본 포스트팅은 인하대학교 컴퓨터공학과 시스템 프로그래밍 수업자료에 기반하고 있습니다. 개인적인 학습을 위한 정리여서 설명이 다소 미흡할 수 있으니, 간단히 참고하실 분들만 포스팅을 참고해주세요 😎
Classical Problems in Concurrent Programming
- Concurrent Programming 이란? : 프로세스나 쓰레드를 여러개 사용해서 control flow 가 동시에 수행되도록 하는 것
Races
-
read, write 하는 명령어이 여러명있는데 데이터가 하나밖에 없는 경우, 명령어 수행 순서를 별도로 지정해주지 않으면 원하는 의도대로 프로세스가 수행되지 않을 수 있어서 순서를 반드시 지정해줘야 하는 상황
-
특정 코드를 어떤 프로세스나 쓰레드가 실행하는지에 따라서 결과가 달라지는 상황이다.
Deadlocks
-
race 를 해결하기 위해 여러 프로세스에 대해 명령어 순서를 지정해주었더니, 모든 프로세스들이 자신이 원하는 것을 명령을 수행할 수 없도록 다른 프로세스가 가져가 버린 상황. 이래서 그 어떤 프로세스나 쓰레드도 더이상 진행을 못하는 상황이다.
(쉽게말해, 프로세스들이 서로 엉키고 꼬인것이다.)
Starvation / Fairness
-
Starvation : 여러개의 process 가 있는데 의도치않게 특정 한 process 만 계속 수행되는 경우. 나머지 process 는 다 수행이 안된다.
-
Fairness : 반대로 한 process 만 수행이 안되고 나머지 모든 process 가 다 수행되는 경우
Iternative Servers
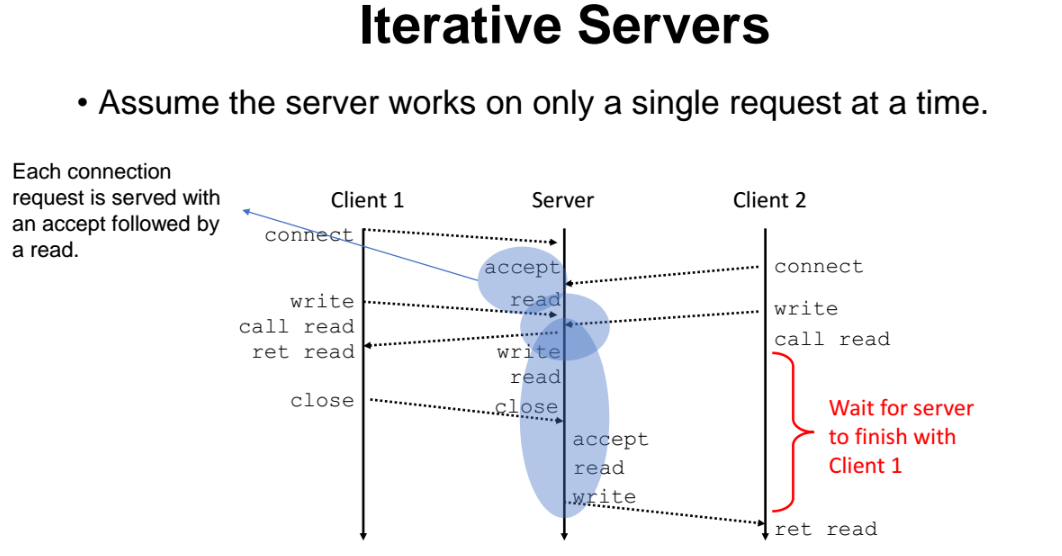
서버는 클라이언트가 요청을 보낼떄까지 기다리고있음. 그래서 Iternative Server 라고 한다.
특정 클라이언트1가 요청을 보내면 해당 요청을 서버가 accept 하고 read 한다. 이떄 다른 클라이언트2에게 요청이 들어오면 바로 accept 하는 것이 아니라, 클라이언트1의 요청에 대한 요청문을 다 수행하고 리턴한 후에, 클라이언트2 가 보낸 요청을 accept 하는 것이다.
그런데 클라이언트2 입장에서는 서버의 상태를 모르기 떄문에 자신이 보낸 요청이 aceept 되었다고 가정하고 write 요청을 보내버린다. 서버 입장에서는 write 요청이 들어왔으니, 해당 요청을 무시하지는 않고 그래도 좀 이따 수행하더라도 요청을 들고는 있는다. 이게 block 된것이다. (위에서 빨간색 부분이 block 된 부분이다.)
정리 : 서버는 동시간에 특정 한 클라이언트의 대한 요청을 수행할 수 있다.
