
본 포스트팅은 인하대학교 컴퓨터공학과 오픈소스 SW 개론 수업자료에 기반하고 있습니다. 개인적인 학습을 위한 정리여서 설명이 다소 미흡할 수 있으니, 간단히 참고하실 분들만 포스팅을 참고해주세요 😎
Feature
ML (머신러닝) 모델들은 Feature 라는 값들로 이루어진 데이터를 입력받는다. Feature 란, 데이터를 설명하는 각 속성을 의미하며, 사람이 아닌 기계가 충분히 이해할 수 있는 형식의 데이터 들을 의미한다.
=> ML들은 Feature로 표현된 데이터들을 통해 목적을 달성하도록 학습을 스스로 진행하는 방식이다.
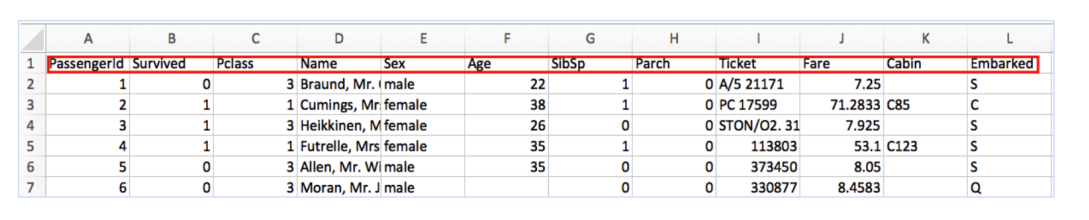
예를들어 아래처럼 인풋 데이터들을 넣어줘야지 ML 이 이해 가능하다. 각 컬럼(속성) 들 (Name, Age, Ticket 컬럼 등등) 이 바로 Featue 다.
Training and interface
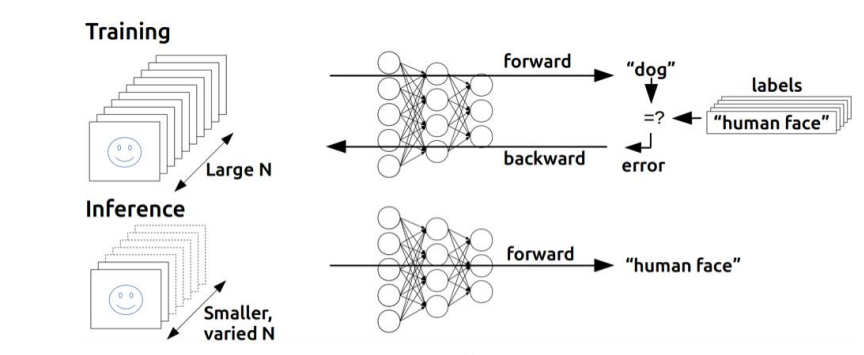
ML 은 크게 2가지 과정으로 나뉜다.
-
Training(학습 과정) : ML 모델에서 계속 파라미터 데이터를 주입해주면서, 답을 정확히 도출해내도록 훈련을 시키는 방식.
-
Interface(추론 과정) : 앞서 훈련된 모델을 기반으로 ML 이 알아서 보이지 않는 데이터 결과값을 예측 및 도출해내는 것 (Ex. 결과값으로 강아지임을 판별해내는 것)
=> Training 과정을 통해 ML에게 충분히 학습을 시켰다면, 이후 서비스로 출시하는 과정이 바로 Interface 과정이다. 즉 ML 이 충분히 학습한 이후 사람들이 원하는 데이터를 충분히 추론해서 결과값으로 리턴해주는 과정이다.
ML tasks
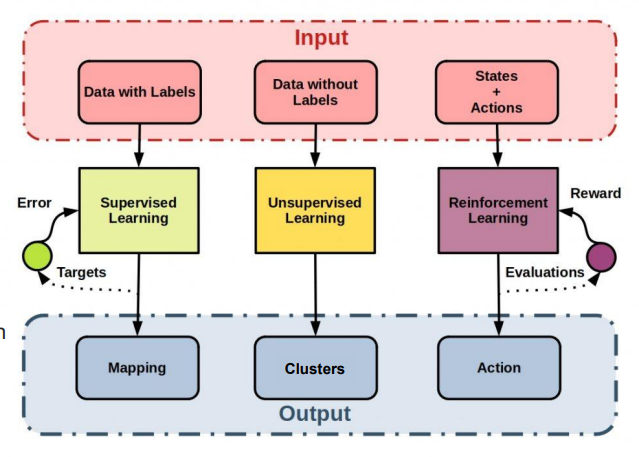
ML 의 Task는 크게 3가지로 분류된다.
