🟨 효율적인 SQL 코드 작성하기
📍 테이블을 집합으로 생각하기
-
테이블은 일반적으로 집합 개념과 대응됨.
집합 내 다양한 원소가 존재하고 각 원소의 특징은 컬럼값으로 구분할 수 있다는 의미. -
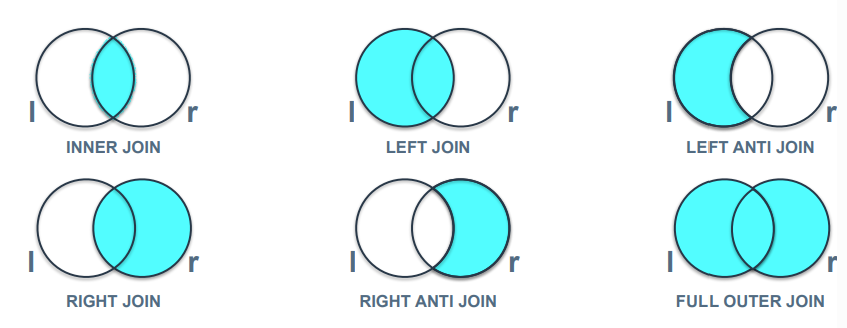
이전 강의에서 JOIN 정리 시 벤 다이어그램을 두고 설명했는데, 테이블을 집합 개념으로 생각하고 쿼리 작성하면 도움이 됨.
가장 대표적인게 WHERE을 통한 필터링.
필터링이 가능할 때 최대한 먼저 필터링을 해서 집합 크기를 줄여준 뒤에 다른 테이블과 JOIN 하는게 좋음.
-
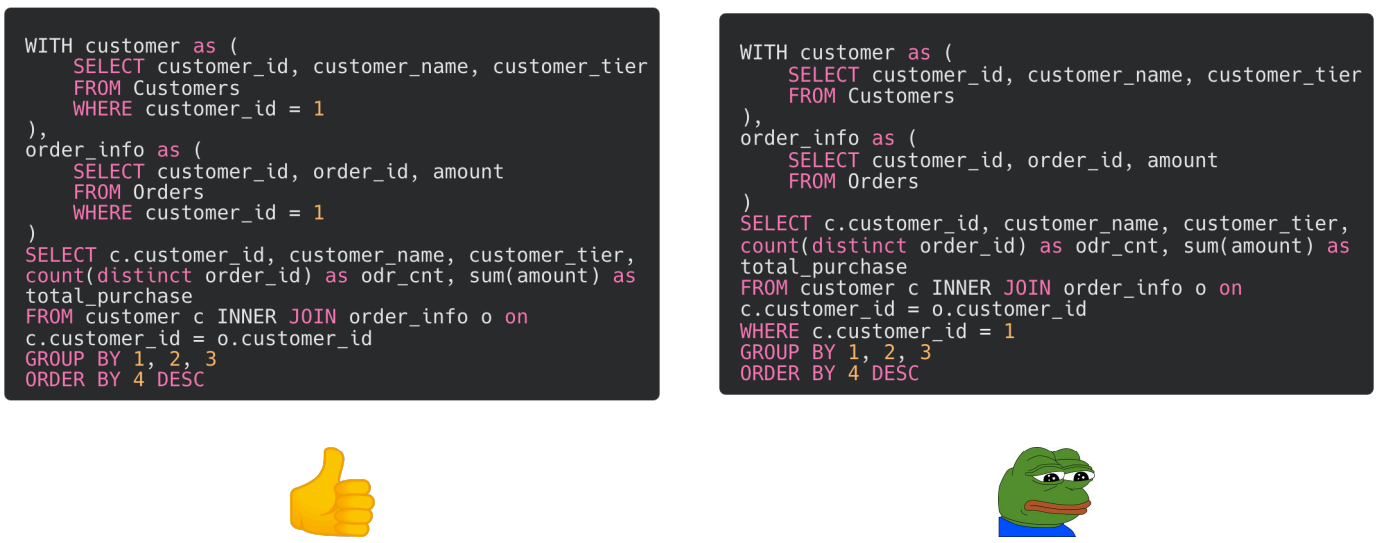
예제 쿼리를 보면 1번 고객의 주문이력을 고객정보와 결합해서 보고싶은 경우.
