🟨 다양한 데이터 타입 다루기
📍 숫자
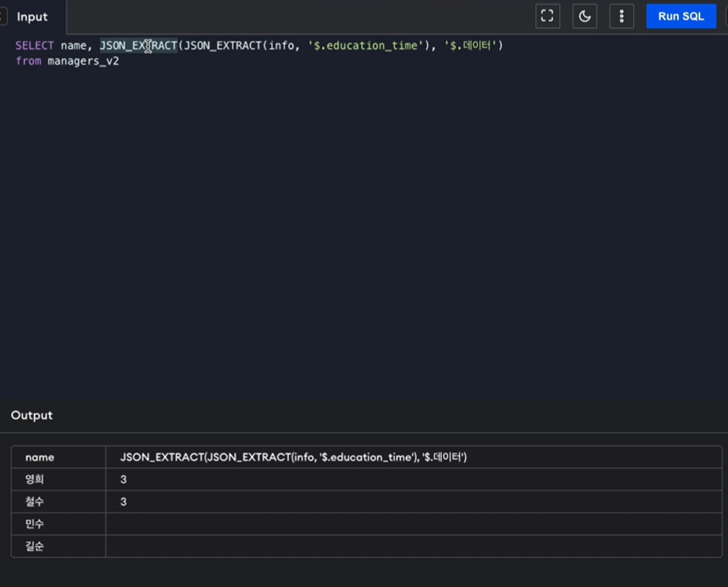
MySQL은 다양한 숫자 데이터 타입을 제공함.
BIT(M)
-
0과 1로 이루어진 비트만을 저장함. 컴퓨터는 0과 1의 비트로 이루어져 있고 0과 1로 모든 값을 저장/처리 함.
-
비트는 컴퓨터가 데이터를 저장하는 기본단위라고 할 수 있음.
-
BIT(M)에서 M은 몇 비트를 쓸지를 의미. 1이 기본 값이고 64까지 가능.
ex) M = 4 이면, 0000, 0001, 0010 이런식으로 4개의 값을 담게 됨
TINYINT
-
매우 작은 정수를 담을 때 사용.
-
기존 INT 타입에 비해 작은 저장공간을 차지함.
-
8비트까지 사용할 수 있고 범위는 -127 ~ 127 또는 0 ~ 255.
BOOL
-
참/거짓을 담기 위해 사용.
-
BOOL은 TINYINT(1)와 같음. 이 값이 0이면 False, 1이면 True.
SMALLINT
-
대략 6만개의 정수를 표현할 수 있는 정수 데이터 타입.
-
16비트까지 사용 가능.
MEDIUMINT
-
대략 1670만개의 정수를 표현할 수 있음.
-
24비트까지 사용 가능.
INT
-
일반적으로 사용하는 정수를 표현할 수 있음.
-
32비트까지 사용 가능하며 약 42억 9천만 정수를 표현할 수 있음.
BIGINT, SERIAL
-
INT 타입보다 2배 많은 비트를 사용.
-
BIGINT 중 부호가 없는 걸 SERIAL이라고 부름.
DECIMAL(M,D)
-
고정 소수점 타입.
-
M은 숫자 전체 자리 수, D는 소수점 이하 자리 수
-
소수점 이하 자리 수를 미리 고정하고 고정된 자리 수로만 소수점을 표현함.
FLOAT
-
부동 소수점 타입.
-
4 바이트, 즉 32비트 사용.
DOUBLE
-
FLOAT보다 더 큰 부동 소수점 타입.
-
8 바이트, 즉 64 비트 사용.
현업에서는 디테일하게 나누어서 사용하지는 않음.
BOOLEAN, INT, DOUBLE을 자주 사용.