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Label 이란?
Label : 각 데이터를 인풋으로 넣었을 때 도출되는 각 예측값( = 정답 = 결과값)
Supervised Learning (지도학습)
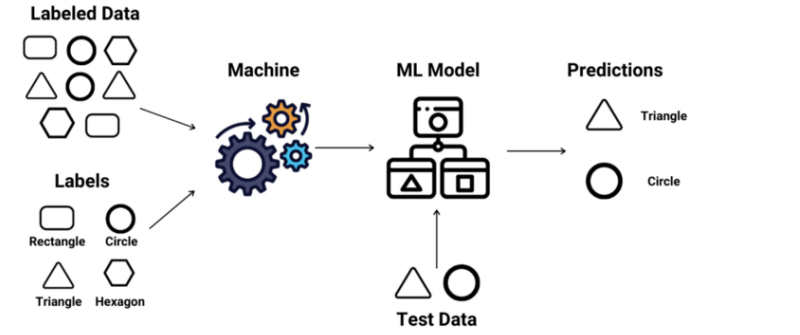
- 인풋 데이터와 예상되는 결과값인 Label 데이터를 기반으로(데이터를 기계에 주입해서) 학습을 진행하는 ML 모델
1) 위의 예시의 경우, 기계에다 데이터를 넣어서 학습시킬 때 그냥 삼각형 이미지 데이터(Labled Data) 를 넣어주면서 동시에 이건 삼각형이라는 타입(Label) 이라는거야! 라고 하며 Label 정보도 동시에 기계에다 인풋을 넣어준다.
2) 그러면서 ML model 은 이것이 삼각형인지, 동그라미인지, 사각형인지등의 결과값을 예측해서 도출해내는 것을 계속 학습한다.
3) 해당 ML model 이 도출해낸 결과값을 보고, 사람은 이것이 틀린것인지 맞은것인지 ML model 에게 알려준다. 그러면 ML model 은 계속 올바른 정답을 찾아내도록 계속 인간으로 부터 학습하게 된다.
4) 그래서, ML 은 주어진 인풋에 대해서 올바른 결과값(정답)을 도출해낼때까지 학습을 마쳤다면 해당 ML model은 서비스에 활용이 될 수 있는 것이다.
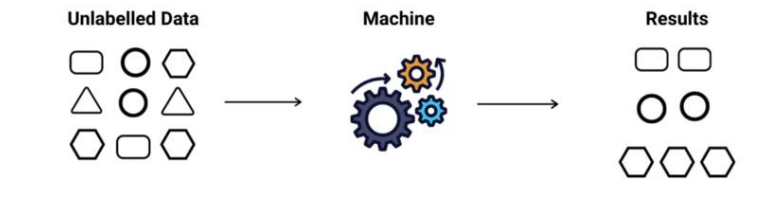
비지도학습 ( Unsupervised learning )
지도학습과 차이점을 비교해보면,
- 지도학습의 인풋 : 데이터 + Label + 학습목표(training objectives)
- 비지도학습의 인풋 : 데이터 + 학습목표
=> 이때 주의할점은, 비지도학습은 training objectives, 즉 학습목표도 인풋으로 받는다.
- 전형적인 비지도학습 방식은 dimensionality reduction 과 clustering 라는 과정을 포함한다.
