
두 테이블 간의 교집합을 반환.
-
컬럼 값이 양쪽 테이블에서 일치하는 행만 반환하므로 데이터 정확성이 높음. 컬럼 값이 비어있거나 한쪽에만 있는 행은 제외됨.
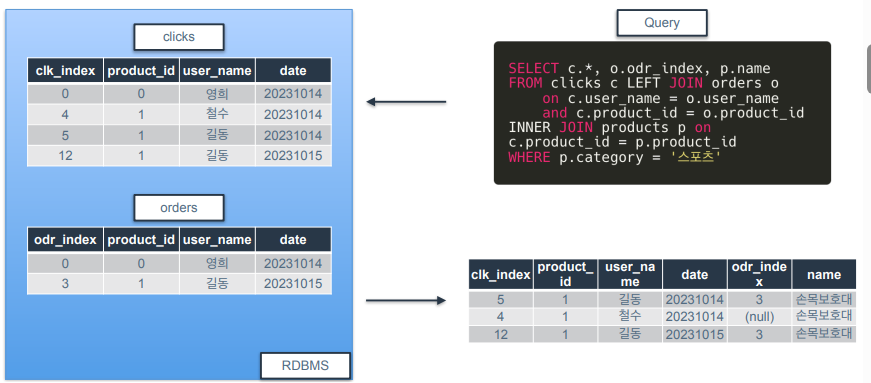
(실습)
클릭이 실제 구매로 이어진 경우를 찾기 위해 orders 테이블과 clicks 테이블을 결합해봄.
SELECT clicks *, 1 as ordered
FROM clicks INNER JOIN orders
ON clicks.user_name = orders.user_name
AND clicks.product_id = orders.product_id
AND clicks.date = orders.date 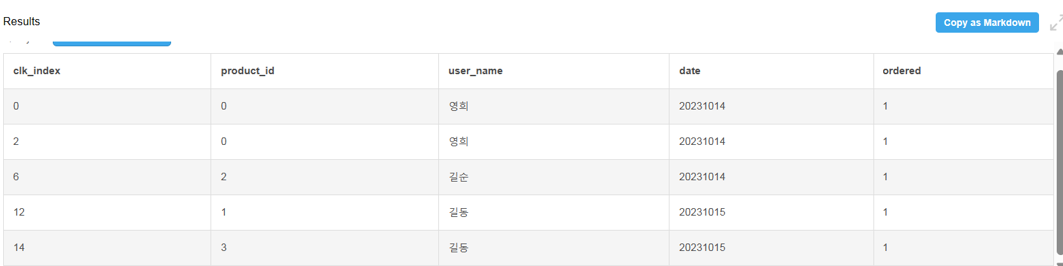
-
clicks와 orders 테이블 INNER JOIN 시 3개의 key 사용하였음(user_name, product_id, date).
➡️ 이 3개의 값이 양쪽 테이블에 존재하고 서로 같은 행들만 결합➡️ 왜 3개의 조건 사용? 어떤 유저가 어떤 상품을 언제 구매했는지 보려면 3개를 다 넣어줘야 함.
-
위의 예시처럼 ON 뒤에 여러 개의 조건을 결합하여 사용할 수도 있음.
-
위의 결과는 product_id로 되어있어서 무슨 상품을 구매했는지 알기가 어려움. 따라서 여기에 product_name도 결합해보겠음.
SELECT clicks *, 1 as ordered, name FROM clicks INNER JOIN orders ON clicks.user_name = orders.user_name AND clicks.product_id = orders.product_id AND clicks.date = orders.date INNER JOIN products ON clicks_product_id = products.product_id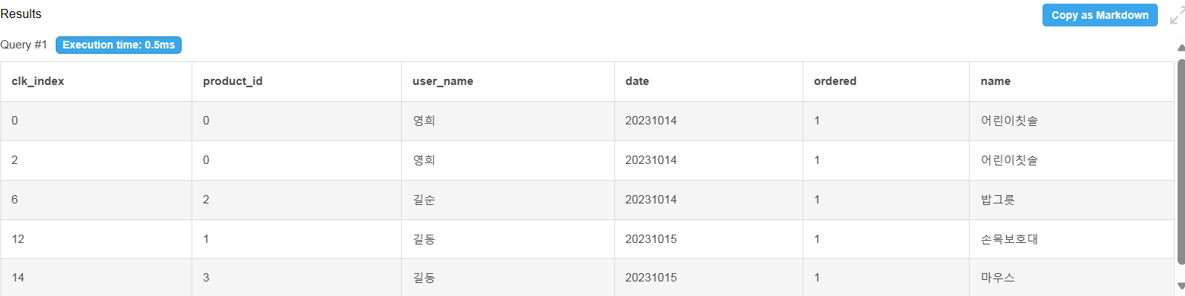
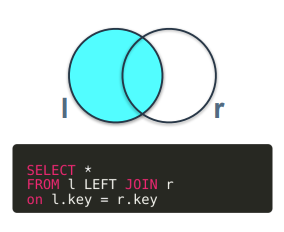
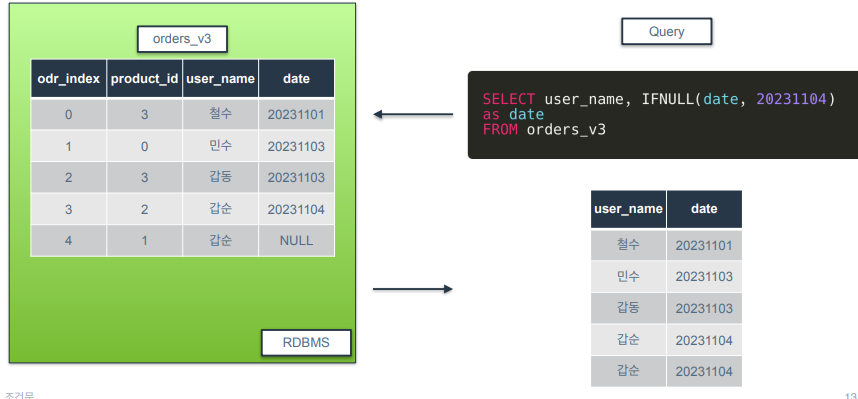
LEFT JOIN
-
왼쪽 테이블의 모든 행을 가져오고 오른쪽 테이블에서 일치하는 행을 가져와 결합하는 JOIN 유형
-
오른쪽 테이블에서 왼쪽 테이블과 일치하지 않는 행은 null 값으로 표시됨.
-
예시)
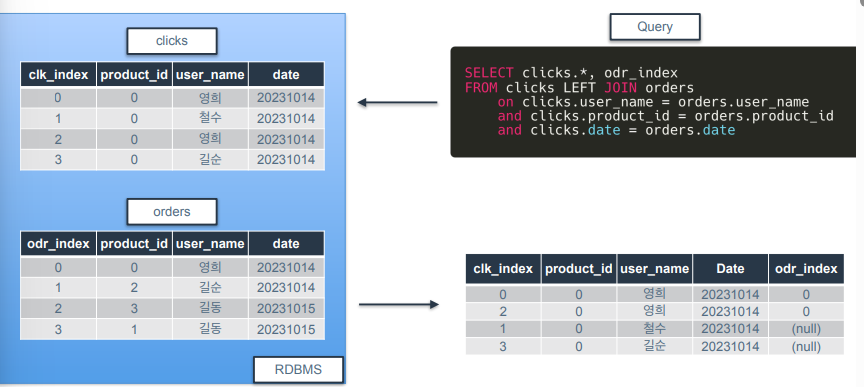
-
clicks 테이블을 기준으로 결합을 하되, 모든 컬럼이 같아야 결합을 함.