(실습)
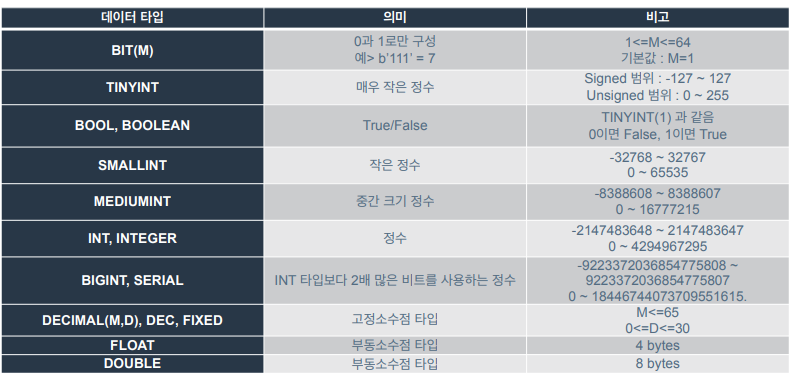
1. 우선, IF문 활용해서 숫자와 TRUE, FALSE 간의 관계를 확인해봄.
-
0은 FALSE로 간주되기 때문에 FALSE가 반환됨.
-
1이면 TRUE로 간주되기 때문에 TRUE가 반환됨. 1 아닌 다른 수 넣어도 참으로 간주해서 TRUE가 반환(음수 넣어도 동일).
-
조건이 2=TRUE이면 2=1이라고 쓴 것과 동치이기 때문에 FALSE 반환.
2.기존에 실습했던 products 테이블에서 price는 원래 INT 타입이었으나 이번에는 TINYINT로 바꿔서 해봄

-
이렇게 작성하면 오류남. price에 들어간 값들이 양수라 하더라도 범위가 255까지인데 그걸 넘기 때문.
-
따라서 넣어주는 값을 조정하면 스키마 빌드 에러 x

- price에 소수점을 넣어주면 DB마다 다르긴 하지만 알아서 반올림해서 결과를 보여줌.
📍 문자
CHAR
-
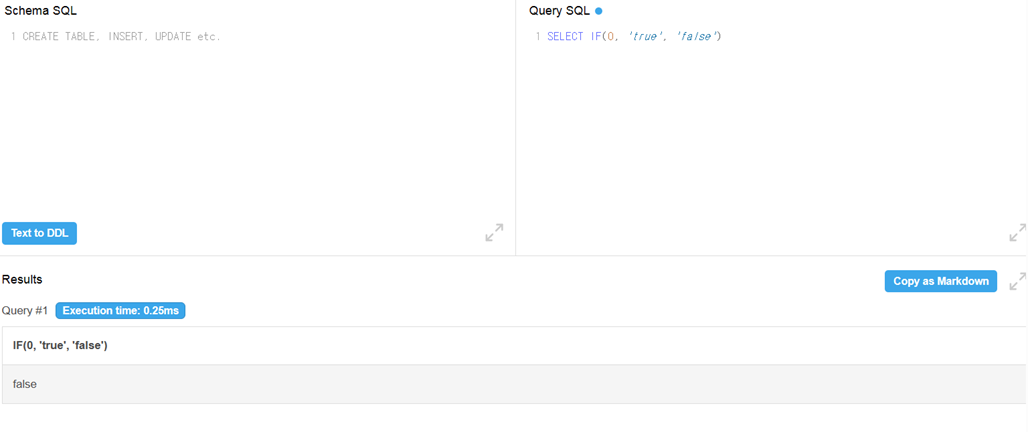
고정된 길이의 문자열.
-
선언된 길이보다 짧은 문자열이 들어와도 빈 문자열로 남은 문자열 채움.
VARCHAR
-
변동 가능한 길이의 문자열.
-
길이 0 ~ 65,535 바이트
-
이는 MySQL에서 한 행이 가질 수 있는 총 길이와 동일. 다른 컬럼들의 데이터도 저장하려면 한 컬럼이 한 행이 쓸 수 있는 전체 공간을 다 쓰면 안됨.
➡️ 따라서 실제로는 65,535 바이트보다 짧은 문자열이 담겨야 함. -
VARCHAR은 데이터가 몇 바이트짜리인지 정보를 담는데 추가적인 바이트를 사용
➡️ 문자열 크기가 255 바이트 이하이면 1바이트 사용, 더 크면 2바이트 사용. -
DB마다 다르지만 길이를 초과하는 문자열이 들어오면 일반적으로는 INSERT시 에러가 발생.