Reinforcement learning (강화학습)
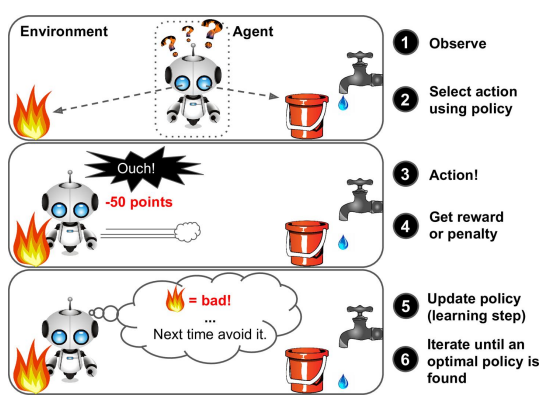
다양한 행동과 시행착오를 걲으면서 환경에 대해 경험(experience)를 쌓아나가면서 학습해 나가는 방식
Iris dataset : scikit-learn 으로 Classification(분류) 해보기
여러가지 dataset 중에서 Iris dataset 에 대해 Classification 을 진행해보자.
t Iris datase 특징
- 4가지의 feature 를 보유 => 꽃의 길이 4가지 (cm단위)
- 3가지의 클래스를 보유 (versicolor, setosa, virginica) => 꽃의 품종
아래처럼 실제로 있는 꽃 하나에 대해 길이를 특정해서 feature 화 시킨것이다. feature화된 정보 4자지 종류를 가지고 어떤 해당 꽃이 어떤 상세 품종인지를 맞춰보는 것이다.
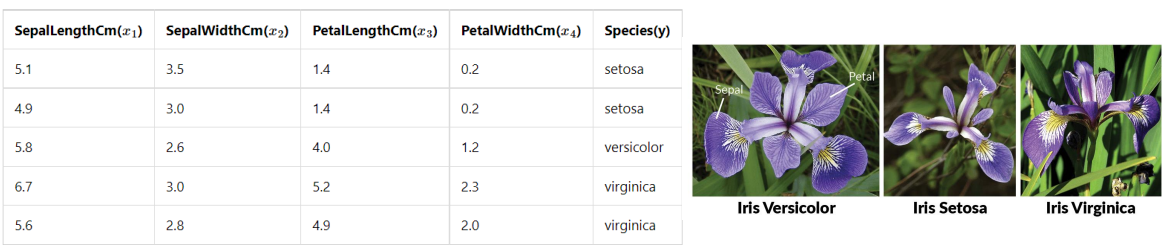
Iris dataset 관련 코드 설명

-
sklearn.datasets 에 정의되어 있고, load_iris 함수를 통해 datast 을 호출할 수 있다.
-
Iris dataset 을 포함해서 sklearn 에 있는 대부분의 ML 알고리즘들은 2차원 행렬의 형태를 지닌다. 이때 행렬의 행은 sample 데이터의 개수이고, 열은 feature 의 개수이다. 즉 "(sample 데이터 개수) x (feature 개수)" 의 행렬 형태를 보유하고 있다.
-
150개의 sample 꽃 데이터와 4가지 종류의 feature 를 보유하고 있다.
-
shape 함수 : 해당 dataset 의 행렬의 사이즈를 출력한다. (150, 4) 와 같이 출력한다. 즉, Iris dataset은 150행 4열짜리 크기를 가진 행렬이다.
Label 관련 내장함수 : target
해당 dataset 의 Lable 값을 조회하고 싶다면 target 함수를 사용하면 된다.
-
target : 해당 dataset 의 모든 각 데이터들이 속해있는 label 값을 숫자로 치환해서 싹다 출력하는 함수
=> 0이 출력되는 경우, 해당 데이터는 0번째 label 클래스에 대한 데이터임을 의미
-
target_names : 해당 dataset 의 label 종류를 모두 출력

fit 함수 : training 시켜주는 함수
dataset 을 가지고 ML model 을 만드는 방법 => fit 메소드를 호출하면 끝!
-
fit 함수 : 입력받은 파라미터 데이터를 적절히 변환시켜서 ML model 을 학습(training) 시켜주는 함수
- 지도학습의 경우, data 와 label 2개의 파라미터 데이터(인풋 값)로 넘겨줘야함
- 비지도학습의 경우, data 1개만 인풋으로 넘겨주면 된다.
predict 함수, dataset 의 행렬이 형태
- dataset 의 행렬의 형태 : ( sample 의 개수, feature 의 개수 )
=> 지도학습이든 비지도학습이든, 행렬의 형태로써 데이터가 저장할때 shape 함수로 출력을 해봤을 때 (150, 4) 와 같은 형태로써 저장이 됐을것이다.