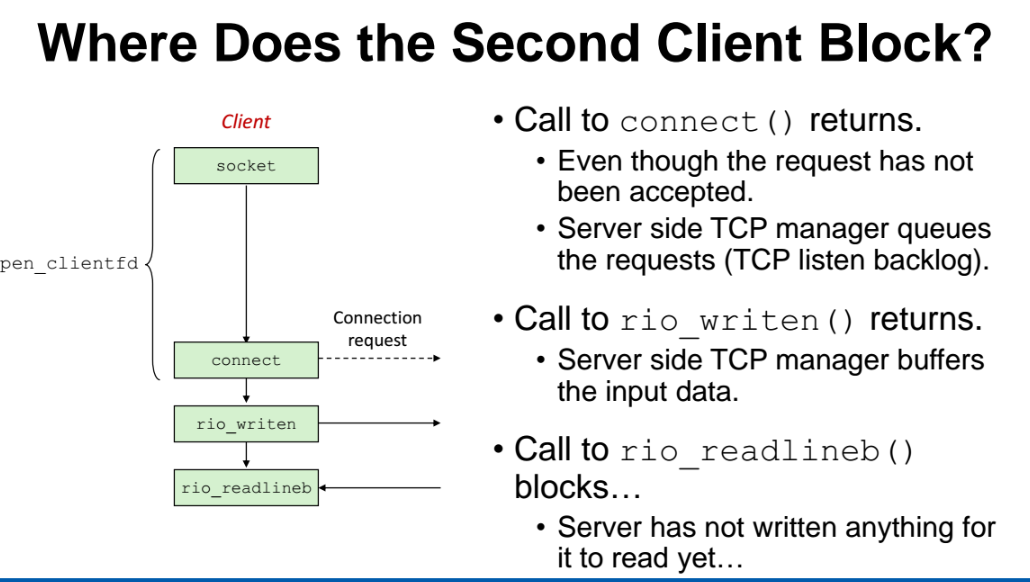
- 클라이언트2가 connect() 함수로 서버에 연결하겠다고 요청을 했을텐데, 서버는 해당 요청을 받았지만 클라이언트1의 요청을 수행하고 있느라 요청내용을 버퍼에 쌓아놓는다.
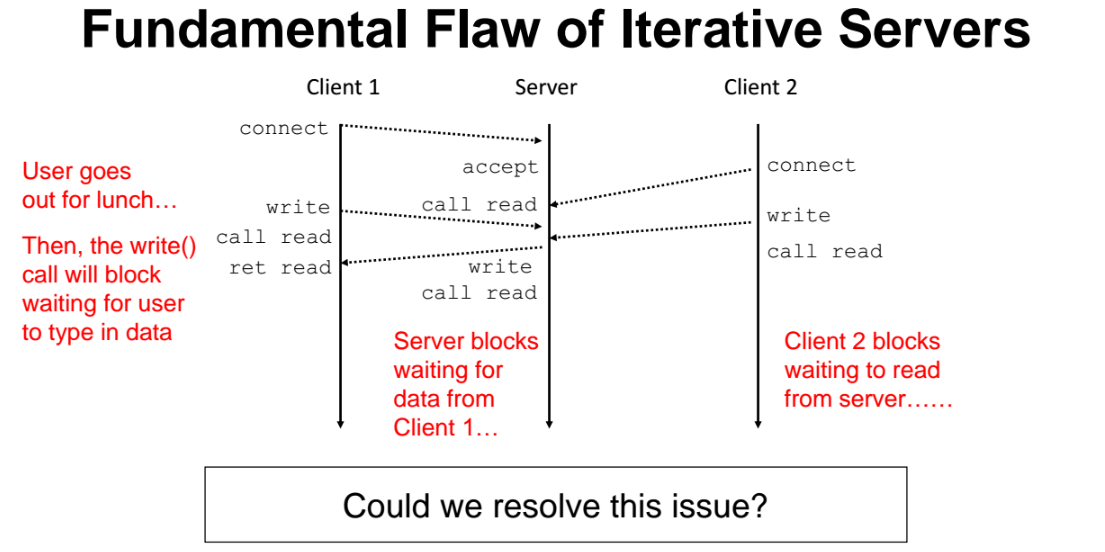
이전에 배웠듯이 read 와 write 함수는 block 함수이다.
클라이언트1이 write 요청을 보내고 점심밥 먹으러 갔다. 그러면 서버 입장에서는 read 를 해야하는데, 근데 read 가 연결은 되어있는데 write 하려는 클라이언트 쪽에서 데이터를 주지 않고 점심밥을 먹으러간 상태라면 서버는 계속 기다려야하는가?
=> 이러한 상황에서 클라이언트 2가 connect 를 시도하면 서버가 반응이 없어서 무슨 상황이 발생한 것인지 모를것이다. (클라이언트1이 밥을 먹으러 간것을 모른다.)
