📍 4-1. 이전 강의 퀴즈 리뷰
학습 내용을 퀴즈 형태로 리뷰해보자
✅ 1
Q : 데이터 분석가가 속한 팀은 뭐라고 부르는가?
A : Decision Science / Product Science(데이터 과학가가 속한 팀) / Data Engineering(데이터 엔지니어가 속한 팀)
✅ 2
Q : 데이터 분석가가 가치를 만들어내는 일반적인 방법이 아닌 것은?
A : 중요 지표 정의 / 대시보드 작성 및 운영 / 데이터 기반 리포트 작성 / ETL 시스템 운영(데이터 엔지니어 역할)
✅ 3
Q : 데이터 분석가에게 필요한 역량이 아닌 것은?
A : SQL / ELT와 데이터 모델링 / 통계적 지식 / 이벤트 로그 수집(데이터 엔지니어가 보통하는데 회사에 따라서 백엔드 엔지니어가 하기도 함)
✅ 4
Q : 애자일 개발 방법론에서 필요한 미팅이 아닌 것은?
A : 플래닝 미팅 / 스탠드업 미팅 / 회고 미팅 / 스태프 미팅(애자일과 전혀 관계없는 미팅)
✅ 5
Q : 다음 중 일반적으로 KPI라고 할 수 없는 것은?
A : 매출 / 유료 고객 수 / 등록 회원 수(등록 회원 수가 많다고해도 실제 서비스를 이용하는 사람이 일부이면 의미가 없는 지표, 허영지표)
✅ 6
Q : KPI의 특징이 아닌 것은?
A : 후행지표 / 선행지표 / 회사에 중요한 가치를 표현
✅ 7
Q : 다음 중 연속적인 값을 예측하는데 사용되는 ML은?
A: Binary Classification / Multiclass Classification / Regression / Reinforcement Learning
✅ 8
Q : 훈련 데이터에 답이 존재하는 형태의 머신러닝을 무엇이라고 부르는가?
A : Supervised Learning / Unsupervised Learning / Reinforcement Learning
✅ 9
Q : ML 모델의 빌딩, 테스트, 배포, 모니터링을 담당하는 직군을 무엇이라고 부르는가?
A : MLOps
✅ 10
Q : ML 모델을 만들 때 사용했던 피처의 분포가 바뀌는 현상을 뭐라고 부르는가?
A : Data Drift
📍 4-2. Gen AI란? - 1
생성형 AI가 무엇인지 알아보자
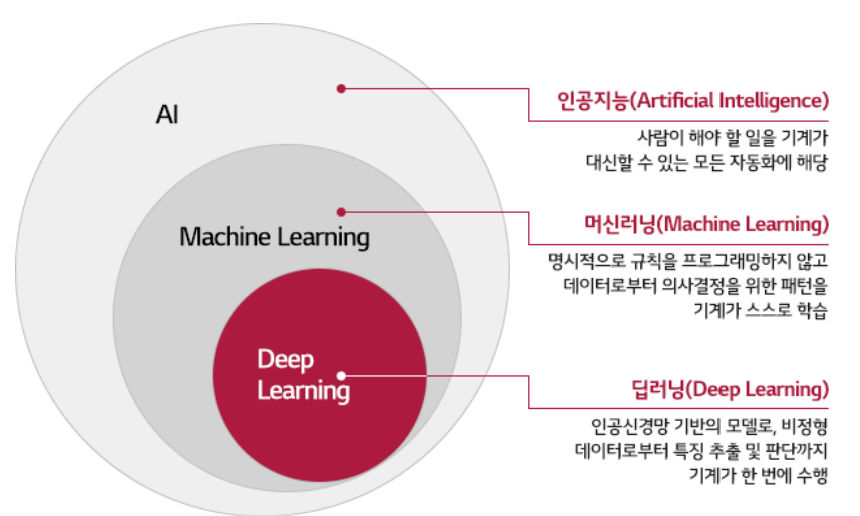
인공지능, 머신러닝, 딥러닝
-
인공지능 : 인간이 하는 일을 대신해주는 시스템을 만드는 컴퓨터 과학을 말함
-
머신러닝 : 인공지능의 일부
-
딥러닝(인공신경망 기반) : 머신러닝의 일부, 인공신경망 사용해서 기존 머신러닝 알고리즘이 처리 못하는 복잡한 패턴 처리 가능, 인공신경망이 발전하면서 이미지/비디오/오디오 등의 복잡한 데이터 처리에 적합
 ※ 이미지 출처 : LG CNS
※ 이미지 출처 : LG CNS
Gen AI란?