-
왼쪽 쿼리
-
customer 블록에서 고객정보를 가져올 때 customer_id = 1 로 필터링
-
order_info 블록에서 customer_id = 1로 필터링해서 구매이력 가져옴
-
2개의 블록을 JOIN해서 원하는 결과 얻음
-
-
오른쪽 쿼리
- 블록 내에서 필터링을 하지 않았고 마지막에 JOIN 시 customer_id로 필터링함
-
두 쿼리는 결과값을 같지만 실제로 실행해보면 왼쪽 쿼리가 더 빠름
-
-
(실습)
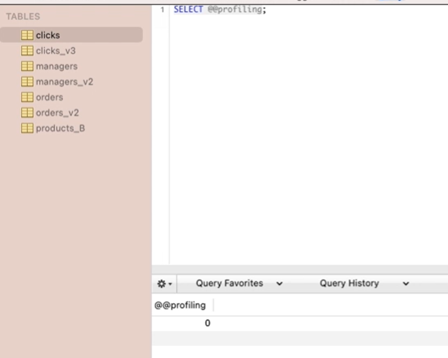
오늘은 쿼리 실행시간 비교해보기 위해서 온라인 실습 사이트가 아닌 강사님 로컬에 띄워놓은 maria DB로 진행.1.현재 프로파일링이 가능한지 체크하기
-
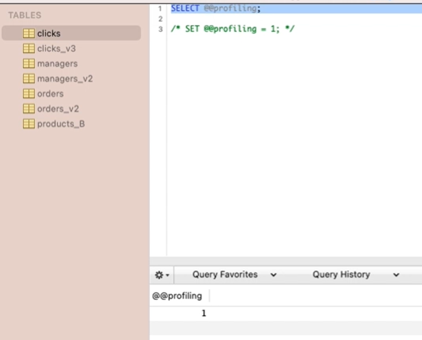
0은 프로파일링이 꺼져있다는 의미. 명령어를 입력해서 프로파일링을 켜줌.
-
쿼리 프로파일링은 쿼리 실행이 얼마나 걸리는지, CPU는 얼마나 사용하고 있는지 등 쿼리 실행에 대한 세부내용을 확인하는 것을 말함.
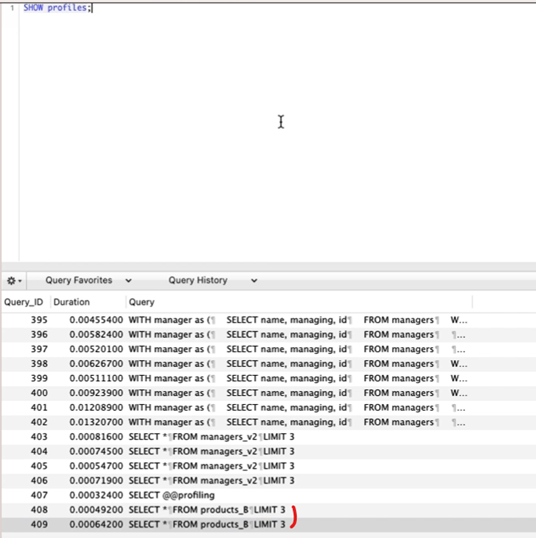
쿼리 실행하고
SHOW profiles;하면 프로파일링 내용이 나옴.