=> 즉 이렇게 생긴 서버를 사용할 수 없다. 즉, 한번에 하나만 처리해주는 서버는 사용할 수 없다. 이 해결법은 바로 멀티쓰레딩(multi threading) 이다.
Concurrent Server
- 서버가 클라이언트의 여러 요청을 동시에 수행할 수 있도록 한다. 아래의 3가지 방법이 있다.
Process-based approach
- child process 를 fork 해서 늘림으로써 여러 프로세스가 여러 요청을 처리하도록 하는방식
Event-based approach
- 여러 요청을 모았다가 한번에 처리해주는 방식으로, 실제로는 한 프로세스가 이벤트를 처리하는 것인데 마치 여러 프로세스가 처리하는 것 처럼 보이게 하는 방식
Thread-based approach
- 프로세스는 기본적으로 logical flow 를 여러개 가지고있게 된다.
- 프로세스는 여러개의 독립적인 프로세스들을 생성해서, 각 프로세스들이 하나의 logical flow (하나의 요청)를 처리할 수 있도록 한다.
Approach#1 : Process-based Servers
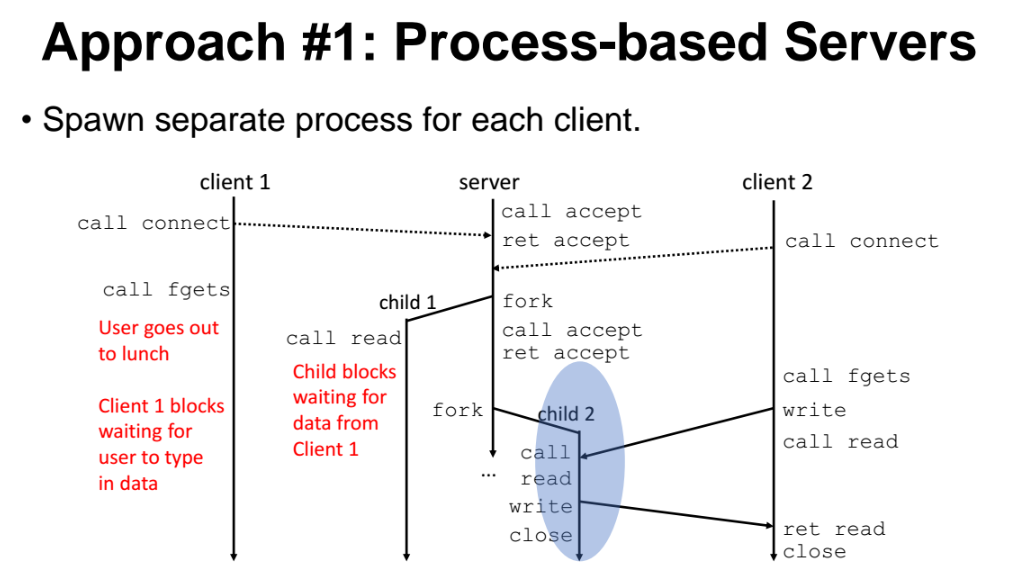
아까와 달리 서버에 클라이언트 요청이 들어올때마다 child process 를 늘려서 child 들이 요청을 대신 받아서 처리하도록 하는 방식
예제
- parent 가 child process 보다 나중에 끝나야(exit) 하므로, child 를 fork 해줄떄마다 새롭게 생긴 process 들을 다 race 를 불러줘야한다.


실제로는 이런 방식은 구현 불가능,
- 프로세스만드는데 생각보다 비쌈.
