📍 3-1. 데이터 기반 제품 개선이란?
머신 러닝 기술을 사용해 제품/서비스의 기능을 개선하는 것에 대해 살펴보자
데이터 과학자의 역할
-
Product Science하는 사람들
-
머신러닝을 활용하여 사용자의 경험 개선해줌.
문제 정의 ➡️ 데이터 수집 ➡️ 모델 빌딩 + 테스트
훌륭한 데이터 과학자란?
-
열정과 끈기가 있는지
-
다양한 경험을 해보았는지
-
코딩 능력을 갖추었는지
-
현실적인 접근 방법 이용하는지
➡️ 애자일 기반 모델링, 딥러닝이 모든 문제의 답은 아님(간단한 솔루션이 더 좋은 경우도 있음)
-
과학적인 접근 방법 이용하는지
➡️ 지표 기반 접근, 목표가 무엇이고 그걸 어떻게 측정할 것인지 명확하게 만들고 들어가는게 중요함
※ 제일 중요한 것은 모델링을 위한 데이터 존재 여부!
모델 개발 전체 과정(Life-Cycle)
문제 정의 ➡️ 훈련용 데이터 수집 ➡️ 모델 빌딩 + 테스트 ➡️ 모델 배포 ➡️ A/B 테스트 ➡️ 테스트 결과 분석 ➡️ 결과가 좋으면 전체 론치 / 결과가 안좋으면 이전 과정 반복
📍 3-2. 데이터 기반 제품 개선 케이스
머신 러닝 모델링 예시
1) 개인화된 추천 엔진
- 강사님께서 강의 추천을 규칙 기반 ➡️ 머신러닝 기반으로 전환하신 예시를 들어주셨음
2) 사기 결제 감지
-
이상값 탐지를 실행
-
머신 러닝의 편향성 or 머신 러닝 윤리의 중요성의 패턴이 나타남(?)
➡️ 데이터를 잘못 수집하면 bias 또는 윤리 문제가 발생. 예를 들어, 사기 결제가 중국에서 발생했는데, 훈련 데이터가 잘못 수집된 경우 중국에서 발생하는 결제를 다 사기라고 판단해버리는 경우가 발생
3) 환자 이상 징후 예측
- 과거 의료 데이터와 다양한 측정장비에서 측정되는 수치 정보들이 쌓이고 이것들을 바탕으로 이상징후 예측 모델을 만듦.
4) 농업용 자율 트랙터
- 존디어라는 회사는 머신 러닝을 사용해서 자율 트랙터를 개발함(밭을 탐색하고 효율적으로 수확 및 심기 같은 작업을 수행).
5) 의료 이미지 분석
-
VoxelMorph라는 오픈 소스 프레임워크는 딥러닝을 이용하여 MRI를 분석해줌.
-
원래 x-ray기반으로 심장병 진단이 가능한데 초음파 사진 기반으로 심장병을 진단하는 기술이 나오기도 함.
📍 3-3. 머신 러닝이란?
머신 러닝이 무엇이고 어떤 종류들이 있는지 알아보도록 하자
머신 러닝 정의
-
머신 러닝?
🔉구체적으로 프로그래밍을 하지 않고 배울 수 있는 능력을 컴퓨터에게 주는 분야의 연구(by Arthur Samuel) -
결국, 배움이 가능한 기계의 개발. 학습의 종류에 따라 지도학습, 비지도학습, 강화학습이 존재.
-
딥러닝(인공신경망)은 이 중의 일부. 이미지 처리/자연어 처리에 적용하기 좋음.
머신 러닝 모델이란?
-
머신 러닝 : 데이터로부터 학습을 하는 알고리즘
머신 러닝 모델 : 그러한 학습 결과로 만들어진 블랙박스(해당 모델을 가지고 실제 예측을 하게 되는 것) -
즉, 머신 러닝 모델은 학습된 결과가 들어가있는 블랙박스로써, 예측을 할 때 사용됨.