TEXT
-
변동 가능한 길이의 문자열.
-
VARCHAR과 다르게 길이 지정 불가능. 최대 길이만 안넘으면 문자열 길이에 상관없이 집어넣는 방식.
-
쿼리 시 메모리가 아니라 디스크를 사용
➡️ 따라서 CHAR, VARCHAR(메모리 사용)보다 쿼리문 반환이 느림.
TINYTEXT
-
TEXT이지만 더 짧은 TEXT 저장.
-
최대 255 바이트까지 저장 가능.
MEDIUMTEXT
- 최대 길이가 1670만 바이트 문자열 저장 가능
LONGTEXT
- 최대 길이가 42.9억 바이트 문자열 저장 가능
ENUM
-
제한된 값 리스트를 미리 작성하고 그 안에 있는 값만 삽입할 수 있도록 하는 타입(컬럼 타입을 지정할 때부터 들어갈 수 있는 값 리스트를 지정).
-
없는 값을 테이블에 INSERT 하면 에러 발생(DB설정마다 다르지만 없는 값 넣으면 빈 값 들어가는 경우도 존재).
-
ENUM은 훨씬 적은 저장소 용량으로 동일한 데이터를 저장할 수 있다는 장점이 있음
ex - 만약 강아지, 고양이, 원숭이 이렇게 3가지 값만 가지는 컬럼이 있다고 할 때, 데이터가 테이블에 들어오면 실제 문자열을 저장하는게 아니라 해당 값에 매핑되는 더 짧은 문자열을 저장(강아지는 0, 고양이는 1, 원숭이는 2 이런식!)
-
현업에서 사용할 수 있는 경우는 많지 않음(유연성과 확장성이 낮기 때문. 데이터에 변동이 있으면 대응하기가 어려움).
SET
-
ENUM과 비슷하게 처음 가능한 값 리스트를 제한함. 그러나 ENUM과 다르게 0개 혹은 여러개의 값이 올 수 있음.
ex - 만약 강아지, 고양이, 원숭이 값으로 제한했을 때 빈 문자열이 들어와도 괜찮고 강아지,고양이가 들어와도 괜찮고 고양이, 원숭이도 괜찮음
즉, 가능한 값 리스트의 모든 조합이 올 수 있음(순서는 무시).
(실습)
1. name 컬럼값을 4글자로 제한해보기
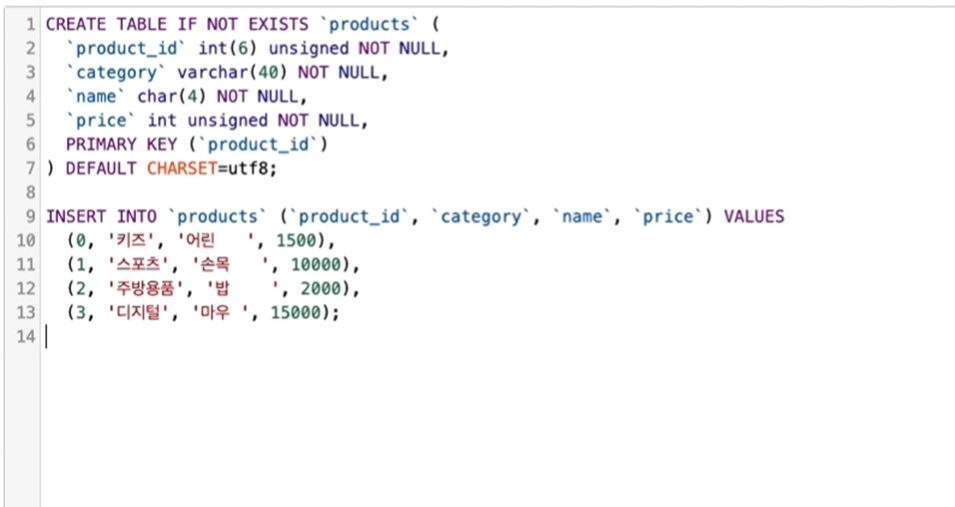
- 길이 넘는 문자열을 INSERT 해주면 스키마 빌드에 에러 발생.