Concurrent Server : accept IIIustrated
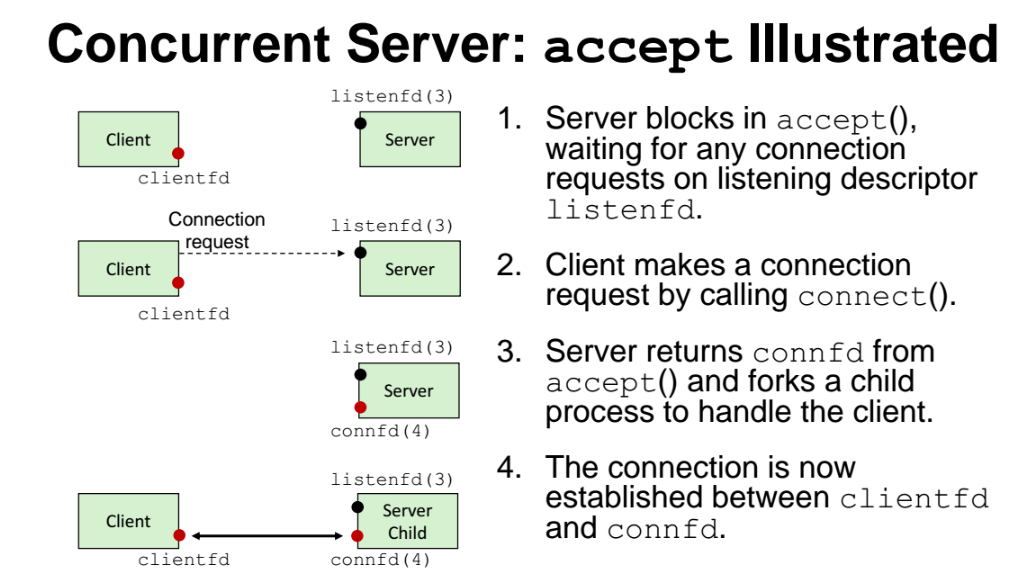
-
accept 란 클라이언트가 서버에게 connect 요청을 보냈을때, 서버가 요청을 수락하는 것
-
클라이언트와 서버 모두 file descriptor 가 있는데, 이떄 listenfd 란 connect 요청을 받겠다는 역할을 수행하는 file descirptor 임
클라리언트가 accept 을 보내면, 서버가 connected 되었다고 하는 connfd() 라는 것이 생기고, 그러면 클라이언트가 가지고있는 clientfd 와 서버에 생긴 connfd 가 서로 연결이 되면서, 이떄가 클라이언트와 서버가 제대로 연결된 것이다.
=> 이런 일련의 과정을 처리하는 것을 각 child process 에 대해 가능하게 해준다. 즉, 하나의 클라이언트의 요청을 수행하는 것을 하나의 process 가 처리할 수 있도록 각 process 에 대해 만들어주는 것이다.
한계점, 단점
-
이런 방식은 너무 heavy 함! 한 요청이 들어오면 한 child process 가 생성되어야 하므로 process ID 가 계속 너무 생겨서 안좋다.
-
또한 요청 들어올때 마다 process 가 생기는 이 자체가 너무 안좋다. 소캣으로 열수있는 통신 채널이 제한되어 있는데 너무 많이 생기면 막힐수있다.
장점
- 각 프로세스는 독립적으로 수행되므로, 공유할 데이터만 최소로 공유하고 대부분 공유하지 않는다. (프로세스끼리 꼬이고 엉킬 위험이 줄음)
Approach #2 : Event-based Servers
-
connect 요청을 여러개를 미리 받는방식
=> 아까처럼 한 요청이 들어오면 바로 accept 하는것이 아니라, 통로가 여러개 열어있으니까 요청이 어느정도 많이 들어왔을때 동시에 통로를 열어주는 방식
예제
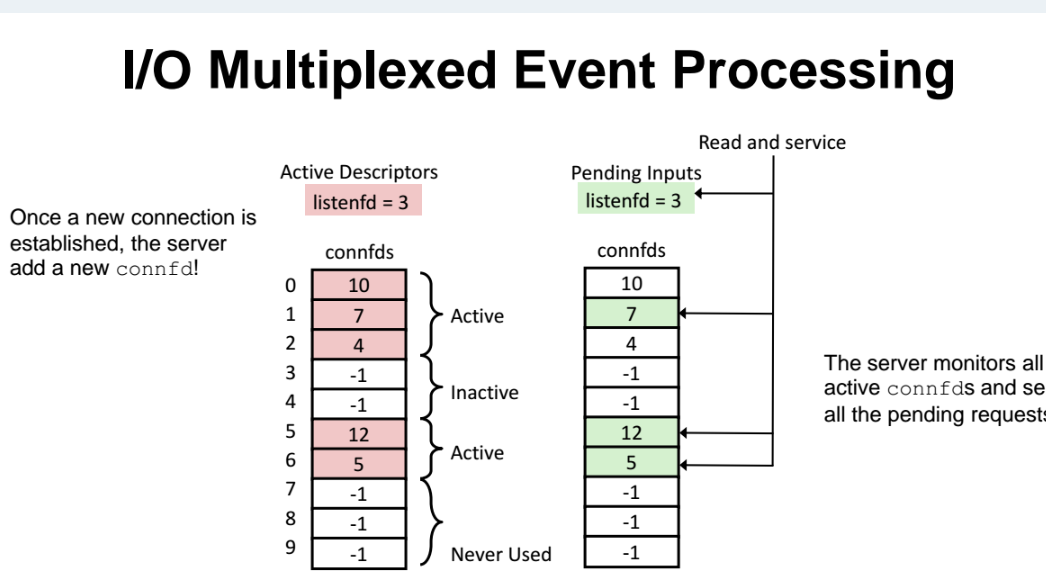
서버가 connect 요청을 받을 수 있는 10개의 통로를 열어놓고, 기다린다.