-
머신 러닝 모델은 데이터 과학자가 만들고 그 만들어진 모델을 실제 서비스에서 사용하기 위해서는 모델을 배포하고 api형태로 사용할 수 있게 해주어야하는데 이걸 담당하는 부서가 MLOps.
머신 러닝 종류
1) 지도 기계 학습 : 학습 데이터를 통해 학습(정답이 존재)
-
크게 2종류가 있음.
- 분류(이진 분류/다중 분류)
- 회귀 지도 학습(Regression, 연속적인 숫자가 되는 형태)
-
예시 1 : 타이타닉 승객 생존 여부 예측(이진 분류 문제)
-
탑승 승객별로 승객 정보와 최종 생존 여부가 트레이닝 셋으로 제공됨.
-
예측 해야되는 정보를 label/target이라고 부름.
-
기존 필드(피처)를 그대로 쓰는게 아니라 사용하기 쉬운(문자->숫자 변환) 형태로 바꾸는 걸 feature engineering이라고 부름.
-
-
예시 2 : 스팸 웹 페이지 분류기(이진 분류)
-
정상 웹 페이지인지 스팸 웹 페이지인지 분류
-
언어를 모르는 경우 어떻게 판단?
🔉 문자열로 된 훈련데이터는 그대로 머신 러닝에 쓸 수가 없음. 어떻게든 숫자의 집합으로 바꿔주어야 함. 문장을 형태소 분석을 해서 품사별로 떼어내고 조사,명사 등의 비율을 분석하여 판단. 스팸 페이지의 경우 명사의 비율이 더 클 것임.
-
-
지도 기계학습 과정
훈련 데이터가 주어짐(label/target이 존재하며 Y로 표현됨)
➡️ 전처리를 통해서 트레이닝 셋에서 숫자가 아닌 값들을 숫자로 바꾸던지 사용을 안하던지 함
➡️ 학습 알고리즘으로 훈련
➡️ 머신러닝 모델이 만들어지는 거
➡️ 만들어진 모델을 배포를 하고 사용해야함(이걸 추론/예측이라고 함)
➡️ 배포가 되고 api 형태로 노출이 되면 넘겨주고 모델 출력이 return되는 형태가 됨(?)
2) 비지도 기계 학습 : 데이터를 주면 특정기준으로 그룹핑을 하는 거
-
예시 1 : Language model
-
GPT가 그 예시. GPT는 Large Language Model(LLM).
-
Language model을 어떻게 훈련하고 빌드하나?
🔉문장을 주고 context window 이동시키면서 다음 단어를 정답으로 주고 예측하게 훈련하는 거(정답지를 주지 않아도 문장이 들어있는 페이지 선택하면 인풋과 정답이 다 들어있는 거)
-
3) 강화 학습 : 게임 같은 환경에서 어떻게 플레이를 하면 이기고 지는지 학습하는 거(ex.알파고,자율주행)
📍 3-4. ML 모델 개발 시 고려할 점
현업에서 모델 개발 시 알아야할 점들은?
모델 개발 시 마찰이 생기는 지점 - 개발된 모델의 이양 관련
- 데이터 과학자들의 일반적인 생각
- 데이터 과학자: 문제를 풀기 위한 좋은 머신 러닝 모델을 만들겠어!
데이터 엔지니어: 모델 만들고 다음 스텝은 뭐야?
데이터 과학자: ???
- 데이터 과학자: 문제를 풀기 위한 좋은 머신 러닝 모델을 만들겠어!
-
데이터 엔지니어들의 일반적인 생각
- 데이터 엔지니어: 머신 러닝 모델을 받긴 했는데 어떻게 배포하지?
데이터 과학자: 모델이 잘 론치 되었어?
데이터 엔지니어: ???
- 데이터 엔지니어: 머신 러닝 모델을 받긴 했는데 어떻게 배포하지?
