🟨 SQL을 이용한 데이터 분석: 트랜잭션과 기타 고급 SQL 문법
📍 4일차 숙제 리뷰
숙제 1 : 사용자별로 처음 채널과 마지막 채널 알아내기
-
방법 1
-
방법 2
-
방법 3
-
방법 4
숙제 2 : Gross Revenue가 가장 큰 user ID 10개 찾기
-
방법 1
-
방법 2
숙제 3 : raw_data.nps 테이블을 바탕으로 월별 NPS 계산
-
방법 1
-
방법 2
📍 트랜잭션 소개와 실습
트랜잭션
-
트랜잭션이란?
atomic하게 실행되어야 하는 SQL들을 묶어서 하나의 작업처럼 처리하는 방법.
-
atomic 하다는게 무엇인가?
여러 개의 SQL이 동시에 성공하든지 동시에 실패해야지만 데이터의 정합성에 문제가 없는 경우를 말함.
예를 들어, 계좌 이체는 2개의 오퍼레이션으로 구성됨. 한 사람이 계좌로부터 돈을 인출하는게 첫번째이고 두번째는 인출된 금액을 다른 사람의 계좌에 입금하는 거.
이 두 개의 오퍼레이션은 동시에 성공을 하든지 동시에 실패를 해야함(이게 atomic하다는 거)
그렇지 않으면 계좌 금액에 문제가 생기기 때문.
-
atomic 할 필요 없는 경우 : 은행 계좌 조회
2개의 계좌를 조회한다고 하면 하나가 실패했다고해서 문제가 생기지는 않음.
이렇게 read만 하는 경우는 문제가 없는데 write를 하게 되는 경우(=상태가 바뀌는 경우)에 문제가 생김.
SQL 경우에 writing이 들어가는 경우는 INSER INTO, DELETE FROM 등을 통해 테이블의 변동이 생기는 경우.
-
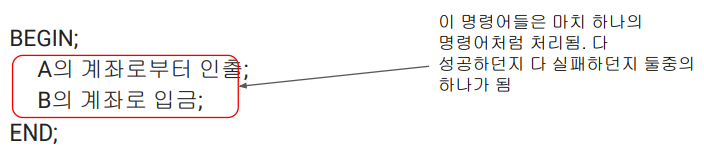
두 개의 오퍼레이션을 성공해야하는 경우는 SQL문을 트랜잭션으로 묶어줌.
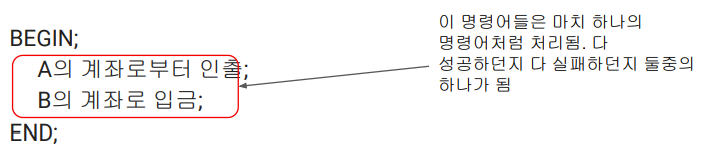
-
SQL들은 BEGIN과 END 사이에서 실행해줌.
다 성공하든지 유지하든지 하나를 이뤄낼 수 있게 함.
-
END 까지 성공하면 성공으로 마크하고 관계형 데이터베이스의 상태를 바꿈.
-
SQL이 하나라도 실패하면 원래 상태로 돌아감(BEGIN 이전으로).
➡️ 이거를 ROLLBACK 한다고 함.
-
모든 SQL 문은 뒤에 세미콜론 붙여야 함.
-
SQL은 커밋 모드에 따라서 다름. TRUE의 경우 위 이미지와 같이 되는 것이고, FALSE일 때는 또 다름.
-
트랜잭션 커밋 모드
-
automcommit = True
-
보통 automommit이 True라고 하면 내가 INSERT INTO, CREATE TABLE 등 명령어를 주면 바로 테이블에 반영됨.
-
구글 colab도 autocommit = True로 작동
-
만약 내가 A 테이블에 2개의 레코드를 트랜잭션 써서 추가했다고 할 때(END까지 실행이 안 되어진 상태라면) 누군가 다른사람이 DB 조회하면 이 레코드들은 아직 조회가 안됨.
왜? COMMIT이 안됐기 때문. 내가 돌리는 코드에서 END가 실행되면 그 시점에 DB에 반영이 되고 그 때 조회가 가능함.