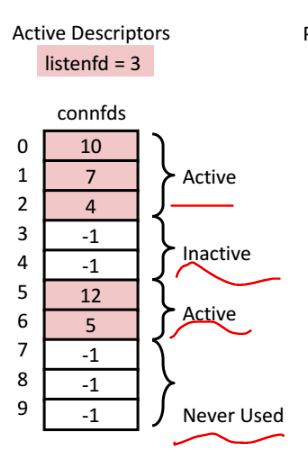
위처럼 서버에서 사용하고 있었던 놈(active) 도 있고, 사용 안되고 있는 놈(inactive) 도 있고, 사용 된적이 없는 놈(never used) 도 있을것이다.
즉 위 그림에서는 5개의 클라이언트가 서버와 연결되어 살아있는 것(active 상태) 이다. 이런 상황에서 새로운 클라이언트 요청이 들어오면 그 요청들을 모았다가 한번에 system call 로 처리해주는 것이다.
단점
=> 논리적으로는 여러개를 동시에 처리해주는 것이지만, 미리 요청을 보내려고 대기하고 있는 클라이언트 입장에서는 다른 클라이언트 요청이 더 들어오기 전까지 한참 기다릴 수도 있다는 단점이 있다.
장점
- 디버깅하기 쉬움. 쓰레드도 하나고 프로세스도 하나이기 떄문
=> 멀티쓰레드를 활용하는 방식은 디버깅하기 엄청 어렵다.
Approach#3 : Thread-based Servers
- 각 connect 요청이 들어올 때마다 쓰레드를 만들어서
- Process 의 구조를 바라보는 옛날관점
=> 지금껏 배워왔던 구성요소
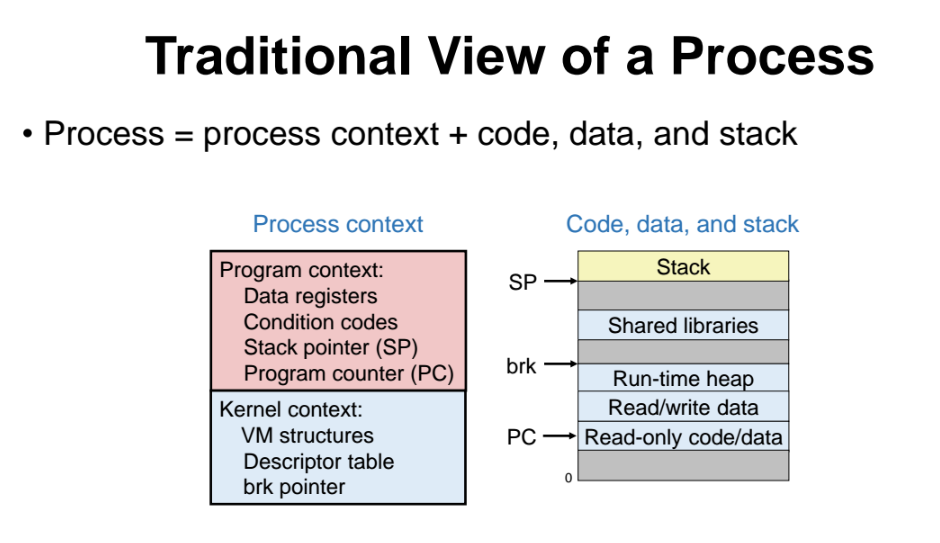
- 멀티쓰레드를 사용하는 사람들의 관점에서 바라본 process 구조
=> process 를 main thread 로 바라보는 관점. main thread 라 부르며, main thread 가 여러개 있는 구조
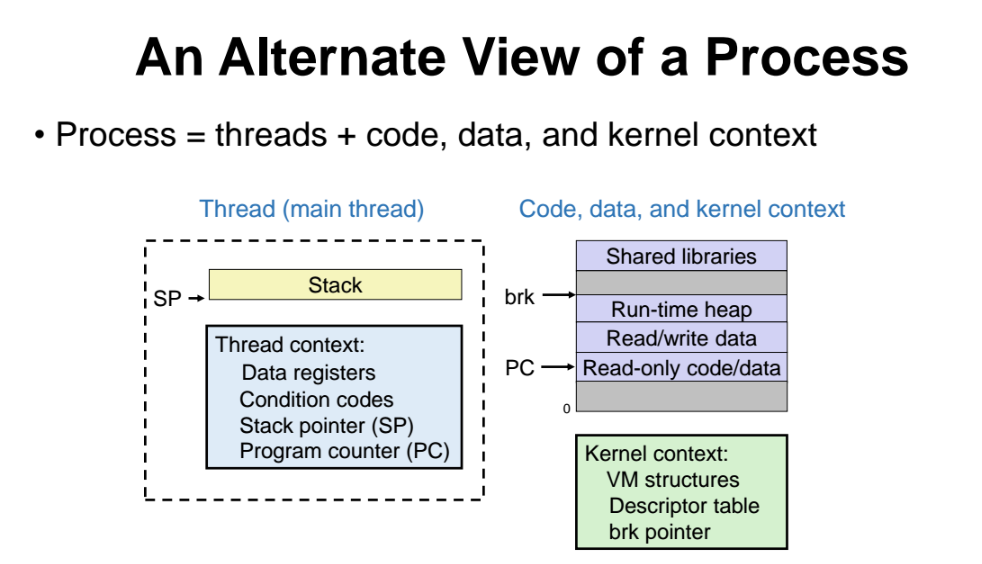
쉽게말해, 쓰레드란 여러 쓰레드들이 물리적 메모리 공간의 같은 데이터를 공유하는 것
=> 즉, 데이터를 주고 받아야할때 의사소통할 필요없이 메모리에 access 하면된다.
