
본 포스트팅은 인하대학교 컴퓨터공학과 오픈소스 SW 개론 수업자료에 기반하고 있습니다. 개인적인 학습을 위한 정리여서 설명이 다소 미흡할 수 있으니, 간단히 참고하실 분들만 포스팅을 참고해주세요 😎
Series, DataFrame
- Pandas 에서는 Series, DataFrame 객체라는 것을 자주 사용함

Series
- 판다스에서 사용하는 1차원 배열 객체
- 리스트와 같은 시퀀스 데이터타입을 파라미터로 받음
Series 는 인덱스 + Value 의 쌍으로 구성된다.

Series 의 속성들 : value, index
이 속성들을 사용하면 Series 의 index 와 value 값만 따로 추출할 수 있다.
value : Series 의 value 값만을 따로 추출

index : Series 의 index 값만을 따로 추출
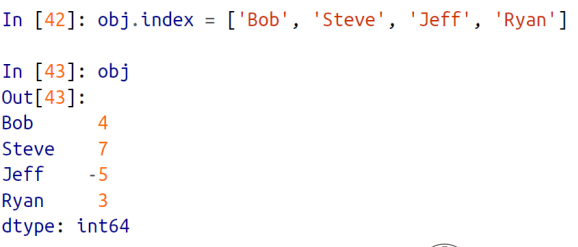
- obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan']
- obj 의 각 index 값들을 원하는 값들로 새롭게 할당가능
=> 기존 인덱스 값으로 0,1,2,3 이 할당되있던 것을 주어진 문자열로 바꿈
- obj 의 각 index 값들을 원하는 값들로 새롭게 할당가능
Series의 index
Series 객체 생성시 index 바로 지정해주기
Series 객체를 선언할때 아예 index 값들을 처음부터 지정해줄 수 있다.
=> Series의 첫 인자로는 리스트와 같은 시퀀스 객체를 넣어주고, 2번쨰 인자로는 index 옵션을 통해 index 값들을 지정해주면 된다.
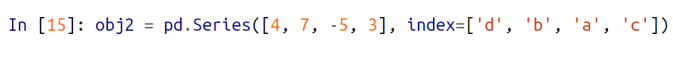
인덱싱하기
우리가 설정한 라벨값을 기반으로 인덱싱을 하면된다.

필더링, 스칼라 곱, 수학연산 함수, .. 등을 적용한 결과로 value 값은 변해도, 그에 매칭하는 index 값들은 변하지 않는다.
당연한 말이지만 그렇다.
아래처럼 여러 기능을 적용해도 index 값들은 변함이 없다.