즉, 앞서 말한 내용이지만 행렬의 행부분에는 sample 의 개수가, 행렬의 열 부분에는 feature 의 개수가 적절한 형태로 구현되어야 한다.
- prediect 함수 : ML model 에 인풋값을 넣으면 그에 대한 적절한 아웃풋을 생산해냄
fit 함수를 호출해서 ML 모델을 학습을 다 시키고 종료되고나서 ML 모델을 서비스에서 활용할때 predict 함수를 사용하면 입력한 데이터에 대한 아웃풋을 생성해준다. (ex. 인풋으로 고양이 사진주면, 이거 고양이 사진임~ 이라고 ML 모델이 리턴해줌 )
ex) output = classifer.predict(X_test)
전반적인 ML 의 processes 과정
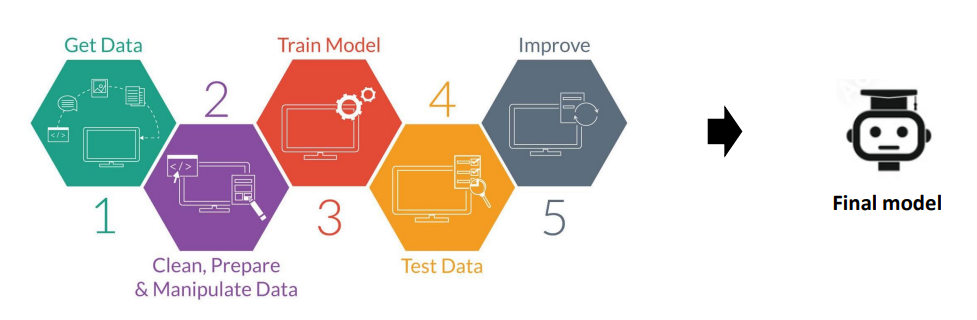
-
Get Data : 인간으로부터 데이터를 입력받는다.
-
Clean, Prepare, Manipulate Data : 학습할 데이터(Training Data) 와 성능 평가시 사용할 데이터(Test Data) 를 분류시킨다.
-
Train Model : 훈련시킴
-
Test Data : 학습이 완료된 ML 모델을 가지고 테스트를 해본다.
-
Improve : 더 향상된 ML 모델이 나오기전까지 1~3 사이의 과정들을 계속해서 반복한다.
-
Final Model : 향상 과정까지 마쳤다면 최종적인 ML model 이 생성된다.
Split the dataset
dataset 에 존재하는 데이터들에 대해 학습할 데이터(Training Data) 와 성능 평가시 사용할 데이터(Test Data) 를 분류시키는 과정을 Split the dataset 이라한다.
-
이떄 test dataset 은 외부에 유촐되서는 안된다. 만일 유출된 데이터는 dara leakage 라고 부른다.
-
두 dataset 은 비율 조정이 가능하며, 보통 training dataset 의 사이즈가 test dataset 의 사이즈보다 더 크다.
- test data 는 그냥 검증만 할때 쓰이는 데이터인데, 만일 test data 에 다 몰빵해버리면 학습시킬 training data 가 없어진다.
test 를 위한 함수
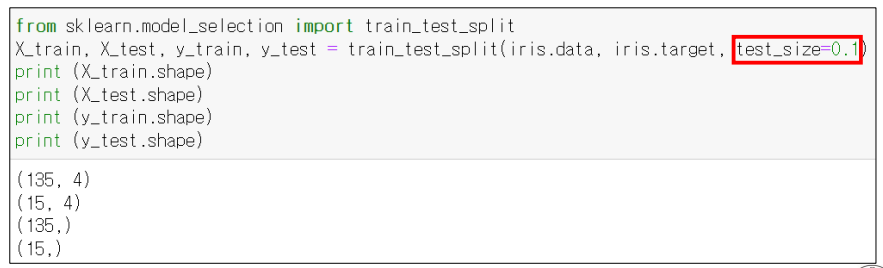
- train_test_split 함수 : Training Data 와 Test Data 로 데이터를 분류시켜주는 함수
- test_size : 전체 dataset 에서 Test Dataset 의 비율을 할당시켜주는 함수
- train_test_split 함수는 인풋에 대한 아웃풋 사이즈가 2배로 늘어서 도출된다. dataset 을 2 종류로 쪼개기 떄문!