- 공백이 들어가는 경우는 에러 x.
2.공백이 저장되는지 확인해보기
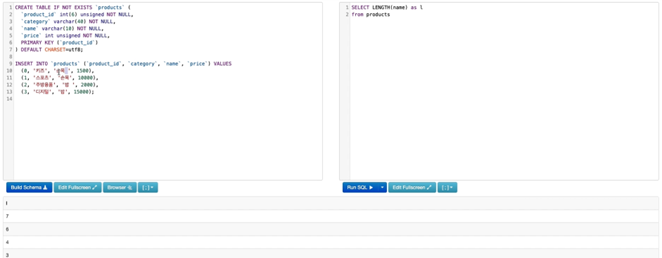
-
공백이 저장되는 것을 확인할 수 있음. 지정된 타입길이 이내이면 공백도 같이 저장됨.
-
한글은 한글자에 3바이트, 영문은 1바이트 차지. 따라서 한글 두글자에 공백하면 7바이트가 됨.
📍 이진
-
이진 데이터 타입과 문자 데이터 타입을 나누어서 설명하지만 MySQL 공식 문서에서는 묶어서 설명하고 있음.
ex) BLOB과 TEXT를 같이 설명함(그만큼 비슷해서)
-
Binary 파일은 데이터를 저장하거나 활용하기 위해 0과 1의 이진 형식으로 인코딩해둔 파일을 의미.
-
근본적으로는 0과 1로 이루어진 데이터이지만 이진형식을 표시할 때 16진법으로 표시하기도 함. 즉, binary 타입은 다른 데이터 타입을 포함하는 개념.
ex) TEXT 파일은 binary 파일에 포함되지만 binary 파일이라고 꼭 TEXT 파일인 것은 아님. 이미지일수도 있고 숫자일수도 있음.
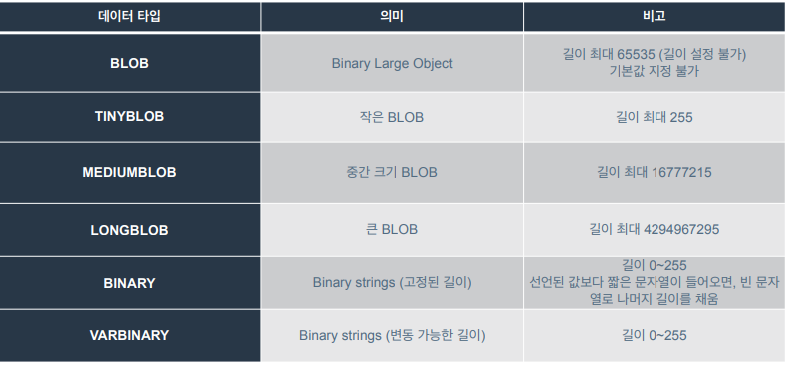
BLOB
-
문자열 뿐만 아니라 데이터 무엇이든 집어넣는 타입.
-
TEXT와 마찬가지로 최대 길이는 65,535로 기본값은 지정할 수 없음.
TINYBLOB
- 최대 길이가 255 바이트인 BLOB
MEDIUMBLOB
- 최대 길이가 1677만 바이트인 BLOB
LONGBLOB
- 최대 길이가 42.9억 바이트인 BLOB
BINARY
-
BINARY와 VARBINARY는 CHAR과 VARCHAR의 binary 버전.
-
저장되는 형태와 길이 설정 방식이 다름.
VARBINARY
-
변동 가능한 길이
-
VARBINARY와 BLOB의 관계는 VARCHAR과 TEXT의 관계랑 비슷함.
(실습)
1. name 컬럼 타입을 binary(6)으로 설정해보면, 에러가 나게 됨.
왜? 괄호 안은 글자수가 아니라 바이트를 의미하기 때문.