-
Gen AI = Generative AI
-
학습된 컨텐츠 바탕으로 새로운 컨텐츠를 만드는 딥러닝 기술
ex) GPT와 같은 입력 컨텐츠 내용을 학습한 모델이 만들어짐
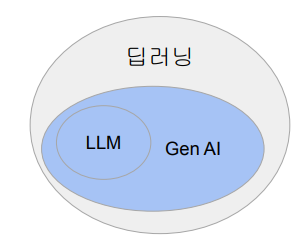
딥러닝과 Gen AI와 LLM의 관계
-
Gen AI는 딥러닝의 일부
-
LLM(Large Language Model)은 Gen AI의 일부
딥러닝의 모델 타입
1) Discriminative
- 분류/예측을 하는 것으로 label이 존재하는 데이터에 적용
- feature들과 label간의 관계를 학습(ex.개/고양이 분류)
2) Generative
- 훈련 데이터와 비슷하지만 새로운 데이터를 생성(ex. 개 이미지 생성)
- 비지도 학습에 해당
- 훈련된 데이터의 통계적 특성을 이해
Gen AI 모델과 일반 ML 모델의 동작 방식
-
일반 ML 모델에서 y는 보통 숫자(regression), 카테고리(classification), 확률 등이 됨.
-
Gen AI 모델에서 y는 보통 자연어 문장, 이미지, 오디오 등이 됨.
Gen AI 의 파운데이션 모델
-
파운데이션 모델이라함은 누군가 시간과 노력을 들여서 광범위한 데이터셋을 바탕으로 학습을 시킨 모델을 말함. 이러한 파운데이션 모델은 pre-trained 되었다고 말함.
-
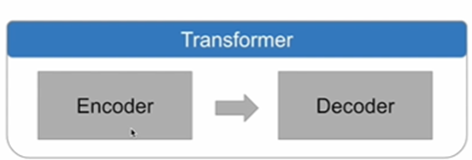
Gen AI의 파운데이션 모델은 트랜스포머 모델 아키텍처를 사용함.
-
Gen AI의 파운데이션 모델은 일반적인 모델이라 특정 토픽에 대해서는 성능이 안나올 수 있지만 다양한 토픽에 대해 어느정도 성능이 나옴
-
Gen Ai 예시: GPT-3, GPT-4 / BERT / T5 / DALL-E 등
Gen AI 의 파운데이션 모델과 파인튜닝
-
pre-trained 모델을 적용하고 싶은 분야에 커스텀하고 싶다는 니즈가 생김 ➡️ 파운데이션 모델을 파인튜닝 형태로 특정 지식을 학습시킴
ex) GPT라는 pre-trained된 LLM이 있는데, 다양한 대화 예제 넣어서 파인튜닝한게 chat GPT
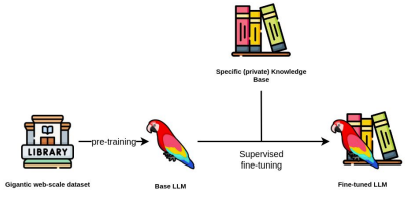
Gen AI 의 모델들
1) Generative Language Models
- 훈련 데이터로부터 제공된 문장들로부터 언어 패턴을 학습한 모델
- 문장 일부를 받으면 다음 단어 예측
2) Generative Image Models
- 새로운 이미지를 만드는 모델
Gen AI 모델의 한계 = 헛소리/환각(Hallucinations)
- 모델이 부정확하거나 무의미하거나 조작된 정보를 생성하는 경우가 존재
➡️ 사실 확인이 필요 - 발생 이유
➡️ 훈련 데이터 불충분, 훈련 데이터 품질 이슈, 훈련 데이터 최신성 부족, 모델에게 충분한 요구(?)가 주어지지 않음(프롬프트 디자인 중요)