Series 와 파이썬 Dictionary
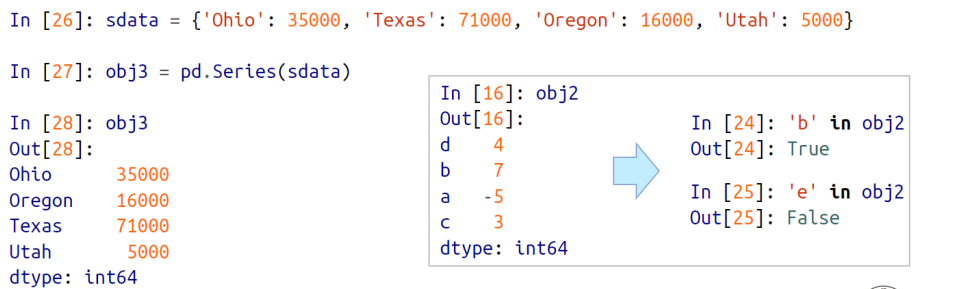
- Series 가 파이썬 딕셔너리를 인자로 받게되면, 딕셔너리의 key값이 Series 의 인덱스 값이 되고, 딕셔너리의 value 값은 Series 의 value 값으로 변한다.
딕셔너리를 인자로 받을때, key 값을 그대로 받는것이 아니라 오름차순으로 정렬해서 key 값을 바는다.
=> 그래서 아래 예제처럼, key값이 Ohio, Texas, Oregon, Utah 는 정렬되어서 Ohio, Oregon, Texas, Utah 순서로 key 값이 할당된다.
Series는 원하는 인덱스만 값을 추려서 따로 값을 할당할 수 있다.
직전 위의 예제를 보면 California 라는 인덱스가 없다. 그런데 아래 예제에서는 인덱스 값중에 하나로 California 를 넣어놨다.
그러면 인덱스와 key 값이 서로 매칭이 되지 않을것이다. 그런데 판다스에서는 자동적으로 인덱스에 존재하지 않는 key 값을 그냥 null 로 채워준다.
그리고 이 인덱스에 해당하는 value 부분만 자동적으로 채워준다.
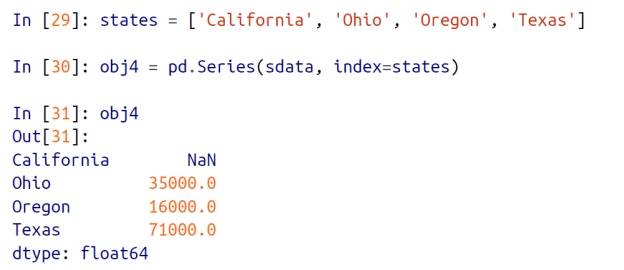
=> 원하는 인덱스는 states 라는 것을 가지고 있는데, states 인덱스에 해당하는 값을 sdata 를 통해서 추출해온다.
그런데 Califonia 라는 것은 sdata 에 없기때문에, 이 경우에 대해 에러처리하는 것이 아니라 Califonia 라는 key 값에 대한 value 에다 null 값으로 넣어주고 나머지 존재하는 인덱스들에 대해서만 값을 넣어주는 것이다.
- 그래서, 원하는 인덱스의 결과만 추출해줄 수 있는 기능도 존재하는 것이라 생각하면 된다. 원하는 인덱스 값이 없다면 null 값으로 넣어준다.
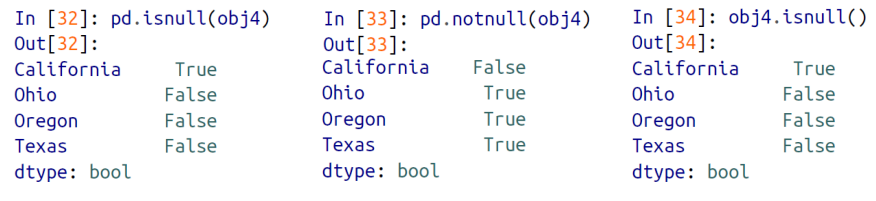
isnull, notnull 함수
missing data 를 처리할 수 있는 함수
-
pd.isnull( ) / obj4.isnull( ) : value에 null값을 저장하고 있는 것들에 대해 True 를 출력
-
pd.notnull( ) / obj4.notnull( ) : value에 null이 아닌 값을 저장하고 있는 것들에 대해 True 를 출력
인덱스를 기준으로 자동 오름차순 정렬
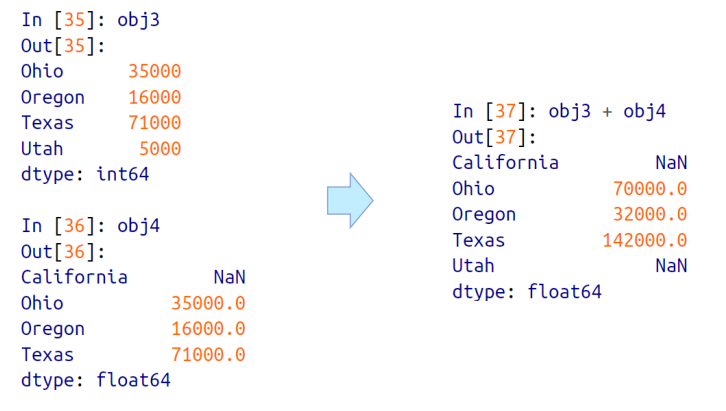
Series 는 앞서 언급했듯이, 인덱스를 기준으로 자동 오름차순 정렬을 해준다.
=> 아래 예제에서 obj3 과 obj4 Series 객체를 더한 결과도 자동으로 오름차순 정렬이 된 결과가 나온다.
두 Series 객체의 인덱스가 밎지않아도 연산을 진행한다.
-
obj3 과 obj4 는 인덱스 값이 다른것들이 일부 있어서 (ex.Ohio 인덱스는 공통적으로 겹치지만, California 와 Utah 의 경우 인덱스 값이 다르다.) 에러가 발생한다고 생각할 수도 있겠지만, 이 경우는 인덱스를 그냥 통합시켜서 출력시켜버린다.
즉 같은 겹치는 인덱스끼리에 대해서는 연산을 진행해서 출력하고, 당연한 소리지만 서로 다른 인덱스에 대해서는 그냥 출력한다.
name 옵션
- Series 자체에다 이름을 할당시켜주는것
=> obj4.name = 'population' : obj4 라는 Series 객체 자체에다 population 이름을 부여한것이다.
- Series 의 index 에도 이름을 지정해줄 수 있다.
=> obj4.index.name = 'state' : obj4 Series 객체의 index 에 state 라는 이름을 부여함

DataFrame
- 2차원 행렬형태
- 각각의 컬럼(열)에 대해서 다른 종류의 데이터를 가질 수 있다.
- 인자값으로 리스트,딕셔너리와 같은 시퀀스 자료형과, 2차원 numpy block 등을 받을 수 있다.
DataFrame 선언방법
- 딕셔너리 형태인 key-value 쌍으로 구성된다.
보통 value 에 들어가는 데이터 형태는 Numpy 배열이다.
=> 그래서 DataFrame 생성시에 value 에 Numpy 배열을 넣어주면 된다.
츨력 결과를 보면 알듯이, DataFrame 의 각 key 에 해당하는 값들이 column 에 순차적으로 저장된다.

head() 함수
- df.head() : 해당 DataFrame의 상위 5개의 데이터에 대한 row만 출력

columns 옵션
-
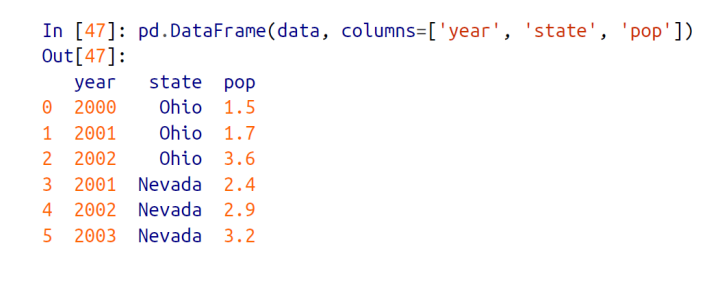
DataFrame 의 컬럼(열)의 순서도 지정이 가능하다. 만일 DataFrame의 기존의 컬럼의 순서가 pop, state, year 순서였다면, 아래처럼 columns 옵션을 부여해서 우리가 원하는 순서대로 컬럼의 순서를 변경 가능하다.
-
그리고 columns 옵션에 기존에 없었던 컬럼을 새롭게 지정해주면, 아래처럼 새로운 컬럼이 생성되고 그에 속하는 모든 value 들은 null 로 초기화된다. (새롭게 생성된 해당 컬럼에 속하는 value 들이 없기 때문에 일단 null 로 초기화됨)
row 옵션
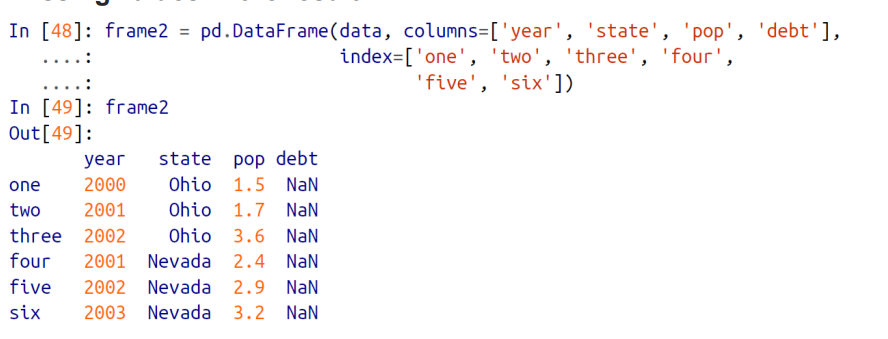
- 또한, 아래처럼 row(행)에 대해 index 에 대한 라벨링, 순서 정보를 넣을 수 있다.
=> 즉, 컬럼에 대한 라벨링은 columns 옵션으로, row(행)에 대한 라벨링은 index 옵션으로 해줄 수 있다.
그리고 각 컬럼에 대한 인덱스 정보를 출력할떄는 아래처럼 columns 속성을 통해서 출력 가능하다.

DataFrame의 컬럼 or 행에 접근하기 (인덱싱)
column 에 대해 접근하기
- 배열에서 쓰는 인덱싱처럼 하면된다. 그러면 해당 컬럼의 row 정보들이 출력된다.

- 또는 컬럼을 속성(attribute) 처럼 아래와 같이 접근할 수도 있다.
아래 예제는 year 라는 컬럼에 접근하는 것이다.
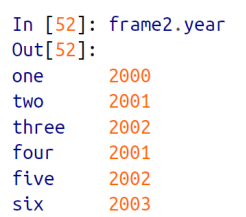
row 에 대해 접근하기
- loc 이라는 속성으로 접근(인덱싱) 가능하다.

인덱싱을 통해 원하는 특정 컬럼의 데이터들을 모두 새롭게 할당할 수 있다.
예를들어, 아래와 같이 debt 컬럼에 16.5 와 같은 스칼라 값이나, arange 와 같은 배열로 해당 컬럼을 채워줄 수 있다.