-
clicks 테이블과 모든 조건이 일치하는 orders 테이블 행은 odr_index 행을 가져오게 되고 그러지 않은 거는 결합되지 않아 null로 표기됨.
-
-
특징 - 왼쪽 테이블의 모든 테이블을 포함하므로 JOIN으로 누락되는 테이블이 없음(왼쪽 테이블 기준). 두 테이블의 key값이 일치하지 않는 경우 null로 표시되므로 어떤 행이 일치하고 어떤 행이 일치하지 않는지 쉽게 볼 수 있음.
-
JOIN 결과는 테이블이므로 WHERE 절에 넣어서 필터링 할 수도 있음.
(실습)
클릭 및 구매이력을 상품명과 함께 뽑아봄.
SELECT clicks *, ord_index, name
FROM clicks LEFT JOIN orders
ON clicks.user_name = orders.user_name
AND clicks.product_id = orders.product_id
AND clicks.date = orders.date
INNER JOIN products ON clicks_product_id = products.product_id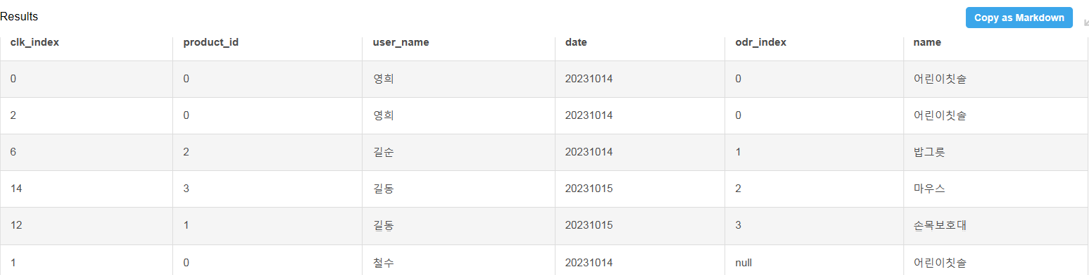
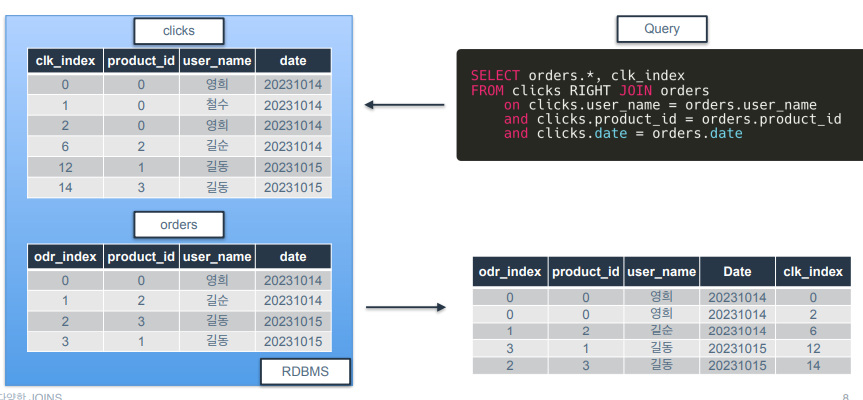
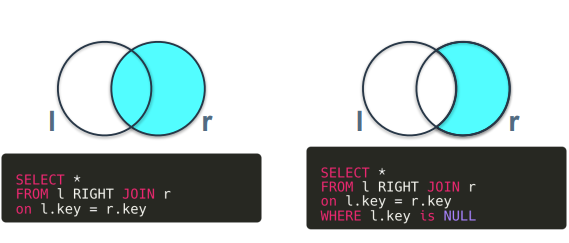
RIGHT JOIN
-
LEFT JOIN의 반대.
-
오른쪽 테이블의 모든 행을 가져오고 왼쪽 테이블에서 일치하는 행을 가져와 결합하는 JOIN 유형.
-
왼쪽 테이블에서 가져온 컬럼 중 오른쪽 테이블과 key값이 일치하지 않는 경우 null 값으로 표시됨.
-
예시)
-
orders 테이블 기준으로 clicks 테이블을 결합하는 거.
-
ord_index보면 0번이 두 개가 되었는데, 그 이유는 영희가 20231014에 0번 상품을 두 번 클릭했기 때문. 클릭 인덱스가 서로 다른 값이 두 개 있으므로 ord_index의 0번 값에 붙어서 나오게 된 것.
-
FULL OUTER JOIN
-
두 테이블 간의 모든 행을 가져오며 일치하는 행과 일치하지 않는 행 모두를 포함하도록 결과를 반환하는 JOIN 유형
-
결과 집합에는 두 테이블의 모든 데이터가 포함되고 일치하지 않는 행의 컬럼값은 null.
-
두 테이블의 모든 행을 포함해서 필터링 되는 게 없음. 따라서 결과 집합이 크면 성능 문제가 발생할 수 있음.
-
DB 마다 지원 여부가 다름. MySQL은 지원하지 않기 때문에 다음 이미지처럼 해주어야 FULL OUTER JOIN.
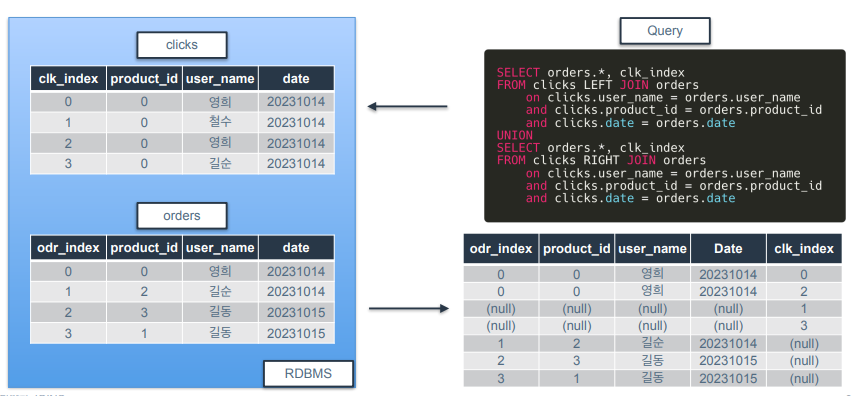
-
이처럼 FULL OUTER JOIN은 INNER JOIN, LEFT JOIN, RIGHT JOIN을 위아래로 붙인 결과로 이해할 수 있음.
CROSS JOIN(= Cartesian product)
-
두 테이블 간의 가능한 모든 조합을 생성할 때 사용.
-
예를 들어 상품 클릭한 시간, 구매한 시간의 차이의 평균을 구하고 싶을 때 사용.
구매한 상품을 같은 것으로 한정하면 INNER JOIN하면 되지만 어떤 상품이든 클릭한 시간과 어떤 상품이든 구매한 시간과의 차이를 보려면 CROSS JOIN해서 모든 클릭/구매 간 조합을 만들고 평균을 구함.