그리고 train_test_split 함수는 아래와 같은 형태를 지닌다.

- test_size 함수는 Training Data 와 Test Data 사이의 비율을 조정해주는 것으로써, test_size = 0.1 을 할당한경우 test data 의 비율이 10% 이고, training data 의 비율의 90% 이다.
예시
StandardScaler 함수, Transformation 과정
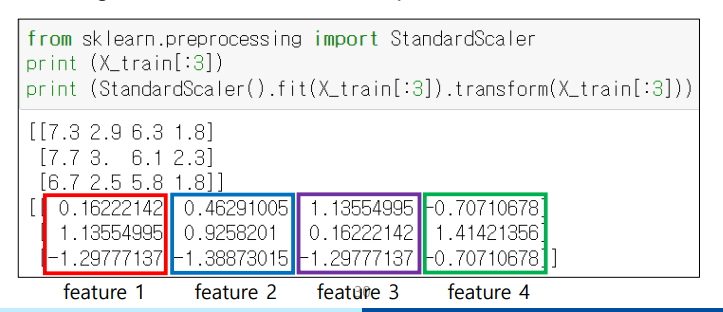
각 feature 들의 스케일 값이 많이 차이가 날수있다. 예를들어 어떤 dataset 의 feature1 의 data 들의 값들은 0.1, 0.3, 0.6 과 같은 값들인데, feature2 의 data 값들은 10000, 500백만 과 같이 차이가 심하면 ML 이 학습하기가 곤란해진다.
- 따라서 각 feature 들의 스케일을 맞춰주는 것이 필요하다. 이때 사용하는 함수이 StandardScaler 이다.
StandardScaler : 각 feature 들의 스케일을 맞춰줄 때 사용하는 함수
- 즉 dataset 을 split 하고 ML 에 값을 넣어주기전에 데이터를 변형시키는(스케일을 바꿔주는) 위와 같은 과정을 Transformation 이라고한다.
아래와 같은 식을 통해 스케일을 재조정한다.
z = (x - u) / sfit 메소드 + transform 메소드
- 그렇다면 StandardScaler 를 어떻게 사용할까?
StandardScaler 함수안의 fit 함수를 사용하고, 또 그 안의 transform 함수를 연달아서 사용해주면 된다.
아래처럼 4가지의 feature 들의 스케일이 얼추 비슷하게 맞추어진 모습을 확인할 수 있다.
pipeline
- 앞서 transform 과정까지 거치며 데이터를 변형을 다 했다면, 이제 당연히 ML 모델에 변형한 데이터를 넣어서 학습시켜주면 된다.
그런데 make_pipeline 함수를 사용해서 Pipeline 객체를 생성후, 이 객체로 Transformation 변형과정과 test 과정까지 모든 일련을 과정을 한번에 처리가 가능하다.

make_pipeline 의 파라미터로 원하는 순서대로 객체를 넣어주면 된다.
StandardScaler() 객체는 직전에 살펴봤듯이 Transformation 를 해주는 함수이고, RandomForsetClassifier() 객체는 분류 ML 모델중에 하나다.
pipe 객체의 fit 함수

- 그냥 fit 함수를 호출하는 것과 동일하다.
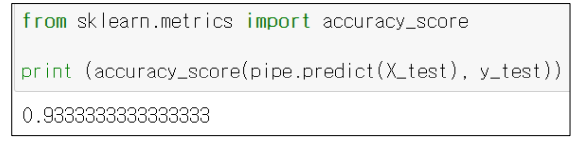
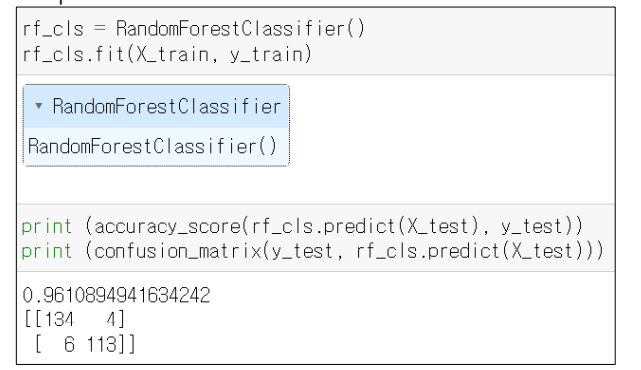
accuracy_score, pipe 객체의 predict 함수
굉장히 다양한 유형에서의 성능을 평가할 지표가 나올 수 있는데(ex. 속도 빠르기, 꽃의 길이 등), 이번에는 대표적인 지표중 하나인 "정확도"로 성능을 평가해보겠다.