📍 4-3. Gen AI란? - 2
입력에 따른 Gen AI 모델 : Input이 이미지인 경우
1) output이 image인 경우
- 해상도가 낮은 이미지를 입력으로 줘서 이미지 개선하는 경우
- 지우고 싶은 영역 삭제해주고 배경을 적당히 생성해주는 경우
2) output이 text인 경우
- 이미지를 주고 이미지에 대한 설명이 나오는 경우
- 이미지를 바탕으로 그 이미지에 대한 질문과 대답을 하는 경우
- 이미지를 주고 비슷한 이미지를 찾는 경우
3) output이 video인 경우
- 이미지를주고 애니메이션 비디오로 만들어 주는 경우
입력에 따른 Gen AI 모델 : Input이 텍스트인 경우
1) output이 image인 경우
- 텍스트를 기준으로 이미지를 만드는 경우
2) output이 text인 경우(가장 흔한 패턴)
- 주어진 텍스트를 번역하는 경우
- 주어진 텍스트를 요약하는 경우
- 텍스트에 대해 질문과 답을 하는 경우
- 주어진 텍스트의 문법이 맞는지 체크하는 경우
3) output이 video인 경우
- 텍스트 기반으로 비디오를 만들어 주거나 3D 이미지를 만들어 주는 경우
4) output이 audio인 경우
- 텍스트를 주면 읽어주는 경우
- 주어진 텍스트에 맞게 음악을 만들어주는 경우
5) output이 task인 경우
- 코딩보조를 하는 경우
- 비서역할처럼 하는 경우
- 특정 도메인의 일을 자동화해주는 경우
멀티모달 파운데이션 모델
-
파운데이션 모델 예시는 GPT. 해당 모델을 파인튜닝해서 다양한 task에 이용할 수 있음.
-
하나의 모델이 여러개의 task를 서포트하는 거를 멀티모달이라고 부름.
Gen AI 의 기타 문제점
-
웹에서 무단으로 이미지 스크랩하여 모델 학습하는 경우 이미지에 대한 저작권이 걸려 소송하는 사례
-
무단으로 코드 재사용으로 소송 제기된 사례
-
나라마다 입장이 다름
-
노동 시자엥 주는 잠재적인 악영향(stackoverflow와 같은 경우 트래픽 감소로 인력해소)
-
가짜뉴스 생성 문제 발생
📍 4-4. ChatGPT 발전 살펴보기
ChatGPT 3부터 발전 속도가 가속화 되었는데 이에 대해 알아보자
GPT(Generative Pre-trained Transformer)
-
OpenAI에서 만든 초거대 언어모델(LLM)
-
처음에는 두 가지 모델을 제공
1) Word completion : 다음 단어 예측(다양한 언어 지원)
2) Code completion: 다음 코드 예측
GPT-3 vs. GPT-4
-
GPT-3
-
175B개의 파라미터
-
Context window의 크기는 2048 + 1 (입력되는 context가 2048개 단어로 구성, 다음에 올 단어 예상하는 형태로 학습)
-