-
예시)
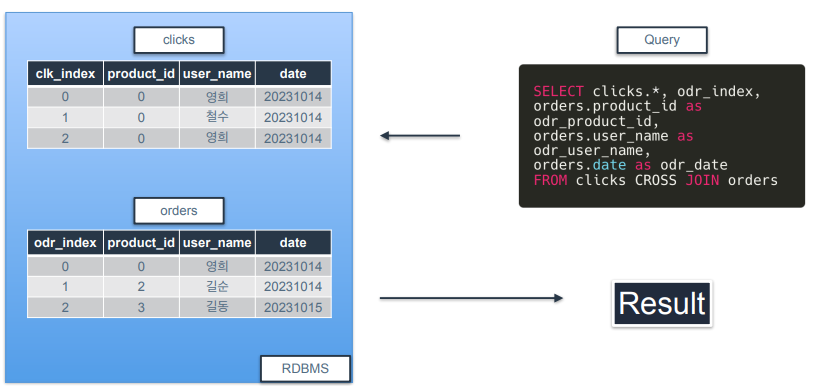
-
우선 clicks 테이블과 orders 테이블에서 겹치는 컬럼 이름을 바꿔줌.
-
결과 테이블 보면 9개의 행으로 구성되는데, clicks 테이블과 orders 테이블이 3개의 행이 있어서 모든 조합이 9라서 결과가 9개의 행으로 구성된 것.
- 실제로 CROSS JOIN하면 결과 테이블이 엄청 커지게 되므로 무분별하게 사용하면 안됨.
-
(실습)
상품 간 유사도를 어떤식으로 구할 수 있는지 알아보겠음
products 테이블과 product_B테이블이 존재. products 테이블에 있는 상품을 클릭하면 product_B에 있는 상품을 추천/반대.
상품을 추천하려면 두 테이블 간의 상품 유사도를 계산할 필요가 있고, 이 때 CROSS JOIN 을 활용
SELECT products *,
products_B.product_id as B_product_id,
products_B.category as B_category,
products_B.name as B_name,
products_B.price as B_price
FROM products CROSS JOIN product_B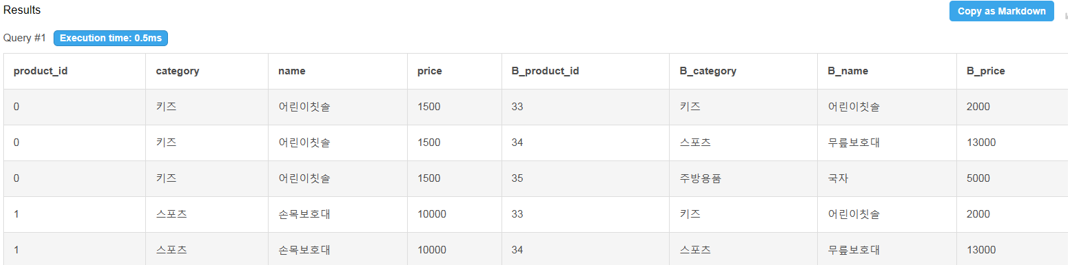
-
총 12개의 행이 생성됨(4행 * 3행 = 12행).
-
유사도 어떻게 구하나?
➡️ cosine 유사도나 유클리디안 유사도가 있지만 지금은 단순한 원리만 소개.
➡️ 카테고리 값이 유사한지 볼 수 있음. 카테고리 값이 같으면 1 아니면 0. 상품 이름까지 같은지도 볼 수 있고 같으면 1 다르면 0. 가격대도 활용할 수 있음. 가격 차이의 절대값이 1000이내면 1점 아니면 0점.
➡️ 각 상품별로 거리가 계산되고 이럴 때 CROSS JOIN이 적용됨.
Alias(=별칭)
FROM clicks c LEFT JOIN orders o-
clicks 테이블은 c, orders 테이블은 o로 지칭하겠다는 의미.
-
별칭을 넣어서 쿼리를 더 가독성있게 만들 수 있음.
SELF JOIN
-
하나의 테이블을 자기 자신과 결합시키는 JOIN 유형
-
SELF JOIN이라는 구문이 있는건 아니고 기존의 JOIN을 활용하되 자기자신과 결합할 때 SELF JOIN이라고 부름.
-
SELF JOIN 할 때는 컬럼명도 겹치고 테이블 명도 겹치기 때문에 ALias 사용이 필수.
-
예시)
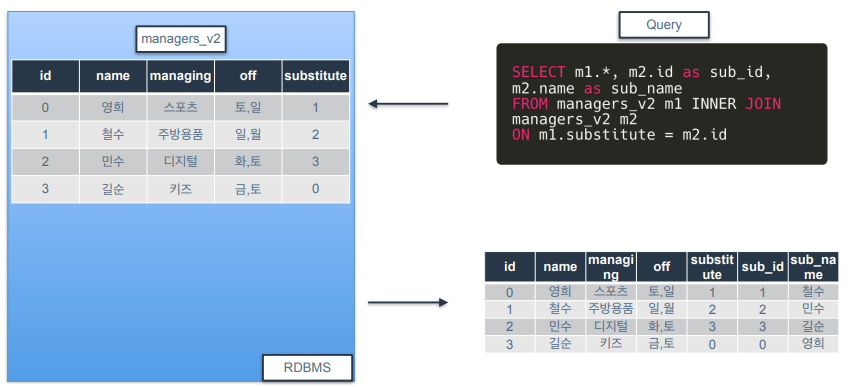
- substitue는 대체자의 id를 의미.
필터링
-
JOIN의 결과로 테이블이 나옴. DB 마다 다르긴 하지만 쿼리 결과물이 임시 테이블로 저장됐다가 세션이 끝나면 삭제되는 식으로 작동함.
-
따라서 결과물이 테이블이기 때문에 기존 테이블에 대해 사용할 수 있는 구문을 그대로 사용할 수 있음.
-
WHERE 조건은 JOIN이 다 끝난 테이블에 대해 적용됨.
- category 컬럼은 SELECT가 아닌데도 사용이 될 수 있었음. 이에 따라 SQL 쿼리가 실행될 때 JOIN을 한 뒤 WHERE과 SELECT가 실행됨을 알 수 있음.
-
쿼리를 효율적으로 만들기 위해서는 결과물을 만들고 필터링을 하는거보다 필터링을 먼저하고 결합하는게 더 좋음!
정리
-
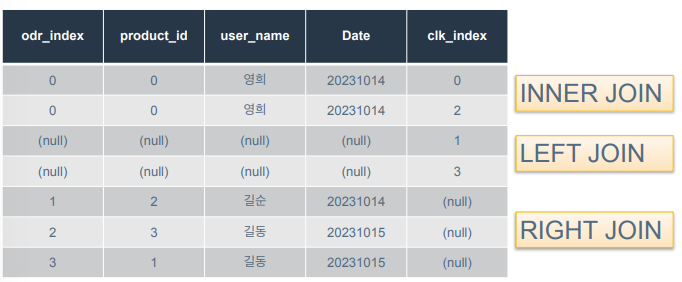
INNER JOIN은 왼쪽 집합과 오른쪽 집합의 교집합을 반환
-
LEFT JOIN은 왼쪽 집합에 해당하는 경우는 모두 포함, 오른쪽 집합에서는 왼쪽 집합과 key를 기준으로 결합 가능한 애만 반환
-
LEFT JOIN을 하되 겹치는 부분을 제거한 경우

-
RIGHT JOIN도 LEFT JOIN과 동일하게 진행.