- accuracy_score : 정확도를 계산해주는 함수
- 정확도 : 맟춘개수 / 전체개수 (전체중에서 몇개를 맞추었는가)
- 선언형태 : accuracy_score(예측값, label값)
Confusion matrix
- 혼동 행렬 : 전체 prediection 이 얼마나 맞았는지(정답인지를) 형렬 형태로 눈에 보기좋게 표현한 것
- 한 축은 label 수치로, 한 축은 prediect (얼마나 맞았는지)를 표현한다.
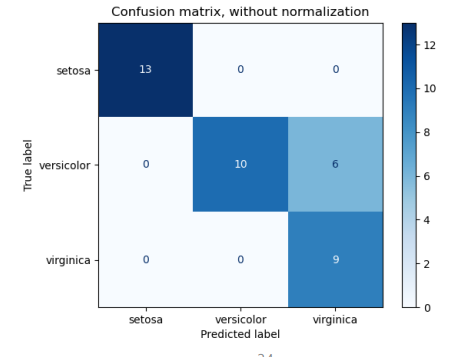
confusion_matrix 함수
- 형태 : confusion_matrix(label 값, prediect 값)

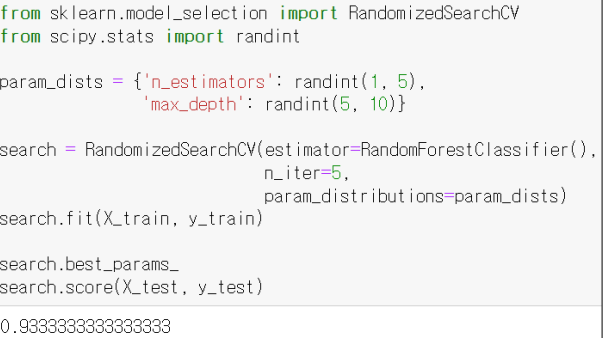
hyperparameters, randomized search
성능에 영향을 주는 값이면서 ML이 스스로 학습할 수 없는 값으로써, 사람이 직접 값을 지정해줘야하는 값들을 hyperparameters 라고한다.
분명 파라미터인데 스스로 학습이 안되고 우리가 직접 데이터를 넣어줘야함
이러한 hyperparameters 는 실험을 반복해서 지정값을 직접 찾을 수 밖에 없다. 그리고 이 과정을 조금 더 편하게 찾을 수 있도록 도와주는 기능이 sckit-learn 에 있다.
-> hyperparameters 를 찾는 방식은 여러가지가 있는데, 그 중 가장 쉬운 방법은 바로 randomized search 방법이다.
randomized search
- 특정 범위를 지정해주고 찾게하도록 하는 방식
옵션2가지
- n_estimators
- max_depth
RandomizedSearchCV 함수 : 주어진 범위 내에서 Random 하게 값을 하나 뽑아서 지정된 횟수만큼만 시도해보는 함수
RandomizedSearchCV 함수를 호출하면 max_depth 에 지정된 구간안에서 RandomForestClassifier 에게 학습을 시킨다.
n_iter 는 총 반복횟수이다.
Data 의 종류(Category) 2가지
- Structured Data (정형 데이터) : table 형태로써 표현될 수 있는 데이터
ex) 타임라인 데이터 - UnStructured Data (비정형 데이터) : table 형태로써 표현될 수 없는 데이터
ex) 이미지, 비디오, 도큐먼트, 오디오 등등
custom dataset
- ML 알고리즘은 structured data 를 분석하는데 좋다. 즉 테이블 형태의 데이터를 분석하는데 좋은데 이떄 pandas 를 활용한다.
csv파일의 데이터를 pandas를 활용해서 가져오기

- 13개의 feature (열)이 있는데, 이중에서 2~6열의 데이터만 추출하고 싶다면 data_df[2:6] 과 같이 하면된다.
groupby 메소드
- groupby 메소드를 통해 특정 컬럼(열)의 값들을 기준으로 그룹화를 시킬 수 있다.
