
본 포스트팅은 인하대학교 컴퓨터공학과 시스템 프로그래밍 수업자료에 기반하고 있습니다. 개인적인 학습을 위한 정리여서 설명이 다소 미흡할 수 있으니, 간단히 참고하실 분들만 포스팅을 참고해주세요 😎
ELF (Executable and Linkable Format)
앞서 살핀 파일들의 포맷(relocateable, executable, shared object file ) 을 통칭해서 ELF 라고 부른다.
- 위의 3가지 오브젝트 파일들은 표준이 되는 binary 포맷의 obj 파일들이며, 그 어떤 운영체에서도 모두 exe 파일로 변환될 수 있다.
ELF 오브젝트 파일의 Format

ELF 파일은 위와 같은 구조를 가진다. (그런데 실제로는 저렇게까지는 안생겼고, 막상 실제로 열어보면 바이너리들이 주르륵 나오는 형태이다. 그냥 논리적인 구조를 따져봤을 때 저렇게 생겼다는거다. )
ELF 파일의 구성성분
- ELF header : 모든 파일들은 자신이 어떤 형식(포맷)을 가지는지를 정보를 가지고 있어야한다. ELF 파일도 마찬가지다.
- Wordsize, byte ordering, file type (파일의 정보. 예를들어, .o, .exec. .so), machine type(해당 파일이 실행되기 위한 시스템의 정보), ... 등을 저장
-
Segment header table : Page 사이즈, virtual addresses (가상 메모리 주소), memory segments, segment sizes 등등을 저장
-
.text : 어셈블리어 소스코드 부분
-
지난 예제에서 main.c 와 sum.c 를 machine level 로 변환했을 떄 이 부분에 어떻게 들어갈까?
=> 원래는 컴파일된 순서대로 넣는것이 디폴트지만, 중간중간에 함수 호출, 해당 함수로 점프를 뛰는 코드등을 고려해서 알맞은 순서로 구성해서 전체적인 하나의 코드로 합쳐놓은(merge 한) 것이다.
-
-
.rodata : Read only data. 말그래로 읽기전용 데이터 집합. => jump table 이 속한다. (이전에 jump table 이란 c언어의 switch 문을 어셈블리어로 변환했을 때 생기는 테이블이라 말했었다!)
-
.data : 초기화된(initialized) 변수들이 할당됨
ex. local 변수에 넣어놓는 초기값들이 들어감 -
.bss : 변수들중에 초기화하지 않은 변수들 (공간을 차지하지는 않는데 section header 는 있다네?)
-
.symtab : symbol table 이 들어감
-
.rel.text // .rel.data : 앞선 .text 와 .rodata 에서는 코드와 데이터를 section 하나로 모아놨었으나 실제로 실행할떄는 저장되어있는 순서와 동일한 순서로 실행한다는 보장이 없다.
따라서 하나로 모아져있는 텍스트를 실행할 때 어떤 순서로 어떤 offset 을 계산해서 명령어를 수행하는 순서가 바뀌어야 하는지를 저장해놓는다. -
.debug : 컴파일러한테 -g 옵션을 주면 디버깅할떄 필요한 데이터를 이곳에 넣어둔다.
-
Section header table : 각 section 들의 시작주소와 offset, size 등을 저장
Linker Symbols
cf) symbol 은 변수(variable) 과 다른것이다! symvbol 은 "이름"이라고 했었다. 즉 local variable(지역 변수) 와 local symbol 은 다른것이다.
Global Symbols
- 앞에 static 키워드를 안붙인 것들(함수든, 변수든간에). 즉 non-static 인 함수, 변수등이다.
External Symbols
- Global symbol 중에서 external 인 symbol들
(여기서는 그냥 global symbol 과 external symbol 이 동일하다고 봐도 무방!)
Local Symbols
- C언어 함수나 전역 변수중에 static 인 애들
cf) Module : .o 또는 .so 와 같이 independent 하게 떨어져서 컴파일된 바이너리 오브젝트 파일들
Step1 : Symbol Resolution
- 링커의 실행은 크게 2단계로 나뉜다.
symbol resolution 이란 symbol 들이 어딨는지 찾는것이다. symbol 들의 주소들을 찾고 모아서 symbol table 을 만든다.
