2.1 네 개의 영역
아키텍처를 설계할 때 표현, 응용, 도메인, 인프라스트럭처로 4가지 영역이 보통 출현한다.
2.1.1 표현 영역
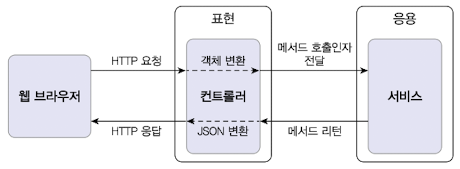
- 사용자의 요청을 받아 응용 영역에 전달한다.
- 응용 영역의 처리 결과를 다시 사용자에게 보여준다.
- 응용 영역이 필요로 하는 형식으로 변환해서 응용 영역에 전달하고 응용 영역의 응답을 요청 프로토콜에 따른 형식으로 변환하여 보낸다. ex) HTTP 요청 파라미터로 전송한 데이터를 객체 타입으로 응용 영역으로 전달하고 응용 영역이 리턴한 결과를 JSON 형식으로 변환해서 웹 브라우저에 전송한다.
2.1.2 응용 영역
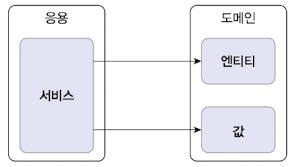
- 전달 받은 요청을 시스템이 사용자에게 제공해야 할 기능을 구현한다. ex) 주문 등록, 주문 취소, 상품 상세 조회, CRUD
- 기능을 구현하기 위해 도메인 영역의 도메인 모델을 사용한다.
open class CancelOrderService(private val orderRepository: OrderRepository) {
@Transactional
open fun cancelOrder(orderId: String) {
val order = orderRepository.findById(orderId)
.orElseThrow()
order.cancel()
}
...
}- 로직을 직접 수행하기보다는 위 코드처럼 도메인 모델에 로직 수행을 위임한다.
2.1.3 도메인 영역
- 도메인 모델의 핵심 로직을 구현한다. ex)
Order,OrderLine,ShippingInfo
2.1.4 인프라스트럭처 영역
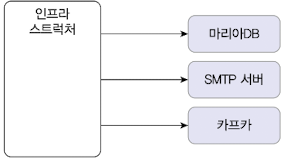
- 구현 기술에 대한 것을 다룬다.
- Database 연동을 처리하고, 메시징 큐에 메시지를 전송하거나 수신하는 기능을 구현한다. 데이터 연동을 처리한다.
- 논리적인 개념을 표현하기보다는 실제 구현을 다운다.
2.1.5 결론
- 도메인 영역, 응용 영역, 표현 영역은 구현 기술을 사용한 코드를 직접 만들지 않는다. 대신 인프라스트럭처 영역에서 제공하는 기능을 사용해서 필요한 기능을 개발한다.
2.2 계층 구조 아키텍처
네 개의 영역의 아키텍처를 그림으로 표현하면 하기 그림과 같다.
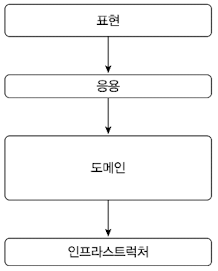
계층 구조 특성상 상위 계층에서 하위 계층으로의 의존만 존재하고 하위 계층은 상위 계층에 의존하지 않는다.
계층 구조를 엄격하게 적용한다면 상위 계층은 바로 아래의 계층에만 의존을 가져야 하지만 구현의 편리함을 위해 계층 구조를 유연하게 적용하기도 한다.
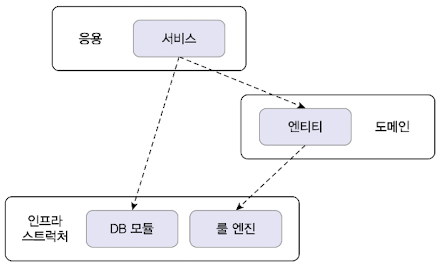
응용 영역과 도메인 영역은 DB나 외부 시스템 연동을 위해 인프라스트럭처의 기능을 사용하므로 이런 계층 구조를 사용하는 것은 직관적으로 이해하기 쉽다. 하지만 인프라스트럭처 계층을 제외한 다른 계층들은 상세 구현 기술을 다루지 않기 때문에 인프라스트럭처 계층에 종속이 된다.