단어의 경우 임베딩이라는걸 하게 되면서 n차원의 스페이스로 매핑하게 되는데, 이때 사용하는 차원이 12,288개(12,288개의 워드벡터 사용)
-
-
GPT-4
-
1T개의 파라미터
-
Context window의 크기는 8192 + 1 (입력되는 context가 8192개 단어로 구성, 다음에 올 단어 예상하는 형태로 학습)
-
단어의 경우 임베딩이라는걸 하게 되면서 n차원의 스페이스로 매핑하게 되는데, 이때 사용하는 차원이 32,768개(32,768개의 워드벡터 사용)
-
-
GPT-4 Turbo
-
Context window의 크기가 128K로 확장됨
-
RAG 기능 제공(Gen AI가 새로운 기능을 습득해야될 때 파인튜닝이 어려우니 프롬프트 만들 때 제약조건 형태로 '이거까지 참고해줘'할 수 있는데 이때 많이 쓰는게 RAG. 회사 내 유스케이스에 적합한 사전정보?같은거라고 생각하면 됨)
-
정보 업데이트
-
Chat GPT 소개
-
2022.11.30 발표
-
GPT를 챗봇 형태로 파인튜닝한 것
-
다양한 용도로 사용가능(ex. 질문에 대한 답변, 번역, 코드 생성 및 리뷰 등)
파인 튜닝(Fine Tuning)
-
이미 만들어진 모델(pre-trained model)위에 새로운 레이어를 얹히고 사용하려는 용도에 맞게 커스터마이즈 시킨 거(다른 용도의 데이터로 훈련하는 것). 이미 만들어진 모델을 수정하는게 아니라 얹은 레이어만 건드는 거.
-
GPT를 chat GPT로 어떻게 파인 튜닝을 했는지?
🔉그 방법이 RLHF(Reinforcement Learning from Human Feedback)
🔉chat GPT 훈련방식 : chat GPT 가 만들어 준 응답이 여러개가 있는데 이를 사람들이 평가해서 모델을 재 트레이닝함(사람 피드백 기반으로 대화하는 인공지능 모델 학습)
좋은 프롬프트란?
-
Chat GPT를 활용하는 방법은 어떻게 명령을 주는가가 중요해짐. 이러한 명령들을 프롬프트라고 부름.
ex) 예를 들어, 간략하게 '이거 해줘'가 아닌 역할을 부여하거나 해야하는 업무를 자세히 써줌(주제 등) 제한이 있으면 제한을 주는게 좋음(줄 수)
Chat GPT 4.0
-
4.0에서는 code interpreter가 추가 됨(코드 작성하면 주피터 노트북 위에서 실행할 수 있게 해줌)
-
이미지 업로드 지원
-
인터넷 통해 일부 검색 가능
-
플러그인 지원
-
멀티모달 가능
더 많은 특징은 강의자료 참고!
Chat GPT 4.0 플러그인
-
플러그인은 뭘까?
🔉 예를 들어 chat GPT를 사용해서 여행계획을 짠다고 생각해보자. 비행기, 호텔, 렌터카 예약 등이 필요함. 이전까지의 chat GPT는 계획만 해주고 실제로 이행해야하는건 사람. 한 단계 더 나아가 계획뿐만 아니라 플러그인 쓰는 사용자면 여행 관련 예약으로 연결해주는 거
GPTs : 에이전트 기능 구현(커스텀 챗봇)
-
