🟨 Python 프로그래밍 및 Pandas 활용 실습 (1)
실습 위주로 강의가 진행되었음
📍 Pandas 소개
-
Pandas란?
파이썬 프로그래밍 언어를 위한 데이터 조작 및 분석 라이브러리.
데이터 구조와 데이터 분석 도구를 제공하여 효율적으로 데이터를 처리하고 분석할 수 있도록 도움.
주요 데이터 구조는 DataFrame(데이터프레임)과 Series(시리즈)임.
-
데이터프레임은 2차원 테이블 형식의 데이터 구조이며 행과 열로 구성됨.
시리즈는 1차원 배열 구조이며 파이썬 리스트 형태라고 생각하면 됨.
-
데이터프레임은 n개의 시리즈로 구성됨.
(데이터프레임 = n개 시리즈) -
2023.04.03에 Pandas 2.0이 출시가 되었으나 현업과 지금까지 자료들은 대부분 1.5.3버전.
(파이썬이 2 -> 3으로 가던 시기처럼 Pandas도 1.5.3 -> 2로 넘어가는 과정)
📍 Google colab 실습 준비
-
Pandas를 사용 시 대체로 사용하는 툴이 2개.
1) 아나콘다
2) 코랩이번 실습은 코랩 사용하여 진행함.
-
코랩 실습 전 세팅 하나 진행.
➡️ 도구 - 설정 - 편집기 - 코드완성 제안을 자동으로 표시 해제해당 설정이 켜져있으면 코드 입력 시 추천이 아니라 바로 구문이 완성이 되어버려서 끄고 진행함.
-
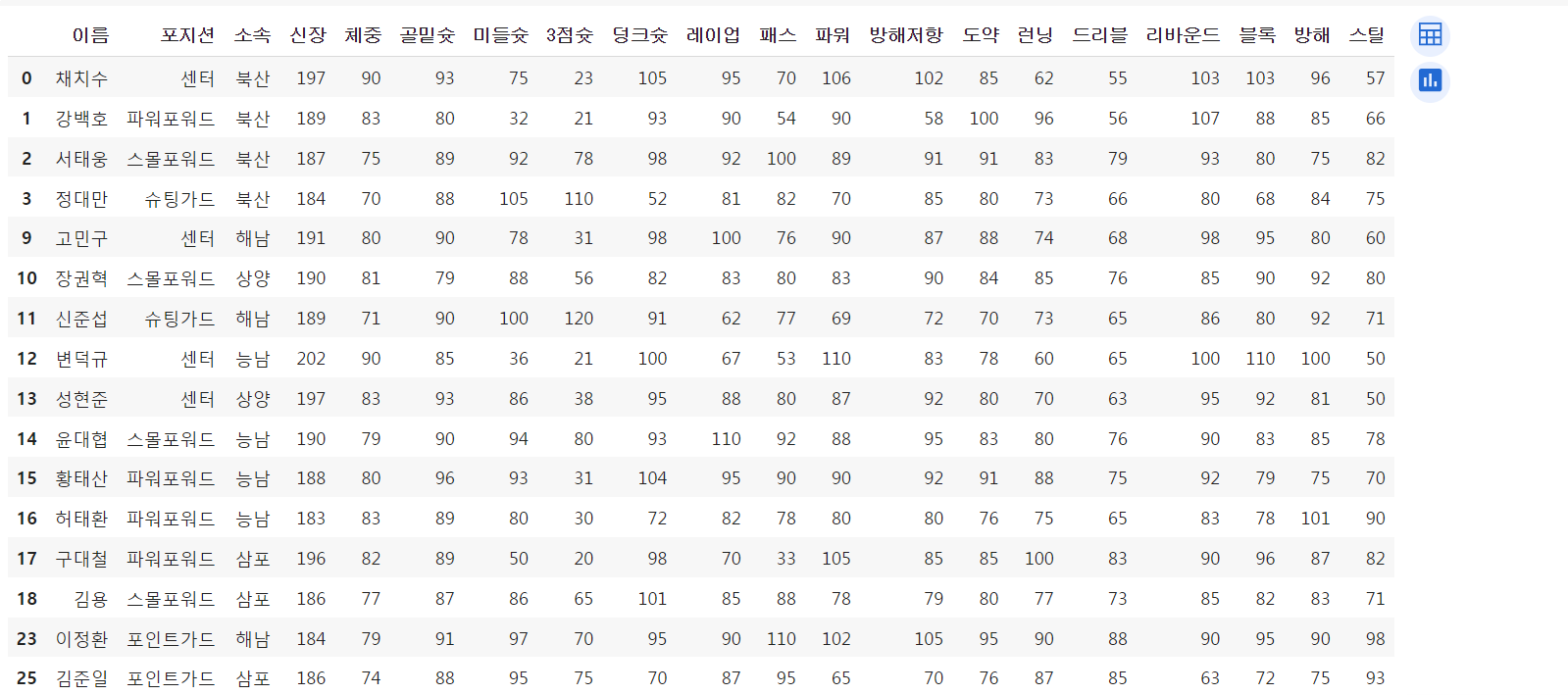
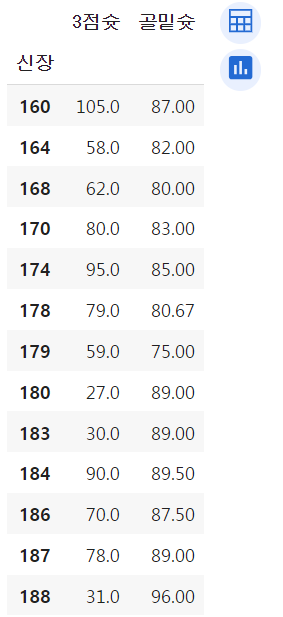
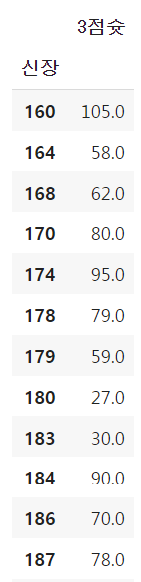
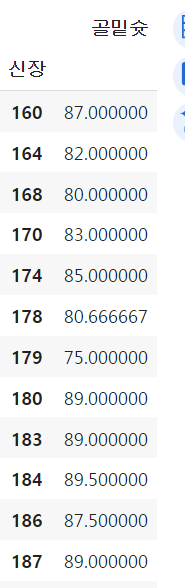