-
FULL OUTER JOIN은 두 집합의 합집합을 표현한 것. MySQL에서는 지원하지 않아서 LEFT JOIN과 RIGHT JOIN을 UNION한 결과
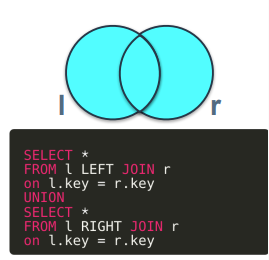
-
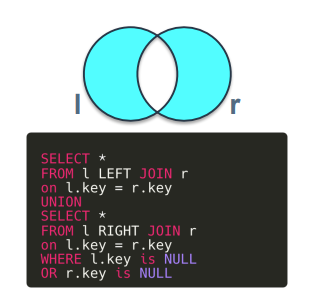
합집합에서 교집합을 제외한 경우. FULL OUTER JOIN을 수행한 뒤 key가 둘 중 하나라도 null인 경우 결과에 포함되도록 조건을 걸었음.
📍 UNION
UNION
-
두 개 이상의 SELECT문의 결과를 결합하여 하나의 결과 집합으로 만드는데 사용.
-
간단히 말해 SELECT한 결과물들을 위아래로 붙이는 거.
-
UNION은 크게 2가지 특징
1) 중복되는 행을 제거해줌
2) 각 SELECT 문의 결과 집합이 포함하는 열의 수(컬럼 수)와 데이터 타입이 일치해야 함
-
예시)
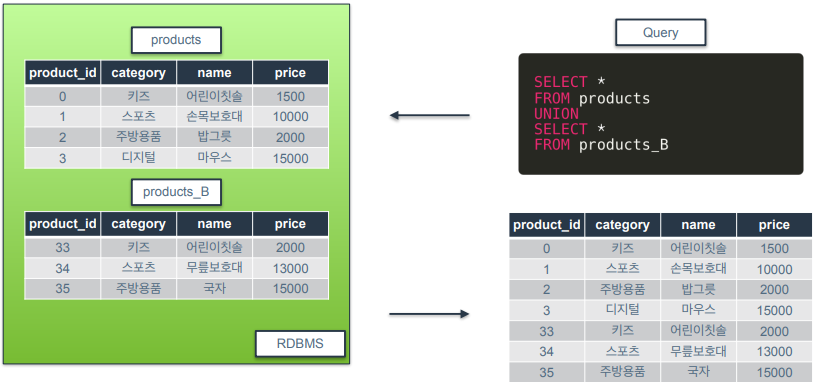
-
products 테이블하고 product_B테이블은 컬럼이 모두 같으므로 union을 사용할 수 있음.
-
컬럼명까지 일치 할 필요는 없지만 컬럼 수와 데이터 타입은 일치해야함.
-
중복제거 기준은 SELECT에 포함된 컬럼 전체가 대상. 컬럼 전체가 같아야 중복제거를 해줌.
-
category 값은 중복제거가 되지만 product_id값이 중복이 아니므로 중복제거가 되지 않았음을 확인할 수 있음.
-
UNION ALL
-
UNION과 달리 중복제거를 하지 않는다는 특징이 있음.
-
중복제거 없이 결과값을 붙여서 반환함.
-
예시)
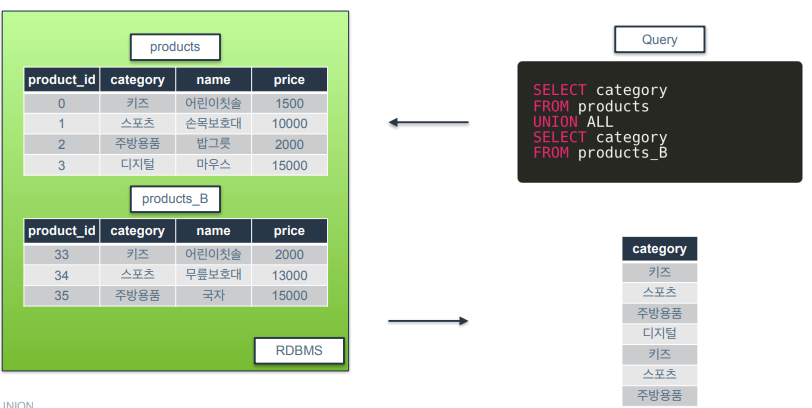
-
FULL OUTER JOIN은 LEFT JOIN과 RIGHT JOIN 결과를 UNION 하면 된다고 했었음.
📍 WITH
-
WITH 구문은 일반적으로 CTE(Common Table Expression)이라고 부르며 MySQL 8.0 버전 이상에서 지원함.
-
SQL에서 임시 결과 집합을 생성하여 복잡한 쿼리를 쉽게 작성할 수 있도록 돕는 기능.
복잡한 쿼리에서 하위 쿼리를 사용해 같은 결과를 여러 번 계산해야하는 경우를 줄여주고 쿼리 가독성을 높여 유지보수를 용이하게 함.
-
WITH 블록을 나오면 그 이후 쿼리부터 블록을 마치 테이블처럼 사용할 수 있음.
-
지금까지 fiddle에서 실습한 거는 5.6 버전이라서 WITH 구문 사용 불가. 따라서 다른 실습 사이트에서 진행
https://www.programiz.com/sql/online-compiler/-
해당 사이트는 기본으로 제공하는 테이블이 존재.
-
고객 정보가 저장된 customers 테이블, 이 고객들이 무엇을 주문했는지 담긴 orders 테이블, 고객별로 배송을 나타내는 shippings 테이블이 존재
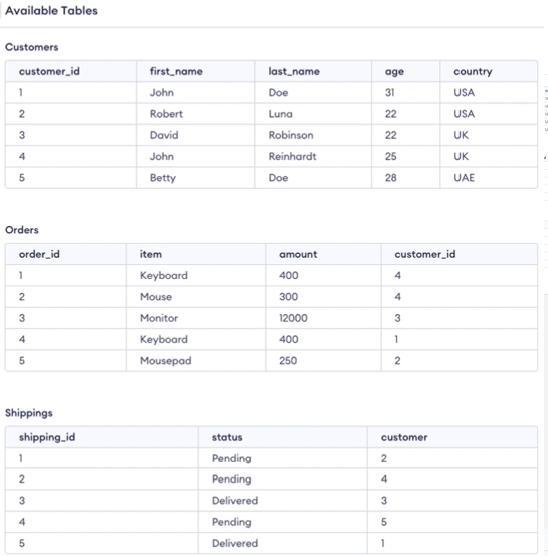
-
(실습)
WITH 구문을 사용해서 고객별로 구매한 상품 수, 총 구매 금액, 배송 status가 pending인 shipping_id 수를 집계해볼 것임.
ord_cnt 블록을 지정하고 order과 customers 테이블 결합 한 뒤 고객 기준으로 집계하고 정렬
WITH ord_cnt as (
SELECT c.customers_id, count(distinct order_id) as odr_cnt, sum(amount) as total_purchase
FROM Customers c INNER JOIN Orders o ON c.customer_id = o.customer_id
GROUP BY 1
ORDER BY 2 DESC
)다음은 ship_cnt 블록 지정
WITH ship_cnt as (
SELECT c.customers_id, count(distinct shipping_id) as ship_cnt
FROM Customers c INNER JOIN Shippings s ON c.customer_id = s.customer
WHERE status = 'Pending'
GROUP BY 1
ORDER BY 2 DESC
)이제 두 개의 블록을 사용해서 최종 결과 만들어보겠음.