아래 예제는 target 컬럼(label)의 사이즈를 계산한것이다.

데이터 Split 하기
앞서 배웠던 train_test_split 방식과 동일하게 진행하면된다.

Decision Tree
- 결정사항들을 가지고 이진트리 형태로 계속 갈림길에서 나뉘는 형태
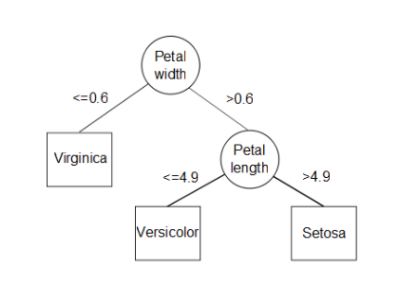
에제

Random Forest
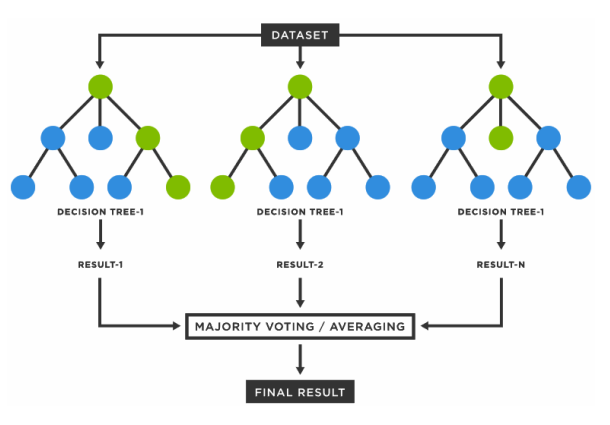
- decision tree 여러개가 모인 형태
- 여러개의 decision tree 중에 일부 몇개 트리를 랜덤하게 추출해서 본다.
Support Vector Machine (SVM)
두 클래스(feature) 를 재일 뚜렷하기 잘 구분할 구분선을 어떻게 그을 수 있을지에대해 학습하는 ML 모델
-
SVM 은 스케일의 영향을 많이받는다. 각 feature 들의 스케일 차이에 따라서 성능이 많이 차이난다. 따라서 SVM 을 사용할때는 스케일을 꼭 맞춰주자!
-
support vector : 구분선에 가장 가까이에 있는 데이터의 포인트 위치

Regression (회귀)
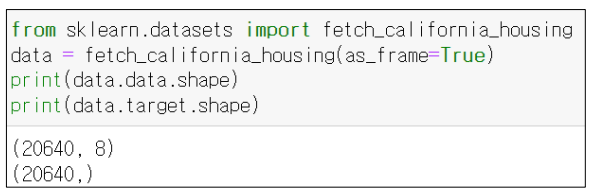

scikit-learn 의 비지도학습
비지도학습 방법
은 아래와 같았다.
- 데이터준비
- DataLabelSplit
- TrainTestSplit
- 모델 객체 생성
- Pipe or SVM
- fit
- predict
인풋 데이터
그리고 앞서 배웠듯이 지도학습은 data 와 label 모두 필요했지만, 비지도학습은 data 만 있으면 된다.
비지도학습의 종류
Clustering
비슷한 데이터끼리 모아서 ML 알고리즘이 알아서 특정 그룹으로 그룹화 시키는 것
이떄 그룹을 cluster 라고 부른다.