- 필터링 순서에 따른 쿼리 속도를 비교해보기
-
필터링을 블록 외에 조건에서 하는 경우와 블록 내에서 하는 경우를 비교
-
쿼리는 매니저 정보와 클릭이력을 결합하려고 하는 경우
우선 블록 외에서 manager id가 1번인 경우를 필터링 해봄(필터링을 나중에 하는 경우)
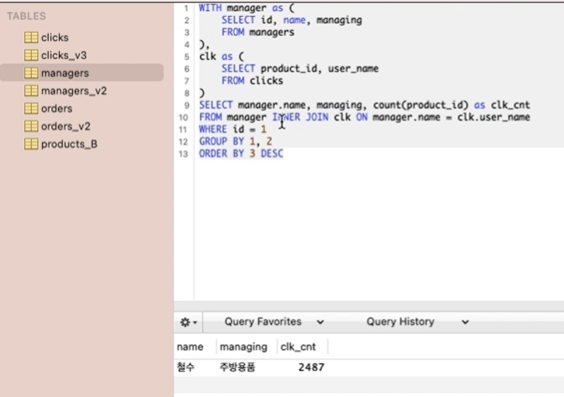
-
다음은 블록 내에서 필터링을 하는 경우(필터링을 먼저하는 경우)
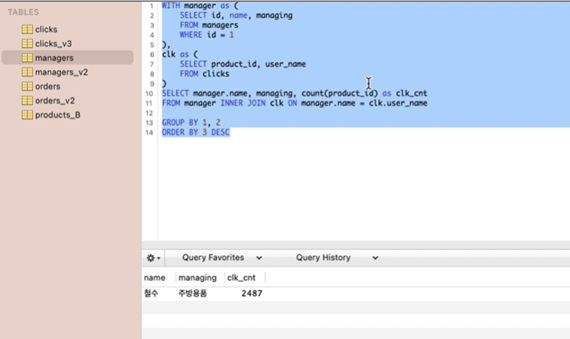
-
두 쿼리의 결과는 같지만 쿼리 실행속도에서 차이를 보임.
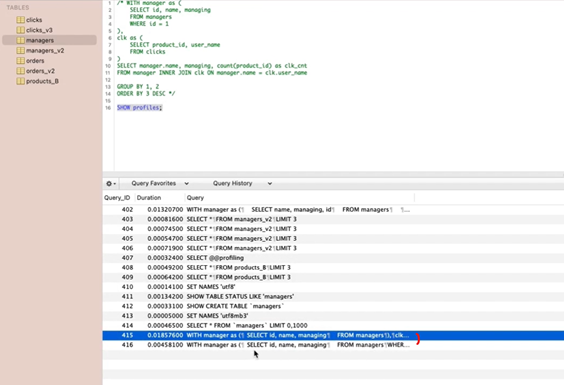
-
필터링을 먼저 한 경우(후자)가 더 빠르다는 것을 알 수 있음.
-
현업에서 다루는 테이블은 지금 다룬거보다 훨씬 크기 때문에 실행 차이가 더 커질 수 있음.
-
결론 : 테이블을 필터링으로 크기를 줄이고 다른 연산이나 JOIN을 하도록 쿼리를 작성하는걸 권장
-
-
📍 *, % 사용 지양하기
테이블을 조회할 때 *, % 기호를 제한적으로 사용해야함.
1) LIMIT 걸고 조회하기
SELECT product_id, category, name
FROM products
LIMIT 10-
새로운 테이블을 조회할 때 LIMIT 거는건 필수.
-
행 수가 100만개가 넘어가는 테이블이 있다면 LIMIT을 걸 때와 아닐 때의 차이가 큼.
2) 파티션이 있는 테이블인지 확인하고, 파티션을 필터 조건으로 걸고 조회하기
SELECT clk_index, user_name, product_id
FROM clicks
WHERE data = '20231104'
LIMIT 10- 파티션으로 테이블이 나뉘어져 있는 경우 WHERE 조건으로 파티션을 지정해주는게 필수.
- 예를 들어, 유저행동 로그 같은 경우 데이터가 쌓이는 양이 매우 많기 때문에 파티션을 나누어서 저장함.
- 파티션 지정 없이 조회하면 쿼리 폭탄이 되기 때문에 예시처럼 WHERE을 써서 파티션을 지정하면 좋음.
1번과 2번은 행 수를 제한적으로 select 하기 위함이었음.
이번에는 컬럼을 제한적으로 select 하는 경우.
3) 컬럼 수가 많은 테이블을 조회할 때 SELECT * 지양하기
SELECT product_id, category, name
FROM products
LIMIT 10- 알고싶은 컬럼만 지정해서 조회하는걸 권장.