-
많은 수의 데이터 과학자들은 R을 비롯한 다양한 툴로 모델 개발
-
프로덕션 환경을 고려하지 않고 데이터 과학자가 모델을 만들게 됨
(실제 프로덕션 환경은 다양한 모델들을 지원하지 못함)
➡️ 운영하는 관점에서 모델이 바로 안돌아가니까 불필요한 작업이 더 필요함
➡️ 많은 회사들이 R로 모델 만들지 말고 파이썬 같은 머신러닝 모델과 서빙이 가능한 언어를 쓰도록 함
모델 개발 시 기억해야 할 포인트 1
-
모델 개발부터 최종 론치까지 책임질 사람이 필요함.
-
모델 개발 초기부터 개발/론치 과정을 구체화하고 소통해야함.
ex) 모델 개발 시 모델을 어떻게 검증? / 모델을 어떤 형태로 엔지니어에게 넘길 것인지? 등등
모델 개발 시 기억해야 할 포인트 2
-
개발된 모델이 바로 프로덕션에 론치가능한 프로세스/프레임워크가 필요함.
ex) R로 개발된 모델은 바로 프로덕션 론치가 불가능,
머신 러닝 전반에 걸친 빌딩/배포 프레임워크가 나오고 있는데, 대표적인게 AWS의 SageMaker.
모델 개발 시 기억해야 할 포인트 3
-
첫 모델 론치는 시작일 뿐이고 론치가 아닌 운영을 통해서 개선을 이뤄내는게 필요함. 결국 피드백 루프가 필요.
-
개선점이 보이면 모델 재빌딩하고 배포하고 반복. 반복하는게 중요해지다보니 모델을 계속 빌딩하고 배포해주는 과정에서 자동화하는게 필요해지고 이런 일을 전문적으로 하는 직군이 MLOps.
📍 3-5. MLOps란?
모델 빌드, 배포, 모니터링 전체 프로세스를 자동화하는 직군!
Data Drift로 인한 모델 성능 저하
- MLOps가 왜 필요한가?
🔉 그 이유는 모델을 한번 만들어서 배포하면 시간이 지나면서 성능이 떨어지게됨(데이터가 계속해서 변화하기 때문. 사용자들이 사용하는 패턴이 달라짐)
➡️ 이를 data drift(데이터 성격이 달라지는거)라고 부르며 이를 모니터링 하는 것이 중요
MLops vs. DevOps
-
DevOps
-
코딩을 하지는 않고 개발해주는 엔지니어들이 따로 있음. 엔지니어들이 만든 코드를 가지고 거기에 테스트 돌리고 배포할 수 있는 패키지로 만들고 프로덕션 서버에 배포하고 모니터링 하는 사람(코드부터 서비스 운영까지 전체 프로세스를 담당해주는 직군)
-
개발자가 만든 코드를 시스템에 반영하는 프로세스(CI/CD)
-
-
MLOps
-
DevOps에서 대상이 개발자들이 만든 코드였다고 하면, MLOps 대상은 데이터 과학자들이 만든 머신 러닝 모델이 되는 것. 모델에다가 오프라인 테스트(훈련에서 쓴 데이터 20퍼를 테스트용으로 남겨두고 이것으로 테스트 하는 것?) 돌려보고 결과가 좋으면 프로덕트 쪽에 배포를 함
-
모델 서빙 환경과 성능 저하를 모니터링
Latency : 실행시간. 모델이 결과를 얼마나 빨리 return하는지
-
CI & CD
-
CI(Continuous Integration) : 코드 리포에 코드를 바꾸는 순간 테스트가 문제없이 돌면 코드를 배포하기 쉬운 형태로 만드는 거(개발자가 코드를 변경할 때 마다 테스트 돌려서 새 코드가 문제 없음을 체크하는 거)
-
CD(Continuous Delivery) : 제대로 빌딩된 CI가 있는 경우 그 결과로 나온 패키지를 프로덕션 서버로 배포하는 거(CI가 끝난 코드를 배포하는 거)
-
DevOps에서 CI,CD 같은게 MLOps 관점에서는 CT(Continuous Training). 자동으로 훈련 데이터 수집하고 모델 빌딩 및 테스트, 배포를 자동화해서 효율을 높이는 거
📍 3-6. 머신 러닝 사용 시 고려할 점
머신 러닝(or AI)을 제대로 사용하는 것은 쉽지 않다. 어떤 고려할 점들이 있는지 알아보자
데이터 윤리와 주의할 점, MLOps
-
데이터로부터 패턴을 찾아 학습
-
데이터 품질과 크기 중요(같은 품질이면 크기가 클수록 힘이 강해짐)
-
데이터 수집 잘못하면 bias가 생김(원치않은 문제발생, 윤리 문제 등)
-
내부 동작 설명 가능 여부도 중요(예를 들어 의료계에서 병을 진단하는 모델이라면 왜 그러한 진단을 했는지 이유가 필요하기도함)
➡️ ML Explainability -
데이터 권리도 중요한 문제(이미지 모델의 경우 원본 이미지 만든 사람이 보상받아야 하는거 아닌지? 와 같은 이슈)
-
데이터 기반 AI는 완벽한가 ?
