DFS & BFS: 자료의 검색, 트리나 그래프를 탐색하는 방법
DFS: 깊이를 우선시하여 끝까지 파고들어 탐색하는 알고리즘
BFS: 모든 경우의수를 탐색하여 정답을 도출하는 알고리즘이다.
DFS: 끝까지 찾아가는 경우라서 최대 깊이만큼 공간을 차지한다. 다만, 최적의 경우의수를 찾기는 쉽지 않다.
BFS: 최적의 경우의수를 찾지만 모든 경우의수를 찾기때문에 노드의 갯수만큼 차지한다.
DFS 구현방법 (재귀함수, 스택)
1. 루트노드부터 시작한다.
2. 방문한 노드를 visited함수안에 넣는다.
3. 현재 방문한 노드와 인접한 노드들 중 방문하지 않은 노드를 방문한다.
4. 2부터 반복한다.
DFS 모델형태:
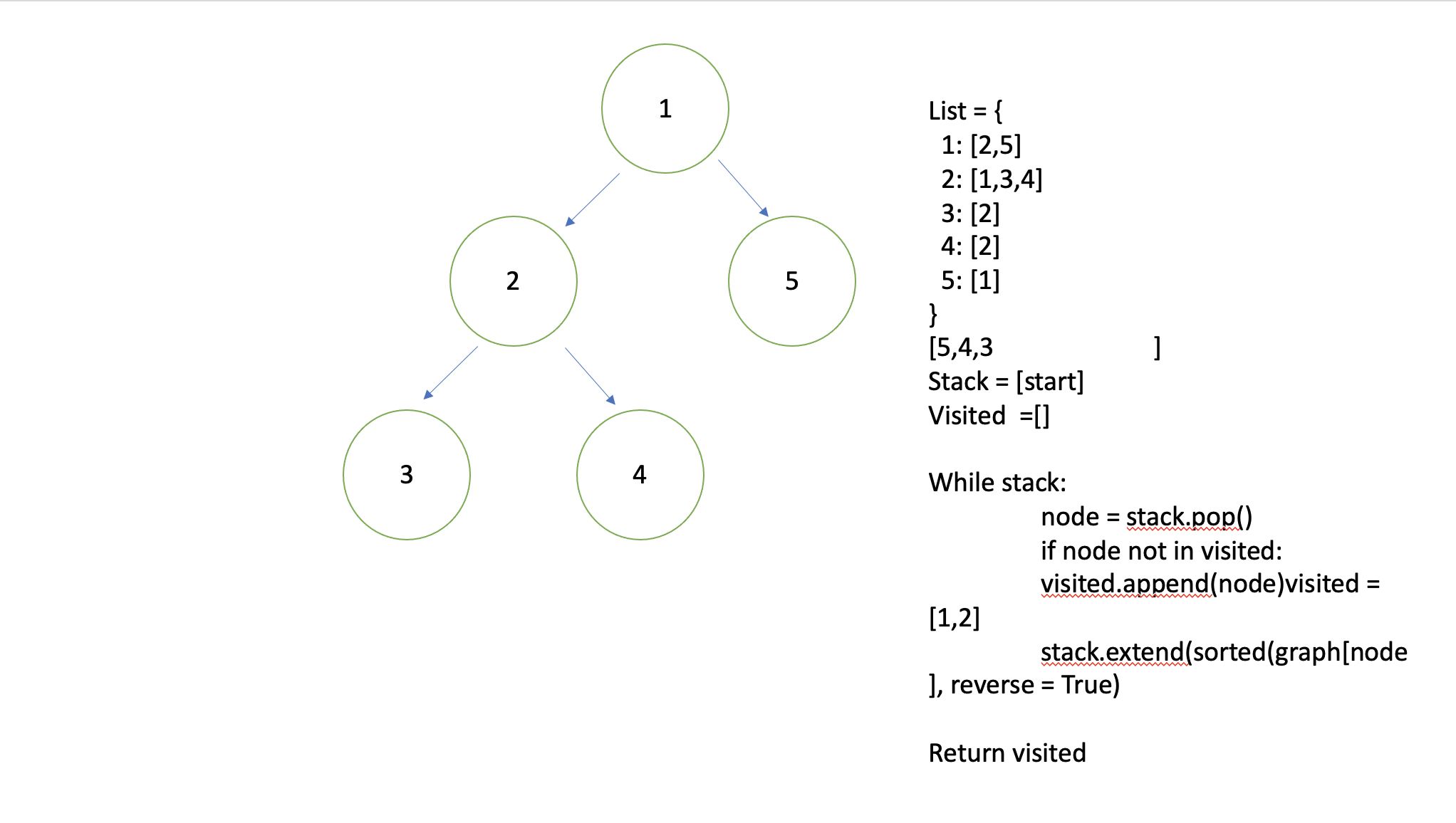
DFS 탐색구현 코드
# 위의 그래프를 예시로 삼아서 인접 리스트 방식으로 표현했습니다!
graph = {
1: [2, 5, 9],
2: [1, 3],
3: [2, 4],
4: [3],
5: [1, 6, 8],
6: [5, 7],
7: [6],
8: [5],
9: [1, 10],
10: [9]
}
visited = []
#시작 노드(루트 노드)인 1부터 탐색합니다.
#현재 방문한 노드를 visited_array에 추가합니다.
#현재 방문한 노드와 인접한 노드중 방문하지 않는 노드에 방문합니다.
def dfs_recursion(adjacent_graph, cur_node, visited_array):
visited_array.append(cur_node) #시작 노드 탐색
for adjacent_node in adjacent_graph[cur_node]: # 시작노드의 인접노드들을 다 불러와서
if adjacent_node not in visited_array: #인접노드중 하나가 visited array에 없다면
dfs_recursion(adjacent_graph, adjacent_node, visited_array) #dfs_recursion 함수를 불러서 다시한번 시작노드 탐색
return visited_array
dfs_recursion(graph, 1, visited) # 1 이 시작노드입니다!
print(visited) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] 이 출력되어야 합니다!다만 BFS를 사용한다면, 무한정 깊어지는 탐색일경우 에러가 날 수 있다.
