🟨 SQL을 이용한 데이터 분석: SELECT 배우기
📍 퀴즈 리뷰
지난 시간 퀴즈를 같이 풀어본다
✅ 1
Q : 다음 중 데이터 웨어하우스 특징이 아닌 것은? (프로덕션 데이터베이스와 비교했을 때)
A :
1. 처리할 수 있는 데이터의 크기가 중요하다.
2. 데이터 처리 속도가 아주 빨라야 한다.
3.보통 클라우드 기반의 Redshift, Big Query, Snowflake 등을 사용한다.
4.회사 내부 직원들(특히 데이터 팀원들)이 주 사용자이다.
'데이터 처리 속도가 아주 빨라야 한다'는 데이터 웨어하우스가 가지면 좋은 장점이긴 하지만 특징이라고 말하기는 어려움.
프로덕션 DB의 경우에는 중요한 특징!
✅ 2
Q : 다음 중 SQL에 대한 설명으로 잘못된 것은?
A :
1. 1970년대 초 IBM이 개발한 관계형 데이터 베이스 질의/조작 언어이다.
2. 비구조화된 데이터를 처리하는데 적합한 언어이다.
3. 데이터 일을 하는 사람이면 반드시 알아야 할 기술이다.
4.DDL과 DML 두 종류가 있다.
SQL은 구조화된 데이터를 처리하는데 적합한 언어임.
✅ 3
Q : 흔히 이야기하는 데이터 인프라의 일부가 아닌 것은?
A :
1. 데이터 웨어하우스
2. ETL 프로세스
3. Spark와 같은 대용량 분산처리 환경
4. 프로덕션 데이터베이스
프로덕션 DB는 데이터 인프라의 일부가 아니고 데이터 웨어하우스에 복제 되어야하는 데이터가 존재하는 데이터 소스(따라서 데이터 인프라가 아님).
✅ 4
Q : 다음 중 클라우드의 장점을 모두 고르시오.
A :
1. 내가 필요한 자원을 필요한만큼 필요할 때 할당하여 사용할 수 있다.
2. 운영 비용이 아닌 초기 투자 비용을 증대시킨다.
3. 고정비용의 지출로 재무측면에서 플래닝이 쉬워진다.
4. 서비스 구현에 필요한 시간을 단축하여 기회비용을 최소화하는 이점이 존재한다.
클라우드는 초기 투자 비용이 없고 운영 비용으로 운영이 됨.
사용한 만큼 돈이 나가는 형태(고정비용X)로 재무 모델이 바뀌게 됨.
고정비용이 아니라서 재무측면에서 플래닝이 쉬워지지는 않음.
✅ 5
Q : 우리가 이번 강좌에서 사용할 데이터 웨어하우스는 무엇인가?
A :
1. 구글 클라우드의 Big Query
2. Snowflake
3. AWS의 Redshift
4. MySQL
1,2번은 많이 사용되는 데이터 웨어하우스
4번은 많이 사용하는 프로덕션 DB
✅ 6
Q : 다음 중 관계형 데이터베이스에 대한 설명으로 잘못된 것은?
A :
1. 구조화된 데이터를 테이블 형태로 표현한다.
2. SQL을 사용하여 구조화된 데이터를 질의하고 조직한다.
3. 보통 데이터베이스 혹은 스키마라고 부르는 일종의 폴더 밑에 테이블을 생성하는 2단계 구조로 테이블들을 관리한다.
4. Star schema보다는 Denomalized schema를 사용하는 것이 일반적이다.
관계형 데이터베이스라고 할 때 4번이 꼭 맞다고는 할 수 없음.
데이터 웨어하우스면 Denomalized schema 사용하는게 더 일반적인데, 상황마다 다른 것이라 어떤 스키마가 더 일반적이다 할 수는 없음.