WITH ord_cnt as (
SELECT c.customers_id, count(distinct order_id) as odr_cnt, sum(amount) as total_purchase
FROM Customers c INNER JOIN Orders o ON c.customer_id = o.customer_id
GROUP BY 1
ORDER BY 2 DESC
),
ship_cnt as (
SELECT c.customers_id, count(distinct shipping_id) as ship_cnt
FROM Customers c INNER JOIN Shippings s ON c.customer_id = s.customer
WHERE status = 'Pending'
GROUP BY 1
ORDER BY 2 DESC
)
SELECT oc.customer_id, ord_cnt, total_purchase, COALLESCE(ship_cnt,0) as shipping_cnt
FROM odr_cnt oc LEFT JOIN ship_cnt sc on oc.customer_id = sc.customer_id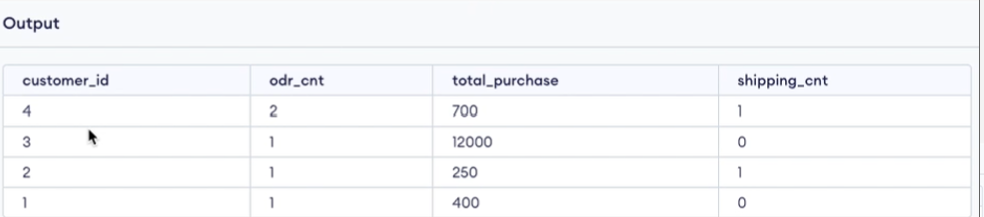
- 결과를 보면 customer_id로 결합이 잘 된 것을 볼 수 있음.
- 이처럼 WITH 구문 사용하면 복잡한 쿼리도 블록 단위로 작성할 수 있기 때문에 코드를 이해하기 훨씬 좋음
- 현업에서는 WITH 구문 적극 사용하는걸 권장!
📍 Subquery
-
Subquery는 쿼리 내부에 포함된 쿼리, 주로 더 큰 쿼리의 일부로 사용됨.
-
복잡한 조건을 사용하여 데이터를 추출하거나 다양한 테이블 간의 관계를 분석하는 등 다양한 쿼리 작업에 사용될 수 있음.
-
잘못 사용하면 리소스를 지나치게 많이 사용할 수 있음.
예시 1) SELECT 구문에서 Subquery 사용하는 경우
(실습)
유저별 평균 구매 가격과 전체 평균 구매 가격을 비교하기
SELECT user_name, AVG(price) as avg_price
FROM orders o INNER JOIN products p ON o.product_id = p.product_id
GROUP BY 1
ORDER by 2 DESC
-
우선 고객별 평균 구매 금액 쿼리를 작성해봄.
-
orders와 products 테이블을 결합하고 user_name으로 그룹화, 유저별로 구매한 평균 가격을 avg_price 컬럼으로 반환.
서브쿼리를 이용하여 전체 평균 구매가격인 total_avg_price 추가해보겠음.
SELECT user_name, AVG(price) as avg_price, (SELECT AVG(price) FROM orders o INNER JOIN products p ON o.product_id = p.product_id) as total_avg_price
FROM orders o INNER JOIN products p ON o.product_id = p.product_id
GROUP BY 1
ORDER by 2 DESC
예시 2) FROM 구문에서 Subquery 사용하는 경우
-
기존 방법대로 하면, 큰 테이블끼리 JOIN이 먼저 들어가기 때문에 리소스가 많이 쓰임.
-
서브쿼리 쓰면 JOIN 전에 필터링 먼저해서 테이블 크기 줄이고 JOIN 가능.
(실습)
스포츠, 주방용품을 담당하는 매니저들의 클릭 이력 가져오기
SELECT C.*
FROM (SELECT name FROM managers WHERE managing in ('스포츠', '주방용품')) a
INNER JOIN clicks c ON a.name = c.user_name
예시 3) WHERE 구문에서 Subquery 사용하는 경우
(실습)
가장 비싼 상품에 대한 클릭 이력 가져오기
SELECT C.*
FROM clicks c
WHERE product_id = (SELECT product_id FROM products ODER BY price DESC LIMIT 1)-
product_id가 서브쿼리와 일치하는 경우로 필터링.
-
서브쿼리는 price를 내림차순해서 하나만 뽑음(즉, 가장 비싼 상품).

-
위처럼 ALL 구문 사용해도 됨. ALL은 주로 서브쿼리에서 사용됨.
price값이 모든 값보다 크거나 같아야 참 반환. 즉, price가 최대일 때만 필터링.
ALL외에 ANY, SOME도 서브쿼리와 함께 사용됨.
예시 4) Subquery와 EXISTS를 같이 사용하는 경우
-
EXISTS는 앞에서 배운 IN 연산자와 비슷함. IN은 비교 대상이 되는 값들을 직접 입력했지만 EXISTS는 서브쿼리와 함께 사용.
-
EXISTS가 반환하는 값은 참 또는 거짓.
(실습)
매니저들 중에 상품을 구매한 사람이 있는 경우, 구매 테이블 전체를 출력하기
SELECT o.*
FROM orders o
WHERE EXISTS (SELECT user_name FROM orders o INNER JOIN managers m ON o.user_name = m.name)- 서브쿼리 결과로 TRUE가 반환되면 위쪽 쿼리도 실행이 되고 FALSE가 나오면(=서브쿼리 결과가 없는 경우) 전체 쿼리 결과도 출력되지 않음.
🟨 다양한 SQL 함수 다루기
📍 타임스탬프 함수
타임스탬프 함수는 현재 시간을 구하거나 날짜 간 차이를 구할 때 사용.
타임 스탬프를 배우기에 앞서 SQL에서 시간을 표시하는데 사용하는 데이터 타입에 대해 배워보자
SQL에서 날짜와 시간 관련 데이터 타입
-
STRING : ‘yyyy-mm-dd’, ‘yyyy-mm-dd HH:MM:SS’
-
가장 단순하게 시간 데이터 저장할 수 있는 방식이며 형식에 제한이 없음.
-
그러나 날짜를 더하거나 빼거나 요일을 구하는 등 시간 관련 함수를 사용하지 못한다는 단점이 있음.
-
-
DATE : yyyy-mm-dd
-
년, 월, 일 정보만을 저장하며 시간단위 까지는 저장하지 않음.
-
DATETIME, TIMESTAMP보다 저장공간을 덜 차지함.
-
정확한 시간까지 저장할 필요가 없을 때, 대규모 데이터를 저장해야하는 경우 저장공간 절약할 수 있음.
-
-
DATETIME : YYYY-MM-DD HH:MM:SS
-
날짜와 시간정보를 모두 저장하며 정밀한 시간정보를 제공함.
시간정보를 초 단위까지 저장해야하는 경우에 보통 사용함.
-
시간간의 연산이 가능하기 때문에 시간 간격을 고려한 데이터 분석이 가능.
-
DATE보다 더 많은 정보를 저장하니까 저장공간이 더 필요함.
-
-
TIMESTAMP : YYYY-MM-DD HH:MM:SS UTC
-
DB 종류에 따라 표기 방법이 다름.
MySQL의 경우 DATETIME과 비슷하지만 맨 뒤에 타임존이 붙음.