GPTs : 커스텀 챗봇을 쉽게 만들어주는 기능. 원래는 파인튜닝 api써서 직접 만들어야했는데, GPTs쓰면 GPT에 내 환경에 맞는 버전을 만드는 거
- 예시 : 어린이 코딩 교육으로 유명한 code.org lesson planner라고 해서 code.org에 있는 컨텐츠를 바탕으로 교사 같은 사람들에게 커리큘럼을 쉽게 만들 수 있는 챗봇모델을 만들어서 퍼블리쉬 함
-
GPTs store : 내가 만든 GPT를 다른 사람도 쓸 수 있게 하는 거
📍 4-5. Gen AI 적용케이스
Gen AI 적용 케이스들을 살펴보자
Gen AI 적용케이스
1) Quizlet
- 미국 초중고에서 많이 사용하는 학교에서 배운 자료 업로드, 질문 공유 하는 서비스
- chat GPT로 구축된 Q-chat이라는 개인 튜터 만들었는데, 이는 Quizelet이 가지고 있는 다양한 컨텐츠를 가지고 파인튜닝된 것
2) Duolingo
- 언어 학습 앱
- 프리미엄 기능으로 GPT 써서 AI 파트너와 roleplay, 실수할 때 문법 규칙을 세분화해서 설명하는 기능을 추가함
3) Morgan Stanley
- 미국의 유명한 파이낸스 회사
- 내부 직원을 위해 자산관리와 관련된 방대한 데이터 검색용 챗봇 개발
4) Viable
- GPT-4를 써서 서비스에 대한 리뷰처럼 정형화하기 힘든 텍스트 정보들을 가지고 다양한 시그널을 추출해서 분석하기 쉬운 형태로 만들어 줌
- LLM을 파인튜닝해서 비정형 데이터 분석용 모델이 생성된 거
5) Buzzfeed
- chat GPT를 사용하여 즉석에서 퀴즈를 만드는데 사용
- 자회사인 Tasty 어플에도 chat GPT를 사용하여 레시피를 추천해주는 챗봇 만듦
📍 4-6. [실습] Gen AI를 활용한 업무자동화
마케팅 문구 생성 / 데이터 분석 / 코드 작성 중 데이터 분석을 진행해본다
Chat GPT code interpreter를 사용한 데이터 분석
-
chat GPT에 code interpreter 기능이 있음. 이거를 통해 데이터 분석을 해볼 수 있음.
-
강의 자료에 첨부된 Gapminder 데이터로 분석해볼 예정. 나라별로 특정 년도에 인구가 얼마이고, 어디 대륙에 속하고, 평균 수명은 어떻고, gdp는 어떤지 들어있는 데이터.
➡️ 이 데이터로 어떤 데이터 분석을 할 수 있을지 chat GPT한테 물어보고 분석을 해달라고 요청을 해보는 것을 해볼 것
-
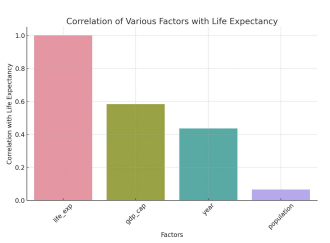
만약 평균 수명에 영향을 주는 가장 큰 변수가 무엇인지와 시각화를 요청하면, 상관관계 분석 해주고 시각화도 해줌(chat GPT 4.0기준).
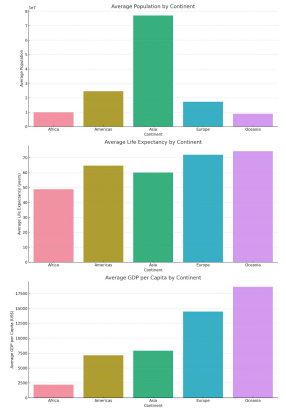
- 대륙별로 인구, 평균수명, GDP 등의 지표가 어떻게 다른지 비교분석과 시각화 요청하면 결과를 다음과 같이 보여줌.