4) LIKE 사용 시 % 제한적으로 사용하기
SELECT product_id, name
FROM products
WHERE name LIKE '23FW%'
LIMIT 10SELECT product_id, name
FROM products
WHERE name LIKE '23FW__'
LIMIT 10-
% 기호는 임의의 문자열 기호를 의미. 임의의 문자열 몇 개가 반복되어도 괜찮기 때문에 연산량이 커지게 됨
➡️ 따라서 규칙을 최대한 좁혀서 사용하는 것이 좋음. 예를 들어 23FW로 시작하는게 확실하면 뒤에 %만 붙일 수 있지만 뒤에 몇 글자인지 알고 있다면 언더바( _ )를 활용할 수도 있음
-
제한적인 규칙일수록 DB 리소스는 더 적게써서 더 효율적임.
-
% 남용하지 않고 규칙 찾아서 제한적으로 적용하면 더 효율적인 쿼리 작성 가능.
(실습)
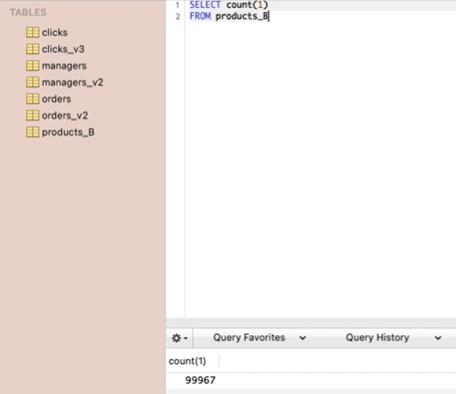
1. 우선 product_B의 테이블의 크기를 확인해봄(대략 10만개)
-
LIMIT를 걸지 않고 데이터를 하는 경우와 LIMIT를 걸고 데이터 조회하는 경우 비교
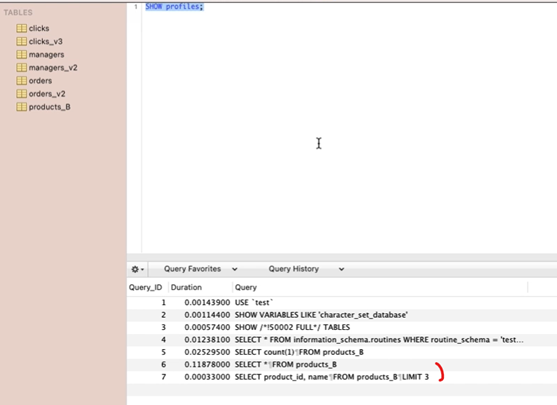
- 프로파일링 결과보면, 수행시간 차이가 크게 나는 것을 확인할 수 있음.
-
LIKE와 % 사용한 쿼리 비교
앞뒤로 % 사용한 경우와 뒤에만 %사용한 경우 비교
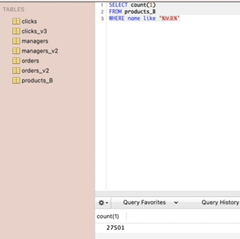
프로파일링 해본 결과는 다음과 같음.
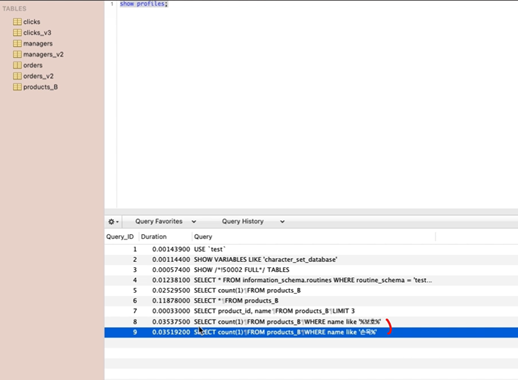
-
큰 차이는 아니지만 뒤에만 % 붙인 경우가 더 빠름.
-
이처럼 문자열을 조건으로 필터링 할 때 규칙을 제한적으로 사용하는게 좋음.
-
📍 데이터 타입 잘 확인하기
DB 설정에 따라 다르지만 묵시적 형변환을 지원함.
묵시적 형변환이란 비교하고자하는 두 값이 다른 타입일 때 타입을 알아서 DB가 맞춘 뒤 비교하는 것.
1) 비교 연산자를 쓸 때 타입 확인하기
SELECT count(1)
FROM clicks
WHERE date > '20231031'-
해당 쿼리에서 data가 string일 때 문자열과 비교해주어야 묵시적 형변환이 발생하지 않음.