-
저장할 수 있는 범위가 DATETIME보다 제한적이며 저장공간을 더 적게 차지함.
-
시간 연산이 용이함.
-
타임스탬프 함수 - 현재 시간
-
NOW() : MySQL 서버의 시간을 가져오는 함수. 쿼리문이 실행되는 시점의 시간을 반환.
-
CURRENT_TIMESTAMP() : NOW와 동일
-
CURTIME() : DB마다 다르지만 서버의 시간만을 반환하거나 날짜도 포함해서 반환하는 경우도 있음.
-
CURRENT_DATE() = CURDATE() : 현재 날짜를 반환하고 시간까지는 반환하지 않음.
-
-
SYSDATE()
-
NOW 함수와 거의 동일하지만 약간의 차이가 존재.
-
NOW와 CURRENT_TIMESTAMP는 쿼리가 실행되는 시점을 반환하지만 SYSDATE는 SYSDATE가 호출되는 시점을 기록.
-
-
YEAR()
-
날짜에서 년도 뽑아내는 함수.
-
input이 문자열로 들어와도 적용가능한 경우가 종종 있음.
-
-
MONTH()
- 날짜에서 월을 뽑아내는 함수.
-
DAY()
- 날짜에서 날짜를 뽑아내는 함수.
-
HOUR()
- 시간을 뽑아내는 함수.
-
MINUTE()
- 분을 뽑아내는 함수.
-
SECOND()
- 초를 뽑아내는 함수.
-
WEEKDAY()
- 요일을 반환하는 함수.
-
MONTHNAME() / DAYNAME()
-
각각 몇 월인지, 무슨 요일인지 영문으로 뽑아내는 함수.
-
잘 사용하지는 않고 이런게 있다 정도로 알고 있으면 됨.
-
타임스탬프 함수 - 날짜 형식화
-
STR_TO_DATE
- 문자열로 입력한 날짜를 날짜타입으로 바꿔주는 함수.
-
DATE_FORMAT
-
지정된 형식으로 날짜 출력.
-
지정된 형식은 다음 이미지 참고.

-
%M이면 월 이름이 영문으로 나옴.
-
타임스탬프 함수 - 날짜 연산
-
ADDDATE() : 특정 interval만큼 시간을 더하는 함수.
- DATE_ADD() : ADDDATE랑 같은 함수.
-
SUBDATE() : 특정 interval만큼 시간을 빼는 함수.
- DATE_SUB() : SUBDATE도 같은 함수.
-
CONVERT_TZ()
- 타임존을 변경하여 시간을 출력하는 함수.
-
DATEDIFF()
- 두 날짜 간의 차이를 일 단위로 반환하는 함수.
-
TIMEDIFF()
- 두 시간 간의 차이를 일 단위로 반환하는 함수.
-
TIME_TO_SEC()
- 시간을 초 단위로 바꾸어 반환하는 함수.
(실습)
- DATE_ADD 함수 사용
SELECT DATE_ADD('2023-11-01', INTERVAL 3 SECOND) as added
- CONVERT_TZ 함수 사용
SELECT CONVERT_TZ(NOW(), '+00:00', '+09:00') 
-
NOW는 지금 시간.
-
00:00은 from time zone, 09:00은 to time zone.
-
한국 시간은 UTC(영국시간)에서 9시간을 더해줘야하므로 다음과 같이 작성.
📍 타입 변환
-
필요성
-
SQL 쿼리문에서는 적재된 데이터를 타입변환해서 가져올 수 있음.
ex) 정수 타입으로 저장된 데이터를 문자열로 변환한 뒤 다른 테이블과 결합하는 경우
-
조직이 커지면 데이터를 적재하는 주체가 다양화 됨.
중요한 데이터는 중앙에서 관리한다고 하더라도 각 조직에서 니즈에 맞는 데이터를 적재한 뒤 대시보드를 만드는 등 활용하기 때문에 완전히 중앙 집권화 하기가 어려움.
따라서 같은 의미의 데이터라도 서로 다른 조직에서 데이터를 관리하는 경우에 데이터 타입이 불일치하는 경우가 발생.
데이터 간 비교를 하거나 결합할 때는 타입 변환 함수 써서 데이터 변환이 선행되어야함.
-
타입 변환 시에는 CAST와 CONVERT 사용하며 둘은 동일한 기능을 수행. 약간의 사용문법상의 차이가 존재.
-
(실습)
1.문자열을 정수 타입으로 바꾸기(CAST이용)
SELECT CAST('20231014' AS SIGNED INTEGER) as int_date 
-
컬럼값을 타입 변환 할 수도 있음.
orders 테이블에 있는 date값을 정수값으로 타입변환 해보기.
SELECT CAST(date AS SIGNED INTEGER) +3 as int_date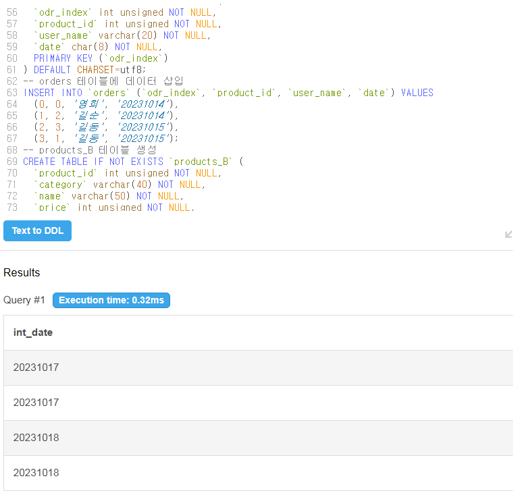
-
예제로 든거는 날짜이지만 정수로 변환했기 때문에 더한 결과 값이 10월 32일 이런식으로 나오는 결과 발생할수도 있음.
- 날짜 연산하는 경우에는 DATE_ADD 쓰는게 안전.
2.CONVERT 이용한 형변환
SELECT CONCAT(CONVERT(price, CHAR), ' ON SALE') as sale_price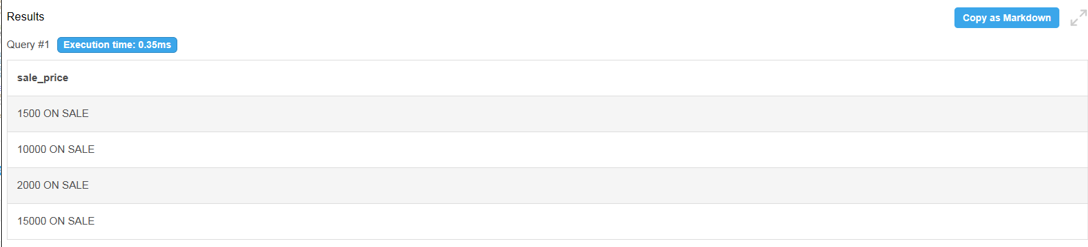
price를 문자열로 바꿔주고 다른 문자열과 CONCAT 한 예시.
3.UNION 이용하는 경우
날짜가 문자열 타입으로 들어가있는 orders 테이블과 날짜가 정수로 들어간 orders_v2 테이블이 있음.