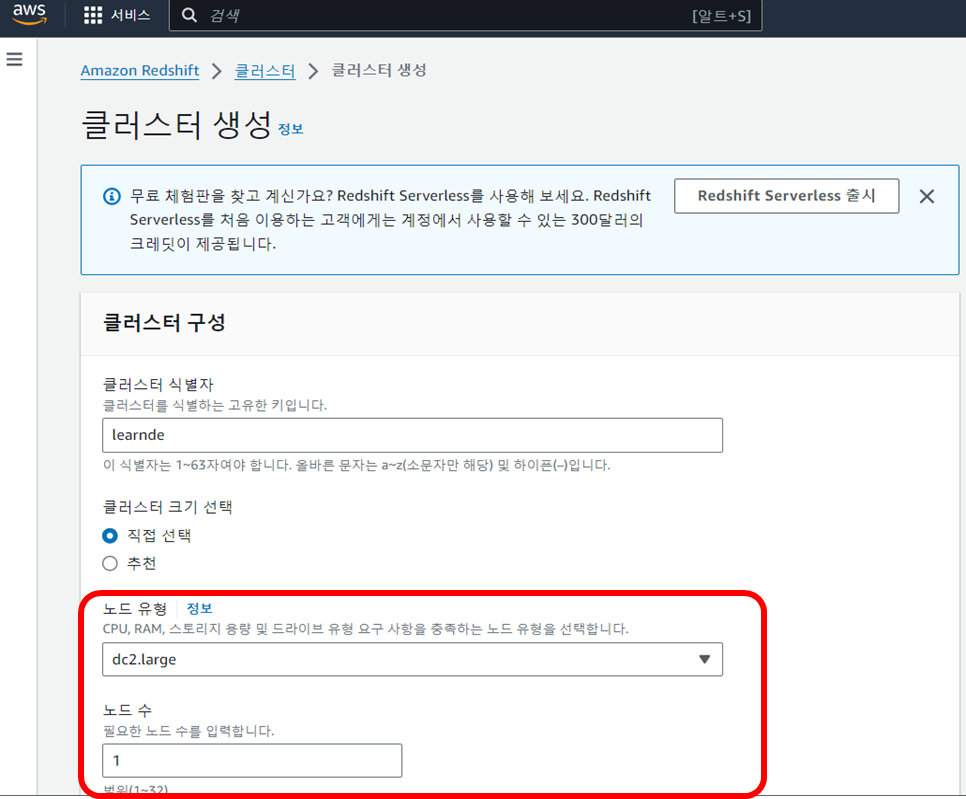
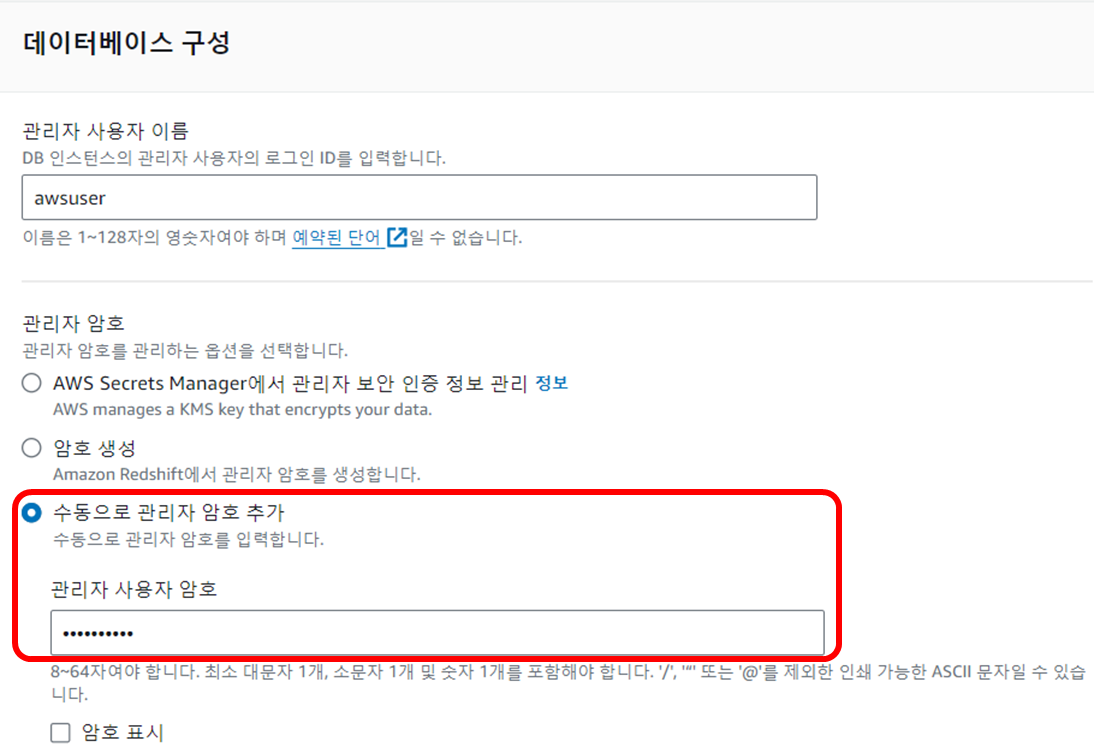
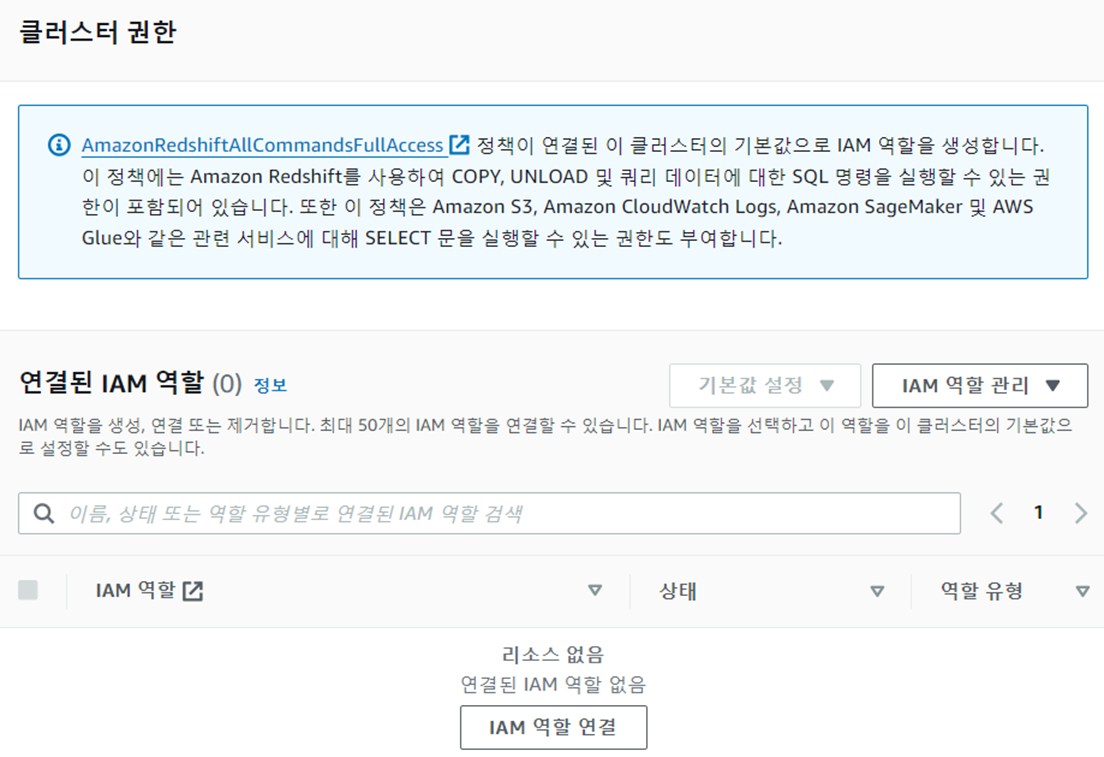
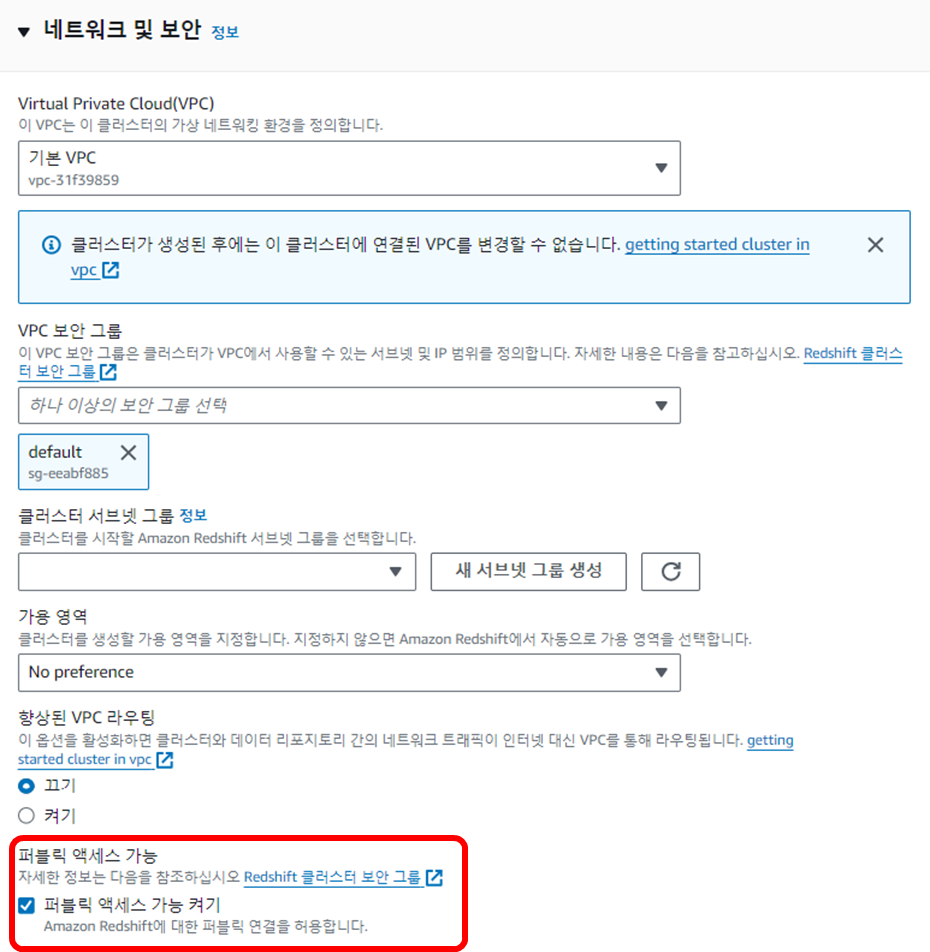
📍 Redshift 론치

📍 SQL 정리
이전 SQL 수업에서 배운 내용과 중복이지만 다시 정리함.
SQL 기초
-
다수의 SQL문을 동시에 실행한다고 하면 SQL문 끝날 때 마다 세미콜론으로 분리 필요함.
ex) SQL문1; SQL문2; SQL문3;
-
SQL 주석

-
SQL 키워드는 대문자를 사용한다던지 하는 나름대로의 포맷팅이 필요.
같은 맥락으로 테이블/필드 이름 명명 규칙을 정하는 것도 중요!
➡️ 1. 단수형(User) vs. 복수형(Users)- _ (user_session_channel) vs. CamelCasing(UserSessionChannel)
SQL DDL : 테이블 구조 정의 언어
-
DDL은 테이블의 구조를 정의해줌.
-
Redshift에서 스키마 밑에 테이블이 존재하게 되는데, 스키마를 만들어줄 때 CREATE SCHEMA 사용 ➡️ 스키마 만드는 명령도 DDL에 포함됨.
- CREATE TABLE
CREATE TABLE row_data.user_session_channel(
userid int,
sessionid varchar(32) primary key,
channel varchar(32)
);-
CREATE TABLE은 테이블 생성하는 명령어
-
CREATE TABLE 폴더(스키마)이름. 테이블 이름형태
➡️ 필요한 경우 primary key 설정까지!데이터 웨어하우스에서는 primary key 보장을 못해줌.
왜? 보장해주면 큰 레코드들이 추가될 때 마다 보장하기 위해서 체크를 해야하는데, 성능이 나오지 않기 때문에.