실습에 사용할 데이터는 '슬램덩크에 등장하는 농구선수 관련 데이터'임.
라이브러리 import
필요한 라이브러리 모듈 참조가 필요함.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns-
pandas 처럼 많이 참조되는 라이브러리 중 하나는 numpy.
numpy는 파이썬에서 과학적,수치적 계산을 수행하는데 사용되는 라이브러리.
-
예시에서는 시각화 해주는 라이브러리도 참조했는데 2가지가 있음.
1) matplotlib
2) seaborn
요즘은 seaborn을 더 많이 쓰는 추세임.
데이터 읽어오기
-
Pandas를 써서 excel 데이터를 읽어옴.
# read_excel : 엑셀 파일 읽기 df = pd.read_excel('./slamdunk_player_stats.xlsx')읽어와서 df라는 변수에 넣어주고 출력해서 데이터를 확인해봄.
-
데이터 일부를 출력한 결과

colab의 한글 이슈

데이터를 뽑고 구글에서 지원하는 시각화 기능을 누르면 시각화를 해주는데 에러가 발생. 에러 확인해보면 한글 관련 에러임을 알 수 있음.
한글 에러 해결은 로컬에서의 해결 방법과 클라우드에서의 해결 방법이 다른듯.....?
import os
if os.name == "posix" :
plt.rc("font", family = "AppleGothic") # 맥북
else:
plt.rc("font", family = "Malgum Gothic") # 윈도우-
위의 코드는 로컬환경에서의 해결 방법이니 코랩에서 유의미한 코드는 아님.