그렇기때문에, stack의 가장 마지막에 넣은 원소를 빼서 visited array에 추가하는 방법을 활용해서 구현해본다.
# 위의 그래프를 예시로 삼아서 인접 리스트 방식으로 표현했습니다!
graph = {
1: [2, 5, 9],
2: [1, 3],
3: [2, 4],
4: [3],
5: [1, 6, 8],
6: [5, 7],
7: [6],
8: [5],
9: [1, 10],
10: [9]
}
def dfs_stack(adjacent_graph, start_node):
stack = [start_node]
visited = []
while stack: #스택이 존재할때까지 계속해서 돌아간다
current_node = stack.pop() #current_node를 Stack 맨뒤에서 pop 한값을 가져온다.
if current_node not in visited: #current_node의 인접한 노드들이 visited에 없다면
visited.append(current_node) # visited에 붙여주고
stack.extend(sorted(adjacent_graph[current_node],reverse =True)) #붙인값들을 reverse 형태로 즉, 내림차순으로 sort하여서 리스트를 스택에 붙여라)
return visited
print(dfs_stack(graph, 1)) # 1 이 시작노드입니다!위에 stack.extend(sorted())함수를 쓰고 내림차순 형태로 받아야지 위의 재귀함수처럼 [1,2,3,4 ---] 형태로 받을 수 있다. BFS 알고리즘 구현방법만 알아도 된다고하면 for adjacent_node in adjacent_graph[current_node] 문을이용해서 원소하나씩 append를 하는 구조도 된다.
정렬문제:
산술평균, 최댓값, 최빈값, 범위 등을 구할때 정렬을해서 구하면 좋다
특히, sort()함수를 이용해서 오름차순 혹은 내림차순 형태로 정렬을 해주고 답을 구해야한다.
최빈값같은경우는 from collections import Counter를 한 이후에, Counter('변수').most_common()함수를 불러오면 리스트안에 가장 많이쓰인 원소 순서대로 불러와진다.
출력값의 형태는 [('원소', '원소가 불려진횟수'), ('원소', '원소가 불려진 횟수')] 등 이런식으로 원소가 불려진다