class DroolsRuleEngine(private var kContainer: KieContainer) {
fun DroolsRuleEngine(): DroolsRuleEngine {
val ks = KieServices.Factory.get()
kContainer = ks.kieClasspathContainer
return this
}
fun evalute(sessionName: String, facts: List<T>) {
val kSession = kContainer.newKieSession(sessionName)
try {
facts.forEach{x -> kSession.insert(x)}
kSession.fireAllRules()
} finally {
kSession.dispose()
}
}
}응용 영역은 가격 계산을 위해 인프라스트럭처 영역의 DroolsEuleEngine을 사용한다.
class CalculateDiscountService(private var ruleEngine: DroolsRuleEngine) {
fun CalculateDiscountService() {
ruleEngine = DroolsRuleEngine()
}
fun calculateDiscount(orderLines: List<OrderLine>, customerId: String): Money {
val customer = findCustomer(customerId)
// ...
}
}이 코드에는 두가지 문제점이 있다.
1. CalculateDiscountService 만 테스트하기 어렵다.
CalculateDiscountService를 테스트하려면RuleEngine이 완벽하게 동작해야 한다.RuleEngine클래스와 관련 설정 파일을 모두 만든 이후에 비로소CalculateDiscountService가 올바르게 동작하는지 확인할 수 있다.
2 구현 방식을 변경하기 어렵다.
Drools가 제공하는 타입을 직접 사용하지 않으므로CalculateDiscountSerfice가Drools자체에 의존하지 않는다고 생각할 수 있다. 따라서Drools의 세션 이름을 변경하면CalculateDiscountService의 코드도 함께 변경해야 되는데,MutatbleMoney는 룰 적용 결괏값을 보관하기 위해 추가한 타입인데 다른 방식을 사용했다면 필요 없는 타입이다.
겉으로는 인프라스트럭처의 기술에 직접적인 의존을 하지 않는 것처럼 보여도 실제로는 Drools라는 인프라스트럭처 영역의 기술에 완전하게 의존하고 있다. 이런 부분에서 Drools가 아닌 다른 구현 기술을 사용하려면 코드의 많은 부분을 고쳐야한다.
2.3 DIP
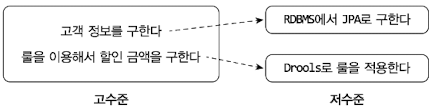
고수중 모듈은 의미 있는 단일 기능을 제공하는 모듈이다. 고수준 모둘의 기능을 구현하려면 여러 하위 기능이 필요하다. 저수준 모듈은 하위 기능을 실제로 구현한 것이다. JPA를 이용해 고객 정보를 읽어오는 모듈과 Drools로 룰을 실행하는 모듈이 저수준 모듈이 된다.
고수준 모듈이 동작을 하려면 저수준 모듈을 사용해야된다. 앞서 계층 구조 아키텍처에서 언급했던 구현 변경과 테스트가 어렵다는 문제가 발생하기도 한다.
DIP로 저수준 모듈이 고수준 모듈에 의존하도록 바꿀 수 이싿. 추상화한 인터페이스를 통해 저수준 모듈이 고수준 모듈에 의존하도록 할 수 있다.
interface RuleDiscounter {
fun applyRules(customer: Customer, orderLines: List<OrderLine>): Money
}ruleDiscounter를 사용할 경우 아래처럼 CalculateDiscountService를 변경할 수 있다.
class CalculateDiscountService(private var ruleDiscounter: RuleDiscounter) {
fun CalculateDiscountService(ruleDiscounter: RuleDiscounter): CalculateDiscountService {
this.ruleDiscounter = ruleDiscounter
return this
}
fun calculateDiscount(orderLines: List<OrderLine>, customerId: String): Money {
val customer = findCustomer(customerId)
return ruleDiscounter.applyRules(customer, orderLines)
// ...
}
}더이상 Drools에 의존하는 코드는 없다. RuleDiscounter의 구현 객체는 생성자를 통해서 전달받는다. RuleDiscounter를 상속받아 구현을 했으므로 Drools 관련 코드를 이해할 필요는 없다.
class DroolsRuleDiscounter(private var kContainer: KieContainer) : RuleDiscounter {
fun DroolsRuleEngine() {
val ks = KieServices.Factory.get()
kContainer = ks.kieClasspathContainer
}
override fun applyRules(customer: Customer, orderLines: List<OrderLine>): Money {
val kSession = kContainer.newKieSession("discountSession")
try {
kSession.fireAllRules()
} finally {
kSession.dispose()
}
return money.toImmutableMoney();
}
}RuleDiscounter의 출현으로 바뀐 구조
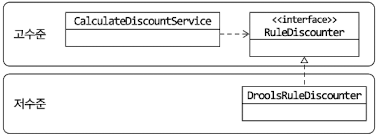
CalculateDiscountService는 더 이상 Drools에 의존하지 않는다. 할인 금액 계산이 추상화 된 RuleDiscounter 인터페이스에 의존할 뿐이다. "룰을 이용한 할인 금액 계산"은 고수준 모듈의 개념이므로 RuleCounter 인터페이스는 고수준 모듈에 속한다. DroolsRuleDiscounter 는 고수준의 하위 기능인 RuleDiscounter 를 구현한 것이므로 저수준 모듈에 속한다.
저수준 모듈이 고수준 모듈에 의존한다고 해서 이를 DIP(Dependency Inversion Principle), 의존 역전 원칙이라고 부른다.
문제 해결
- 구현 교체가 쉬워짐
- 테스트가 용이해짐
customer를 찾기 위해선 CustomerRepository가 필요하다. CustomerRepository 또한 인터페이스이므로 대역 객체를 사용해서 테스트를 진행할 수 있다.
2.3.1 DIP 주의사항
DIP는 단순히 인터페이스와 구현 클래스를 분리하는 정도로 받아들일 수 있다. DIP의 핵심은 고수준 모듈이 저수준 모듈에 의존하지 않도록 하기 위함인데 DIP를 적용한 결고 구조만 보고 저수준 모듈에서 인터페이스를 추출하는 경우가 있다.
DIP를 적용할 때 하위 기능을 추상화한 인터페이스는 고수준 모듈 관점에서 도출한다. CalculateDiscountService 입장에서 봤을 때 할인 금액을 구하기 위해 룰 엔진을 사용하는지 직접 연산하는지는 중요하지 않다. "할인 금액 계산"을 추상화한 인터페이스는 저수준 모듈이 아닌 고수준 모듈에 위치한다.
인프라스트럭처에 위치한 클래스가 도메인이나 응용 영역에 정의한 인터페이스를 상속받아 구현하는 구조가 되므로 도메인과 응용 영역에 대한 영향을 주지 않거나 최소화하면서 구현 기술을 변경하는 것이 가능하다.
2.3.2 DIP 와 아키텍처
저수준 모듈과 고수준 모듈사이에 DIP를 적용하면 저수준 모듈인 인프라스트럭처 영역이 응용 영역과 도메인 영역에 의존하는 구조가 된다.
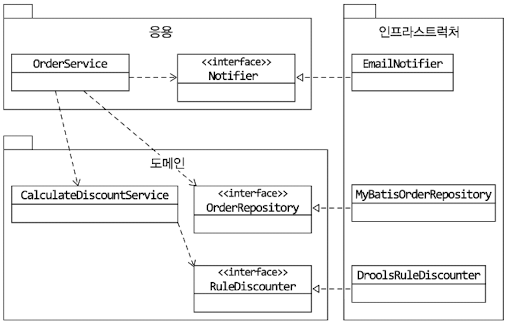
인프라스트럭처에 위치한 클래스가 도메인이나 응용 영역에 정의한 인터페이스를 상속받아 구현하는 구조가 되므로 도메인과 응용 영역에 대한 영향을 주지 않거나 최소화하면서 구현 기술을 변경하는 것이 가능하다.
2.4 도메인 영역의 주요 구성요소
도메인의 핵심 모델을 구현하는 도메인 영역의 모델은 도메인의 주요 개념을 표현하며 핵심 로직을 구현한다. ex) Entity, Value
| 요소 | 설명 |
|---|---|
| Entity | - 고유의 식별자를 갖는 객체 - 도메인 모델의 데이터를 포함하며 해당 데이터와 관련된 기능을 함께 제공 ex) Order, Member, Product |
| Value | - 고유의 식별자를 갖지 않는 객체로 개념적으로 하나인 값을 표현할 때 사용 - Entity의 속성으로 사용할 뿐만 아니라 다른 Value 타입의 속성으로도 사용 가능 ex) Address, Money |
| Aggregate | - 연관된 Entity와 Value 객체를 개념적으로 하나로 묶은 것 |
| Repository | - 도메인 모델의 영속성을 처리 |
| Domain service | - 특정 엔티티에 속하지 않은 도메인 로직을 제공 - domain 로직이 여러 Entity와 Value를 필요로 하면 domain service에서 로직을 구현. |
2.4.1 Entity와 Value
도메인 모델의 Entity와 DB 모델의 Entity는 다르다.
도메인 모델의 Entity는 주문을 표현하는 Entity는 주문과 관련된 데이터뿐만 아니라 배송지 주소 변경을 위한 기능을 함께 제공
class Order(
private val orderNumber: String,
private var state: OrderState,
private var orderLines: MutableList<OrderLine>,
private var totalAmounts: Money,
private var shippingInfo: ShippingInfo,
) {
// ...
// 도메인 모델 Entity는 도메인 기능도 함께 제공
fun changeShippingInfo(newShippingIngo: ShippingInfo) {
// ...
}
}- 도메인 모델의 Entity와 DB 모델의 Entity의 차이점
- 데이터와 함께 도메인 기능을 함께 제공한다.
- 데이터를 담고 있는 데이터 구조라기보다 데이터와 함께 기능을 제공하는 객체
- 도메인 관점에서 기능을 구현하고 기능 구현을 캡슐화해서 데이터가 임의로 변경되는 것을 막는다.
- 두 개 이상의 데이터가 개념적으로 하나인 경우 Value 타입을 이용해서 표현할 수 있다
class Order(
private val name: String,
private val email: String,
) {
// ...
}RDEMS와 같은 관계형 데이터베이스는 Value 타입을 제대로 표현하기 힘들다. Value 와 Entity를 개별 데이터로 저장을 하거나 별도 테이블로 분리해서 저장해야 된다.

왼쪽 테이블과 같은 경우는 주문자라는 개념이 드러나지 않고 주문자의 개별 데이터만 드러난다. 오른쪽 테이블의 경우는 주문자 데이터를 별도 테이블에 저장했지만 테이블의 Entity에 가까우며 Value 타입의 의미가 드러나지는 않는다. 반면 도메인 모델의 Orderer는 주문자라는 개념을 잘 반영하므로 도메인을 보다 잘 이해할 수 있도록 돕는다.
Value는 불변으로 구현할 것을 권장하며, Entity의 Value 타입 데이터를 변경할 때는 객체 자체를 완전히 교체한다는 것을 의미한다.
ex) 배송지 정보를 변경하는 코드는 기존 객체의 값을 변경하지 않고 다음과 같이 새로운 객체를 필드에 할당한다.
2.4.2 애그리거트
- 커진 도메인 모델로 인해 많고 복잡해진
Entity와Value가 생겼을 때 좋다. - 도메인 모델이 복잡해지면 전체 구조가 아닌 한 개
Entity와Value에만 집중하는 상황에서 모델을 관리할 때 사용한다. - 도메인 모델에서 전체 구조를 이해하는 데 도움이 된다.
- 관련 객체를 하나로 묶은 군집이다.
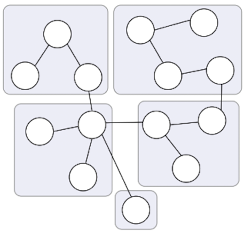
애그리거트 특징
- 개별 객체가 아닌 관련 객체를 묶어서 객체 군집 단위로 모델을 바라볼 수 있다.
- 개별 객체 간의 관계가 아닌 애그리거트 간의 관계로 도메인 모델을 이해하고 구현할 수 있다. 큰 틀에서 도메인 모델을 관리할 수 있다.
- 군집에 속한 객체를 관리하는
Root Entity를 갖는다. Root Entity는 애그리거트에 속해 있는Entity와Value객체를 이용해서 애그리거트가 구현해야 할 기능을 제공한다.- 애그리거트 루트를 통해서 간접적으로 애그리거트 내의 다른
Entity나Value객체에 접근한다. 내부 구현을 숨겨 애그리거트 단위로 구현을 캡슐화할 수 있도록 돕는다.
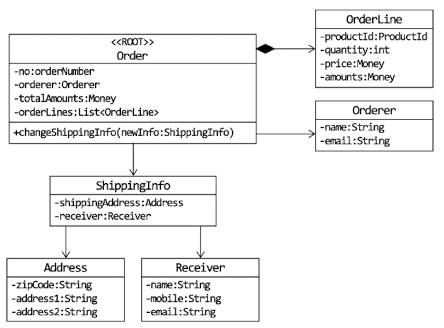
fun changeShippingInfo(newShippingIngo: ShippingInfo) {
checkShippingInfoChangeable();
// ...
}
private fun checkShippingInfoChangeable() {
// ...
}checkShipppingInfoChangeable 메서드는 도메인 규칙에 따라 배송지를 변경할 수 있는지 확인한다. 주문 애그리거트는 Order를 통하지 않고 ShippingInfo를 변경할 수 있는 방법을 제공하지 않는다. 즉 배송지를 변경하려면 Root Entity인 Order를 사용해야 하므로 배송지 정보를 변경할 때에는 Order가 구현한 도메인 로직을 항상 따르게 된다.
애그리거트 구현 시 고려할 점
- 애그리거트 구성 방법에 따른 구현의 복잡도, 트랜잭션 범위
- 구현 기술에 따른 애그리거트 구현에 대한 제약
2.4.3 레포지터리
정의
- 도메인 객체를 보관하기 위한 도메인 모델
- 요구사항에서 도출되는 도메인 모델인
Entity나Value와 다르게 구현을 위한 도메인 모델이다.
기능
- 애그리거트 단위로 도메인 객체를 저장하고 조회하는 기능을 정의
@Repository
interface OrderRepository : JpaRepository<Order, String> {
fun findByOrderNumber(number: String): Order
fun save(order: Order)
override fun delete(order: Order)
}OrderRepository의 메서드를 보면 대상을 찾고 저장하는 단위가 애그리거트 루트인 Order이다. Order는 애그리거트에 속한 모든 객체를 포함하고 있으므로 결과적으로 애그리거트 단위로 저장하고 조회한다.
도메인 모델을 사용해야 하는 코드는 레포지터리를 통해 도메인 객체를 두한 뒤에 도메인 객체의 기능을 실행한다.
open class CancelOrderService(private val orderRepository: OrderRepository) {
@Transactional
open fun cancelOrder(orderId: String) {
val order = orderRepository.findByOrderNumber(orderId) ?: throw NotFoundException()
order.cancel()
}
}도메인 모델 관점에서 OrderRepository는 도메인 객체를 영속화하는 데 필요한 기능을 추상화한 것으로 고수준 모듈에 속한다. 기반 기술을 이용해서 OrderRepository를 구현한 클래스는 저수준 모듈로 인프라 스트럭처 영역에 속한다.
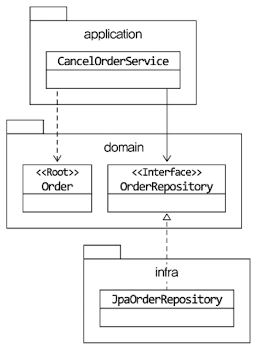
결론
- 응용 서비스는 필요한 도메인 객체를 구하거나 저장할 때 레포지터리를 사용한다.
- 응용 서비스는 트랜잭션을 관리하는데, 트랜잭션 처리는 레포지터리 구현 기술의 영향을 받는다.
2.5 요청 처리 흐름

응용 서비스는 도메인 모델을 이용해서 기능을 구현한다. 기능 구현에 칠요한 도메인 객체를 레포지터리에서 가져와 실행하거나 신규 도메인 객체를 생성해서 레포지터리에 저장한다. 두 개 이상의 도메인 객체를 사용해서 구현하기도 한다.
2.6 인프라스트럭처 개요
특징
- 표현 영역, 응용 영역, 도메인 영역을 지원
- 도메인 객체의 영속성 처리, 트랜잭션, SMTP 클라이언트, REST 클라이언트 등 다른 영역에서 필요로 하는 프레임워크, 구현 기술, 보조 기능을 지원
- 도메인 영역과 응용 영역에서 인프라스트럭처의 기능을 직접 사용하는 것보다 이 두영역에 정의한 인터페이스를 인프라스트럭처 영역에서 구현하는 것이 시스템을 더 유연하고 테스트하기 쉽게 만들어 준다.
구현의 편리함은 DIP가 주는 다른 장점만큼 중요하기 때문에 DIP의 장점을 해치지 않는 범위에서 응용 영역과 도메인 영역에서 구현 기술에 대한 의존을 가져가는 것이 나쁘지 않다.
2.7 모듈 구성
- 영역별로 모듈이 위치할 패키지를 구성. 도메인이 크면 하위 도메인으로 나누고 각 하위 도메인마다 별도 패키지를 구성한다.
- 도메인 모듈은 도메인이 속한 애그리거트를 기준으로 다시 패키지를 구성
- 애그리거트, 모델, 레포지터리는 같은 패키지에 위치시킨다.
주의할 점
- 모듈 구조 세분화에 대한 규칙은 없으나 한 패키지에 너무 많은 타입이 몰려서 코드를 찾을 때 불편한 정도만 아니면 된다.
- 한 패키지에 10~15개 미만의 타입 개수를 유지하려고 하며, 개수가 넘어가면 패키지를 분리해본다.