-
코랩에서는 폰트를 우선 설치해주어야 함.
!sudo apt-get install -y fonts-nanum !sudo fc-cache -fv !rm ~/.cache/matplotlib -rf어떤 폰트가 있는지 모르니 아는 폰트를 강제로 설치해줌.
위는 폰트를 설치하고 준비한 것일뿐 설정한 것은 아님.
plt.rc("font", family="NanumBarunGothic") # 폰트 설정이렇게하고 런타임을 재시작 해준 뒤, 데이터프레임 읽어오는 코드 재실행하고 시각화하면 에러없이 시각화가 잘 진행됨.
런타임 재시작 안해주면 다음과 같은 에러 발생.
📍 데이터프레임 구조 확인
1. df.info() : 데이터의 기본적인 구성을 보기

2. df.head(), df.tail() : 데이터의 앞/뒤쪽 확인하기
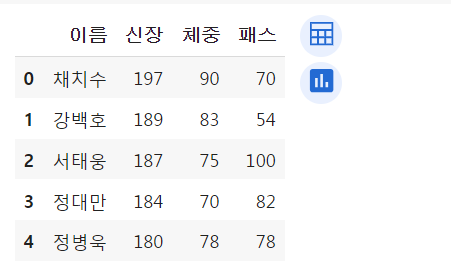
df.head() 인자를 안주면 앞쪽 5개 데이터 불러옴.

df.head(3) 다음과 같이 인자를 숫자로 주면 앞에서 데이터 3개 불러옴.

df.tail() 인자를 안주면 뒤쪽 5개 데이터 불러옴.

df.tail(3) 다음과 같이 인자를 숫자로 주면 뒤에서 데이터 3개 불러옴.

📍 행 조회(loc, iloc, slicing)
Pandas의 데이터구조 중 하나인 시리즈로 데이터를 조회함.
시리즈를 사용하기 위해서 대표적으로 loc이라는 속성을 사용해야함.
df.loc[1]
# series로 인덱스 레이블 조회하기
df.loc[1]여기서 1은 숫자가 아니라 인덱스 레이블을 의미. 1번 인덱스에 있는 레코드가 시리즈 형태로 반환됨.

df.loc[[1]]
# 데이터프레임으로 인덱스 조회하기
df.loc[[1]]결과가 이쁘게 안나오는데 데이터프레임 형태로 이쁘게 보려면 대괄호를 추가해주면 됨.

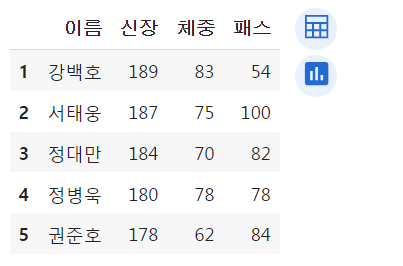
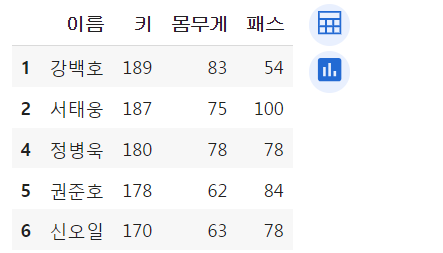
df.loc[[3,6,9]]
# 여러 행 조회하기
df.loc[[3,6,9]]여러행을 조회하고 싶다면 리스트 안에 넣어줌.

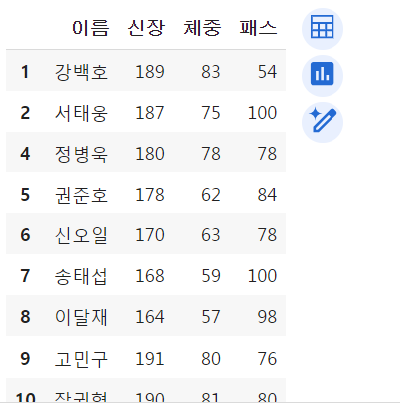
df.loc[3:7]
# 범위로 조회하기
df.loc[3:7]인덱스 레이블 범위로 조회하는 거도 가능함.