(어짜피 같은 메모리의 데이터 공유하므로, 남의 데이터를 가져오는 것이 쉽게가능)
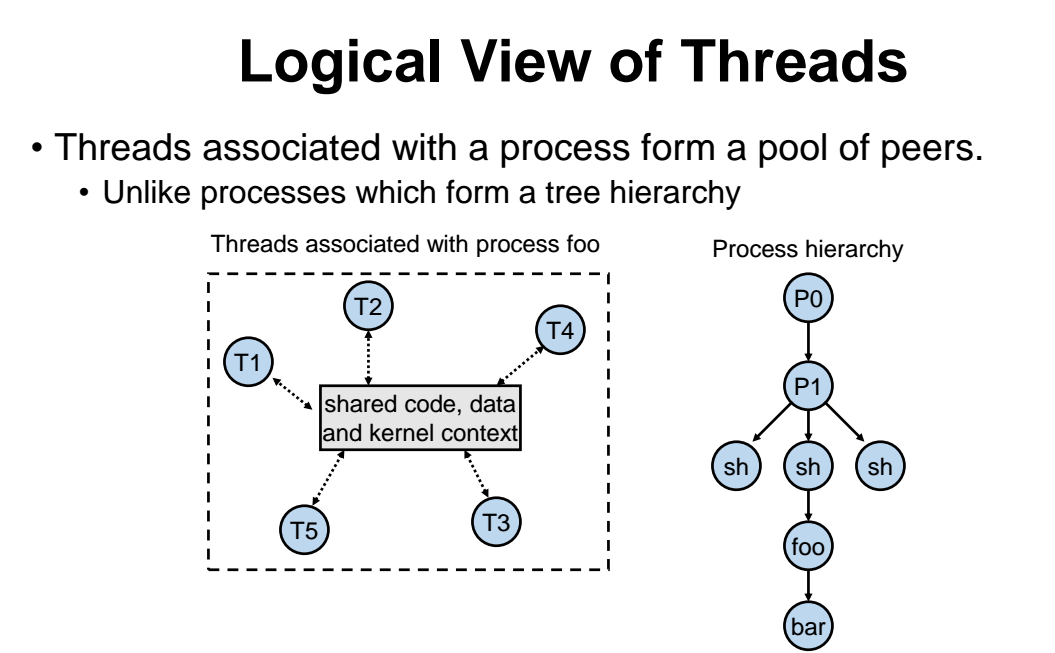
- 쓰레드가 뭔지 자세히 살펴보자.
=> 쓰레드가 2개 있는데, 이 2개는 같은 process 에서 나왔다. 그래서 각자 스택을 가지고 있긴해도 이 2개가 process 입장에서 보면 같은것이다.