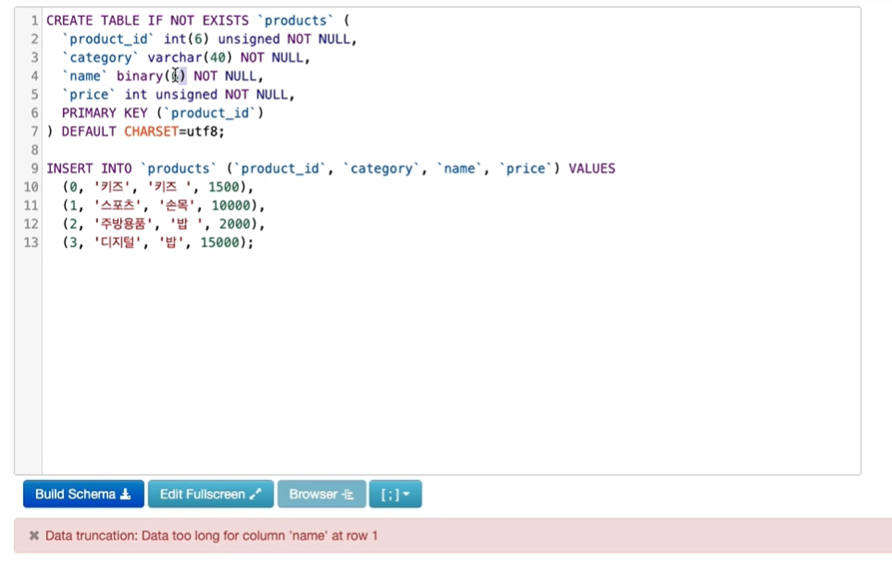
- 한글은 한글자당 3바이트이고 공백은 1바이트이기 때문에 에러가 발생.
- binary(7)로 바꾸면 에러 발생 x.
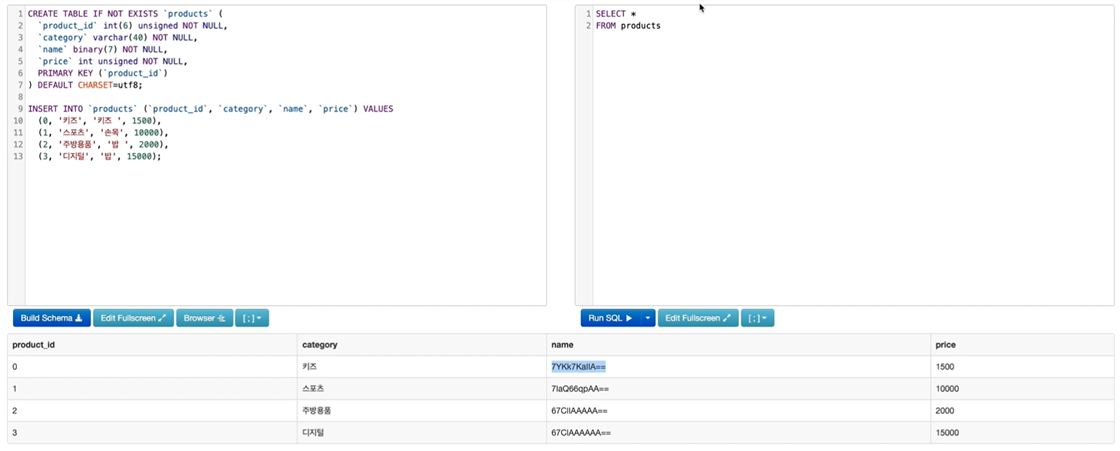
- 이때 name 컬럼은 binary strings로 들어가 있음을 확인 가능
2.CAST함수를 써서 name컬럼을 binary에서 char 형태로 바꿀 수 있음.
SELECT CAST(name as char) as str_name
FROM products📍 배열(Array)
-
배열은 array라고 하며 데이터가 저장된 리스트.
ex) ['a', 'b', 'c'] , [1, 2, 3]
-
배열에 저장된 각 데이터를 element라고 하며 원소라고 부름.
-
MySQL에서는 컬럼에 배열 데이터를 저장할 수 있는데, 이 때 JSON 타입을 사용. 이 경우를 JSON ARRAY라고 부름.