-
묵시적 형변환이 발생하면 형변환에 걸리는 시간만큼 쿼리가 비효율적이게 됨.
-
또한 정확한 타입을 확인 안한 상태에서 쿼리가 복잡해지면 쿼리의 결과가 원하는대로 나오지 않았을 때 문제 원인을 찾는데 시간이 오래걸림.
-
따라서 비교 연산자를 쓸 때 타입 확인하고 동일한 타입끼리 비교하기를 권장
2) WHERE 절에서 왼쪽 컬럼에 함수 적용 지양하기
WITH clk as (
SELECT clk_index, event_index, date
FROM clicks
),
event as (
SELECT event_index, DATE_FORMAT(event_end, '%Y%m%d') as event_end_dt
FROM events
)
SELECT count(1)
FROM clk INNER JOIN event ON clk.event_index = event.event_index
WHERE date <= '20231031'
-
해당 예시는 이벤트에 관련된 상품을 눌러본 사람들 중 이벤트가 끝나기 전 클릭이 얼마나 일어났는지 알아보기 위한 쿼리.
-
클릭 이력과 이벤트 이력을 이벤트 인덱스 기준으로 결합을 했고, 클릭 날짜가 이벤트보다 작거나 같은 행만 필터링.
-
이 예시에서 주목할만한 부분은 DATA_FORMAT 함수가 어디에 쓰였는지.
-
DATA_FORMAT이 사용된 이유는 events와 clicks 테이블에서 날짜 형식이 다르기 때문에 맞춰주어야 비교가 되기 때문.
➡️ events에는 -가 들어간 상태로 날짜가 저장되어 있고, clicks에는 -가 없는 형태로 저장되어 있음.
해당 예시말고 WHERE 절에서 data에 DATA_FORMAT 함수를 적용할 수도 있음.
하지만 그렇게 사용하면 문제 발생.
-
WHERE절에서 컬럼에 함수를 사용하는 경우 인덱스를 사용할 수 없게 됨. 인덱스를 사용할 수 있는지 없는지에 따라 읽기속도가 많이 차이남.
-
큰 테이블 컬럼에 적용하면 함수가 실행되는 시간만큼 쿼리가 더 늦어짐.
-
꼭 함수를 써야한다면 더 작은 테이블에 적용하는게 좋음.
결론: 컬럼에 함수를 써야한다면 WHERE 절에서 왼쪽에 있는 컬럼에 쓰지않고 다른 방식으로 함수를 적용하는걸 권장.
(실습)
1. 묵시적 형변환을 알아봄
-
clicks 테이블에서 date 컬럼은 CHAR 타입.
-
CHAR 타입을 문자열이 아닌 정수랑 비교.
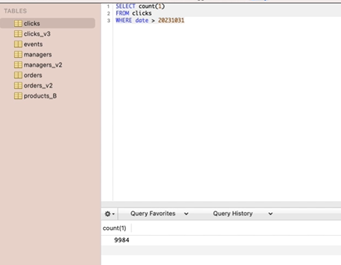
- 이런 경우 비교는 가능함.
-
CHAR 타입을 문자열 타입과 비교.
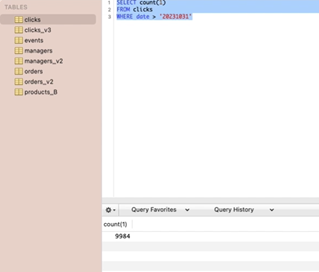
-
쿼리 프로파일링 결과
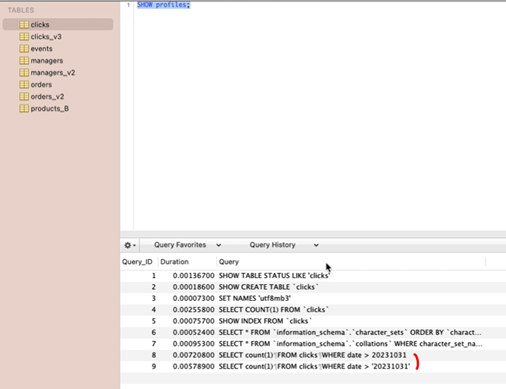
- 묵시적 형변환이 없는 문자열과 문자열 비교가 더 빠른 것을 확인할 수 있음.