=> 그런데 쓰레드 입장에서 보면 다른거임
쓰레드와 프로세스 관점의 차이
- 쓰레드는 코드와 데이터와 커널을 가운대다 놓고 여러명이 동일한 데이터를 "공유"하는 개념
- 프로세스는 각자 "독립"적으로 자기걸 가지고있음
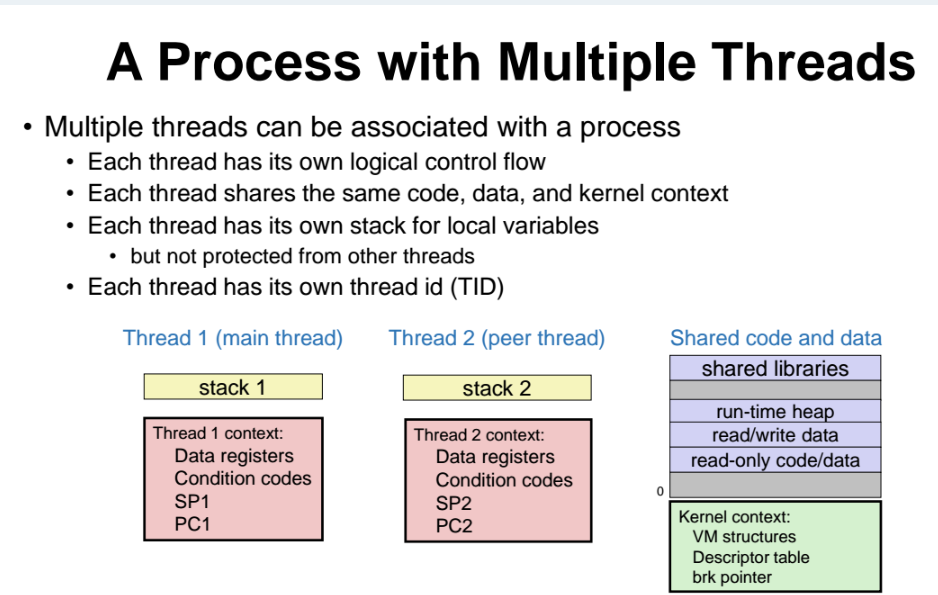
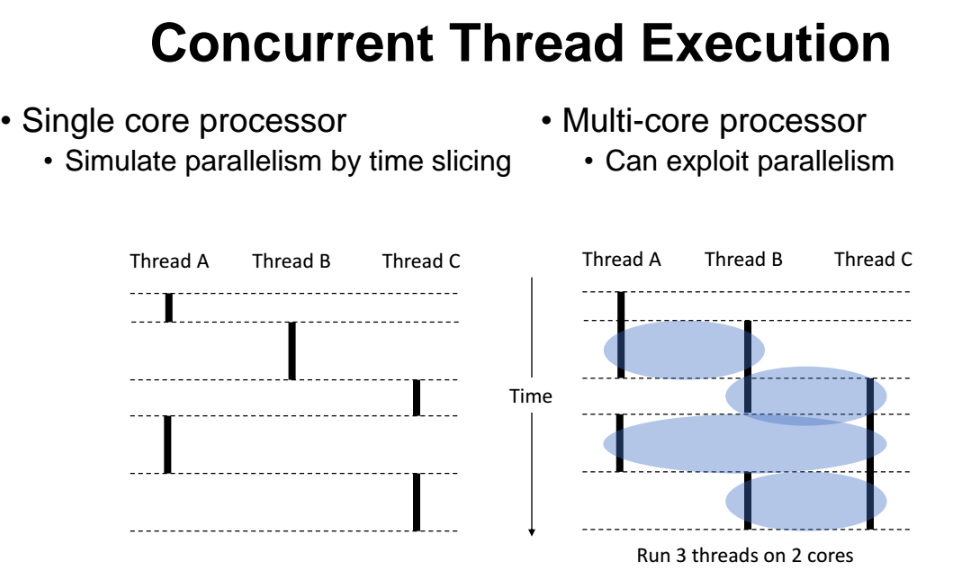
Concurrent 하다는 것은 두 쓰레드(or 프로세스) 가 "동시간" 에 수행되는 것이다.
-
single core(코어 1개) 에서는 코어가 1개밖에 없으므로 동시간대에 하나의 프로세스밖에 실행못함
- 또한 A와 B는 시간대가 겹치므로 Concurrent 하고, B와 C는 Sequential 한것이다.
-
muiti-core(코어 2개) 에서는 동시간대에 2개의 프로세스를 수행가능
- 또한 A,B,C 모두가 Concurrent 하다.
Thread 와 Process 비교

공통점
- 각자 logical flow 를 가지고 있다는 점은 쓰레드와 프로세스 모두 비슷하다.
차이점
- 쓰레드는 코드와 데이터를 공유한다.
- 그러나 프로세스는 각자 독립적으로 본인만의 데이터를 가지고 있다.
POSIX Threads (Pthread) Interface

-
Pthread : POSIX Thread 의 대표적인 표준 쓰레드
-
create, join, self, exit 등의 내장함수들이 있다.
