📍 2-1. 데이터 문해력 퀴즈리뷰
지난 시간 퀴즈를 같이 풀어본다
✅ 1
Q : '데이터 웨어하우스'라는 것은 반드시 빅데이터 기반의 데이터베이스를 말한다.
A : 꼭 그런거는 아님. 회사에 데이터가 없는데 빅데이터 기반의 웨어하우스를 사용할 필요는 없음.
✅ 2
Q : 이상적인 데이터 조직의 발전 단계의 첫 번째는 무엇일까요?
A : 데이터 엔지니어를 영입해서 데이터 인프라부터 만드는 것
✅ 3
Q : ETL을 만들면 이를 주기적으로 실행해주어야 한다.스케줄러로 가장 많이 사용되는 것은 무엇인가?
A : ETL은 데이터 파이프라인이라고 부르는데, 이 데이터 파이프라인의 결과는 데이터 웨어하우스에 테이블 형태로 나오게 됨. 이 때 데이터 파이프라인들을 주기적으로 실행해주는 SW가 필요함(?). 가장 많이 사용하는 것은 Airflow.
✅ 4
Q : ETL과 ELT에 대해 설명해보세요.
A :
ETL - 데이터 엔지니어가 데이터 시스템 바깥에 있는 데이터 소스에서 데이터를 추출하고 변환한 다음 데이터 웨어하우스에 테이블 형태로 적재하는 것
ELT - 적재해놓은 데이터를 데이터 분석가가 사용하기 쉬운 형태로 바꾸는 작업
✅ 5
Q : 다음 중 많이 사용되는 데이터 웨어하우스 기술이 아닌 것은?
A : 오라클 데이터베이스 / AWS의 RedShift / 구글 클라우드의 Big Query / Snowflake
✅ 6
Q : 요즘 데이터팀의 개발방식은?
A : 폭포수 개발 방식(개발 사이클이 한번만 돌고 끝나는 옛날 모델) / 애자일 개발 방식
✅ 7
Q : 현재 추세는 데이터 과학자도 코딩을 할 줄 알아야 한다?
A: 맞다 / 틀리다
✅ 8
Q : 데이터 분석가가 하는 일이 아닌 것은?
A : 중요지표 정의 / 시각화 대시보드 구현 / 데이터 웨어하우스 구현(데이터 엔지니어가 하는 일)
✅ 9
Q : 데이터 과학자들이 꼭 기억해야하는 것이 아닌 것은?
A : 솔루션은 간단할수록 좋다/ 머신러닝을 쓴다면 딥러닝이 가장 좋다(간단한 솔루션이 좋은거임)/ 무슨 일을 하건 내 일의 성공여부를 결정해주는 지표를 생각해야 한다
✅ 10
Q : 데이터 일을 하는 사람들이 꼭 알아야 할 기술을 하나 꼽는다면?
A : SQL/ 파이썬/ 머신러닝
✅ 11
Q : A/B테스트가 무엇인지 간단하게 써보세요.
A : 어떤 새로운 기능을 만들었을 때 그 기능이 의미가 있는지 실제 사용자에게 노출 시켜서 판단 하는 것. 그룹을 두개로 나눠서(vias없게 나누어져야함) 하나의 그룹에는 기존 기능을 노출, 나머지 그룹에는 새로운 기능 노출시켜서 중요한 지표를 기준으로 둘을 비교해서 새로운 기능이 실제 사용자에게 의미가 있게 향상되었는지 확인하는 거.
📍 2-2. 데이터 기반 의사결정이란?
데이터를 기반으로한 의사결정이 무엇인지 알아보자
두 가지 형태의 데이터 기반 의사결정
-
data driven decision : 데이터가 하라는대로 결정한다는 의미가 강함. 해오던 일의 방향이 있고 최적화하는 뉘앙스가 있는 느낌.
-
data informed decision : 새로운 일을 시도할 때, 과거 데이터를 찾아서 참고한다는 의미가 강함.
데이터에서 인사이트 찾기
-
중요 지표를 데이터 기반으로 정의하고 시각화하기
-
가설을 바탕으로 실제 데이터를 보고 확인하기 ➡️ A/B 테스트
데이터 분석 케이스 살펴보기
1) 고객 이탈률
- 샌프란시스코 기반 전동 스쿠터 회사에서 돈을 많이 쓰는 고객들이 두세달 후에 서비스를 그만 사용하는 현상이 발생 ➡️ VIP의 이탈률을 트래킹 하는 것이 중요
2) 마케팅 기여도 분석
-
다양한 광고 마케팅을 디지털 미디어 기반으로 수행
-
결과를 분석하여 어느 채널에 어떤 형태의 마케팅이 효과적인지 파악
-
디지털 마케팅은 데이터 중심으로 돌아감
3) 고객 불만과 이탈률간의 관계
-
서비스 관련해서 불만을 이야기하는 고객들의 이탈률은 어떨까?
➡️ 서비스에 관심이 많은 사람들이 불만을 이야기 하는 것이지 관심이 없는 사람들은 불만 표시 없고 바로 그만둠. -
Survivorship bias : 내 눈에 보이는거만 문제라고 생각하고 해결하려는 거
Confirmation bias : 내가 갖고있는 믿음을 더 강하게 추천해주는 그런 류의 증거들만 채택하는거(예를 들어 형사들이 수사할 때, 자신들이 판단하기에 범죄자라고 생각되는 사람을 대상으로만 수사를 깊게 진행하고 그 외의 사람들에겐 눈길 조차 주지 않는 상황)
📍 2-3. 조직 구조의 중요성과 트렌드
데이터 조직이 회사 전체로 볼 때 갖는 조직 형태를 살펴보자
데이터 팀의 조직 구조(3가지)
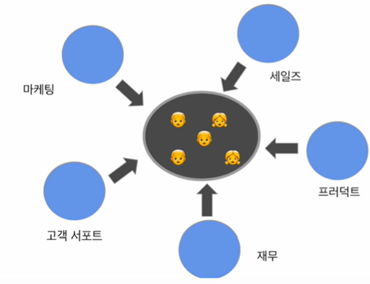
1) 중앙 집중 구조 - 모든 직원이 하나의 팀에 속해서 데이터 엔지니어, 분석가, 과학가가 한 조직에 속해서 일하는 구조
2) 분산 구조 - 데이터 분석가, 과학자에게 적용되는데 조직에 있는게 아니라 현업조직이 있고 그 현업 조직 밑에 소속되어 일을 하는거
3) 하이브리드 구조 - 중앙 집중과 분산 구조의 하이브리드. 모든 조직원들이 한 팀에 소속되지만 일을 할 때는 파견, 임베드 형태로 현업 부서와 같이 일을 하는 형태를 말하는 거
중앙 집중 구조 : 모든 데이터 팀원들이 하나의 팀으로 존재
-
다수의 현업 부서들(ex.마케팅, 세일즈, 프로덕트, 재무, 고객서포트)을 서포트 하는 구조
-
장점: 데이터 팀원들간의 협업이 늘어나고 데이터 팀 내에서 커리어 path가 생겨서 구성원들의 만족도가 올라감.
-
그러나, 현업부서의 만족감은 떨어질 확률이 높음
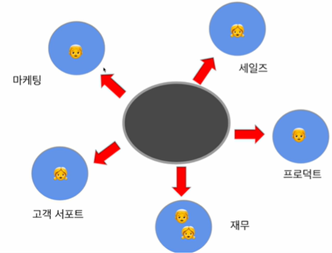
분산 구조 : 데이터 팀이 현업 부서별로 존재
-
현업 부서들의 만족도가 올라감
-
데이터 팀원들은 지식과 경험을 공유하기 힘들고 데이터 인프라나 데이터 공유가 힘들어짐
-
분산 구조도 2가지 경우가 존재
1) 중앙 집중 구조에서 조직개편을 통해 분산 구조가 된 경우
2) 자생적으로 데이터 인력을 키우며 분산 구조가 생기는 경우
-
어떤 문제가 발생? 서로 다른 데이터 전략 / 중복 투자 / 보안,규제 관련 이슈 가능성 증가 / 데이터 공유를 못함으로써 불완전한 데이터셋을 갖게됨
-
but, 이는 어쩔 수 없는 트렌드 ➡️ 이 관점에서는 클라우드 이전이 도움이 됨
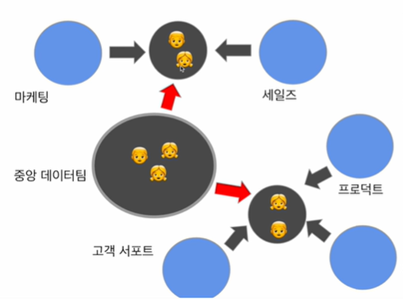
중앙 집중 + 분산 = 하이브리드
-
가장 이상적인 조직구조
-
중앙에 데이터팀이 있고 그 인력이 파견형태가 되어 일을 진행하는 것
-
현업팀에는 담당자가 있으니 이점이 있고 데이터 담당자는 중앙에 소속되어 있으니 팀원들과 의견 공유가 가능해 커리어 path에 문제가 없음
회사 크기에 따른 데이터 조직 형태의 차이
-
회사가 아주 커지면 회사 전체 데이터 웨어하우스 구성이 불가능해짐
➡️ 데이터 메쉬 필요성이 점점 대두됨데이터 메쉬란? 조직별로 데이터 시스템을 별도로 구성해서 속도를 늘리고 효율을 높이되 각 조직이 가지고 있는 데이터가 무엇이 있는지 카탈로그 만들어서 공유를 쉽게 하자는 개념
-
데이터 메쉬를 다시 쉽게 정리하면, "데이터를 중앙조직에서 관리하게 함의 불가능함을 인정하고 각 팀이 알아서 데이터를 관리할 수 있는 형태로 가는데, 거기서 발생하는 문제가 있으니까 어떻게 관리할건지 표준을 만들자는 개념"
마이크로서비스란?