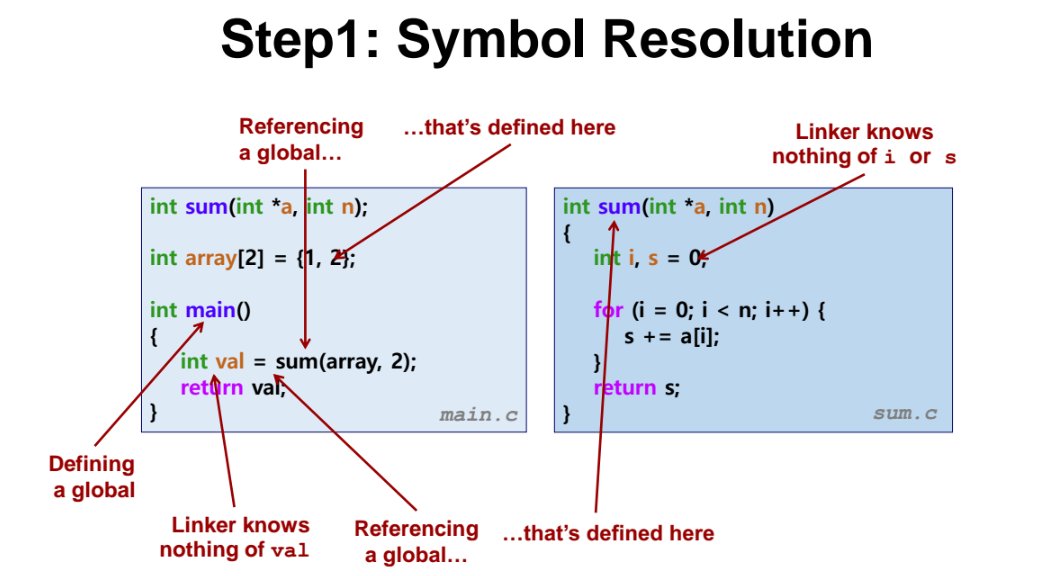
- 링커(linker) 는 변수 var, i, s 같은 것들을 global 인지, local 인지, static 인지 모른다. 몰론 나중에는 최종적으로 global 로 처리가 되긴 하는데, 아직 symbol resolution 단계에서는 해당 변수들이 local 변수인지는 모른다. 즉 신경을 쓰지 않는다.
=> 왜냐하면 링크(link) 할떄 main 함수와 sum 함수가 실행되는 명령어들이 각각 따로 있을텐데, linker 가 해줘야하는 일은 sum 이라는 symbol 이 reference(정의) 되었는데 해당 함수는 main 이 가지고 있지 않는 별도의 함수이다. 그래서 sum 에 대한 정보와 명령어들을 가지고 뭔가를 해줘야하는데, local 변수는 이미 main 안에 다 들어가있다. 즉 어디서 뭔가를 가져온다거나, 다른 곳에 있는 주소를 알아야한다는 등을 할 필요가 없다. 그래서 신경을 쓰지 않는것이다. 어짜피 컴파일 타이밍에 다 처리가됨.
나중에 symbol 테이블에 등록이 되어야하므로 global 로 인식되는 것이다.
Local Symbols

- c언어에는 local non-static 변수, local static 변수가 따로 구분되어서 있다.
local non-static 변수
그냥 평범한 local 변수임. 런타임 타이밍에 필요x. stack frame 에 저장된다.
local static 변수
만일 함수 a( ) 에 static 변수 x 가 있는데 어떤 함수 z를 계속 g 에서 호출하면 x 값이 호출할떄 마다 1씩 증가한다고 해보자.
그런데 만일 변수 x가 static 이 아니였다면, 그 함수 z 안에 들어가서 x 값을 1증가시킨다고 한들 해당 x 변수는 없어질것이다 (그냥 non-static 한 local 변수라면 스택안에 들어가 있으므로 영향을 못끼침).
반면 이 경우는 static local 변수인데, 해당 변수는 스택에 따로 가지고 있는 것이 아니고 dss 나 data 영역(section) 에 따로 가지고 있으므로 다른 함수의 영향을 받을 수 있다.
static 변수의 생명시간은 프로그램이 종료되기 전까지 유지된다 (non-static 한 local 변수는 함수 호출이 끝나면 스택에서 제거되서 없어진다)
예제 분석 : 동일한 이름의 static local 변수가 여럿 존재하는 경우
- 위 예제는 함수 f 와 g 에 모두 동일한 이름의 static local 변수 x 를 가지고 있다. 이 경우는 나중에 symbol resolution 을 할떄 x가 2개가 생긴다. 알아서 링커(linker) 가 각 변수 x에다 .1 과 .2 를 붙여줘서 x.1 과 x.2 가 되고 둘을 구분할 수 있게 symbol table 에 저장해준다.