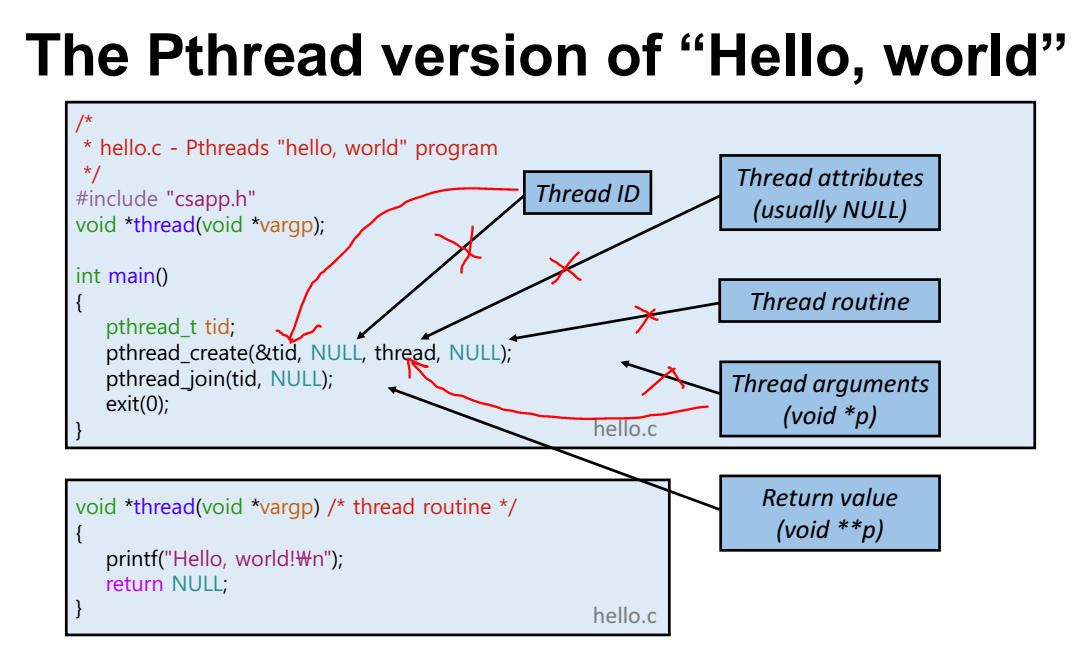
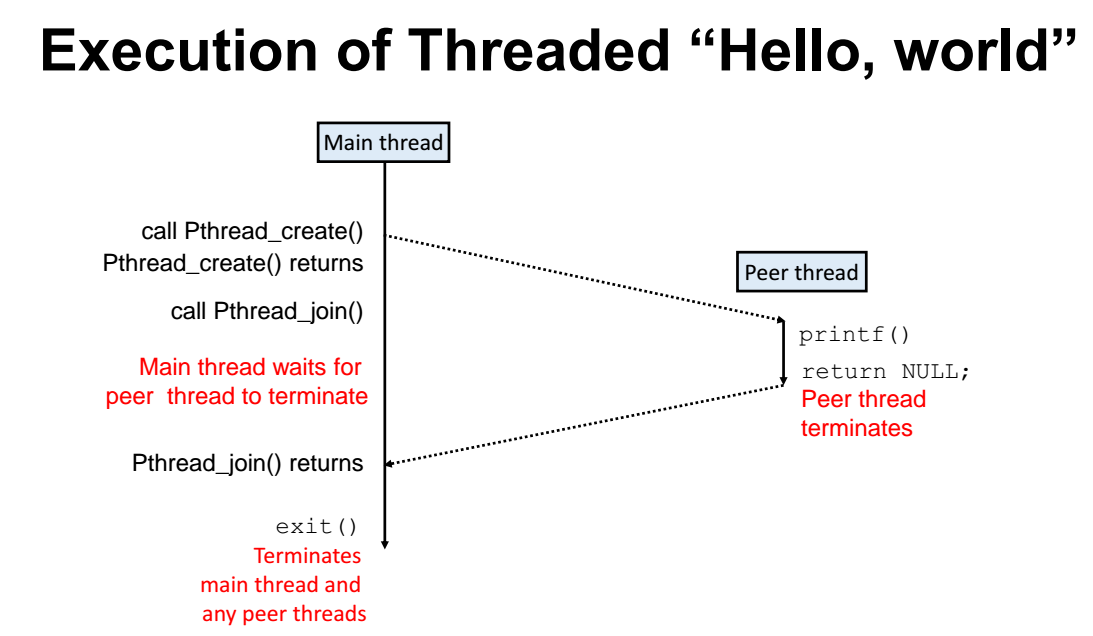
(그림 화살표 잘못된거라 다시 그렸음)
- pthread_create(&tid, NULL, thread, NULL)
-
pthread 를 만들어준다.
-
&tid : thread id 를 받아옴 (process id 처럼 쓰레드도 thread id가 존재함)
-
thread : thread 라는 이름으로 개발자가 만들어준 함수의 주소값을 인자로 넣어줌. 그러면 넣어준 해당 함수를 쓰레드로 만들어준다.
=> main 함수와 thread 라는 쓰레드가 동시에 돌아가기 시작함
(모든 함수가 같은 실행문을 가짐. 즉, main 함수나 thread 함수에서 만일 printf 문을 찍는다면 printf 문이 2번 찍히는 셈임)
-
- pthread_join(tid, NULL) : tid 라는 id 값을 가지는 쓰레드, 즉 thread 쓰레드가 끝날떄까지 기다린다(wait)