-
웹 서비스를 다수의 작은 서비스들로 구현하는 방식
ex) 깃허브를 예시로 들면, 원래는 하나의 repository안에 모든 코드가 들어있음. 하나의 repository에서 모든 코드를 넣는게 아니라 다수의 repository를 가지고 연동하는 형태로 바꿈
-
각 서비스들은 팀 단위로 원하는 언어/기술로 개발하는 자율성을 갖게됨
📍 2-4. 데이터 조직의 일주일 살펴보기
데이터 조직이 무슨 일을 하는지 한 주를 살펴보자
애자일 개발 방법론이란?
-
세상이 빠르게 변화하면서 미리 SW 요구사항을 알 수 없게 됨 ➡️ SW 개발은 폭포수 모델이 아닌 애자일 방법론이 대세가 됨
-
애자일 방법론 특징
1) 짧은 사이클(보통 sprint라고 부름)이 특징(보통 1-3주)2) 매 스프린트는 다음 과정을 반복
-
플래닝 미팅: 스프린트 동안 뭐할지 결정
-
매일 스탠드업 미팅: 매일 짧게 만나서 경과보고
-
데모/회고 미팅: 스프린트의 마지막에 만나서 성과 공유 및 토론
3) 매 사이클마다 바로 쓸 수 있는 기능을 구현
-
애자일/스크럼 보드
- 어떤 일을 해야하고, 어떤 일을 했고, 어떤 일이 완료가 되었는지
➡️ JIRA가 가장 많이 사용되며 Swit, ClickUP등 후발주자도 많이 사용되는 추세
요일에 따른 데이터 팀이 하는 일
1) 월요일
- 지난 스프린트 리뷰
- 새로운 한주 계획
2) 화요일
- 스탠드업 미팅(어제 어떤 일을 했고 오늘은 어떤 일을 진행할 것인지, 문제가 있었는지 등)
- 다양한 미팅들(내/외부 팀원들과 미팅)
3) 수/목요일
- 스탠드업 미팅
- 중요지표 리뷰 미팅
➡️ 대시보드 보면서 중요 지표에 어떤 변화가 있는지 살펴봄
4) 금요일
- 스탠드업 미팅
- 주간 스태프 미팅
자세한 건 강의자료 참고!
📍 2-5. 좋은 지표(KPI)란?
어떤 지표가 좋은 지표인지 알아보자
KPI란?
- Day1에서도 다룬 내용이기 때문에 Day1 자료 참고
지표(Metrics)란?
- 지표와 KPI의 차이점: 지표가 더 큰 집합이고 지표 중에서 일부 조직에 의미있는 지표가 KPI
KPI 기준
-
Represent delivery of real value: 어떤 가치를 나타내는 것이어야 한다(ex. 등록한 전체 회원 수는 의미가 없음)
-
Captures recurring value : 현재 가치만 이야기 하는 것이 아니라 계속해서 재발생되고 있는 가치를 이야기 할 수 있어야 한다(ex. 구독 형태로 무언가를 파는 상황일 때 얼마나 많은 사용자가 재구매하는지)
-
Lagging indicator(후행지표) : 회사의 상황이 어떻게 바뀔건지 예측하는 지표가 아니라 일이 벌어지고 나서 최종적인 결과를 보여주는 지표(ex. 매출액)
-
Usable feedback mechanism : 시스템에 대한 피드백을 받을 수 있어야 한다(ex.서비스를 사용하고 있는 사람이 얼마나 되는지 피드백)
Next Dashboard Fallacy
-
기존 지표 기반 결정을 못하고 대시보드를 계속해서 만드는 현상
-
지표 수는 적을수록 좋고 대시보드의 수도 적을 수로 좋음
➡️ 대시보드 수가 늘어나면 dashboard discovery 이슈가 발생
📍 2-6. KPI와 선행/후행 지표 예
KPI의 몇 가지 예를 들고 선행 지표와 후행 지표가 무엇인지 알아보자
Controllable Input Metrics vs. Output Metrics
-
Input Metrics : 선행 지표 (ex. 식단, 운동)
Output Metrics : 후행 지표 (ex. 체중감량) -
선행 지표를 파악하고 관리해야 후행 지표 KPI가 계산됨!