1) 데이터 양도 중요한데 품질이 중요
ex. 미국 EMR이 좋은 예시. EMR은 환자의 병력을 자세히 기록해서 미래에 도움을 받으려는 목적이 아닌, 법적인 제제를 받지 않기 위해(소송을 막기위해) 기록하는 용도로 만들어짐. 좋은 데이터 같지만 시스템이 만들어진 이유를 살펴보면 그렇지 않다는 것!
2) 의료계 같은 경우, 어떤 결과에 대한 설명이 가능해야해서 불가능한 분야에 머신 러닝 모델을 만드는 것 의미가 없음
3) AI 도입시 문제들을 어떻게 해결할 것인지?
🔉혁신을 만들어낼 생태계와 법률이 필요 --> EU의 관련 법규를 많은 시사점을 줌: Trustworth AI
잘못된 개인정보 보존으로 인한 페널티
- HIPAA - 전자 의료 정보를 보호하려는 목적
GDPR/CCPA - 유럽연합과 캘리포니아 주의 온라인 상에서 개인정보 보호에 관한 법률
AI의 발전과 미래 직업의 변화 : 예 - 의사의 역할
-
AI가 의사를 대체하기 보다는 의사의 효율성과 진단/치료의 정확성을 높이는 보조적 역할
-
미래의 의사모습은?
🔉 현대 비행기의 기장과 같이 될 것 : 운항 시스템이 알아서 조종하고 비상 시 기장이 개입하는 형태로 진행됨. 미래의 의사도 비슷한 구조로 되지 않을까 생각
📍 3-7. [실습] 정의하고 차트 만들어보기
Simple ML for Sheets를 사용해보자
-
Simple ML for Sheets 이용하여 실습을 진행.
-
시트 상의 데이터를 훈련 데이터로 쓰고 컬럼 중 하나가 label/target이 되면서 그 값을 예측하게 훈련을 해서 label/target 값이 비어있는 곳을 채워주는 실습.