-
-
autocommit= False
- autocommit이 False인 경우는 모든 SQL의 대해서 명시적으로 commit이라는 SQL을 실행해야지만 DB 상태가 바뀌는 것.
-
True 일 때는 INSERT INTO 하면 바로 반영되고 트랜잭션처럼 신중히 처리해야할 것들만 BEGIN, END(COMMIT)사이에 넣어주면 됨.
False일 때는 BEGIN, END 트랜잭션 모드가 모든 DB에 write 오퍼레이션일 경우 반영이 되는 것(?). 반영하기 전까지는 내 세션에서는 반영된거처럼 보이는데 다른 사람이 보면 안보임.
-
정리
-
True일 경우 모든 레코드 수정/삭제/추가 작업이 바로 DB에 쓰여짐(이를 commit된다고 함).
-
False일 경우 모든 레코드 수정/삭제/추가 작업이 commit 호출될 때까지 커밋되지 않음.
-
트랜잭션 방식
-
구글 colab의 트랜잭션
-
테이블의 상태를 바꾸는 명령들은 바로 커밋 됨(autocommit = True인 경우).
-
조심히 다뤄야하는 SQL 커맨드의 경우 BEGIN, END 사이에 넣어서 실행해야함.
-
-
psycopg2의 트랜잭션
-
파이썬 모듈 통해서 Redshift 조작한다면 autocommit을 내맘대로 지정할 수 있음.
-
False로 지정하면 내가 매번 테이블 상태를 바꾸고 명시적으로 commit이라는 SQL 커맨드를 호출해야 반영됨(commit()도 가능).
INSERT INTO를 했는데 나중에 보니 안되겠다 싶으면 rollback이라는 SQL 커맨드 실행해서 원래 상태로 돌아갈 수 있음(rollback()도 가능).
-
True로 지정하면 PostgresSQP 커밋 모드와 동일.
-
DELETE FROM vs.TRUNCATE
-
DELETE FROM
-
테이블에서 특정 레코드를 삭제해주는 거(테이블은 남아있음).
vs. DROP TABLE은 테이블 자체를 날림.
-
WHERE 써서 삭제하고 싶은 레코드의 조건을 정할 수 있음.
-
-
TRUNCATE
-
DELETE FROM과 비슷한데, 일부 레코드만 삭제할 수 없고 테이블에 속한 모드 레코드를 삭제함.
-
DELETE FROM의 일종으로 볼 수도 있음.
-
-
차이점
-
DELETE FROM은 트랜잭션 안에서 사용 가능
TRUNCATE는 트랜잭션 안에서 사용 불가(ROLLBACK이 안됨)
-
DELETE FROM은 일부 삭제 가능
TRUNCATE는 일부 삭제 불가
-
따라서 ROLLBACK 할 일 없고 테이블의 레코드를 빠르게 삭제하고 싶은 경우는 TRUNCATE 사용.
시간이 걸려도 ROLLBACK이 가능하게 하고 싶으면 DELETE FROM 사용.
실습
추가 예정
📍 기타 고급 SQL 문법 소개와 실습
UNION, EXCEPT, INTERSECT
-
UNION(합집합)
-
실제 현업에서 유용한 함수 중 하나.
-
여러 테이블이나 SELECT 결과들을 합쳐 하나의 결과로 보여줌.
-
UNION ALL은 여러 개의 SELECT를 합쳐서 새로운 결과를 만들 때 겹치는 레코드가 있더라도 그냥 냅둠.
UNION은 동일한 레코드가 있으면 중복을 제거한 결과를 리턴함.
-
예시) 만약 2020년까지는 페이먼트 시스템을 A를 사용했고 2021년부터는 B 시스템을 사용했다고 해보자.
현재 나는 페이먼트 시스템이 무엇인지 알고싶은게 아니라 그거로 발생한 매출 정보를 알고 싶음.
새로운 형태의 테이블을 만들어서 얻어낼 수 있음.
-
-
EXCEPT(MINUS)
-
하나의 SELECT 문 결과에서 다른 SELECT문 결과를 빼는 것.
-
결국 겹치는 부분은 삭제되고 전자에 존재하는 레코드들만 리턴됨.
-
-
INTERSECT(교집합)
- 여러 개의 SELECT가 있을 때 공통으로 존재하는 레코드만 리턴.
UNION이나 EXCEPT 같은 경우 SELECT 한 결과물 컬럼 수와 데이터 형이 같아야 함.
COALESCE, NULLIF
-
COALESCE
-
NULL 값을 다른 값으로 바꾸고 싶을 때 사용함.
-
COALESCE(Expression1, Expression2, …) 형태
-
함수의 인자로 여러 인자를 받을 수 있는데, 첫번째 인자부터 NULL인지 확인하고 맞다면 다음 인자로 넘어가고 모두 NULL이라면 NULL을 리턴하고 NULL이 아닌 값이 있으면 그 인자 리턴함.
-
-
NULLIF
-
NULLIF(Expression1, Expression2) 형태
-
두 개의 인자를 받는데, 이 인자들의 값이 같으면 NULL 다르면 첫번째 인자 리턴.
-
LISTAGG
-
GROUP BY에서 사용되는 aggregate 함수 중 하나.
-
예시) 사용자별로 한 유저가 방문한 채널들을 시간순으로 쭉 리스트 해보자.
우선 user id 로 그룹핑하고 LISTAGG 사용해서 채널을 나열함
(WITHIN 안써주면 채널이 순서 맘대로 붙음).SELECT userid, LISTAGG(channel) WITHIN GROUP (ORDER BY ts) channels FROM raw_data.user_session_channel usc JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid GROUP BY 1 LIMIT 10;다음은 결과의 예시
68 YoutubeGoogleInstagramYoutubeInstagramInstagramInstagramOrganicInstagramYoutube...구분자 없으면 결과가 알아보기 힘들게 나옴.
따라서 LISTAGG 함수 두번째 인자로 구분자를 설정함.
-
두번째 인자로 '->' 준 예시
SELECT userid, LISTAGG(channel, '->') WITHIN GROUP (ORDER BY ts) channels FROM raw_data.user_session_channel usc JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid GROUP BY 1 LIMIT 10;결과 예시는 다음과 같음.
68 Youtube->Google->Instagram->Youtube->Instagram->Instagram->Instagram->..
WINDOW 함수
AVG, SUM, COUNT, MAX, MIN, MEDIAN ....
ROW_NUMBER, FIRST_VALUE, LAST_VALUE, LAG 함수 등이 있음.
위 3개 함수는 이전에 배웠으므로 LAG 함수를 설명.
-
LAG
-
어떤 레코드들을 순서를 정해서 정렬했을 때 내 앞에 or 내 뒤에 있는 레코드의 특정 필드 값을 읽어옴.
-
LAG(래깅하고자하는 컬럼, 1(한 칸 이전의 레코드에서 읽어와라)).
-
예시) 어떤 사용자 세션에서 시간순으로 봤을 때 앞 세션에서 채널이 무엇인지? 다음 세션이 무엇인지?
SELECT usc.*, st.ts,
LAG(channel,1) OVER (PARTITION BY userId ORDER BY ts) prev_channel
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid
ORDER BY usc.userid, st.ts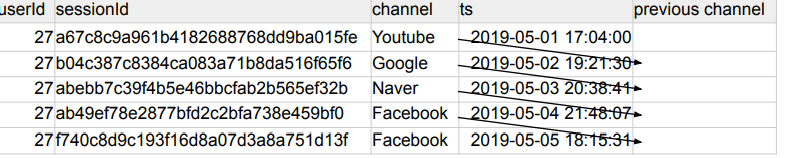
이전 세션이 아니라 다음 세션을 알고 싶다면 ORDER BY를 내림차순으로 하면 됨.
JSON parsing 함수
-
이미 JSON의 구조를 아는 상황에만 사용가능한 함수
-
구조를 모르는 JSON을 받아서 파싱하려면 직접 자신만의 함수를 만들어야함.
예시) 다음 이미지와 같은 구조를 JSON 파일이 있다고 해보자.

f4 밑에 f6을 읽고 싶다면 다음과 같은 코드 작성해야함.
SELECT JSON_EXTRACT_PATH_TEXT('{"f2":{"f3":"1"},"f4":{"f5":"99","f6":"star"}}','f4', 'f6');