2.DATA_FORMAT함수를 WHERE의 좌측에 쓴 경우와 우측에 쓴 경우 비교
-
좌측에 쓴 경우
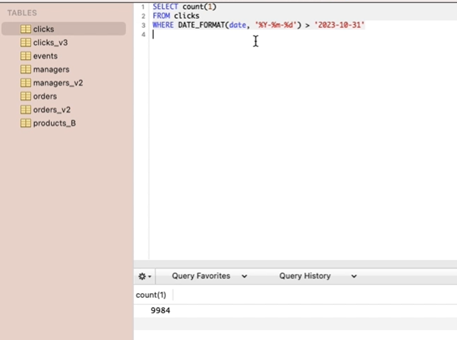
-
우측에 쓴 경우
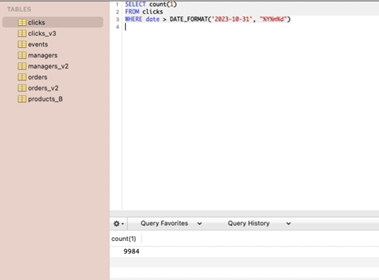
- 고정된 문자열에 DATA_FORMAT함수를 쓰는 경우는 거의 없지만 비교를 위해 함
-
프로파일링 결과 확인해보면 우측에 쓴 경우가 더 빠름을 알 수 있음.
📍 JOIN 시 유의할 점
JOIN은 연산량이 크기 때문에 JOIN 대상 테이블을 최대한 줄이고 시작하는게 좋음
우선 JOIN 하는 테이블 간 관계를 고려해야함.
1) JOIN하는 테이블 간의 관계 고려하기
-
테이블 관계는 크게 3가지로 나눌 수 있음.
-
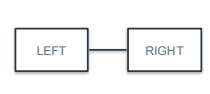
1:1
-
왼쪽 테이블 행 하나가 오른쪽 테이블 행 하나에 대응되는 경우
-
예를들어 직원들의 인사정보 테이블과 팀별 소속 테이블이 있다고 할 때, 하나의 직원이 하나의 팀에 속한다고 가정하면 1명의 직원 기준으로 인사정보 테이블과 팀별소속 테이블은 1:1 관계가 됨
-
-
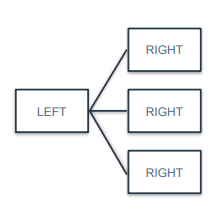
1:N
-
왼쪽 테이블의 행 하나가 오른쪽 테이블의 여러 행에 대응되는 경우
-
ex) 고객정보와 클릭이력/구매이력 간의 관계라고 할 수 있음
고객 한명이 여러 제품을 클릭할 수 있고 여러 상품을 구매할 수 있으니 1:N 관계
-
고객정보와 클릭이력 테이블을 고객정보 테이블 기준으로 LEFT JOIN하면 행 수가 뻥튀기 됨(왜냐면 고객 한명이 여러 번 클릭한 이력들이 LEFT JOIN으로 붙기 때문).
-
반대경우에는 클릭이력 테이블 크기 그대로가 됨.
-
-
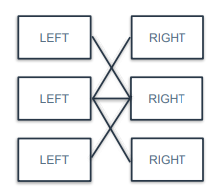
N:N
-
왼쪽 테이블의 행 하나가 오른쪽 테이블의 행 여러개와 대응이 되고, 오른쪽 테이블의 행 하나도 왼쪽 테이블의 여러 개와 대응되는 경우
-
ex) 대학생과 동아리의 관계
학생 한명은 여러 개의 동아리에 가입할 수 있고, 동아리는 학생 여러 명으로 이루어질 수 있음.
-
N:N 관계 테이블을 결합했을 때는 행 수가 학생 수와 동아리 수 조합에 의해 늘어나게 됨.