Progam Symbol 의 Strong, Weak
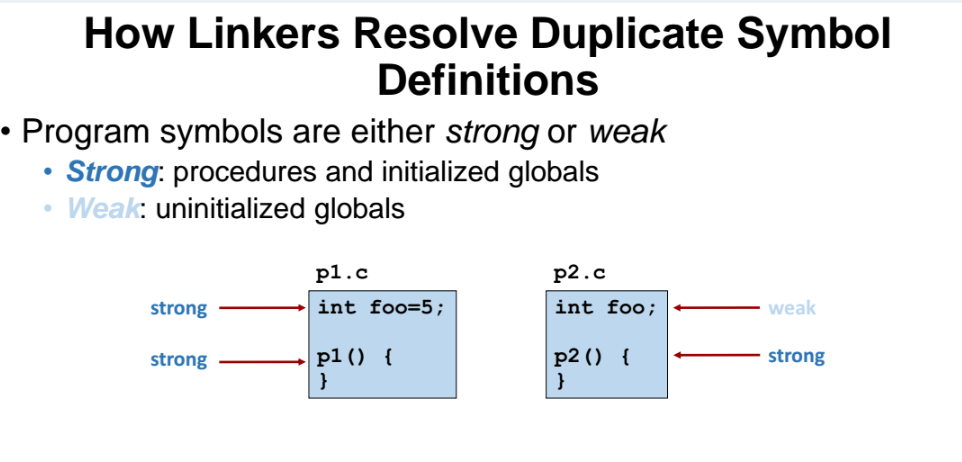
프로그램의 Symbol 이 이름이 중복되는 경우, storing, weak 상태에 따라서 프로그램을 구분지어준다.
linker 입장에서는 프로그램 symbol 이 strong 한지 weak 한것인지의 개념이 있다.
strong vs weak
=> strong 과 weak 는 초기화 여부 에 따라서 strong 한지, weak 한지가 나뉜다.
-
strong 한 symbol : strong 이 weak 보다 우선순위가 높다. 즉 이름이 동일한데 strong 이 있다면 이를 먼저 고른다. 위 예제에서 파일이 2개 있는데, 변수 foo 가 중복되서 선언되어 있고, p1.c 파일에서 foo = 5 로 초기화가 되어있다. 초기화 되있는 쪽이 strong 하다. 그러면 link 타이밍에 p1.c 에 있는 foo 변수를 고른다.
-
weak 한 symbol : 초기화 되지 않는 symbol
Linker’s Symbol Rules
링커의 symbol 에 대한 규칙을 살펴보자.
-
이름이 동일한 중복되는 strong symbol 이 있다면 에러가 발생한다.
-
이름이 다 같은데 하나만 strong symbol 이고, 나머지가 모든 weak symbol 인 경우 strong symbol 을 택한다.
-
weak symbol 만 존재하는 경우, 먼저 linking 된 symbol 을 택한다.
Linker Puzzles
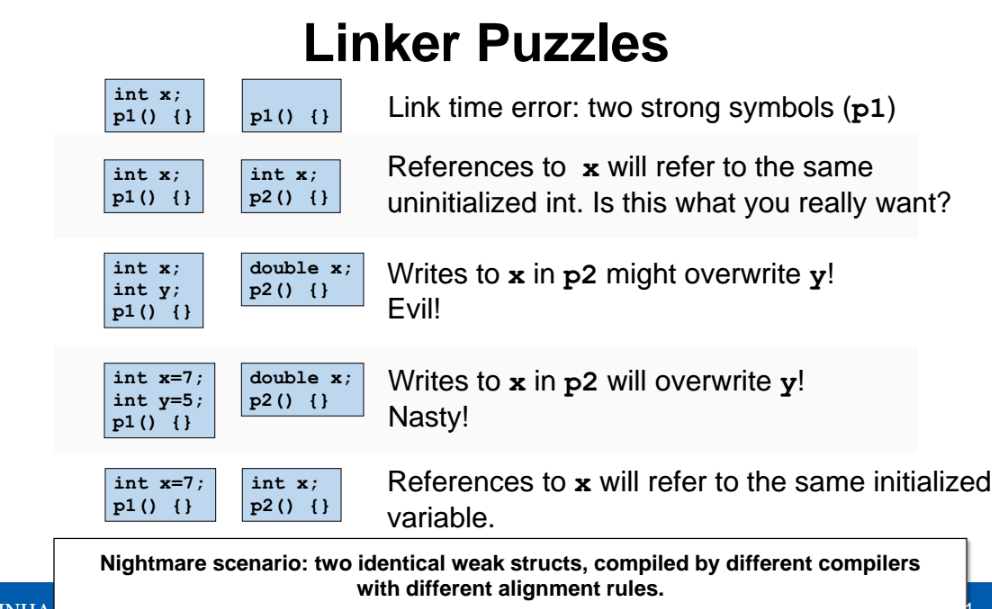

p1 함수가 위처러 2개 있다면 에러가 발생한다. p1 이 둘다 global 이기 떄문에 strong symbol 이기때문

함수 이름은 p1, p2 로 달라졌으나 변수 x가 global 변수이고 중복된다. 에러는 발생하지 않으나 둘 중 어느것이 선택될지는 모른다.