-
JSON 타입으로 저장할 수 있는 데이터 형태가 다양하기 때문에 기본값 설정은 불가능.
JSON_ARRAY
-
입력을 JSON 배열로 반환하는 함수
-
INSERT, SELECT 구문에서 주로 사용
-
예시를 보면 options 컬럼을 JSON 타입으로 지정. INSERT 구문을 보면 JSON ARRAY 함수에 배열의 원소가 될 값들을 넣어주었음.
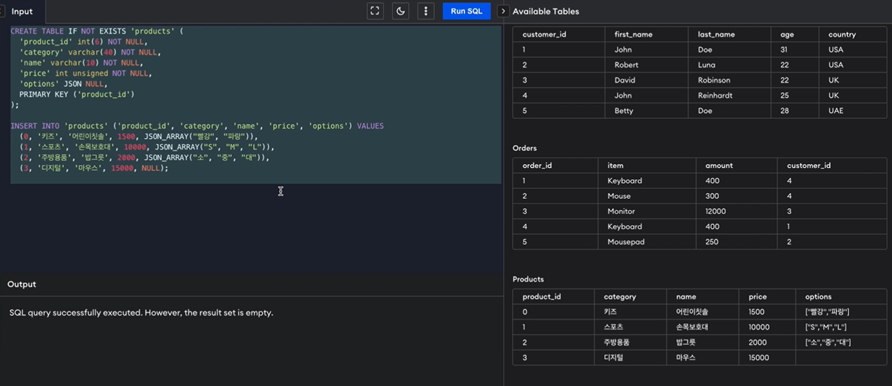
-
JSON ARRAY 안쓰고 다른 방식으로 배열 데이터 넣을 수도 있음
➡️ 직접 '["빨강", "파랑"]' 으로 넣어주는 방식INSERT INTO 'products' ('product_id', 'category', 'name', 'price', 'options') VALUES (0, '키즈', '어린이칫솔 ', 1500, '["빨강", "파랑"]'), (1, '스포츠', '손목보호대', 10000, '["S", "M", "L"]'), (2, '주방용품', '밥그릇', 2000, '["소", "중", "대"]'), (3, '디지털', '마우스', 15000, NULL);- 배열 전체를 감싸는 따옴표는 홑 따옴표(' ')이고 그 안의 문자열을 감싸는건 쌍 따옴표(" ")임을 유의! 따옴표 제대로 안쓰면 에러 발생.
-
(실습)
배열안에 원소에 배열이 들어가는 경우 ➡️ Nested Array
CREATE TABLE IF NOT EXISTS 'products' (
'product_id' int unsigned NOT NULL,
'category' varchar(40) NOT NULL,
'name' varchar(10) NOT NULL,
'price' int unsigned NOT NULL,
'options' JSON NULL,
PRIMARY KEY ('product_id')
);
INSERT INTO 'products' ('product_id', 'category', 'name', 'price', 'options') VALUES
(0, '키즈', '어린이칫솔 ', 1500, JSON_ARRAY("빨강", "파랑")),
(1, '스포츠', '손목보호대', 10000, JSON_ARRAY("S", "M", "L")),
(2, '주방용품', '밥그릇', 2000, JSON_ARRAY("소", "중", "대")),
(3, '디지털', '마우스', 15000, JSON_ARRAY(JSON_ARRAY("흰색", "파랑"), JSON_ARRAY("초록", "보라"), JSON_ARRAY("갈색", "검정")));JSON_TYPE
-
JSON 데이터 타입을 반환하는 함수
-
위의 실습을 JSON TYPE을 써서 확인해보기
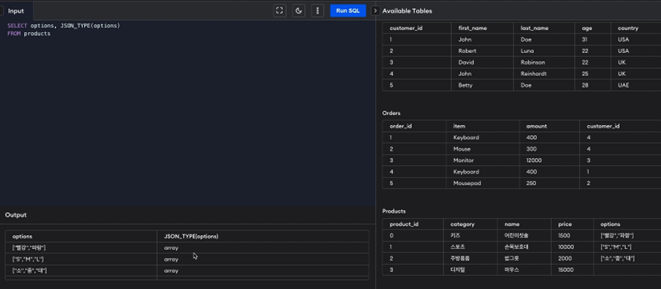
- 마지막 행 NULL 값 빼고는 array로 잘 들어간 것을 확인할 수 있음.