-
-
참고로 DB의 테이블 구조를 설계할 때 ER Model이라는게 있는데, 테이블을 entity로 두고 테이블 간 관계를 realationship으로 표현한 것(테이블 간 관계에 대해 더 알고 싶다면 이 개념을 공부)
https://en.wikipedia.org/wiki/Entity%E2%80%93relationship_model
2) 데이터 중복이 있는지 확인하기
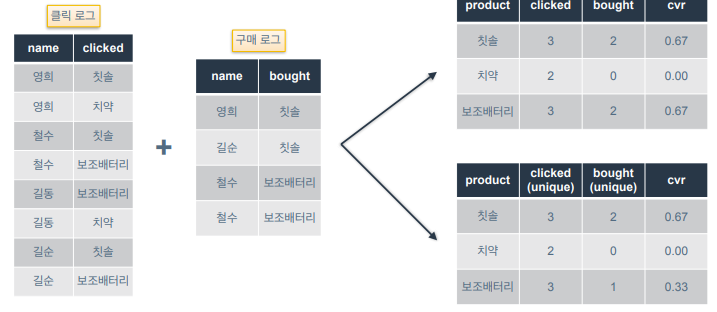
- 데이터 중복이 있는지 확인하지 않고 분석을 수행하면 큰 테이블끼리 결합하는 경우라면 쿼리속도가 느려지게 되고, 의도했던 거와 다른 테이블을 얻을 수도 있음.
-
구매 로그를 보면 철수가 보조배터리를 구매한 이력에 중복이 존재
-
결과를 보면 위의 표의 경우 철수가 2번 구매한 이력이 반영이 안됐음(?)
-
많이 구매되는 상품을 추출하려면 아래표와 같이 unique한 유저 집계를 사용하는게 더 적절
3) 여러가지 쿼리 방식을 고려하기
-
DB에서 원하는 결과 뽑아내기 위해 다양한 방식으로 쿼리 작성할 수 있음.
-
같은 결과라도 뽑기 위한 쿼리는 다양함. 상황에 따라 가장 효율적인거를 사용하는게 좋음.
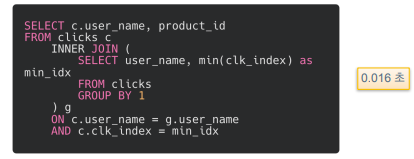
-
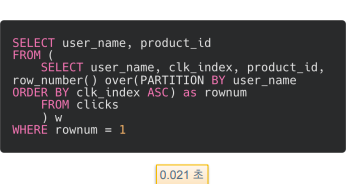
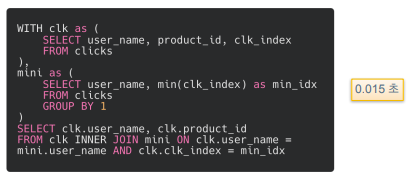
다음 3가지 쿼리는 모두 동일한 결과물을 반환함(유저별로 처음 클릭한 상품을 뽑기 위한 쿼리)
-
1번 쿼리는 window함수 사용. 유저 이름으로 파티션을 나누고 클릭 인덱스로 오름차순 정렬. 그리고 클릭 인덱스가 가장 빠른 행만을 필터링
-
2번 쿼리는 WITH 구문 사용. 첫 블록은 클릭 테이블에서 필요한 컬럼 뽑아옴. 두번째 블록은 유저별로 그룹화해서 가장 빠른 클릭 인덱스를 뽑음. 그리고 JOIN해서 가장 빠른 클릭을 뽑아냄.
-
3번 쿼리는 서브쿼리 사용. 클릭 테이블하고 INNER JOIN 할 대상인 테이블을 추출할 때 서브쿼리 사용.
-
결론: JOIN은 연산량이 커서 효율적으로 쿼리를 작성해주어야함.
(실습)
매니저들의 클릭이력을 뽑기 위해 clicks와 managers를 결합하려고 함.
이 때 두 테이블 모두 크기가 10000.