함수 이름도 p1, p2 로 다르고 변수 x의 타입은 이름의 중복되지만 타입이 다르다. symbol resolution 에서는 타입을 보는 것이 아닌, symbol 이름을 보기 떄문에 타입을 보지않는다. 따라서 둘다 link 를 한다. 그런데 실제로 런타임 할떄는 8바이트 짜리인 double 이 int 를 덮어씌운다.

double x 가 int x 를 덮어씌운다. (앞서 언급했듯이 초기화 되있는것이 더 strong 하지만, 타입이 더 큰것이 작은놈을 덮어씌워버림)
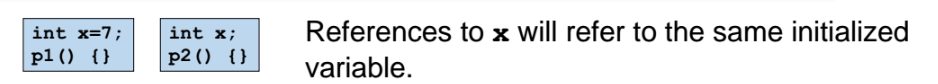
초기화된 x 가 strong symbol 이다.
Global Variable
- global 변수는 쓰지말자. static 변수로 대신 사용하자!
- 만일 global 변수를 사용한다면 초기화를 꼭 해서 strong symbol 로 만들자!
- external global 변수를 reference (정의)한다면 extern 키워드를 사용하자.
Relocation
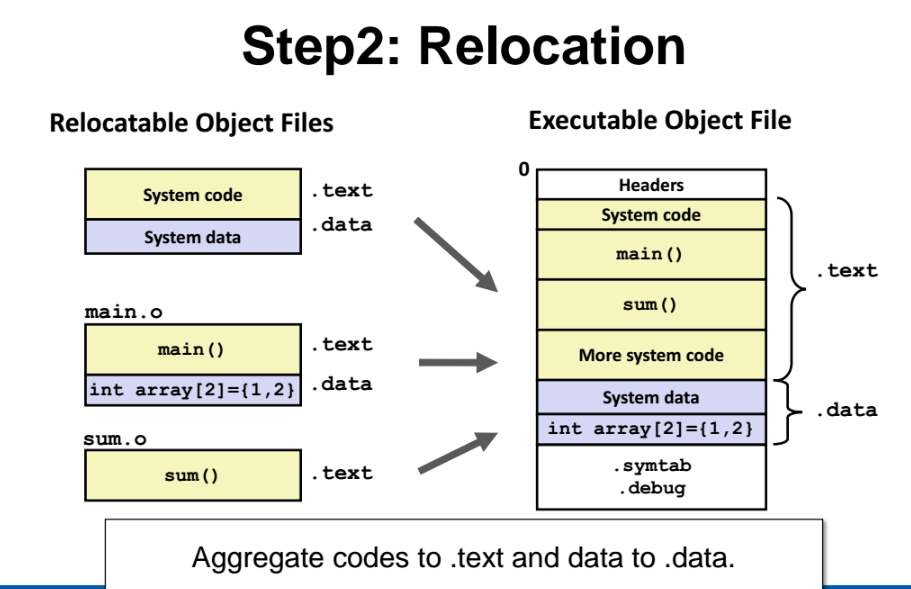
system, main, sum 오브젝트 파일이 다 따로였지만, exe 파일을 만들때 하나로 병합된다. 이떄 exe 파일의 구성 순서는 오브젝트 파일을 준 순서대로 구성된다. 즉 재배치해주는 과정을 relocation 이라고한다.