따라서 primary key 지정해줘도 무시됨.
그렇기 때문에 데이터를 넣을 때 INSERT INTO로 넣으면 시간이 오래걸리기 때문에 이거를 안쓰고 COPY(벌크 업데이트 명령)을 사용.
벌크 업데이트는 csv/json 파일에 데이터를 저장하고 웹 스토리지에 업로드하고 거기에서 원하는 테이블로 한번에 업데이트 하는 방법.
-
CTAS(CREATE TABLE table_name AS SELECT)는 테이블을 만듦과 동시에 내용까지 채워버리는거.
원래는 테이블 정의 후 내용을 넣는데 정의를 하면서 동시에 내용을 채우는 방법을 말함.
- DROP TABLE
-
DROP TABLE은 테이블을 삭제하는 명령어
-
DROP TABLE 스키마 이름.테이블 이름형태 -
만약 삭제하려는 테이블이 존재하지 않으면 에러 발생.
그게 불편한 경우에는
DROP TABLE IF EXISTS table_name;해당 구문 사용하면됨.
테이블이 존재하면 삭제하고 존재하지 않으면 에러 안띄우고 끝남.
-
DELETE FROM 과 비슷하지만 차이점이 존재.
DELETE FROM은 테이블 구조는 그대로이고 지칭된 테이블의 모든 레코드를 지움.
DROP TABLE은 테이블 자체를 날려버림.
- ALTER TABLE
-
테이블에 새로운 컬럼 추가, 기존 컬럼 이름 변경, 기존 컬럼 제거, 테이블 이름 변경 등을 하는 명령어
-
다음과 같은 형태로 작성
ALTER TABLE table_name ADD COLUMN 필드이름 필드타입;ALTER TABLE table_name RENAME 현재 필드이름 to 새 필드이름;ALTER TABLE table_name DROP COLUMN 필드이름;ALTER TABLE 현재 table_name RENAME TO 새 테이블 이름;
SQL DML : 테이블 데이터 조작 언어
-
레코드 질의 언어
-
SELECT FROM
-
테이블로부터 조건에 맞는 레코드들을 읽어오는데 사용
-
읽어올 때 특정 컬럼만 읽어오게 할수도 있고 ORDER BY써서 순서를 결정할 수도 있고 GROUP BY 통해서 특정 값 중심으로 그룹핑해서 읽어올 수도 있음.
-
-
-
레코드 수정 언어
-
INSERT INTO
- 테이블에 레코드를 추가하는데 사용
-
UPDATE FROM
- 테이블의 필드 값 수정 시 사용
-
DELETE FROM
-
테이블에서 레코드 삭제 시 사용
-
TRUNCATE = 조건없이 다 삭제하는 DELETE FROM
차이점은 트랜잭션에서의 사용여부(이후 수업에서 다시 언급예정).
-
-
📍 SQL 실습
실습에 들어가기 앞서 기억해야할 점이 있음.
1. 현업에서 깨끗한 데이터는 존재하지 않음
-
데이터 퀄리티가 좋은지 체크해야함.
어떻게 체크할까?
1) 중복된 레코드 살펴보기
2) 최근 데이터 존재 여부 체크하기
3) Primary key uniqueness가 지켜지는지 체크
4) 값이 비어있는 컬럼 체크하기
-
SQL 가지고 데이터 분석을 할 때는 분석 코드 앞에 사용하려고 하는 테이블들이 원하는 형태로 들어있는지 unit test로 짜서 쉽게 체크해볼 수 있음(노가다 안해도 테스트할 수 있도록)
2. 어느 시점이 되면 너무 많은 데이터가 존재
-
내가 원하는 정보가 들어있는 테이블을 찾는데 문제가 발생함.
-
회사 규모가 작을 때부터 규칙을 만들어 두는게 필요함.
-
이러한 문제를 해결하기 위한 다양한 오픈소스/서비스들이 등장.
ex) DataHub, Amundsen, Select Star 등
실습
구글 colab에서 다양한 SQL 문 연습하기
파이썬 노트북을 SQL 에디터처럼 쓸 수도 있음.