1.서브쿼리 써서 매니저들의 클릭 뽑기
SELECT *
FROM clicks
WHERE user_name IN (SELECT name FROM managers_v2)
2.JOIN써서 매니저들의 클릭뽑기
SELECT c.*
FROM clicks c INNER JOIN managers_v2 m ON c.user_name = m.name
쿼리 프로파일링 결과 보면
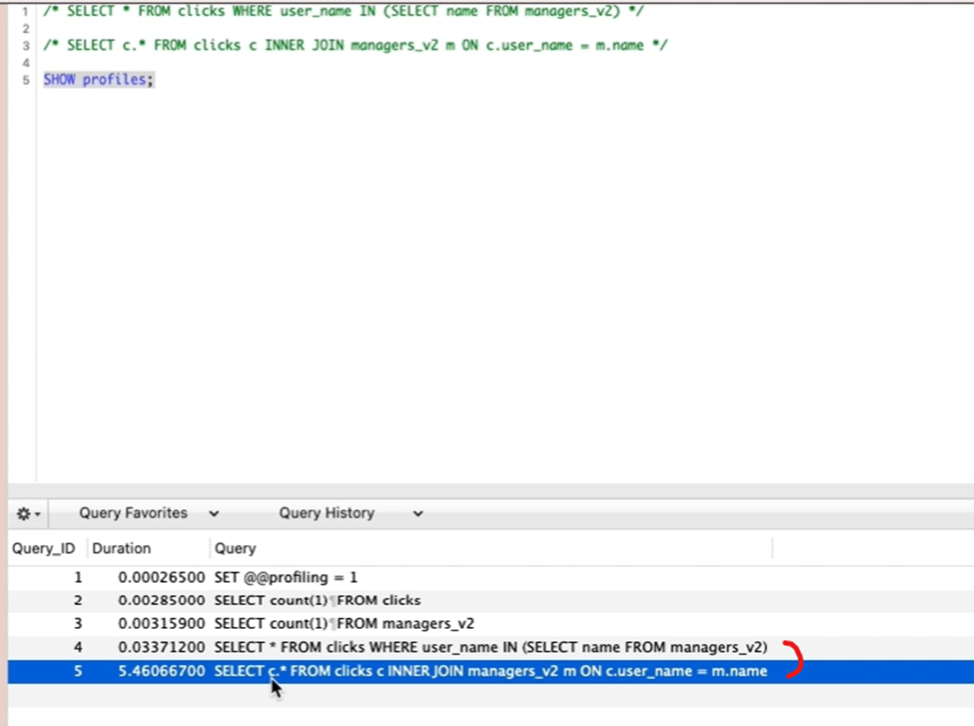
JOIN을 사용했을 때가 속도가 더 느린 것을 알 수 있음.
데이터 별로 쿼리 방식에 따라 효율이 극단적으로 차이날 수 있기 때문에 큰 테이블 간 JOIN을 해야될 때는 여러가지 방식을 비교해보면서 효율적인거 찾는게 좋음.
📍 가독성 높이기
쿼리의 가독성이 중요한 이유는 무엇일까?
쿼리를 보는 미래의 자신과 다른 사람들을 위해서. 사람마다 쿼리를 작성하는 방식이 다르기 때문에 다른 사람이 작성한 쿼리를 보면 이해하는데 시간이 어느정도 걸림.
심지어 자기자신이 작성한 쿼리라도 다시보면 이해하는데 시간이 오래걸릴 때가 있음.
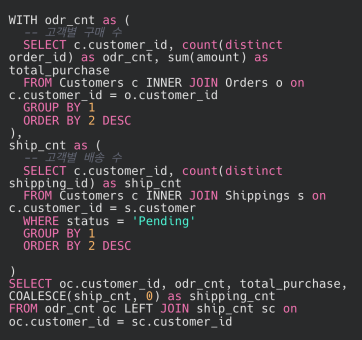
예시 쿼리는 블록이 2개 뿐이지만 현업에서는 블록이 훨씬 더 많음.
이럴 때 쿼리를 가독성 있게 짜두면 이해하기 훨씬 수월함.
가독성을 높이기 위해서는
1) 서브쿼리 보다는 WITH구문이 가독성이 좋음
- 블록으로 구분되기 때문에 각 블록 안의 내용을 숙지한 뒤 블록 바깥에서 어떻게 결합이 되는지 순차적으로 이해할 수 있음.
2) WITH절을 사용할 때 각 블록의 이름을 잘 지정하기
- 각 블록이 의미하는 바가 명확해져서 가독성이 높아짐.
