요약
- HyperCLOVA X 모델군의 첫 번째 추론(reasoning) 모델
- 고품질의 한국어, 영어 데이터를 활용 (약 6T 토큰)
- Peri-LN 트랜스포머와 µP 프레임워크 활용
- 작은 모델에서 탐색된 하이퍼 파라미터를 큰 모델에도 일관성 있게 적용 가능
- 3단계의 커리큘럼 학습을 적용한 사전학습, SFT와 RLVR을 활용한 사후학습 진행
학습
사전학습 (Pre-Training)
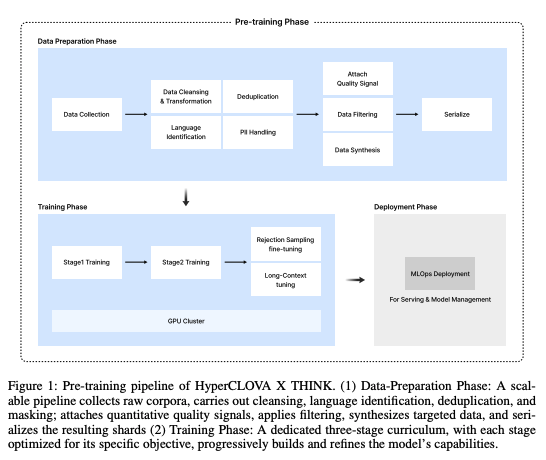
데이터 준비
- 데이터 파이프라인
- 스키마 표준화(schema standardization)를 통한 데이터 형식 통합
- 품질 평가 및 필터링
- 데이터 필터링
- 한국어의 언어적, 타이포그래피적 특징을 반영하여 2단계 필터링 진행
- 1단계의 경우 정량적인 규칙 기반, 2단계의 경우 모델을 활용한 점수 부여 (이진, 0-5점)
- 합성 데이터 생성
- 도메인(교육, 법, 역사, 문화)에 집중하여 합성 데이터 생성
- 기존의 문서를 재작성하거나, 시드 프롬프트로부터 새 텍스트를 생성
- 1) 데이터 디자인 2) 시드 확보 및 생성 3) 필터링 및 정제 4) 통합 단계로 구성
모델 아키텍처
- 연산-메모리 균형 아키텍처
- 얕고 넓은 트랜스포머 구성 (shallower-but-wider)
- 넓이를 중심으로 용량을 재할당했을 때 모델의 품질은 유지하면서도 하드웨어 효율성을 달성
- 안정지향적 트랜스포머
- µP(Maximal Update Parametrization)과 Peri-Layer-Normalized 트랜스포머 결합
- 하이퍼파라미터의 전이와 안정적인 학습 스케일링이 가능하여 비용 효율성 달성 가능
사전학습 커리큘럼
- 1단계: 기반 지식 구축
- 다양한 도메인 대상으로 지식 학습
- 총 6T 토큰 활용
- 2단계: 도메인 특화 역량 확보
- 1T 토큰 추가 활용
- 도메인 지식과 추론(reasoning) 능력 고도화
- 3단계: 컨텍스트 윈도우 확장 및 긴 추론 내재화
- 길이 기반, 비율 유지 리샘플링(length-based, proportion-preserving)을 통한 학습 안정성 유지
- 각 길이 버켓 내의 전체 토큰 수는 유지하면서 긴 문서의 수는 늘리는 방식
- 긴 chain-of-thought 코퍼스를 추가적으로 학습
- 기존 8K에서 128까지 컨텍스트 윈도우 확장
- 길이 기반, 비율 유지 리샘플링(length-based, proportion-preserving)을 통한 학습 안정성 유지
사후 학습 (Post-Training)
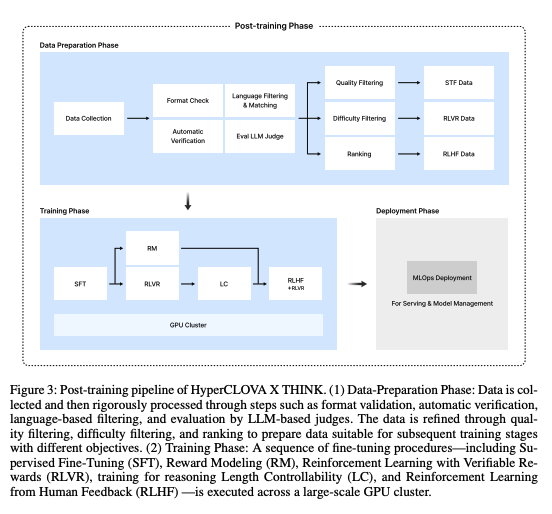
Supervised Fine-tuning (SFT)
- 수학, 코딩, STEM, 일반 등 다양한 고품질의 데이터 큐레이션
- 모든 데이터셋에 대해 다단계 필터링, 기본 형식 체크, 언어 필터링 등 진행
- 추론(reaosning) 데이터에 대해서는 최종 응답이 자동으로 검증 가능한지(verifiable) 확인
- 추론 데이터가 아닐 경우 LLM-as-a-judge를 활용해 유용성, 안전성 확인
Reinforcement Learning with Verifiable Rewards (RLVR)
- GRPO를 활용해 학습 진행
- KL Divergence Penalty를 제거
- Constant Normalization 적용
- 탐색을 위해 Upper Bound를 완화
- 데이터 효율성
- 너무 쉽거나 너무 어려운 프롬프트는 제외
- 오프라인, 온라인에서 모두 데이터 필터링 진행
- 보상(reward) 구성