쉽지는 않지만 파이썬 코딩과 섞어서 쓸 수 있다는 점에서 장점이 많이 존재.
위와 같이 하려면 파이썬 노트북에 %load_ext sql 코드 실행해주어야함.
SQL 문 적을 때 다음과 같은 형태로 적어야함.
%%sql
SELECT *
FROM raw_data.user_session_channel;그 후 SQLAlchemy 문법을 써서 Redshift에 셋업했던거 연결해주면 됨.
%sql postgresql://guest:Guest1234@learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com:5439/dev
(수정)
개인 실습 id와 pw를 할당 받음. 그거로 접속해서 Redshift에 연결하면 됨.
실습에 사용하는 테이블은 다음과 같음.
| Table | Fields |
|---|---|
| session_timestamp | sessionid (string), ts (timestamp) |
| user_session_channel | userid (integer), sessionid (string), channel (string) |
| session_transaction | sessionid (string), refunded (boolean), amount (integer) |
| channel | channelname (string) |
다양한 SELECT 사용해보기
-
raw_data 스키마 밑에 user_session_channel의 모든 레코드와 컬럼을 불러오는 예시
%%sql SELECT * FROM raw_data.user_session_channel;결과의 일부는 다음과 같음.
총 101520개의 rows을 갖음.

위의 코드 처럼 해도되고 컬럼명을 직접 적어줘도 됨.%%sql SELECT userId, sessionId, channel FROM raw_data.user_session_channel;위의 코드와 동일한 결과가 나옴.
-
데이터를 처음 10개만 보고 싶은 경우
%%sql SELECT * FROM raw_data.user_session_channel LIMIT 10;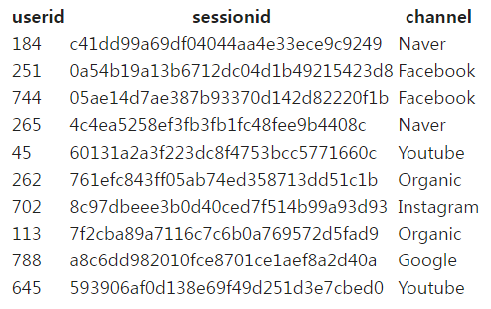
-
유일한 채널이름을 알고 싶은 경우
%%sql SELECT DISTINCT channel FROM raw_data.user_session_channel;
-
채널별로 카운트하고 싶은 경우
%%sql SELECT channel, COUNT(1) -- 채널별 카운트를 하고 싶은 경우. COUNT 함수!! FROM raw_data.user_session_channel GROUP BY 1 ORDER BY 1;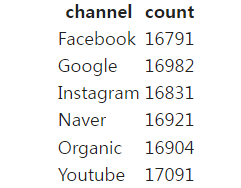
-
테이블의 모든 레코드 수 카운트 하는 경우
%%sql SELECT COUNT(1) -- 테이블의 모든 레코드 수 카운트. COUNT(*). FROM raw_data.user_session_channel;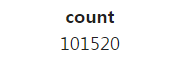
-
채널이 Facebook인거 카운팅하는 경우
%%sql SELECT COUNT(1) FROM raw_data.user_session_channel WHERE channel = 'Facebook'; -- 채널이 페이스북 인거만 필터링해서 COUNT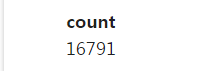
-
CASE WHEN 사용해보기
%%sql SELECT channel, CASE WHEN channel in ('Facebook', 'Instagram') THEN 'Social-Media' WHEN channel in ('Google', 'Naver') THEN 'Search-Engine' ELSE 'Something-Else' END channel_type FROM raw_data.user_session_channel LIMIT 100;컬럼값을 그대로 쓰는게 아니라 변환해야하는 경우가 있는데 그 때 사용할 수 있는게 CASE WHEN.
CASE WHEN 조건 THEN 참일 때 값 ELSE 거짓일 때 값 END 필드이름형태.보통 SELECT 안에서 사용됨.

위는 결과의 일부
-
LIKE / ILIKE 사용해보기
%%sql SELECT DISTINCT channel FROM raw_data.user_session_channel WHERE channel ILIKE '%o%';채널명에 소문자 대문자 관계없이 o가 들어가있는 채널이 유니크한 값이 어떤게 있는지 보는 예시.