여기서 더 slicing하고 싶다면 두번째 인자로 열 이름 slicing 범위를 넣어줌.
# 범위로 조회하기
df.loc[3:7, "이름":"체중"]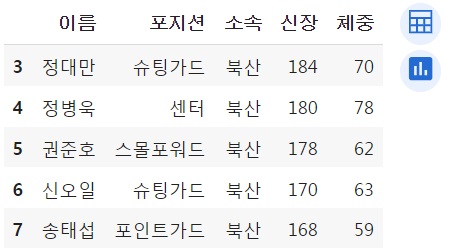
더 세분화된 슬라이싱 기법에 대해 소개.
df.loc[3:8:2]
3~8까지 볼건데 두 칸씩 뛰어서 데이터를 보겠다는 의미.
# 슬라이싱 기법으로 조회하기 1
df.loc[3:8:2]
df.loc[:, ["이름","포지션","소속", "리바운드"]]
이번에는 모든 선수들에 대해 전체 컬럼이 아닌 내가 지정한 컬럼에 대해서만 보겠음.
df.loc[:, ["이름","포지션","소속", "리바운드"]]
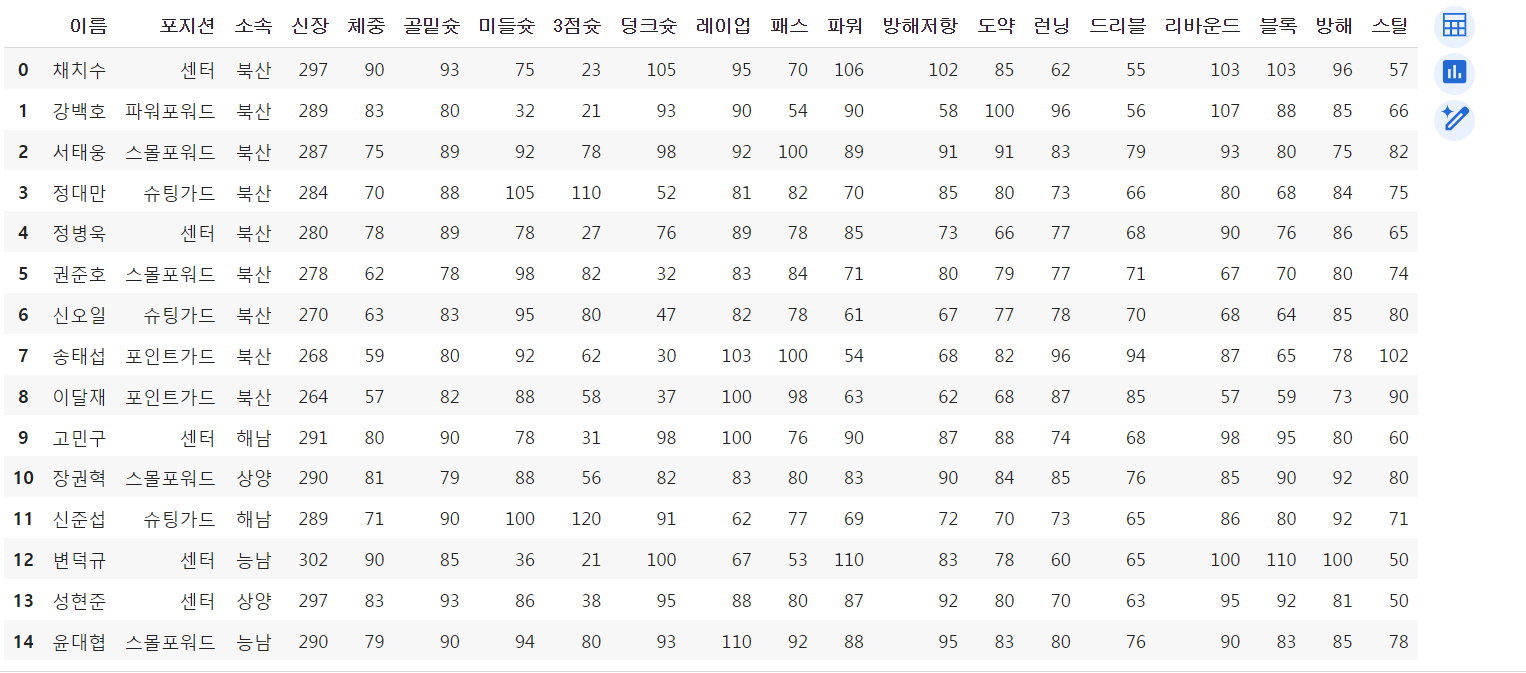
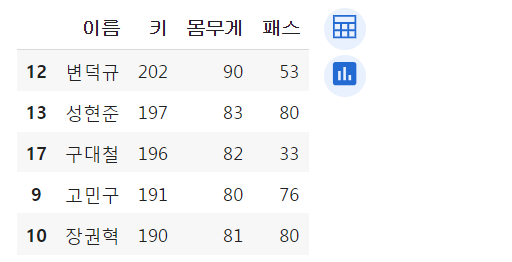
df.iloc[3:7, 0:5]
지금까지 레코드마다 부여된 번호로 접근했는데, 배열의 인덱스처럼 조회를 하고 싶다면 iloc 이용.
# index location으로 조회하고 싶다면 - iloc 사용
df.iloc[3:7, 0:5]원래 두번째 인자에 컬럼 이름 적어줬는데 인덱스 번호로 넣어줌.

📍 시리즈(Series)
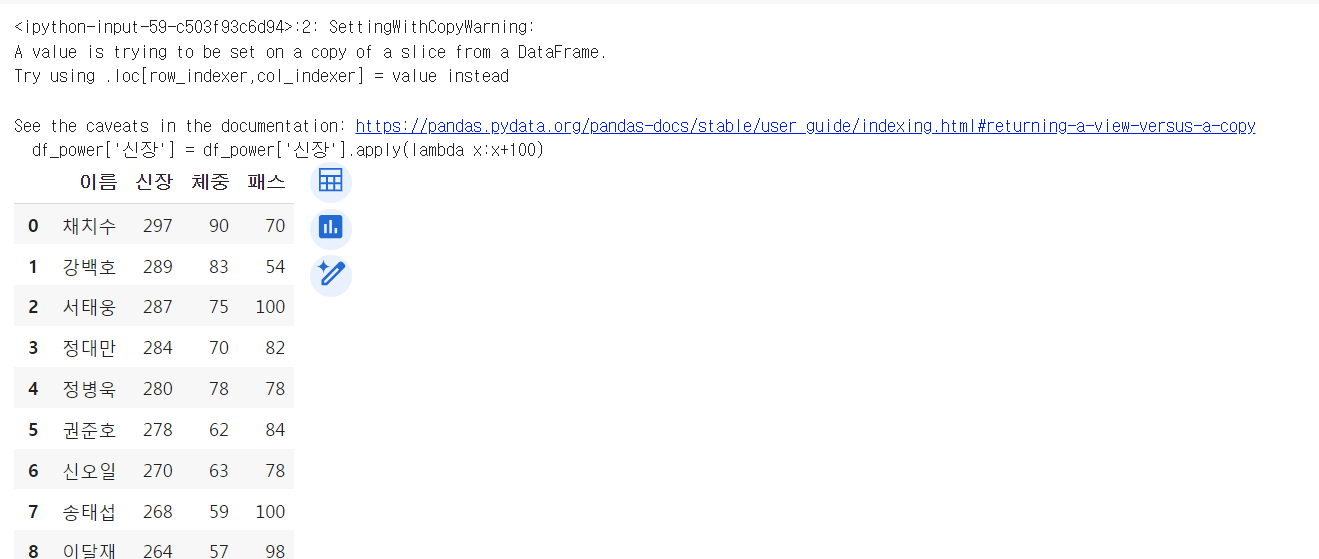
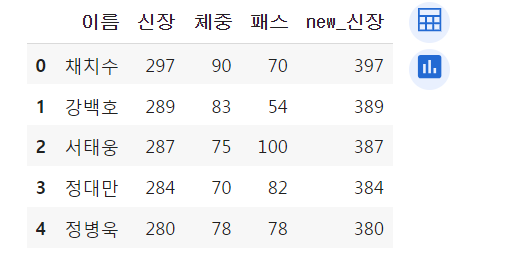
데이터프레임은 시리즈가 여러 개 붙어있는 형태.