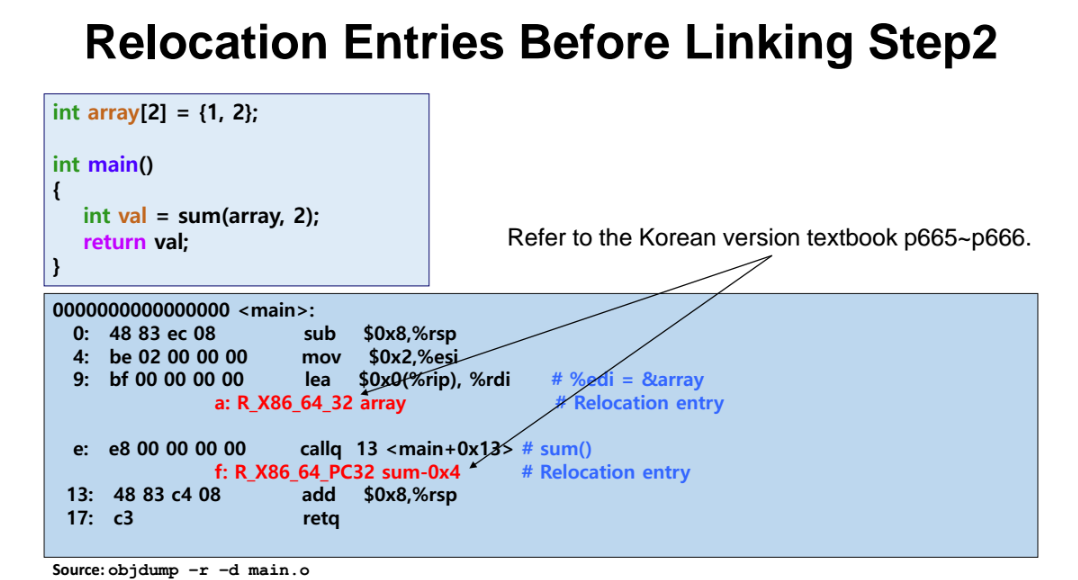
- 실제로 만들어진 exe 파일은 내가 global 변수를 쓸거라면 쓰는 명령어 바로 다음에 붙어있어야 하고, 다른 함수로 점프 뛸거라면 그 다른 함수 코드 다음에 바로 있어야한다.
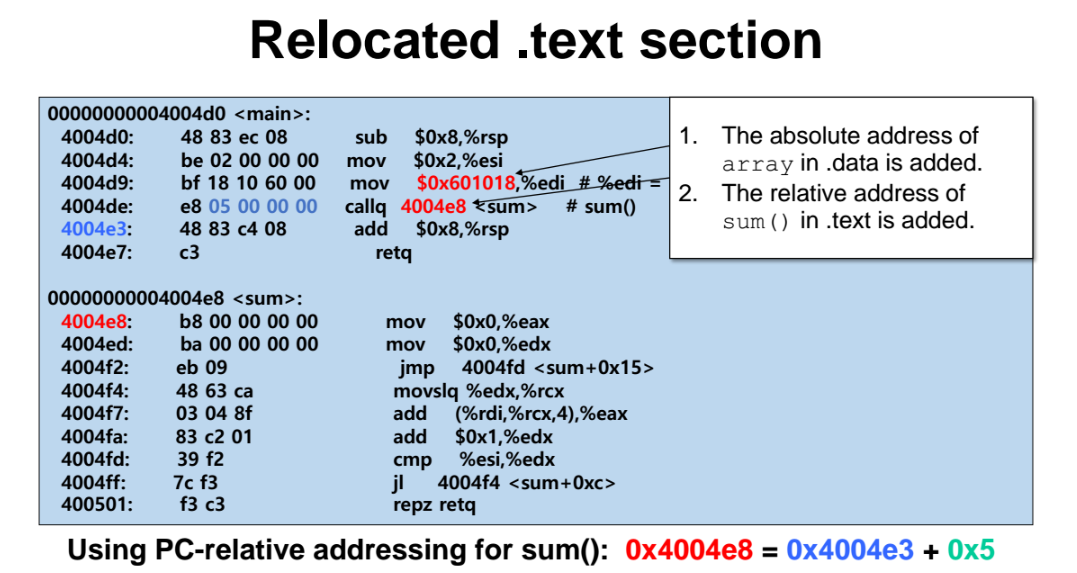
위는 relocated 된 이후의 코드이다.