SELECT *
FROM orders
UNION
SELECT *
FROM orders_v2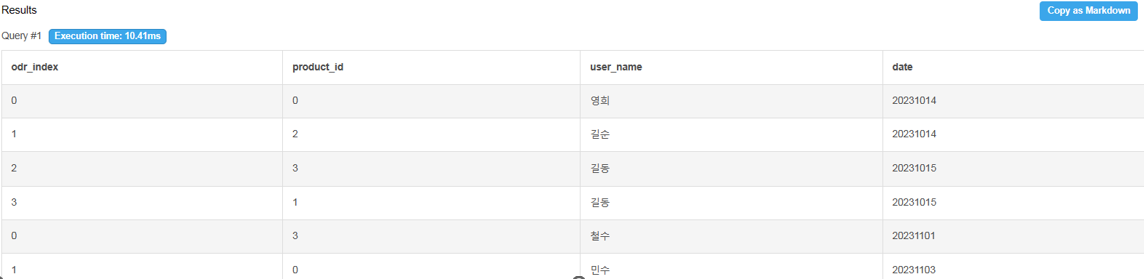
-
결과를 보면 orders테이블과 orders_v2 가 잘 붙은걸 확인할 수 있음.
-
원래 UNION은 데이터 타입과 컬럼 수가 같아야 실행되지만, 테이블이 합쳐질 때 DB에서 형변환이 자동으로 이루어져서 합쳐졌음.
-
그러나 자료형이 다른걸 알고 사용해야함!
📍 조건절
- 조건절은 조건에 따라 데이터를 처리,반환하기 위해 사용.
-
조건을 정의하고 조건이 참일 때와 거짓일 때 다르게 처리하기 위해 사용.
-
IF와 CASE WHEN을 주로 사용.
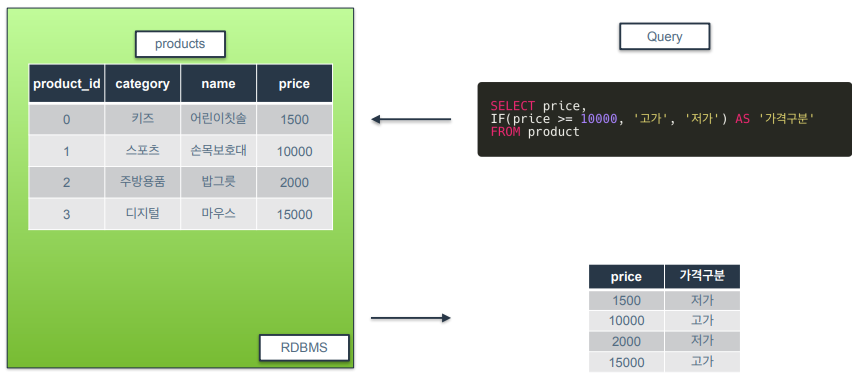
IF
IF(조건, 참일 때 반환 값, 거짓일 때 반환 값)- 예시)
(실습)
1.IF를 여러 개 사용해보기
SELECT name,
IF(manaing IN ('스포츠', '디지털'), '3층', '2층') as floor,
IF(off LIKE '%토%', '토요일 휴무', '토요일 근무') as sat_off
FROM managers
-
managing이 스포츠, 디지털에 포함되면 3층 아니면 2층을 반환.
-
두번째 조건은 off 컬럼에 '토'라는 글자가 있으면 토요일 휴무를 반환 아니면 토요일 근무를 반환.
2.상품을 고가와 저가의 클릭 횟수를 유저별로 계산해보기
SELECT product_id,
IF(price > 10000, '고가', IF(price > 5000, '중가', '저가')) as price_class
FROM product_B이러한 서브쿼리를 써서 product에서 price를 그냥 가져오는게 아니라 price class로 구분해서 가져옴.
SELECT user_name, price_class, count(1) as cnt
FROM clicks c
INNER JOIN( SELECT product_id, IF(price > 5000, '고가', '저가')) as price_class FROM products) p
ON c.product_id = p.product_id
GROUP BY 1,2
ORDER BY 1,2
IFNULL
IFNULL(컬럼명, 어떤 값으로 채울지)-
값이 null 일 때 지정한 값으로 반환하는 함수.
-
예시)
(실습)
1.매장에서 근무하는 매니저들의 구매이력 추출하기
SELECT name, IFNULL(odr_index,-1)
FROM managers m LEFT JOIN orders o ON m.name = o.user_name
GROUP BY 1
-
물건을 구매하지 않은 매니저들은 null값을 갖게 됨.
-
IFNULL 써서 -1 값으로 바꿈.
CASE WHEN
-
IF문과 마찬가지로 조건에 따라 데이터를 처리하기 위한 구문.
-
IF문과 쿼리 작성방법이 다름.
-
중첩하지 않아도 3개 이상의 조건 구간으로 분기 가능.
-
예시)
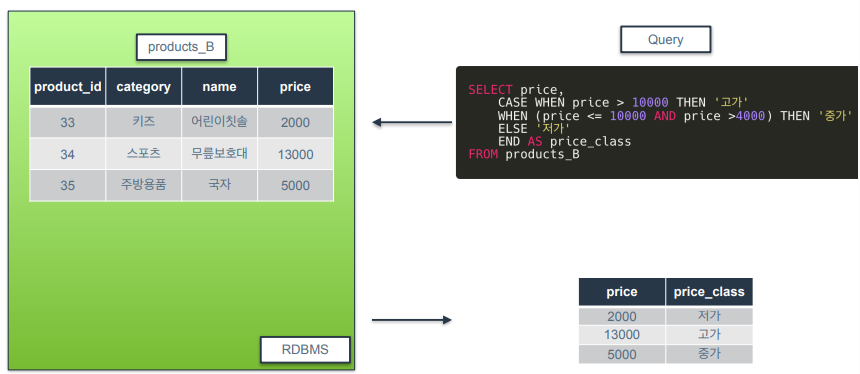
- END AS 컬럼명 ➡️ CASE WHEN문 끝낸다는 의미
(실습)
1.CASE WHEN을 WHERE절에 사용하기
SELECT *
FROM products
WHERE ( CASE WHEN category = '키즈' THEN 1
WHEN name LIKE '%어린이%' THEN 1
WHEN name LIKE '%보호대%' THEN 2
WHEN category = '디지털' THEN 2
ELSE 3
END
) = 1- 기존 WHERE 구문보다 뭐가 편할까?
➡️ 조건이 복잡하게 얽혀있을 때 편함. 조건들을 주석처리 하지 않아도 됨(?)
2.CASE WHEN을 ORDER BY절에 사용하기
SELECT *
FROM products
ORDER BY(
CASE
WHEN category = '디지털' THEN 1
WHEN category = '주방용품' THEN 2
WHEN name LIKE '%보호대%' THEN 3
ELSE 4
END
)
- 단순 컬럼에 대한 오름차순, 내림차순이 아니라 직접 반환순서를 정하고 싶을 때 유용.
3.CASE WHEN을 중첩하여 사용하기
SELECT category, name, price
CASE date WHEN '20231014' THEN
CASE WHEN price > 5000 THEN '첫째날-고가'
ELSE '첫째날-저가'
END
ELSE
CASE WHEN price > 5000 THEN '둘째날-고가'
ELSE '둘째날-저가'
END
END as date_price_class
FROM clicks c INNER JOIN products p
ON c.product_id = p.product_id
📍 그 외 유용한 함수
RANK()
-
특정 컬럼을 기준으로 등수를 매기는 함수.
-
예를 들어 고객이 각 상품에 대해 가지고 있는 관심도를 점수화해서 가지고 있다면 고객별 관심점수가 높은 5개 상품만 홈 화면에서 추천 시 사용가능.