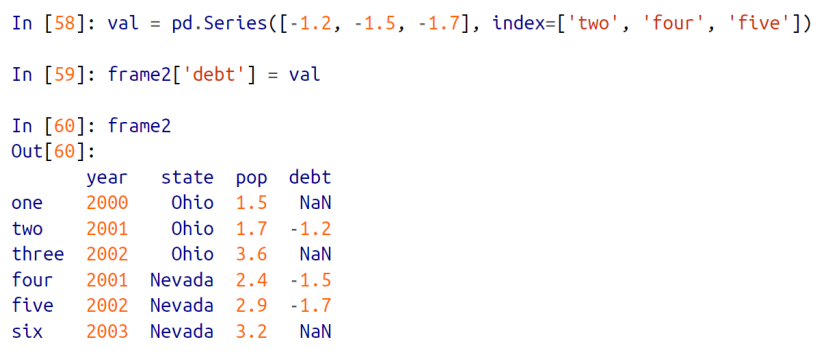
Series의 값도 원하는 특정 컬럼에 할당 가능하다.
Series 는 index 가 따로 존재했었다. 이 index를 통해서, DataFrame 에 만든 인덱스에 매칭을 시켜서 값을 할당시킬 수 있다.
아래 예제에서 val 이라는 Series 는 index 에 two, four, five 라는 인덱스를 가진다. 그리고 그 val 이라는 Series 값을 frame2의 debt 컬럼에 할당시켜주면 two, four, five 에 매칭되어서 Series 의 값이 자동으로 할당된다.
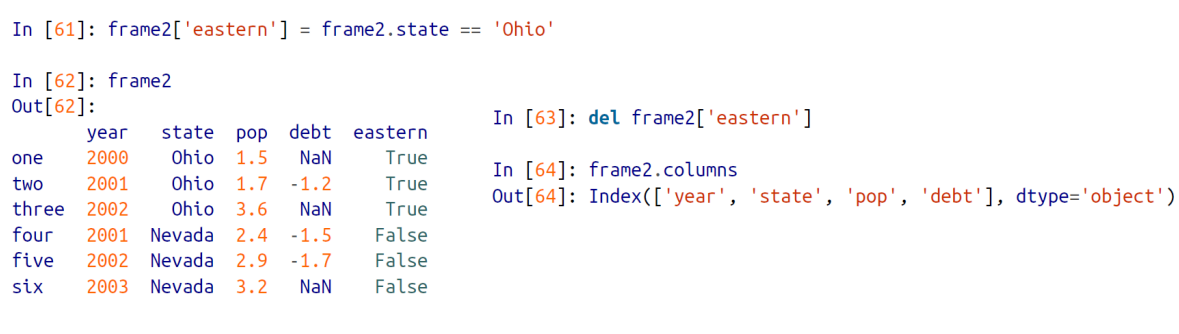
del 키워드
- DataFrame 의 특정 컬럼을 삭제
del frame2['eastern'] : eastern 이라는 컬럼을 삭제
row, column 모두 라벨링하기
- DataFrame 을 딕셔너리를 할당시킨 경우 column 에 대한 라벨링은 되지만, row에 대한 라벨링을 되지 않았다.
=> row 에 대한 라벨링도 하고싶다면, 딕셔너리 안에다 딕셔너리를 할당하면 된다.
DataFrame 의 key 부분은 그냥 그대로 냅두고, value 부분을 딕셔너리로 채워주면 된다.
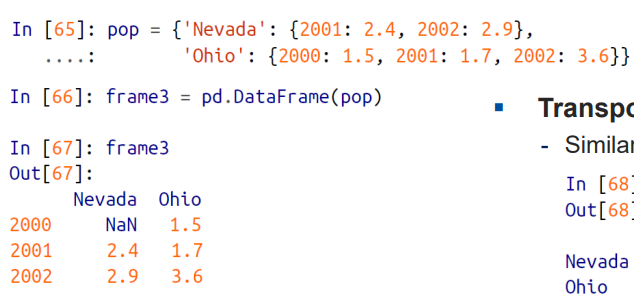
예제에서 Nevada 컬럼의 경우 2000 row 에 대한 값이 없어서 none 값이 채워진다.
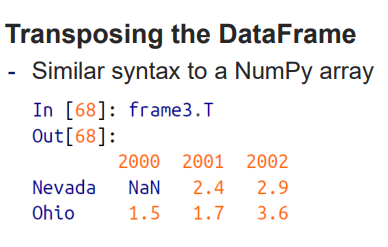
Transpose
Numpy와 마찬가지로 T 를 사용해서 전치행렬을 만들수있다.
Series 객체를 가지고 있는 딕셔너리도 Dataframe 에 넣을수있다.
Series 객체를 value 값으로 넣을수있다.

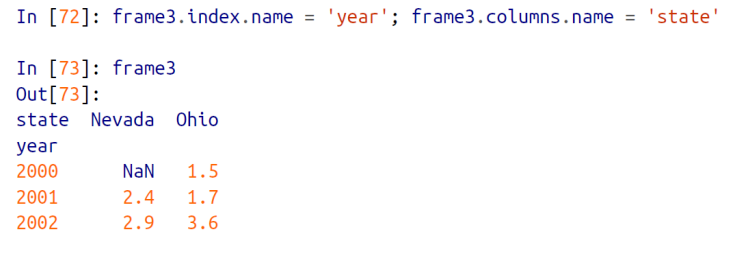
row 와 column 에 해당하는 인덱스에 이름을 할당해줄 수 있다.
Series 처럼 이름 할당이 가능하다.
- df . index . name : DataFrame의 row 에 해당하는 이름 설정
- df . columns . name : DataFrame의 컬럼에 해당할는 이름 설정
values 속성
-
values 속성으로 DataFrame 의 value 부분만 따로 추출 가능하다.
-
df.values

Index Object
- 각 축에대한 이름 또는 해당 축에대한 meta data 를 저장하는 객체

Reindexing : reindex 함수
- 말그대로 인덱싱을 새로 하는것
예를들어 아래처럼 Series 객체에 인덱스값을 d, b, a, c 를 할당한 경우에

출력을 해보면 아래와 같을것이고,

아래처럼 reindex 함수로 Reindexing 을 해준다.
기존의 인덱스는 d, b, a ,c 였으나 e 라는 인덱스를 새롭게 추가하고 기존에 존재하던 인덱스의 순서도 a, b, c, d, e 순으로 새롭게 바꿔주었다.