exe 오브젝트 파일 가져오기(loading)
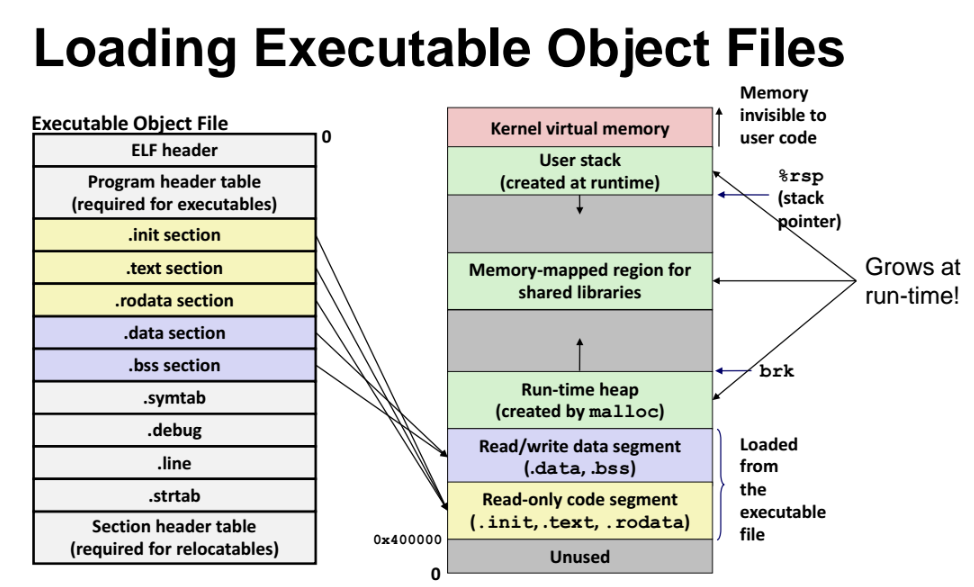
위 그림은 보면, 앞서 배웠던 내용들이다. 스택은 위로 자라나고, 힙은 아래로 자라난다.
loading 할떄 어떻게 되는지를 보면, 우선 왼쪽은 executable 파일이다.
(다음 시간에 자세히 설명한다 하심)
Packaging Commonly Used Functions
앞으로 linking 라이브러리들을 살펴볼것이다.
이 방식은 프로그래머가 직접 자주 사용하는 함수를 모아서 packaing 시키켜서 라이브러르로 만든 방식이다.
그런데 이렇게 계속 함수들을 모으는 방식은 귀찮으니, 이를 해결해주는 2가지 옵션이 있다.
1) 모든 함수를 하나의 소스파일에 다 떄려박으면, 컴파일 타이밍에 한번에 linking 이 된다.
- ex) malloc 과 관련한 함수들을 한 파일에 다 몰아넣고, malloc 키워드만 붙여주면 전체 함수들을 한번에 컴파일할떄 linking 이 된다.
2) malloc 을 부르는 데이터가 다 다른 파일에 있다치고, malloc 을 각 소스코드 파일에 다 붙이는것이다.
(위와 같은 방식은 둘다 안좋으니, 외부 라이브러리를 사용하자! 그래서 등장하는 것이 static 라이브러리와 dynamic 라이브러리이다. )
Static library (옛날 방식)
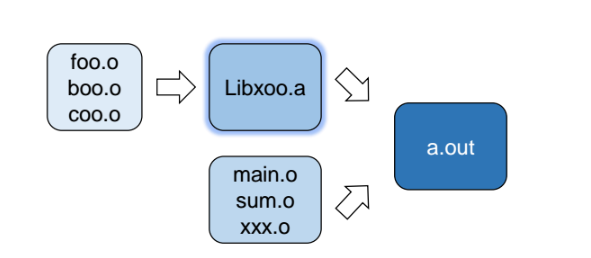
-
.a 로 끝나는 파일들이 Static library 파일이다. 여러개의 .o 파일들을 모아놓은 것이 .a 파일이다.
-
컴파일 타이밍에 linking 타이밍에 여러개의 .o 파일들이 .a 로 통합된다.
=> 즉, 미리 build 해놓은 오브젝트 파일들을 하나로 합쳐서 쓰기 편하게 보관하는 방식이다.
- 미리 컴파일을 해놓았고 relocate 도 어느정도 해놓았기 떄문에 그냥 가져다 붙이면 되서, linking 속도가 빠르다.
Static library 생성과정
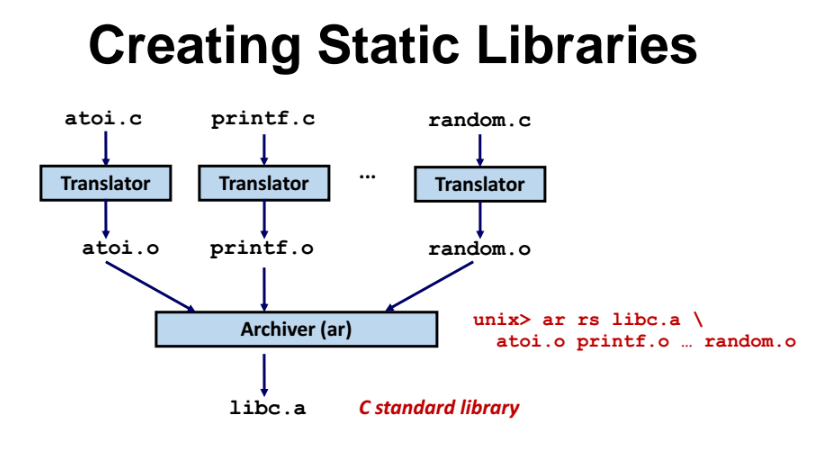
-
컴파일을 시작한다. Translator 를 통해 각 c언어 파일을 오브젝트로 만든다 (각 파일을 따로 컴파일 하는것)
-
오브젝트 파일에 대해 linker 가 아닌 Archiver 라는 것이 있는데, 이 컴파일러 툴을 가지고 오브젝트 파일들을 하나로 합쳐서 .a 파일을 만든다.
자주 사용되는 library 들
1. libc.a
- C언어의 표준 라이브러리
- I/O, memory 할당, malloc, read, write, random, data 와 time, string 관련 모든 함수들이 이 안에 들어있다.
(그냥 딱봐도 기초적이고 프로그래밍하는데 필수적인 것들이 다 들어있다)
2. libm.a
- C언어의 math 라이브러리
- floating point math 함수들(sin, cos, tan, log, exp, sqrt, ...) 이 들어있다.
static library를 Linking 하기

main 함수가 addvec 함수를 실행하고 싶은 경우, addvec 함수가 자주 사용될 것 같다면 libvector.c 파일로 묶어서 libvector.c 를 라이브러리처럼 사용한다.
아래 구조처럼, c언어 파일들을 컴파일해서 Archiver 를 통해 libvector.a 를 만들고, 헤더파일을 미리 만들어놔서 main 를 사용할떄는 헤더파일을 include 하고 내가 쓰고싶은 그 라이브러리 안에 무슨 함수가 있는지 알것이고, 그것을 가져다 쓰면 된다. 그러면 컴파일하고 linking 할때 linker 가 헤더파일을 가져오면 된다
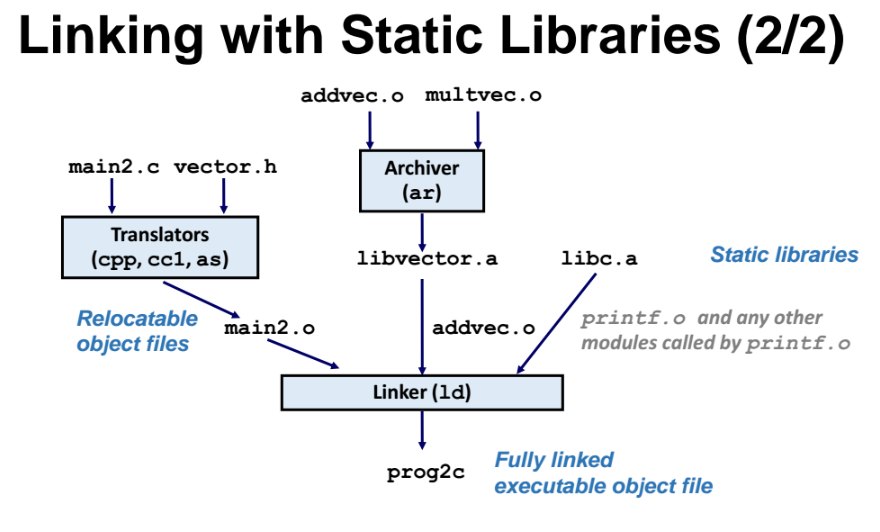
Static library 사용하기
-
기본적으로 전부 external reference(외부에서 정의한것) 이다. 우리가 직접 정의한게 아니라 다른 모듈에 있는 것을 가져온 것이므로.
-
main 함수 입장에서는 다 뒤적뒤적해서 필요한 symbol 들을 그떄마다 찾아야한다.
-
main 함수를 Scanning 할때 라이브러리 안에 있는 함수를 호출했다면, 해당 함수들은 당연히 main 함수안에 없을것이다(라이브러리에 있을테니.)
=> 일단 resolve(해결)이 안된 애들을 모아놓고 나중에 라이브러리에서 뒤적뒤적 하는 것이다.
- resolve 를 할때 순서가 중요하다. 라이브러리가 보통 맨 뒤에 와야한다.
Shared library (최신 방법)
- static libray 에 비해 modularity 밖에 장점이 없었으나,
static libray 를 사용한 경우 단점
-
executable 파일에 모든 오브젝트 파일들을 가져다 붙이는 방식이었다.
=> 만일 프로그램 2개를 만들었는데, 두 프로그램에서 모두 libc 라이브러리를 사용한다면 두 곳에 모두 붙는다. -
런타임시 프로그래밍 두 개를 동시에 실행시키면 완전히 똑같은 2개의 라이브러리가 중복해서 메모리에 올라가있게 된다.
-
라이브러리에 문제(버그)가 있어서 프로그램1에서 해당 라이브러리를 수정을 하는경우, 프로그램2에도 영향을 끼친다. 프로그램2 입장에서는 해당 라이브러리를 다시 link (컴파일을) 해야할 수 있다.
=> 장점 : static library 가 shared library 보다 더 빠르다. linking 할떄 relocation 이 미리 되있어서 원하는 주소를 다 알수있다. 그리고 런타임할떄 메모리에 라이브러리들을 다 미리 올려놓는다.
shared libray 를 사용한다면 단점, 장점이?
-
단점 : 메모리가 아닌 디스크 어딘가에 저장해 놓는다. (자주 쓰이는 녀석들은 cache 에 저장)
=> 런타임 할때마다 relocation 을 해줘야한다. -
오브젝트 파일이 load time 또는 런타임에 직접 라이브러리를 가져온다.
Shared library 의 2가지 방법
1) load-time(loading time) 에 linking 해서 라이브러리를 가져오는 방법
- executable 파일이 처음으로 loading 되고 run 될때 (load-time 일떄) 라이브러리를 떙겨온다.
2) run-time 에 가져오는 방법
- 프로그램을 잘 실행하고 있다가 필요할 때 라이브러리를 동적으로 떙겨온다.
loading time 에 Dynamic linking 하기
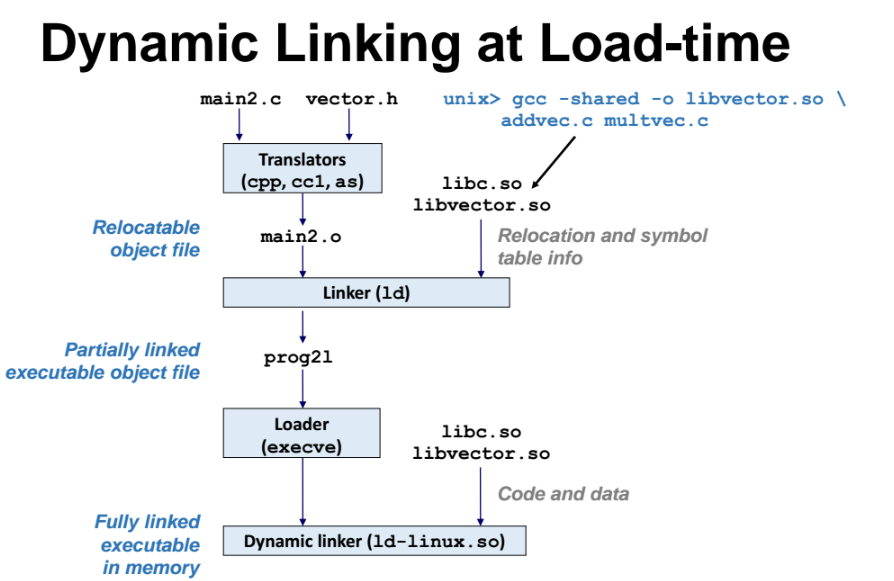
libc.a, libvector.a 와 같은 .a 파일이 아닌 .so 파일이 만들어진다.
=> 즉, 컴파일하고 link 할때 relocation 하고 symbol table 까지만 만들어놓는다.
그런데 이때 프로그램에 실제로 해당 라이브러리를 붙여놓는게 아니다. 주소계산만 해놓는 것이다.
그러고 나중에 실행할대 dynamic linker 에 의해 런타임 타이밍에 필요할때 라이브러리를 동적으로 유도리있게 가져다 주는 방식이다.
=> offset 은 미리 계산되서 meta data 들을 executable 에 넣어만 놓고, 실제로 런타임될때 가져오는 것이다.