-
인풋 지표: 아웃풋 지표를 움직이는 지표이며, 직접 통제 가능
ex. 제품 다양성, 가격, 편의성 -
아웃풋 지표: 인풋 지표의 결과로, 직접 통제 불가능
ex. 판매량, 계약건수, 매출, 이익, MAU(Monthly Active User)
KPI와 선행 지표 예
-
매출 = 가격(P) * 판매량(Q)
➡️ P가 고정되었다는 전제하에 Q를 늘릴 방법을 찾아야 함 -
Q에 영향을 주는 인풋 지표(선행 지표)는 예를 들면 영업팀이라면 영업건수.
두 가지 중요한 KPI
- 매출 vs. 서비스 사용 고객수
➡️ 보통 매출이 훨씬 더 중요한 지표, but 네트워크 현상이 중요한 도메인에서는 '서비스 사용 고객수'도 중요한 지표(ex.페이스북처럼 사람이 많아야만 그 안에서 뭘 할 수 있는 비즈니스를 말함)
📍 2-7. 시각화 대시보드 툴 소개
어떤 대시보드들이 있는지 알아보자
시각화 툴이란?
-
대시보드 혹은 BI(Business Intelligence)툴이라고 부르기도 함
-
KPI, 지표, 중요한 데이터 포인트들을 데이터 기반으로 계산/분석/표시해주는 툴
-
결정권자들이 데이터 기반 의사결정을 가능하게 함
시각화 툴 종류
1) Excel, Google spreadsheet : 사실상 가장 많이 쓰는 시각화 툴
2) Python : 데이터 특성 분석(EDA)에 더 적함
3) Looker(구글) : 고가이지만 굉장히 다양한 기능제공, 자체언어로 데이터 모델을 만드는 것으로 시작
4) Tableau(세일즈포스) : 다양한 제품군 보유 + 일부 사용 무료
5) Power BI(마이크로소프트)
더 많이 있지만 생략(강의자료 참고)
📍 2-8. [실습] 지표 정의하고 차트 만들어보기
-
실습할 때 Tableau Public을 사용할 예정
-
Tableau Public : 무료, 데스크탑 버전 다운받아 사용하는 것이 일반적
단점 : 추출된 데이터 원본(csv파일, json파일)만 데이터 소스로 지원, 읽어올 수 있는 레코드 수 제한
기타 특징: 저장한 대시보드는 모두에게 공개가 되기 때문에 포트폴리오로 사용 가능
-
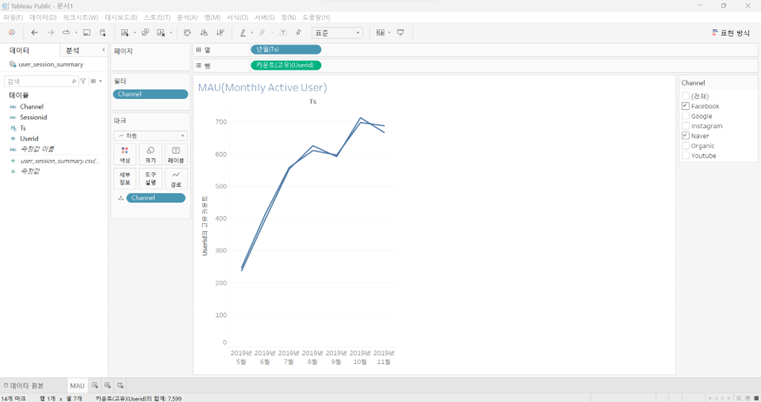
실습 주제 : 한달 내 사용자의 방문 횟수(MAU)
-
Column에는 time stamp(년+월로 설정을 변경)를 넣어줌.
-
Row에는 실제로 내가 알고싶은 지표를 넣어주면 됨(현재 실습에서는 count, 하루에 여러번 방문해도 1만 체크되어야 하기 때문에 고유값으로 설정값을 바꿔줌).
-
6개의 방문경로를 보여줄수 있는데 그 중 위 사진은 2개의 방문경로만 선택한 것(멀티라인차트)
-
대시보드는 sheet의 집합임.