k-means
- clsutering 알고리즘의 대표 예시 : K-means
- 처음에는 아무 Label 이 없는 상태에서 원하는 cluster(그룹) 개수만큼 미리 지정해주고, 그만큼(k개 만큼) 그룹화시키는 방법
Dimensionality reduction(차원 축소)
대량의 feature 를 새로운 소량의 feature 들로 재구성 하는것 (ex. feature 1000개가 있는경우 새로운 타입의 feature 5개로 만든다)
예제
- make_blob : 인위적으로 다양한 데이터를 형성하는 것
ceners 옶션으로 cluster 를 3개 만든다는 것을 지정하고, cluster_std = 0.5 를 통해 하나의 cluster 에서 standard division 이 0.5 정도로 나오게 해서 점을 찍는것이다. 즉 한 cluster 당 점을 50개씩 나오게 해서 총 3개의 clsuter 를 형성
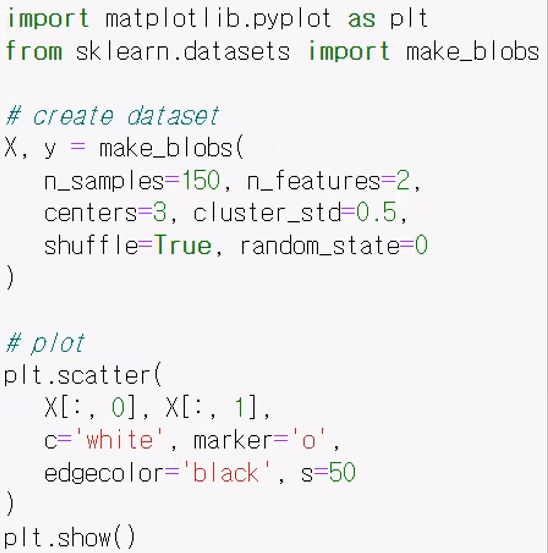
위처럼 데이터틀 생성했다면 아래처럼 모델 객체를 생성하고 fit 을 해준다.
이떄 모델 객체를 생성시 옵션 n_clusters 는 k 를 의미한다.

마지막 과정인 결과확인, 즉 predict 과정은 predict 함수를 활용하면 된다.

각각의 데이터들이 어떤 인덱스값을 가지는 cluster 에 해당하는지를 인덱스 번호들을 array 로써 출력한다.
( cluster 가 3개이므로 인덱스 값이 0,1,2 중에 하나일 것이다. )
- 그리고 k means 학습후에 각 cluster 의 중심점인 centroids 는 cluster_centers 로 확인할 수 있다.
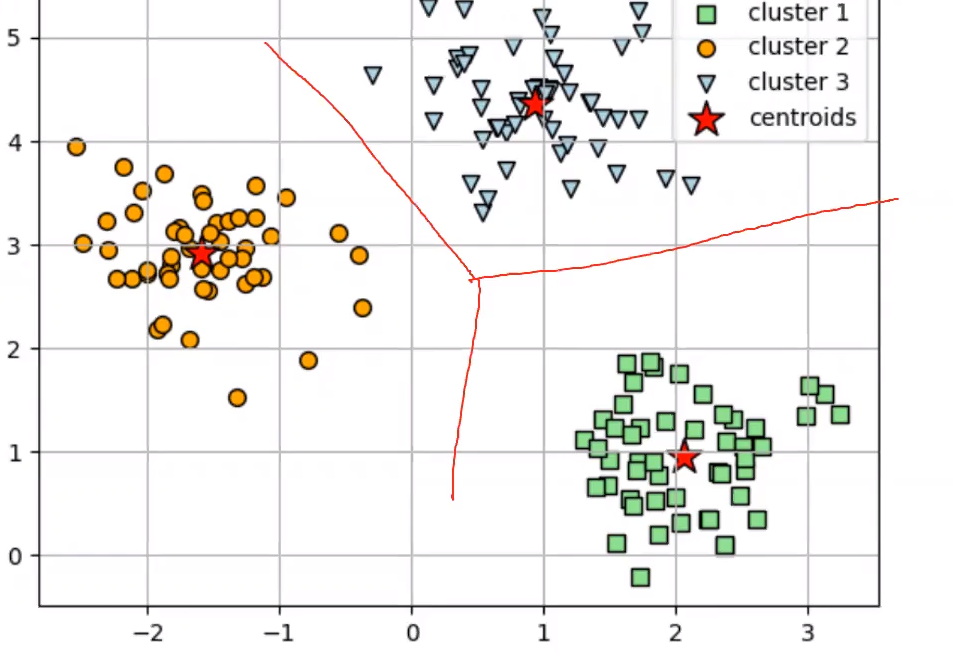
결과