그러고 출력을 해보면 아래와 같다.
인덱스 e는 기존이 없었던 인덱스로써, 새롭게 생긴 인덱스로써 그에 대한 value 값은 none 값을 넣어준다.

ffill
Reindexing 을 하다보면 간혹 missing value 가 발생할 수 있다. 즉 중간에 값이 비어진 경우가 발생할 수 있다. 이렇게 중간에 비어있는 부분을 채우는 방법을 interpolation 이라고한다. interpolation 은 ffill 함수로 할수있다.
- reindex 를 할때 method 옵션에 ffill 이라는 값을 할당해주면 자동으로 직전의 인덱스에 저장된 값(value)으로 채워진다.
예제
기존의 인덱스 값은 아래처럼 0,2,4 였는데

reindex 를 할떄보면 인덱스 1,3,5가 없다. 이떄 method 옵션에 fill 을 할당했으므로, 각 인덱스 1, 3, 5 는 본인의 직전 인덱스의 value 값으로 채워진다.
즉, 인덱스 1은 직전 인덱스인 인덱스 0의 value 인 blue 로, 인덱스 3은 인덱스 2의 value인 purple 로, 인덱스 5는 인덱스 4의 value 값인 yellow 로 채워진다.

row, column 옵션 : 행,열 모두 Reindexing 가능
DataFrame은 row 와 column 이 존재할텐데, row 와 column 에 대해 몯무 reindexing 이 가능하다.
- index 옵션 : 인덱스(행)에 대해 reindexing 하는 옵션
- columns 옵션 : 컬럼(열)에 대해 reindexing 하는 옵션
row (인덱스) 에 대해 reindexing 해보기
아래처럼 기존 인덱스로 a, c, d 를 부여하고, 컬럼 값으로 Ohio, Texas, California 를 부여했다고 해보자.

출력을 해보면 아래와 같을 것이고,

아래처럼 인덱스(row) 에 대해 reindexing 을 할수있다.

column 에 대해 reindexing 해보기
아래처럼 coulumns 옵션으로 컬럼(열)에 대한 reindexing 을 진행할 수 있다.
기존에 Texas 와 California 는 있었던것이라 값이 할당되지만, Utah 의 경우에는 새롭게 생긴 컬럼이다. 따라서 Utah 에 대한 value 의 값들은 none 으로 채워진다.

loc 속성 : row 와 column 을 동시에 reidnexing 하기
loc 옵션으로 row 와 column 을 동시에 reidnexing 할 수 있다.
- loc 옵션 : 라벨명(라벨 이름)으로 reindexing 을 하는 방법이다.
- 첫번쨰 인자 : reindexing 하고자 하는 row에 해당하는 인덱스들
- 두번쨰 인자 : reindexing 하고자 하는 column에 해당하는 인덱스들

drop 함수
- drop 함수 : 특정 row 나 column 을 삭제한 새로운 객체를 리턴해주는 함수
주의할점 : drop 함수는 원본 Series 객체의 특정 데이터를 삭제하는 것이 아니다. 그냥 삭제된 결과만 리턴해주는 것이다.
row만 삭제시켜보기
예를들어 아래와 같은 Series 객체에 대해

drop 함수를 통해 원하는 row 를 삭제한 새로운 Series 객체를 리턴받을 수 있다.
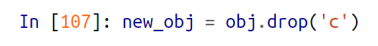
특정 row인 c 행을 삭제한 new_obj 를 출력해보면 아래와 같을것이고,

아래처럼 여러 row 에 대해서도 삭제가 가능하다.
이때 주의할점은 원본 Series 객체(obj)에서 row 가 삭제된것이 아니다.

axis 옵션 : row, column 모두 삭제시켜보기
axis 옵션을 통해 row, column 중에 원하는 것을 삭제시킬수있다.
row 삭제 : axis=0
axis 옵션의 디폴트 값은 0으로, axis 옵션을 별도로 굳이 부여하지 않은 경우는 axis 옵션에 0이 할당된 것이며, row 에 대해 삭제하는 것이다.
(즉 row 를 삭제시키는 경우는 별도로 굳이 axis 옵션을 선언할 필요없음! 어짜피 axis 옵션에 자동으로 디폴트 값인 0이 할당되기 떄문)

column 삭제 : axis = 1 또는 axis = 'columns'
- column 을 삭제하고 싶다면 axis 옵션에 1을 부여하면된다.
아래의 경우, two 라는 columns 를 삭제하는 경우이다.

또한 당연히 아래처럼 row 삭제와 마찬가지로 동시에 여러 column 을 삭제 가능하다. 그리고 axis 에 1 말고도 'columns' 라는 값을 부여해서 column 을 삭제 가능하다.

inplace 옵션 : 원본 Series 객체 데이터 삭제
원래 drop 함수는 원본 Series 객체의 데이터를 삭제시키는 것이 아니였다. 그런데 inplace 옵션에 True 를 부여하면 원본 Series 객체의 데이터도 삭제가 된다.
(inplacde의 디폴트 값은 False 임)
- 아래에서는 c 라는 row 를 삭제하는데, 실제 obj 객체의 c 라는 row 를 삭제시키는 것이다.

Series의 인덱싱하기
numpy 랑 거의유사함. 다른점은, Series 배열에는 Numpy에는 없는 실제로 우리가 할당할 인덱스가 존재한다.
1. 원하는 부분을 인덱싱 가능하다.
=> 차이점 : Series 에서는 인덱싱하고 싶은 인덱스 값들을 직접 할당 가능하다.
- 아래처럼 우리가 원하는 인덱스들에 대해 인덱싱이 가능하다.

2. 라벨링된 인덱스 값들을 가지고 인덱싱도 가능하다.
아래처럼 라벨링된 인덱스 값을 가지고 슬라이싱을 해서 원하는 인덱스에 담긴 value 값들을 볼 수 있다.

또한 아래처럼 라벨링된 슬라이싱을 가지고 해당 인덱스들에 모두 원하는 값을 value 에 할당 가능하다.

출력해보면 b 와 c 인덱스의 value 값으로 5가 할당된 모습을 볼 수 있다.

DataFrame 에 대한 인덱싱
DataFrame 은 row, column 모두 인덱싱이 가능하다.
예를들어 아래처럼 DataFrame 을 구성했을때

컬럼에 대해 인덱싱하기 : 라벨링 값을 활용
각 컬럼에 대한 인덱싱이 가능하다. 라벨링 값을 인덱스로해서 인덱싱을 함

row 에 대해 인덱싱하기 : 정수로 인덱싱을 하자!
정수로 인덱싱 및 슬라이싱을 할 경우, 위에서 본 방법은 컬럼에 대한 인덱싱 방법이라면 정수로 인덱싱 하는 이 방법은 row 에 대해 인덱싱을 하는 방법이다.
아래와 같이 정수로 슬라이싱 하는경우를 보면, 0~1번쨰 row 를 출력하는 것이다.

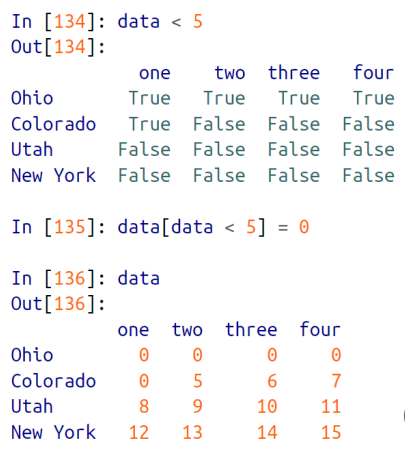
또한 Boolean 배열에 대한 인덱싱을 할때 조건문을 통해 해당 조건에 부합하는 row 들을 출력(인덱싱)할 수 있다.

그리고 DataFrame 자체에 대한 Boolean 인덱싱도 가능하다.
아래처럼 DataFrame 의 값 전체에 대한 Boolean 인덱싱한 결과를 볼 수 있다.
loc, iloc 속성 : DataFrame 의 row 에 대한 인덱싱
- loc : 우리가 할당한 라벨링 값으로 인덱싱 하는것
- iloc : 정수로 인덱싱 할 때 사용
- 정수로 인덱싱할떄는 iloc 을 안쓰고 그냥 인덱싱을 해도되지만, iloc 이라는 속성을 사용해서 하는것이 더 좋다.
- 정수로 인덱싱할떄는 iloc 을 안쓰고 그냥 인덱싱을 해도되지만, iloc 이라는 속성을 사용해서 하는것이 더 좋다.
=> 이 두 속성을 활용하면 row 와 column 모두 인덱싱이 가능하다.
아래 예제에서 [1,2] 는 행(row)에서 첫번째 라벨, 2번째 라벨을 의미한다. 그리고 [3,0,1] 는 컬럼에서 3번쨰, 0번째, 1번쨰 인덱스 라벨을 의미한다.

예제 전체그림

loc 과 iloc 을 통해 슬라이싱하기

아래처럼 iloc 으로 슬라이싱 한 결과 (data.iloc[:, :3]) 를 Boolean 인덱싱도 가능하다.

정수로 인덱싱하기
앞서 설명했듯이, 정수로 그냥 바로 인덱싱하는 방법보다 iloc 활용해 정수 인덱싱 하는 방법이 더 좋다고 했었다.
만일 그냥 정수 인덱싱을 하게되면, Pandas 에서는 인덱싱을 잘못 처리하는 경우가 간혹 발생하기 때문이다.
=> Pandas 에서는 정수 인덱스를 사용하는 것보다 일반적으로 라벨링된 특정 이름이 들어간 인덱스를 가지고 인덱싱 하는 방법이 좋다.
수식연산을 통해 데이터 정렬하기
Dataframe 의 2개의 데이터에 대한 산술연산을 했을때,
- 같은 인덱스끼리는 그냥 수식연산을 하고 리턴해주고,
- 다른 인덱스에 대해서는 none 값을 리턴해준다.
예를들어 아래처럼 s1, s2 가 있는데 몇개의 인덱스가 다르다. s1 에는 인덱스 d 가 있지만 s2에는 없고, s2 에는 인덱스 f 와 g가 있지만 s1 에는 없다.

s1+s2 와 같이 더하기 연산을 진행한 결과를 보면, s1과 s2에 둘다 존재하는 인덱스는 그냥 더하기 연산이 진행되었지만 겹치지 않는 인덱스는 none 값이 출력된 것을 볼 수 있다.
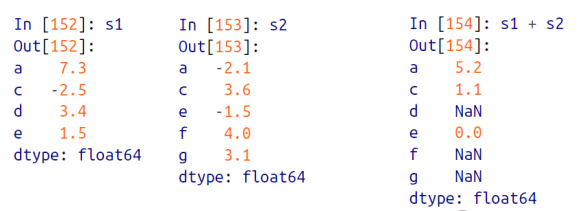
fill_value 옵션 : None값 처리하기
앞서 계속 말했지만, 두 DataFrame 간에 공통되는 인덱스가 아에 없더라도 일단 에러를 발생키지지 않고 연산을 진행해주며, 인덱스가 아예 겹치지 않는다면, 당연한 소리지만 모든 결과값이 None 이 출력될 것이다.
더하기 연산 진행시 발생하는 None 값 처리하기
아래를 보면 df1 과 d2 의 인덱스가 서로 A, B 로써 겹치는 인덱스가 아에없는데,
수식연산을 진행해주면 겹치는 인덱스가 없어서 전부 None 값으로 처리되는것을 볼 수 있다.

그렇다면 None 값들을 특정한 값으로 채워서 연산을 진행해주는 기능이 필요할것이다.
예를들어 아래처럼 DataFrame 2개를 만들고

고의로 일부러 df2의 1행 b열에다 None 값을 넣었고,

그러고 이 None 값을 어떻게 처리하는지 과정을 살펴보자.
만약에 두 DataFrame 에 대해 더하기 연산을 진행시 df1 + df2 와 같이 그냥 진행한다면 아래처럼 None 값이 발생할 것이다.

이를 처리하기 위해선 add 라는 함수와 fill_value 라는 옵션을 사용하면 된다.
이전에는 두 DataFrame 에 대해 더하기 연산을 진행시 df1 + df2 와 같이 했었는데,
그게 아니라 add 함수를 사용해서 더하기 연산을 하고, 그 안에 fill_value 옵션을 사용해서 None 값들이 0 으로 모두 치환되도록 해주면 된다.
그러면 None 값들이 0으로 치환되면서 df1 와 df2 에 대해 더하기 연산이 원활하게 진행 가능해진다.
아래 결과를 보듯이 기존에 1행 b열에는 그냥 더하기 연산을 하면 None 값이 저장되어있었는데, 0으로 치환해주니 5.0 이 저장된것을 볼 수 있다.

Reindexing 할떄 fill_value 옵션 활용하기
그리고 Reindexing 을 할때도 None 값이 발생했었는데, 이떄도 fill_value 옵션을 사용하면 된다.
DataFrame의 broadcasting 과 유사한 수식연산
broadcating 이 차원이 다른 배열들에 대해 연산을 가능하게 해주는 것처럼 비슷하게 진행된다.
=> Series 가 복사가되어서 DataFrame 의 크기에 맞춰서 연산이 진행되는 방식이다.
예를들어 아래처럼 frame, series 라는 이름의 객체를 생성하고,

출력을 한번 해보면 아래와 같으며,
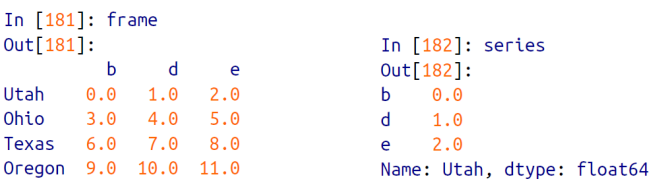
연산을 진행하면 아래와 같이 broadcastring 과 같은 연산이 진행됨을 알 수 있다.

DataFrame 와 Series 사이의 연산
보듯이, Dataframe 은 인덱스가 서로 매칭되지 않더라도 연산이 진행된다는 장점이 있다.
=> 만일 아래처럼 Series 안에 Dataframe 에 해당하는(매칭되는) 인덱스가 없다고 하더라도 산술연산을 했을떄 인덱스를 자동으로 추가해준다.
아래를 보면 DataFrame 에는 인덱스 f가 없는 상황이고, Series 입장에서는 인덱스 d가 없는 상황이다. 그래서 보듯이 수식연산 결과로 인덱스 d와 f에 None 값을 할당해준다.
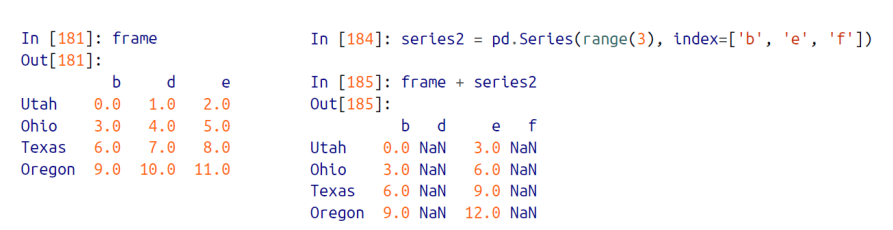
row 에 대한 broadcasting 유사 연산을 하고싶은 경우
앞서 살펴본 방법들은 컬럼(열)에 대한 유사 broadcasting 연산이였다. row 에 대해 연산을 진행하고 싶다면
- axis = 'index' 로 설정해주고,
- 산술 관련 함수(add, sub, ...) 등을 사용해서 row에 대한 연산을 진행해준다.
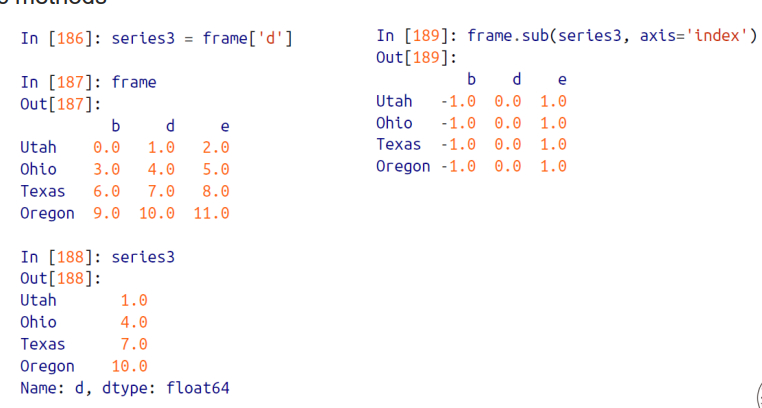
DataFrame에 적용가능한 함수들
- Numpy 의 ufuncs(universal function) 은 Pandas 에도 적용 가능하다.
- abs() 함수는 numpy 의 함수이지만 Pandas 의 DataFaame 객체에 대해서도 적용 가늘하다.

Sorting 과 Ranking 관련 함수들
sort(), sort_index()
- obj.sort() : 정렬하는 함수
- obj.sort_index() : row 또는 column 의 인덱스를 알파벳순으로 바꿔주는 함수
- 디폴트로는 row 에 대한 인덱스를 정렬시켜 줌
- 컬럼(열)에 대해 정렬시키고 싶다면 axis 옵션에 1을 부여하면 된다.


ascending 옵션에 False 를 부여하기 : 내림차순 정렬해줌
- ascending 을 번역하면 오름차순이다. 즉, False 를 부여하면 오름차순의 반대인 내림차순 정렬이된다.

sort_values() : value 값들을 정렬

by 옵션
- sorting 을 진행할떄 Series 는 상관없지만, DataFrame 은 by 라는 옵션을 통해 특정 컬럼에 대해서만 정렬을 진행할 수 있다.
frame.sort_values(by='a') : 컬럼 a에 대해서만 정렬을 진행한다.
frame.sort_values(by=['a','b']) : 컬럼 a에 대해 먼저 정렬해주고, 그 다음으로 동점인 데이터들에 대해서 컬럼 b에 대해 정렬을 진행해준다.

rank 함수
- 순위에 대한 점수를 매겨서 출력하는 함수
- 만약 총 7개의 그룹이 있다면 1등은 7점, 꼴등(7등)은 1점을 부여한다. 그리고 공동 순위에 대해서는 6.5점, 1.5점과 같은 순위를 부여한다.
예를들어 아래와 같은 Series 에 대해 rank 를 적용하면

아래와 같다. 이떄 0과 2에 대해서 6.5인것을 볼수있는데, 이는 데이터 7이 2개가 있다. 즉 1등이 2명이라는 말이다. 그러면 1등은 7점이고 2등은 6점인데 그들의 평균값을 내린 6.5를 넣은 것이다.
=> ex) 만일 공동 1등이 3명이라면 해당 3명에 대해 (7+6+5) / 3 = 6점을 부여한다.

DataFrame 에 rank 함수 적용하기
DataFrame 에 대해서도 rank 함수를 적용할 수 있다. 마찬가지로 row 와 column 각각에 대해 랭킹(순위)를 매길 수 있다.
axis = 'columns' 으로 적용하면 각 row 에 대한 랭킹을 매기는 것이다. 햇갈리지 말자!!!