-
STRING 함수 사용해보기
%%sql SELECT LEN(channel), UPPER(channel), LOWER(channel), LEFT(channel, 4) FROM raw_data.user_session_channel LIMIT 100;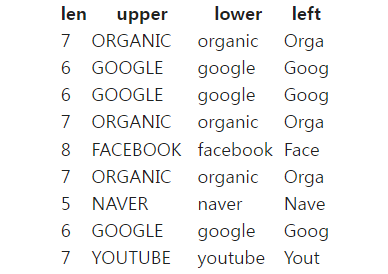
- LEFT(str, n) : str에서 n번째자리까지 뽑아냄
- UPPER, LOWER : 각각 문자열을 대문자로, 소문자로 변경해줌
- LAPD : 어떤 문자열의 왼쪽에다가 string을 패딩해줌
- SUBSTRING : LEFT와 비슷한데 왼쪽부터가 아니라 시작점을 주면 거기부터 몇 개의 문자 뽑아냄
-
테이블 만들고 데이터 넣기
CREATE TABLE raw_data.count_test ( value int );테이블 생성해주고 데이터 넣어줌.

%%sql SELECT COUNT(1) count_1, COUNT(0) count_0, COUNT(NULL) as count_null, COUNT(value) count_value, COUNT(DISTINCT value) count_distinct_value FROM raw_data.count_test;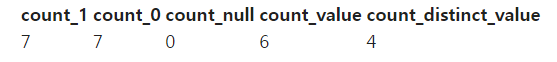
- COUNT 함수는 주어진 인자 값이 NULL이면 0이 되고 아니면 1씩 더하는 방식으로 작동.
-
COUNT(1), COUNT(0)은 결과가 7이 되고 COUNT(NULL)은 0이 들어와서 결과도 0.
-
COUNT(value)은 NULL인게 하나 있는거 제외하고 6을 반환.
-
COUNT(DISTINCT)는 DISTINCT하는 순간 전체가 5개로 줄고 NULL인거 빼고 카운트 되니까 4가 반환.
- NULL 관련 연산
%%sql
SELECT 0 + NULL, 0 - NULL, 0 * NULL, 0/NULL 
- 사칙연산 시 null이 들어가면 결과도 null.
- null은 값이 존재하지 않음을 나타내는 상수. 0이나 ""과는 다름.
-
타입 변환(타임존 관련 변환)
%%sql SELECT GETDATE(), -- 현재 시간 (UTC기준) CONVERT_TIMEZONE('America/Los_Angeles', GETDATE()); -- 미국시간으로 바꾸기
-
CONVER_TIMEZONE(' ', ts)에서 ts에는 UTC 기준의 ts가 들어가야함.
-
DATE, TRUNCATE하면 ts받아서 날짜만 리턴. 뒤에 시각, 분, 초는 지워버림.
-
TO_CHAR는 숫자나 시간을 문자열로 바꾸는 함수
-
TO_TIMESTAMP는 문자열로 되어있는 시간을 날짜시간으로 바꿔주는 함수
-
타입 변환
%%sql SELECT 1/2, 1/2::float;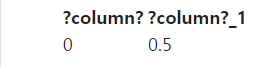
-
1/2의 결과는?
0.5가 나와야하는데 정수끼리의 연산은 정수가 되어야하기 때문에 0이 결과로 나옴.
따라서 분모,분자 하나라도 float타입으로 바꿔줘야함.
바꾸는 방법은 2가지
1) :: 오퍼레이터 사용
2) cast 함수 사용
- 판다스와 연동하기
result = %sql SELECT * FROM raw_data.user_session_channel df = result.DataFrame() # return 되는게 pandas dataframe들
-
df.head()하면 처음 5개 데이터 불러오기
-
df.groupby(["channel"]).size()
group by해서 size추출
-
df.groupby(["channel"])["sessionid"].count()
group by해서 count
실습의 자세한 내용은 해당 링크와 colab 파일(SQL_practice_0319.ipynb) 참고!