- format reward: 모델 응답에서 준수된 규칙의 수 / 전체 규칙의 수
- language reward: 프롬프트와 같은 언어로 생성된 글자의 비율
- verifiable reward: 0, 1 (이진)
- overlong reward: soft overlong penalty와 overlong loss masking 도입
- 길이 때문에 유효한 추론에 페널티를 부여하면 학습 안정성을 저해하고 원치 않는 보상 노이즈가 발생할 수 있기 때문
- 전자는 응답 길이기 미리 정의한 최대 값을 넘는다면 점차 증가
- 후자는 잘린(truncated) 샘플들의 loss를 마스킹
- rollout sampling 최적화
- 비동기로 샘플링 진행하여 효율성 증가
Reasoning Length Controllability
- 길이에 페널티를 주는 보상 함수를 사용
- 인풋 지시사항에 "Think for maximum N tokens"를 추가
- N의 범위는 1024, 2048, 4096, 8192, 16384
Reinforcement Learning from Human Feedback (RLHF)
- 사람의 선호와 모델의 응답을 얼라인시키기 위한 학습 과정
- 보상 모델 학습
- 사람 선호 데이터와 GRPO 활용
- KL 페널티는 0.1로 부여
- RLVR 이후 RLHF 학습 시 최적화된 추론(reasoning) 능력의 일부 저하가 발생
- RLVR과 RLHF를 동시에 학습
평가
평가 벤치마크
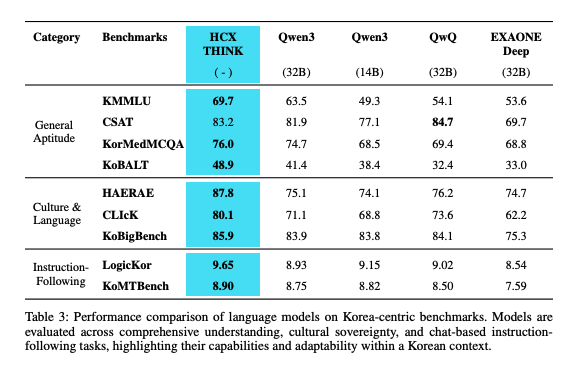
- 한국어 특화 벤치마크들에 대해 평가
- 일반 역량
- KMMLU
- 35,030개의 전문가 수준 다지선다 문제
- 인문학, STEM 등 다양한 범주 포괄
- CSAT
- 한국어 대학수학능력시험
- KorMedMCQA
- 7,469개의 의사, 간호사, 약사, 치과의사 대상 자격증 시험문제
- 2012-2024년 시험 문제 (다지선다)
- KoBALT-700
- 한국어의 언어학적, 유형학적 깊이를 반영한 벤치마크
- 700개의 전문가가 작성한 다지선다 문제
- syntax, semantics, pragmatics, phonetics/phonology, morphology
- KMMLU
- 문화 및 언어
- HAERAE-1.0
- 6개 태스크(표준 명명 체계, 외래어, 희소어, 일반 상식, 역사, 독해)
- 1,538개의 다지선다 문제
- CLIcK
- 한국 특화 언어, 문화(사회, 전통, 정치, 경제, 법, 역사, 지리학) 평가 벤치마크
- 약 2,000개의 다지선다 문제
- KoBigBench
- 공개 예정 데이터셋
- HAERAE-1.0
- 지시 이행
- LogicKor
- 한국어 다분야 사고력 벤치마크 (멀티턴)
- 6개 태스크(추론, 수학, 글쓰기, 코딩, 이해, 국어)의 총 42개 데이터로 구성
- LLM-as-a-judge로 평가
- KoMTBench
- 한국어 지시사항 이행 벤치마크 (멀티턴)
- 80개의 데이터로 구성
- LLM-as-a-judge로 평가
- LogicKor
분석
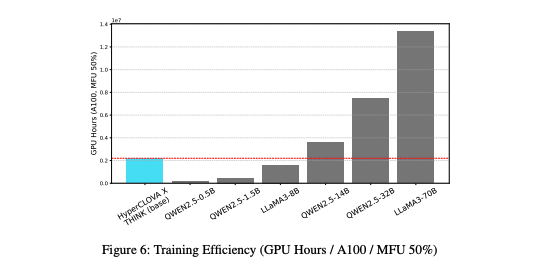
학습 효율성
언어간 전이가능성 (Cross-Lingual Transferability)
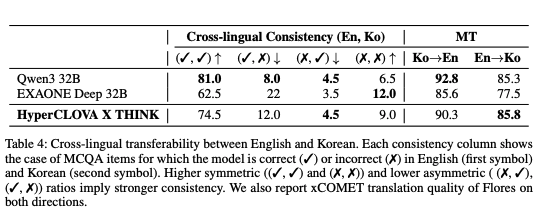
- 언어간 일관성
- Global-MMLU-Lite를 활용하여 측정
- 기계 번역
- Flores, xCOMET-XL 활용하여 측정

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab