감정몬스터
LLM과 멀티모달로 만드는 심리 테이밍 챗봇: 감정 몬스터
1. 프로젝트 개요 및 핵심 차별점
"뻔한 위로는 그만. 나보다 더 내 편이 되어주는 감정 페르소나와의 딥 다이브"
- 타겟 고객 (1020 세대): 딱딱하고 교훈적인 상담 앱에 거부감을 느끼는 세대. 제타(Zeta)처럼 '캐릭터와의 티키타카'를 통해 위로를 얻는 것에 익숙한 유저층.
- 핵심 심리 치유 기법 (대리 감정 & 자가 치유): AI가 이성적인 조언을 하는 대신, 유저의 감정을 3배로 부풀려 대신 표출(Vicarious Emotion).
- 예시: 유저가 억울한 일을 당했을 때, 분노 캐릭터(화씨)가 유저 대신 극대노하며 날뜁니다. 유저는 오히려 이성을 찾고 캐릭터를 말리면서 무의식적으로 자신의 화를 가라앉히는 '자가 치유(Self-soothing)'를 경험하게 됩니다.
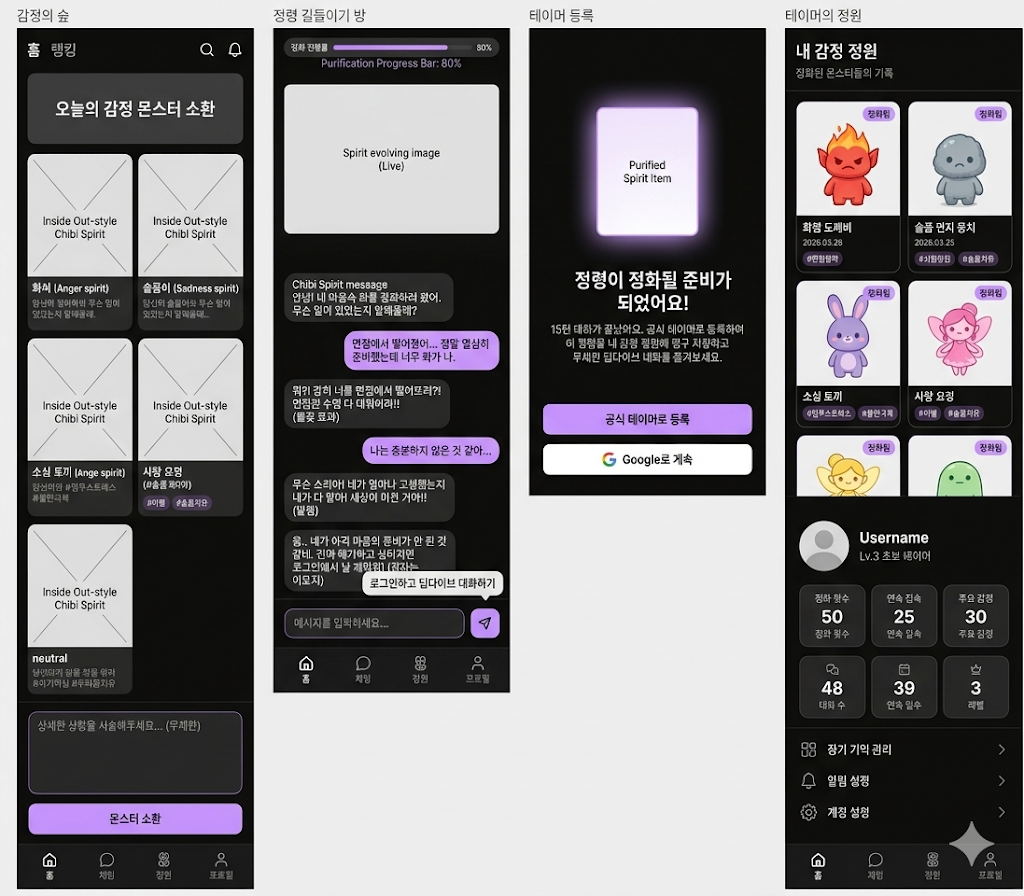
📱 2. 화면 구조 (UX/UI 4 탭)
게임 같은 퀘스트나 스폰 개념을 배제하고, 철저히 '캐릭터와의 관계 형성'에 집중합니다.
① [홈] 캐릭터 프로필 선택
- 컨셉: "오늘은 누구에게 기대어 볼까?"
- UI/UX: 어두운 숲/방 배경에 5명의 감정 몬스터(화씨, 슬픔이, 소심이, 사랑이 등) 프로필이 제타 홈 화면처럼 나열되어 있습니다.
- 동작: 유저가 자신의 현재 기분에 맞춰 대화하고 싶은 캐릭터를 클릭하면 즉시 채팅방으로 입장합니다.
② [채팅] 실시간 멀티모달 룸 (메인 코어)
- 컨셉: 대화의 흐름이 끊기지 않는 초고속 몰입형 채팅방.
- UI/UX: 상단 40%는 캐릭터 이미지, 하단 60%는 vLLM으로 한 글자씩 타자 쳐지는 스트리밍 채팅창입니다.
- 동작: 무거운 이미지 렌더링은 최소화하고, 서버에서 감정 상태 플래그만 받아와 프론트엔드에서 비 내림/하트 뿅뿅 같은 CSS/DOM 이펙트로 실시간 반응을 보여줍니다.
③ [도감] 감정 정원 (비주얼 다이어리)
- 컨셉: 아이템 파밍이 아닌, 캐릭터와의 소중한 '추억 보관함'.
- UI/UX: 폴라로이드 사진 형태의 카드들이 2단 그리드로 나열됩니다.
- 동작: 대화 중 유저가 깊은 속마음을 털어놓아 큰 위로를 받은 순간(Peak Moment), AI가 백그라운드에서 SDXL로 "이 순간을 기억할게 📸"라며 스페셜 폴라로이드 사진을 딱 1장 생성해 도감에 꽂아줍니다.
④ [프로필] 마이페이지 & 대시보드
- 컨셉: 투명한 AI 데이터 통제실 및 심리 분석 리포트.
- UI/UX: 유저 닉네임, KoELECTRA가 매일 분석한 '주요 감정 통계' 위젯.
- 동작: RAG(하이브리드 메모리)에 저장된 내 과거 대화 기억들을 열람하거나 초기화할 수 있는 관리 메뉴를 제공하여 신뢰감을 줍니다.
💬 3. 챗봇 동작 로직 (리텐션 & 방어 기제)
📍 Phase 1: 15턴 맛보기 (비로그인)
- 약 15턴 내외로 짧고 밀도 있는 대화를 진행합니다.
- 스무고개/트롤링 방어: 유저가 장난만 치면 몬스터가 삐져서 도망가는 것이 아니라, "음.. 네가 아직 마음의 준비가 안 된 것 같네. 진짜 얘기하고 싶어지면 [로그인]해서 날 깨워줘!"라며 쿨하게 대화를 멈추고 자연스러운 회원가입을 유도합니다.
📍 Phase 2: 딥 다이브 모드 (로그인 후 무제한)
- 내 편이 된 캐릭터와 밤새도록 이어지는 무제한 딥토크 모드입니다.
- 대화가 30턴, 50턴 깊어질수록 캐릭터 전경은 가만히 둔 채, 뒤쪽 배경만 (어두운 숲 -> 별이 빛나는 밤하늘 등으로) 몰래 생성하여 크로스페이드(Fade-in) 시켜 시각적 감동을 줍니다.
🚀 4. 핵심 기술 스택 & 아키텍처 (FE/BE 최소화 전략)
한 달이라는 시간 안에 제타급의 속도를 내기 위해 프론트엔드 UI(HTML/CSS/AJAX)와 백엔드 API 브릿지는 최소한으로 가져가고, 팀 리소스를 AI 인프라에 집중합니다.
🏗️ A. 물리적 서버 분리 아키텍처
- RunPod (AI 연산 공장 - A6000 등 단일 대용량 GPU):
- vLLM (Llama-3 8B): 시스템 프롬프트(대리 분노 등)를 주입하여 지연 시간 0.1초대의 초고속 텍스트 스트리밍 담당.
- SDXL Turbo + LoRA: 우리만의 몬스터 화풍을 유지하며 폴라로이드/배경 이미지를 1초대에 생성.
- KoELECTRA (파인튜닝): 텍스트의 감정과 위험도를 즉시 분류.
- AWS EC2 & S3 (통제실 및 저장소):
- 프론트엔드의 요청을 받아 RunPod으로 분기(Routing)해 주는 가벼운 FastAPI 브릿지 서버.
- 내부에 로컬
ChromaDB/FAISS를 띄워 과거 대화 기억(RAG) 검색. 생성된 이미지는 S3에 올려 URL만 프론트에 전달.
🧠 B. Multi-turn 컨텍스트 관리 기술
대화가 길어질 때 발생하는 토큰 제한(Context Window) 한계를 극복하기 위한 2중 메모리 구조입니다.
- 단기 기억 (Rolling Window): 최근 5~10턴의 대화만 원문 그대로 프롬프트에 유지하여 자연스러운 티키타카 보장.
- 장기 기억 (Mid-turn Summarization): 윈도우를 벗어난 과거 대화는 버리지 않고, 백그라운드에서 sLLM이 1~2줄의 핵심 문장으로 압축하여 시스템 지시문에 누적. 무한히 대화해도 맥락을 유지합니다.
🎯 C. 파인튜닝(Fine-Tuning)의 이원화
- 감정/위험 1차 분류기 (KoELECTRA): 무거운 LLM을 거치기 전, AI 허브 감성 대화 말뭉치로 학습된 NLU 모델이 0.1초 만에 개입하여 감정 태깅 및 위험 발화 필터링.
- 페르소나 최적화 (sLLM Instruction Tuning): 아동·청소년 상담 데이터를 몬스터 말투로 리라이팅하여 학습. 기계적인 AI 말투("무엇을 도와드릴까요?") 붕괴를 원천 차단.
🎨 D. LoRA를 활용한 몬스터 화풍 유지
대화 중간 이미지 렌더링 시 그림체가 바뀌는 몰입 방해 요소를 제거합니다.
- 우리가 원하는 도트풍/일러스트 이미지 20~30장을 사전 확보하여 LoRA(Low-Rank Adaptation)로 가볍게 학습. 프롬프트가 변해도 고유하고 일관된 화풍을 보장합니다.
🔮 5. 소름 돋는 '기억 공유' 세계관 (Core Memory)
"단순 요약이 아니다. 감정의 숲에서는 소문이 빠르다."
- 세션이 끝나면 전체 대화를
{이슈: 면접탈락, 감정: 분노}형태의 JSON 데이터로 백엔드 DB에 저장합니다. - 다음 날 유저가 접속해 다른 몬스터와 대화하더라도 이 JSON을 시스템 프롬프트에 주입하여 선톡을 날립니다.
- "어제 화씨 형이 뿜는 불길 봤어... 면접 때문에 상처받았다며? 오늘은 나한테 얘기해 봐..."
- 일반적인 챗봇이 매일 처음부터 묻는 지루함을 완벽하게 파괴하는 압도적인 라포(Rapport) 형성 구조입니다.
👥 6. 팀 R&R (5인 AI Pipeline)
5명의 팀원이 각 AI 모듈에 확실한 오너십을 가지고 개발합니다.
- 👩💻 AI 아키텍트 & MLOps: vLLM 서빙 환경 구축, 양자화(Quantization) 최적화, 텍스트/이미지 비동기 스케줄링 및 자원 관리.
- 👨💻 비전 AI 엔지니어: SDXL Turbo + LoRA 훈련, 몬스터 감정 상태 변화에 따른 동적 프롬프트 엔지니어링 및 생성 파이프라인.
- 👩💻 NLP (분류기) 엔지니어: KoELECTRA 기반 감정 및 위험 발화 실시간 1차 분류기(0.1초 처리) 파인튜닝.
- 👨💻 프롬프트 & 메모리 엔지니어: 롤링 윈도우 기반 멀티턴 프롬프트 설계, JSON 요약 파이프라인(Core Memory) 및 RAG 구축.
- 👩💻 풀스택 인테그레이션: AI 모델들의 API 통합 브릿지 서버(Node.js/FastAPI) 구축, 클라이언트 비동기 통신(채팅 스트리밍 UI) 및 DOM 이펙트 연결.
역할,추천 모델,선정 이유
A. sLLM (Main Chat),Llama-3 (8B) or Qwen-2.5 (7B) Instruct,제타급 초고속 응답
: vLLM 엔진과 조합하여 0.1초대의 압도적인 스트리밍 속도 보장. 4/8bit 양자화를 적용해 VRAM 비용 절감.
B. Image Generation,SDXL Turbo + Custom Inside Out-style Chibi LoRA"1초대 렌더링 & 화풍 유지:
기획안의 ""Inside Out-style Chibi Spirit"" 컨셉을 일관되게 유지하기 위한 custom LoRA 학습 필수. Turbo 모델로 쾌적한 UX 제공."
C. NLU / Classification,KoELECTRA (fine-tuned),"초고속 의도 분석:
유저의 발화를 0.1초 만에 '감정 태그(분노, 우울 등)' 및 '유해성/자해 징후'로 사전 분류."
D. Memory / RAG,ko-sBERT (Embedding),RAG(Retrieval-Augmented Generation) 시스템 구축:
유저의 과거 대화를 벡터화하여 저장. 의미 기반 검색(Semantic Search)을 통해 장기 기억 보존.
🧠 추천 모델 상세 가이드 및 선정 이유
A. sLLM (Main Chat) - Llama-3 (8B)
UX와의 연결: "Spirit Taming Room"의 "Chibi spirit message" 생성.
선정 이유: 한 달이라는 짧은 기간 내에 모델을 서빙하고 최적화하기에 가장 완벽한 sLLM입니다. PagedAttention 기술을 지원하는 vLLM 엔진에 올리면, 여러 유저의 대화를 병렬로 처리하면서도 지연 시간 없이 쾌적한 스트리밍 출력을 제공합니다. 제타(Zeta) 수준의 '티키타카'를 위해 필수적입니다.
B. Image Generation - SDXL Turbo + LoRA
UX와의 연결: 기획안의 "Inside Out-style Chibi Spirit" placeholder 및 "Chibi Dragon portrait frame (1-second Turbo rendering)" 노트.
선정 이유: 사용자가 디자인에서 명시한 "인사이드 아웃 스타일의 아기자기한 정령" 화풍을 모든 감정 종류에 걸쳐 일관되게 유지하는 것이 핵심입니다. 이를 위해 기본 SDXL-Turbo 모델에 'Inside Out-style chibi vector art' 이미지를 LoRA로 학습시키는 파이프라인이 필수입니다. "1-second Turbo rendering" 노트에서 알 수 있듯이, Turbo 모델을 활용하여 UX 지연을 최소화합니다.
C. KoELECTRA 감정 분류 모델 (NLU)
UX와의 연결: 앱 이름 자체가 "Emotion Monster"이며, 유저 발화에 맞춰 "Red anger spirit", "Blue sad spirit" 등을 소환해야 함.
선정 이유: 유저가 고민을 입력하면, 이를 무거운 LLM에 바로 맡기기 전에 가벼운 KoELECTRA 모델로 먼저 감정을 분류합니다. 한국어에 특화된 모델이므로 KoELECTRA 또는 RoBERTa를 AI 허브의 감성 대화 말뭉치로 파인튜닝하여 사용합니다. 이를 통해 유저의 감정을 0.1초 만에 판별하여 LLM의 페르소나를 결정하고, 자해/욕설 등 위험 발화에 대한 실시간 1차 문지기 역할을 수행합니다.
D. ko-sBERT (Embedding)
UX와의 연결: "Memories Archive" 및 "RAG systems," 그리고 "소름 돋는 '기억 공유' 세계관" 기획.MySQL DB에 저장된 대화 요약 JSON 데이터 검색. MySQL DB에 저장된 대화 요약 JSON 데이터 검색.
선정 이유: 제타 같은 라포(Rapport) 형성을 위해서는 봇이 과거 대화를 기억해야 합니다. 이를 위해 유저의 대화 로그를 ko-sBERT (Korean Sentence-BERT)를 이용해 벡터화하여 Faiss나 ChromaDB 같은 벡터 DB에 저장합니다. 유저가 모호하게 "아씨, 또 걔랑 싸웠어"라고 말해도, 의미 기반 검색을 통해 한 달 전 싸웠던 친구의 이름과 사건 디테일을 찾아내어 LLM에게 제공(RAG)합니다.