JSON_EXTRACT
-
array 내부의 데이터에 접근할 수 있음.
-
배열 내부의 데이터에 인덱스를 통해 접근하는 것을 인덱싱이라고 함.
-
첫번째 예시는 JSON 타입의 options 컬럼에서 모든 값을 꺼내오는 예시
SELECT options, JSON_EXTRACT(options, '$') AS all_elements FROM products- $는 모든 원소를 가져옴
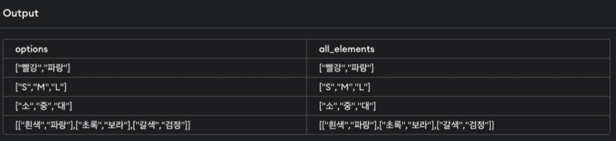
- $는 모든 원소를 가져옴
-
두번째 예시는 원하는 인덱스의 값만 꺼내오는 예시
SELECT options, JSON_EXTRACT(options, '$[0]') AS idx_elements FROM products- $[인덱스]는 해당 인덱스의 값만 가져옴
📍 구조체(Key-value)
-
key-value 데이터는 key와 value로 이루어진 데이터를 의미.
ex) {'이름' : '홍길동', '부서' : '개발팀', '직책' : '팀장', '근무지' : '판교'}
-
key는 데이터를 찾을 수 있는 기준이 되는 값, value는 key에 대응되는 값.
-
예시에서 이름은 key값, 홍길동은 value값.
-
MySQL에서는 key-value도 JSON 타입으로 저장하고 관리함.
JSON_OBJECT
-
key-value 입력값을 JSON 객체로 반환하는 함수
-
array에서 JSON ARRAY 사용한거와 유사하게 사용.
-
주로 INSERT, SELECT 구문에서 사용함.
-
JSON_OBJECT 입력시에는 key, value 순으로 입력
ex) JSON_OBJECT(키1, 값1, 키2, 값2, ...)
(실습)
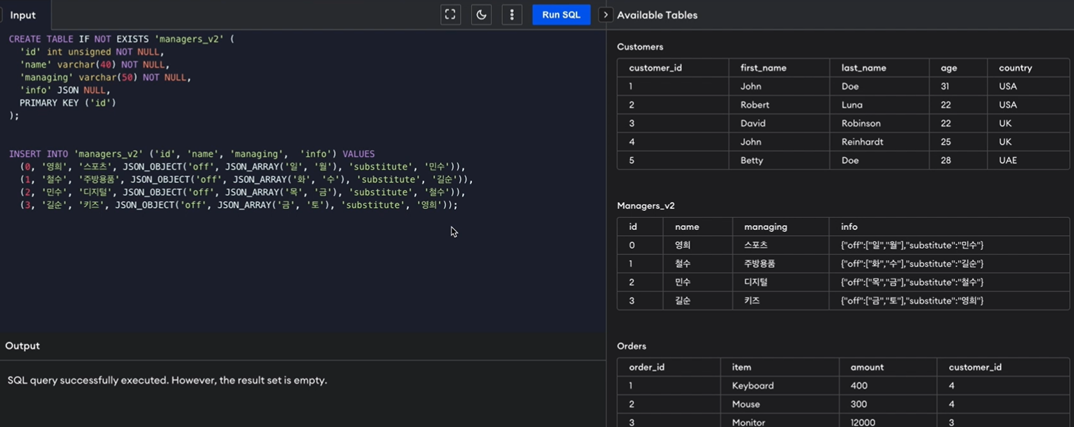
- info 컬럼에 키 값 off, substitute 넣어주고 각각에 해당하는 value가 잘 들어간 것을 확인할 수 있음.