-
Simple ML for Sheets
- 구글 스프레드시트의 무료 확장판
- 시트상의 데이터를 훈련 데이터로 간단한 머신 러닝 모델을 만들어볼 수 있음
- 해볼 수 있는 task가 많은데 이번 실습에서 하는거는 "predict missing values"
-
실습 단계
1) Simple ML for Sheets 설치
2) 강의자료에 있는 예제 시트를 복사
3) 예제 시트를 보면, species컬럼 중 비어있는 칸이 존재. 차있는 훈련 데이터를 사용해서 머신 러닝 모델을 만들고 비어있는 칸을 예측해볼 것임
4) 예제 시트에서 "확장프로그램" 누른 뒤 Simple ML for Sheets에서 "start" 버튼 누름
➡️ 이러면 오른쪽에 Simple ML for Sheets라는 메뉴바가 생성됨(3가지 task중 predict missing values를 수행)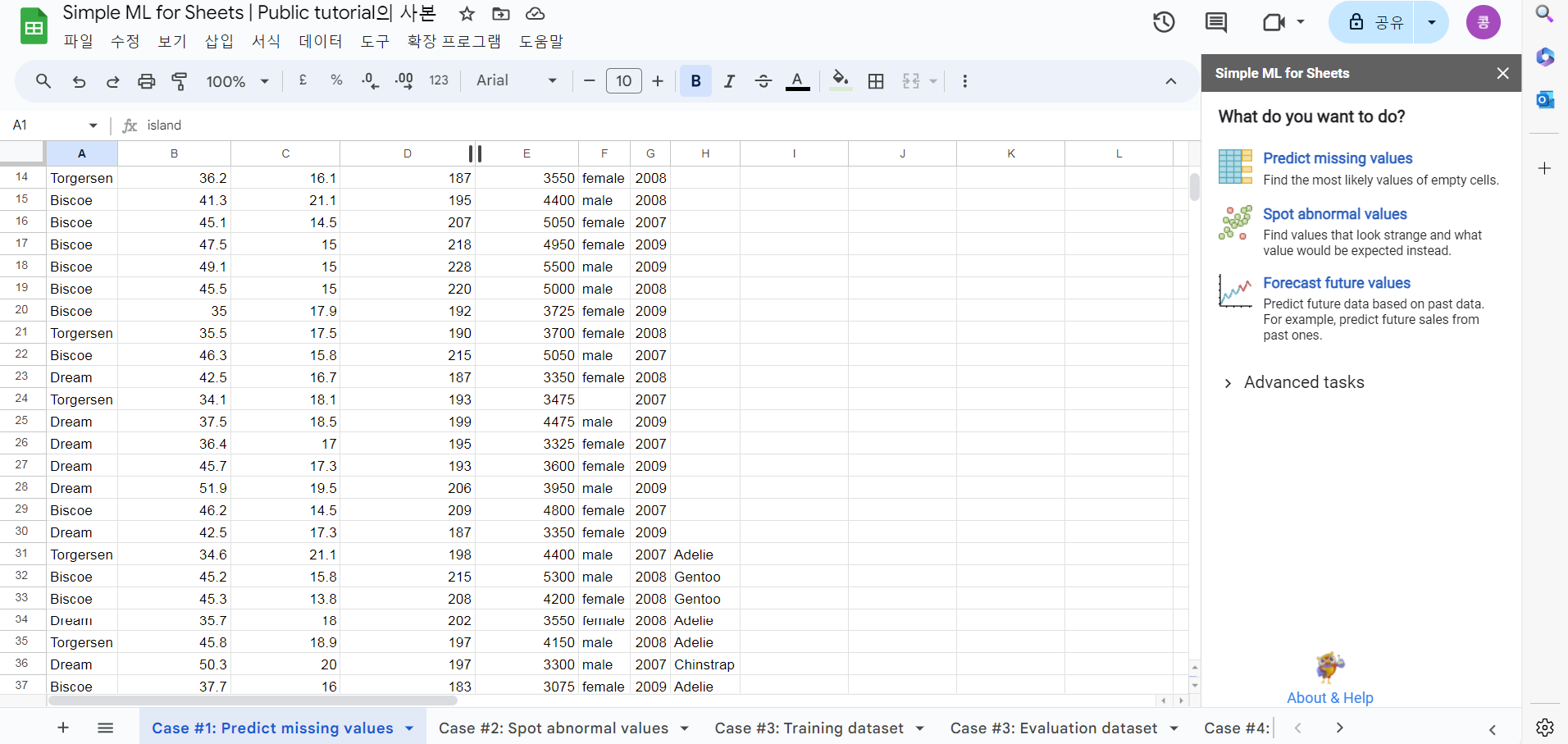
5) predict missing value를 누르게 되면 또 다른 팝업이 생성되고 해당 팝업에서 "predict"버튼 누르면 모델을 빌딩하고 predict까지 해줌(speices 옆에 두 개의 컬럼이 추가됨)
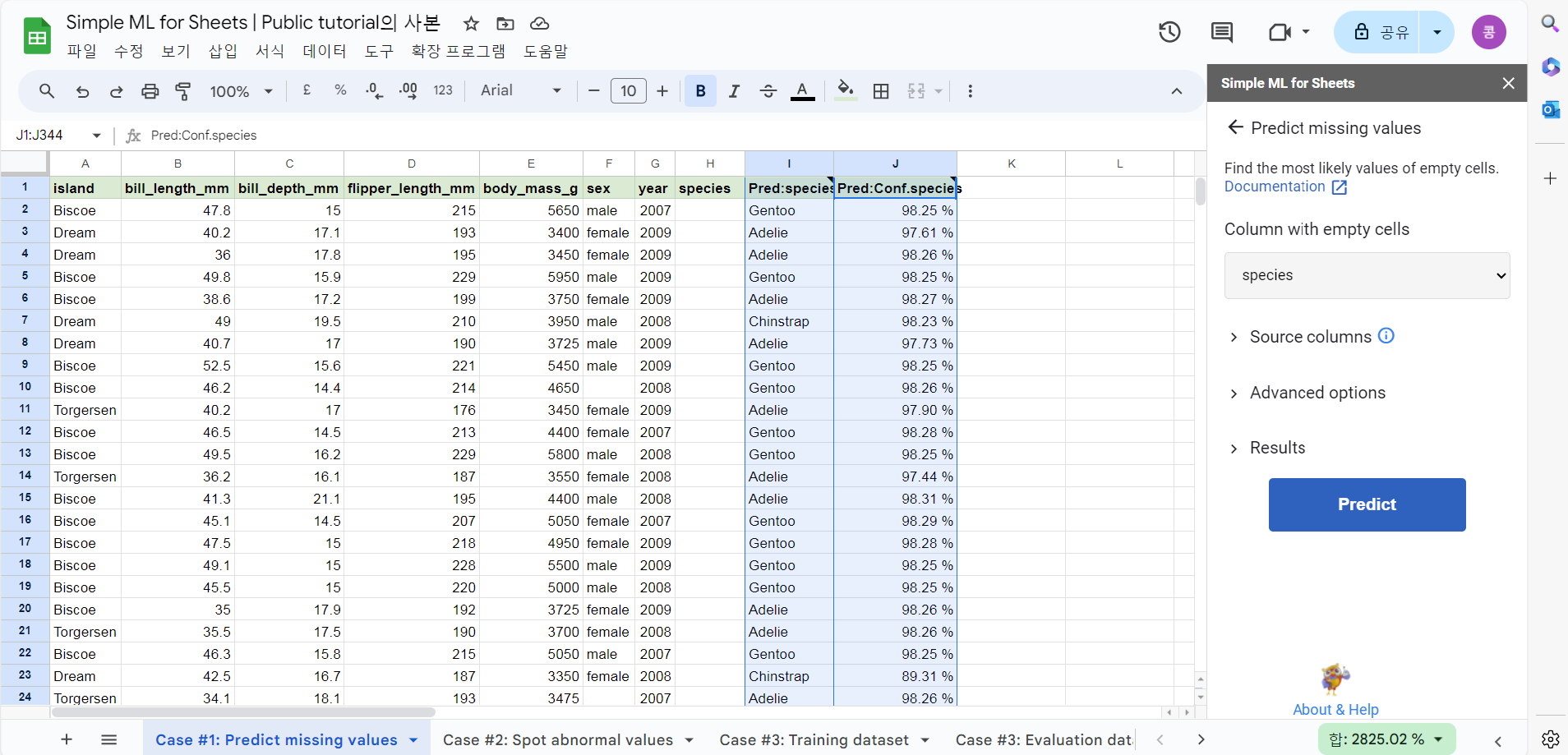
- 이 때 I 컬럼은 예측된 species값, J 컬럼은 예측 시 가지고 있는 확신도