과제
-
캐글에 가서 데이터 셋을 하나 정하고 chat GPT를 이용하여 데이터 분석을 해보자
-
chat GPT 3.5이면 데이터 셋을 업로드하지 못하기 때문에 데이터 셋을 설명하고 어떤 분석이 가능한지 요청해야 함
-
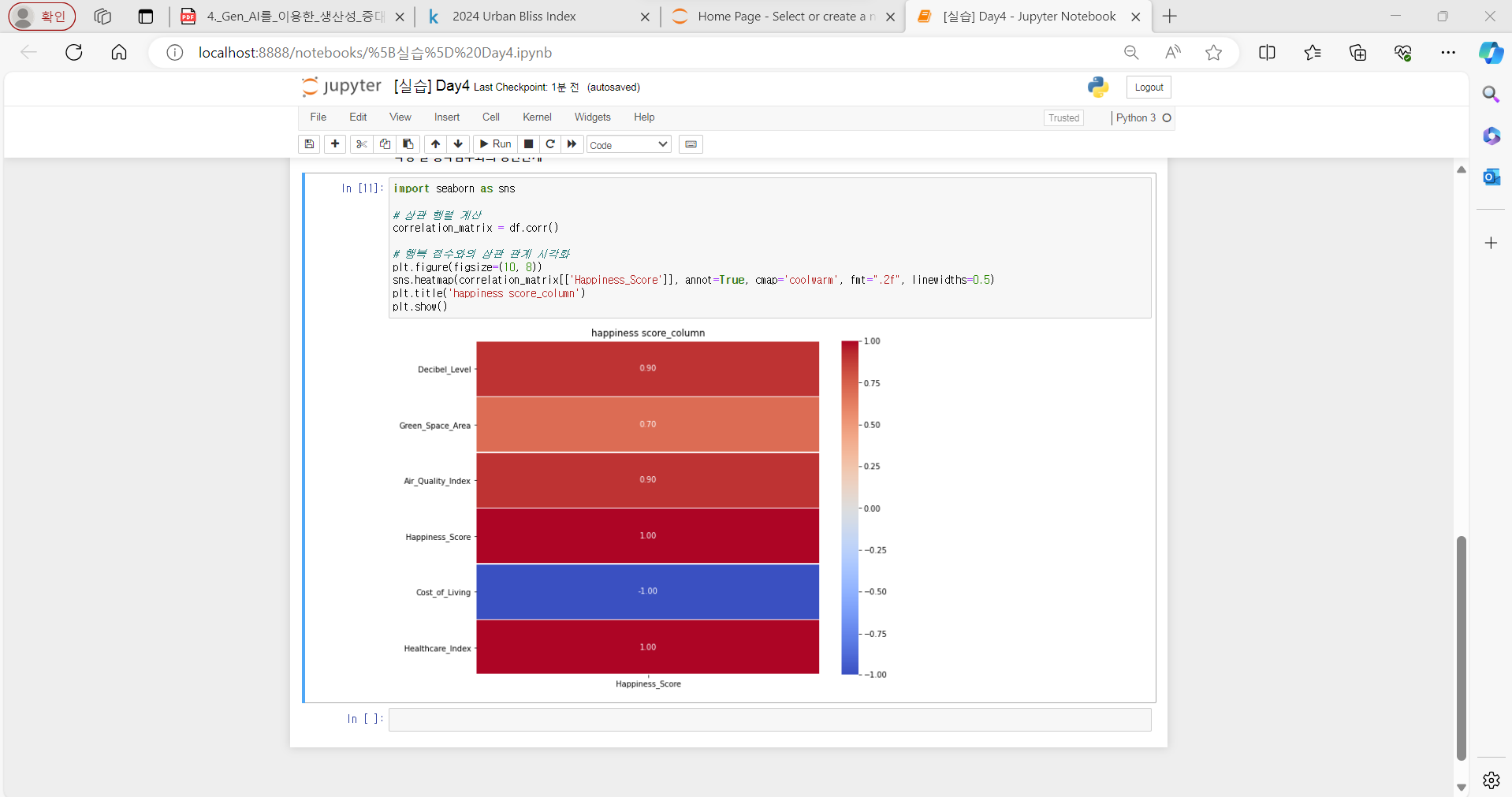
캐글에서 '2024 도시별 행복지수' 데이터를 선정하여 과제 진행하였음
➡️ 데이터 속성에는 도시 이름, 년도 및 월, 데시벨 수준, 교통 밀도, 녹지 비율, 대기 질 지수, 행복 지수, 생활 지수, 의료 지수 등이 존재

-
행복 지수와 다른 속성들 간의 상관관계 분석을 요청하니 pandas와 matplotlib이 포함된 코드를 결과로 내놓음
-
jupyter notebook에서 코드를 실행해 본 결과, 다음과 같이 시각화를 해준 코드임을 확인하였음