JSON_EXTRACT
-
array에서 인덱싱 할 때는 $[인덱스] 해서 사용
-
key-value에서 JSON EXTRACT 써서 값 가져올 때는 $.key이름 하면 해당 키 값에 해당하는 value값 가져옴.
(실습)
위 예시에서 키 값이 off에 대응하는 value값을 불러옴.
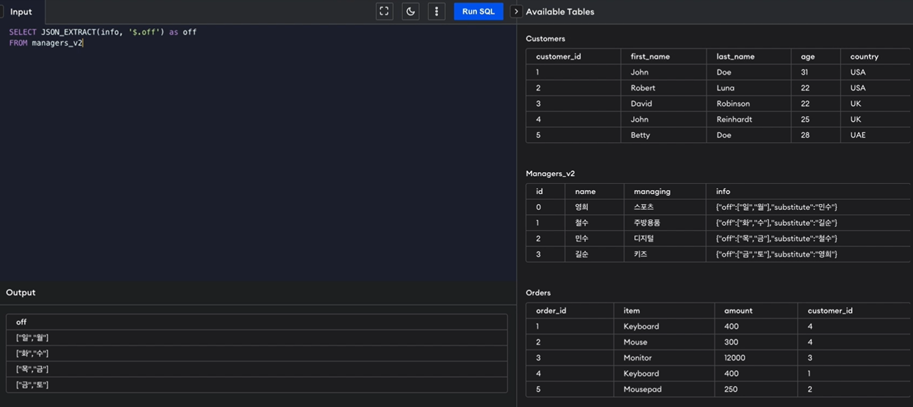
-
결과값이 array인데, 여기에 대해서 인덱싱 가능.
SELECT JSON_EXTRACT(info, '$.off[0]') as off_idx FROM managers_v2
JSON_INSERT
- key-value 쌍을 삽입할 때 사용
(실습)
managers_v2 테이블에서 info 컬럼에 새로운 key-value 삽입
UPDATE managers_v2 SET info = JSON_INSERT(info, '$.education_time', JSON_ARRAY(5, 10))- 새로운 컬럼인 education_time이 들어감

JSON_REPLACE
- 이미 있는 컬럼값을 바꾸는 함수
(실습)
새로운 key인 education_time에 대응하는 value값들을 update 함.
UPDATE managers_v2 SET info = JSON_REPLACE(info, '$.education_time', JSON_ARRAY(0, 10))- 값이 (5,10)에서 (0,10)으로 바뀐걸 확인할 수 있음.
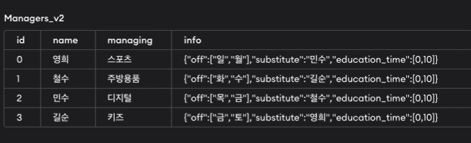
마지막으로, key에 대응되는 value로 array뿐만 아니라 key-value가 올 수도 있음(key-value에서 value에 해당되는 부분에 또 다른 key-value가 오는 형태).
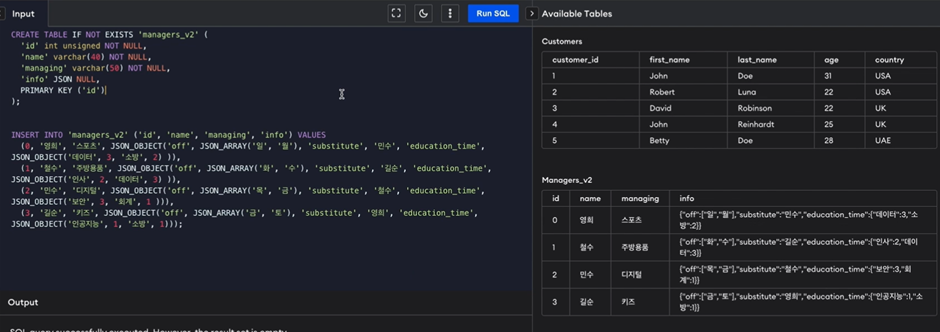
여기서 JSON_EXTRACT를 적용하면 안쪽 key에 대응되는 value값 추출 가능.