-
dense_rank() : 동점인 순위가 있을 때 수를 건너뛰지 않고 빽빽하게 채워서 순위를 하나씩 올리는 함수
-
percent_rank() : 몇퍼센트의 다른 값들이 지금 보고있는 값보다 작은지 비율로 나타내는 함수(0.75라고하면 75%의 값이 보고있는 값보다 작다는 의미).
-
MySQL 8 이상부터 지원하는 환경에서 실행해야함.
(실습)
1.강의자료 예시
SELECT age,
rank() over (ORDER BY age) as asc_rank,
rank() over (ORDER BY age DESC) as desc_rank,
dense_rank() over (ORDER BY age) as dense_rank,
percent_rank() over (ORDER BY age) as percent_rank
FROM Customers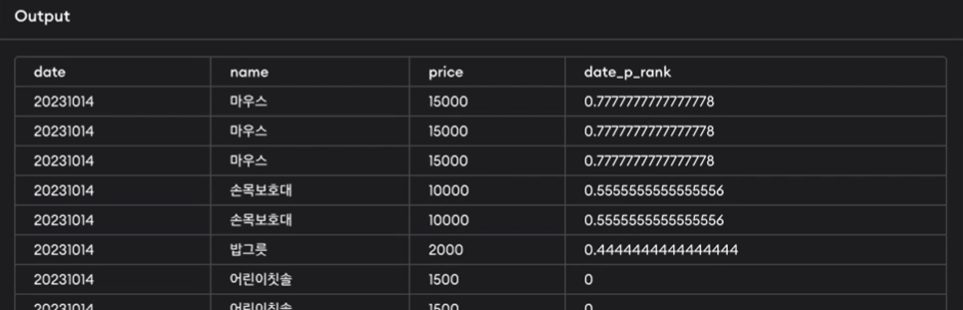
2.클릭이 일어난 상품 중 날짜별로 해당 상품이 얼마나 비싼지 percent_rank로 표시하기
SELECT date, name, price, percent_rank() over(partition by date ORDER BY price) as date_p_rank
FROM clicks c INNER JOIN products_B ON c.product_id = p.product_id
ORDER BY 1,3 DESC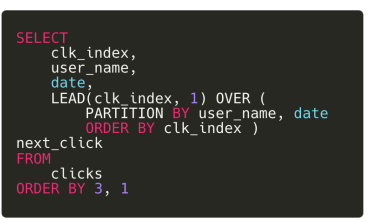
-
percent_rank를 구하되 date를 기준으로 파티션을 먼저 나누고 price순으로 정렬(날짜가 같은 경우 price로 정렬하겠다는 의미)
-
0.777777~ 값은 어떻게 나왔나?
➡️ 231014에서 클릭은 총 10개가 있는데 자기자신을 제외한 9개 값 중 7개가 price가 작음. 따라서 7/9해서 0.77777~ 가 나온 것.
LEAD()
-
파티션 내에서 다음에 올 값을 찾는 함수.
-
예시)
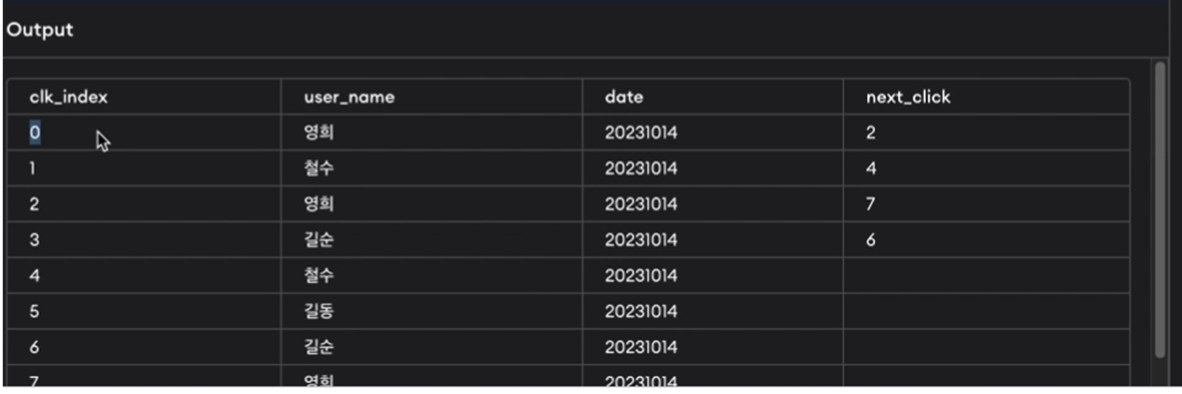
-
lead함수가 가져올 컬럼은 clk_index이고 1이 들어갔으므로 바로 다음에 오는 값을 가져옴.
-
rank처럼 파티션과 순서가 중요함. 예시에서는 user_name, date로 먼저 파티션을 함.
-
lead 함수 결과물을 next_click으로 반환.
-
(실습)
강의자료 예시
SELECT clk_index, user_name, date,
LEAD(clk_index,1) OVER (partition by user_name, date ORDER BY clk_index) next_click
FROM clicks
ORDER BY 3,1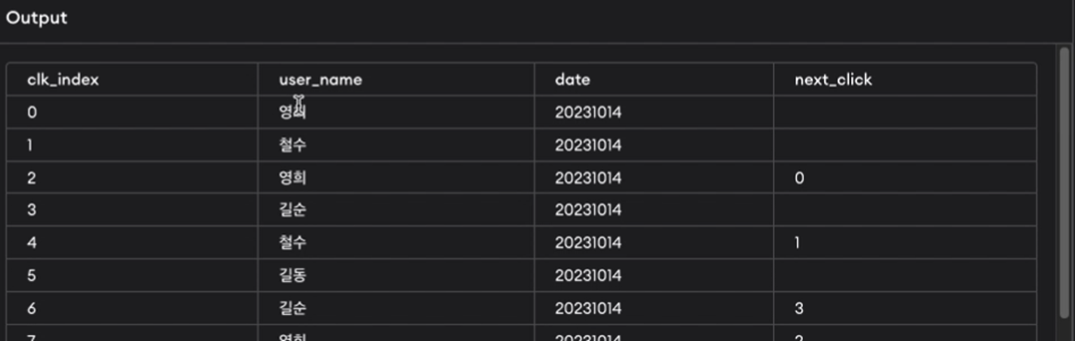
-
0번 click의 next_click은 2번.
-
lead 함수와 파티션을 활용하여 고객 행동 흐름을 파악할 수 있음.
-
예를 들어 첫번째 클릭한 제품과 두번째 클릭한 제품 가격을 비교해서 고객이 더 싼 물건을 찾고 있는지와 같은 흐름을 파악할 수 있음.
LAG()
-
LEAD와 비슷하지만 그 반대.
-
LEAD가 파티션 내에서 그 다음에 올 값을 찾는 거였다면 LAG는 그 전에 어떤 값이 왔는지 찾는 함수.
(실습)
강의자료 예시
SELECT clk_index, user_name, date,
LAG(clk_index,1) OVER (partition by user_name, date ORDER BY clk_index) next_click
FROM clicks
ORDER BY 3,1지금까지 설명한 함수를 window 함수라고 함.
이번에는 시간 다루는 함수, 타입 변환, 조건절, window 함수까지 다루었음.