따라서 데이터프레임에서 특정 레코드 한 줄을 수정하고 싶다면 특정 시리즈를 저장하는 변수에 수정을 해줌.
행 조회하기
# 행 조회하기 -> 시리즈 -> 1차원 데이터
df.loc[1]
열 조회하기
# 단일 열 조회하기 -> 시리즈 -> 1차원 데이터
df['이름']
타입 확인하기
# 타입 확인하기
type(df['이름'])# 타입 확인하기
type(df.loc[1])
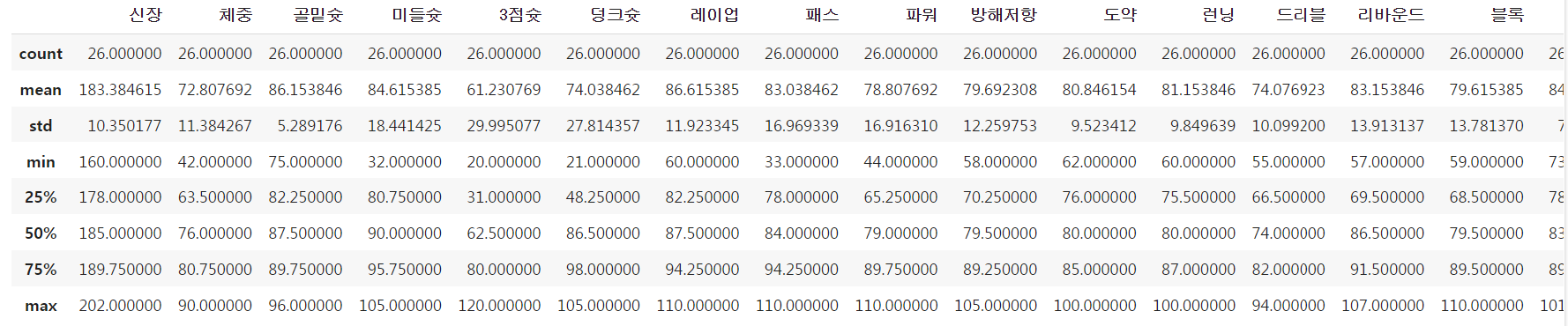
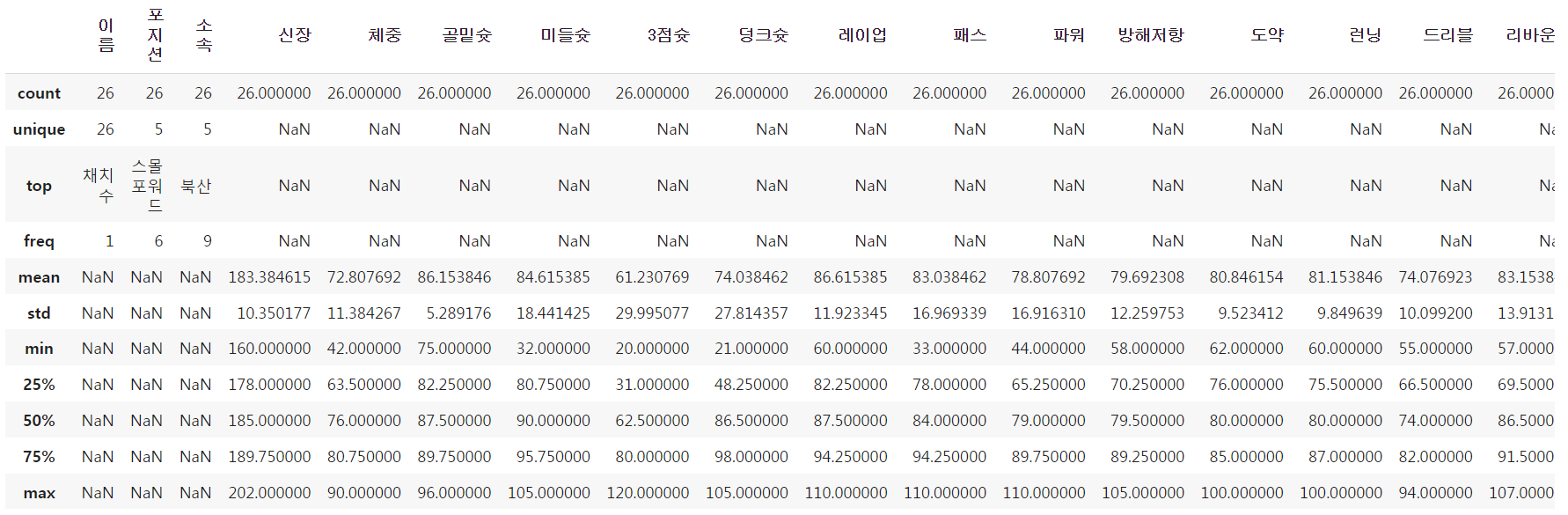
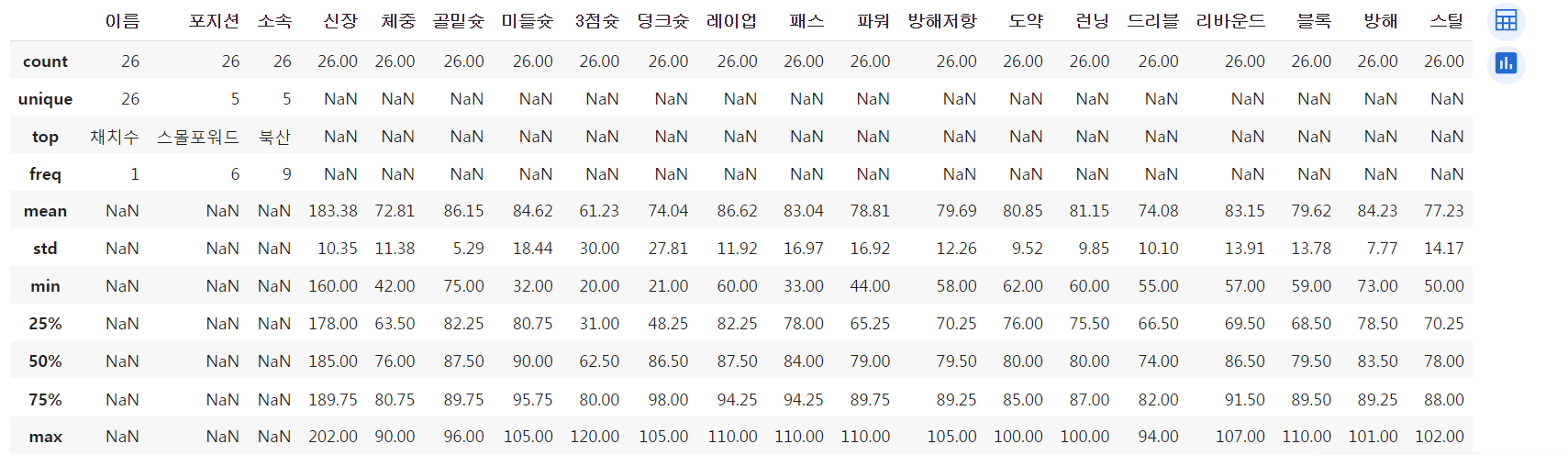
📍 기술 통계 - describe()
📍 문자 탐색 - .str.contains('문자')