1. 2주차 내용의 연습 및 복습 again
1-1) 2주차에 했었던 스파르피디아에 movie openAPI를 사용하여 좀 더 그럴싸한 페이지를 구성해보자
- 페이지 로딩시에 해당 API의 영화 관련 정보들을 바로 가져오기
- 영화제목/이미지/설명/코멘트/별점 등을 카드의 형태로 담아 화면에 띄워주기
- 초기값으로 주어졌던 카드박스들 없애기
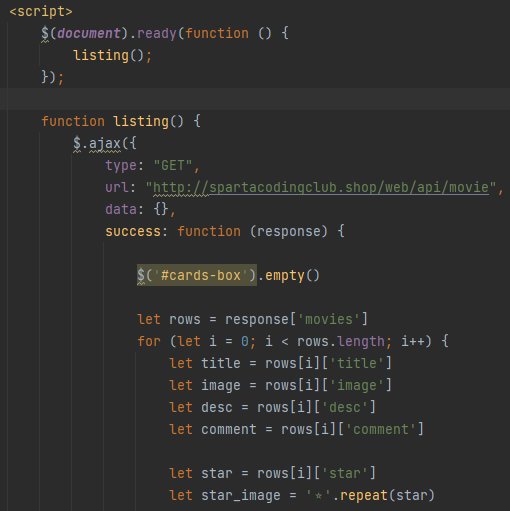
#반복숙달을 위한 작업이라 별도의 설명은 필요치 않겠지만, 별점부분은 단순히 숫자로 적히는 것 보다는 별 이미지가 별점 갯수만큼 달리게 하는 것이 개발 관행(?) 이므로 이를 유념해서 구현한다
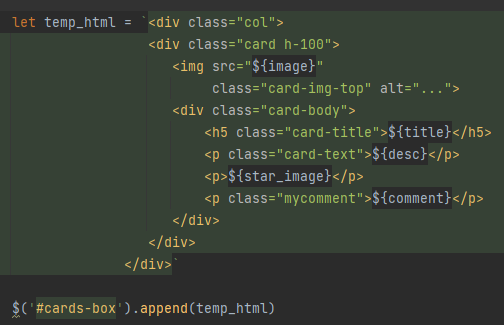
1-2) API + Ajax를 통해 호출 및 정의해 놓은 정보들을 만들어 놓았던 카드의 형태로 담아 cards-box에 붙여준다
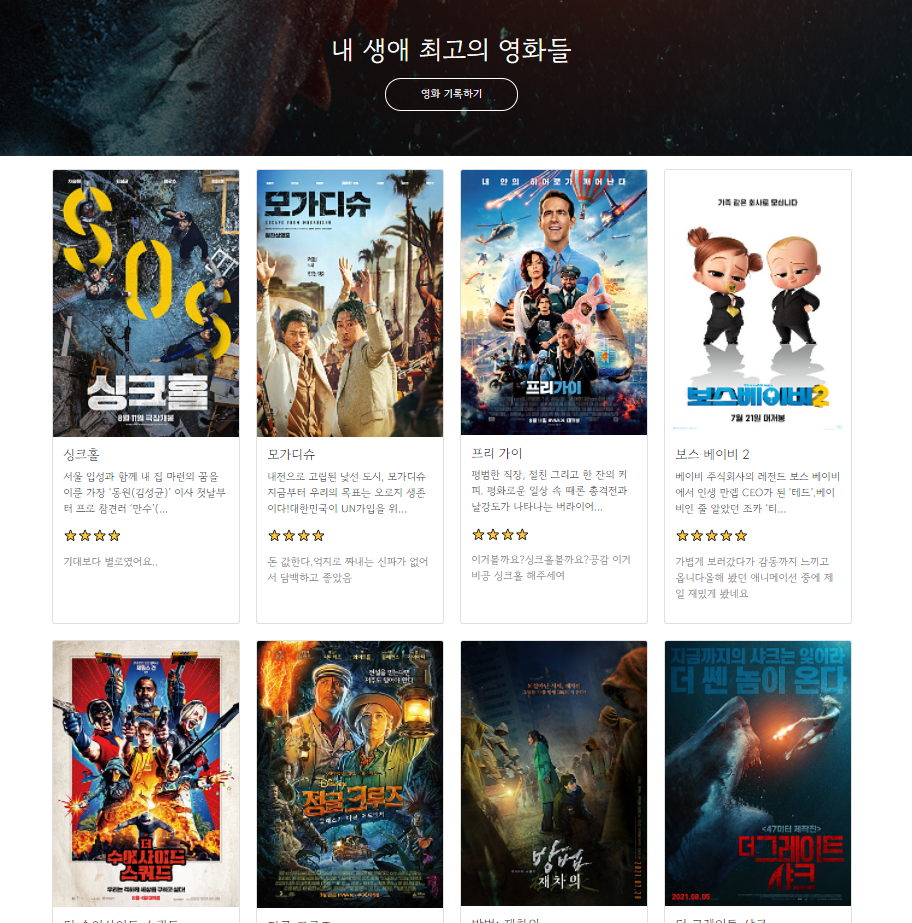
1-3) 결과를 확인하고 오류 여부나 수정할 것들을 체크해 본다
2. 파이썬 패키지 사용해보기(requests)
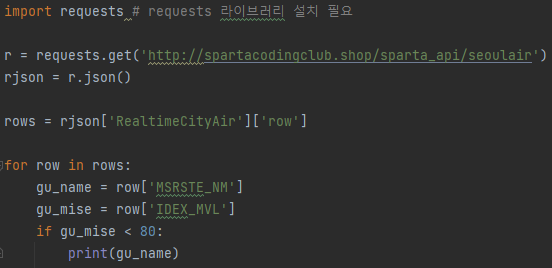
-
요청에 사용된 API는 이전에 다뤄본적 있던 서울시 미세먼지 데이터이다
-
선언된 변수들과 데이터 인덱스등을 미뤄 볼 때 이것이 무엇을 뜻하는 코드인지 알 수 있을 것이다
-
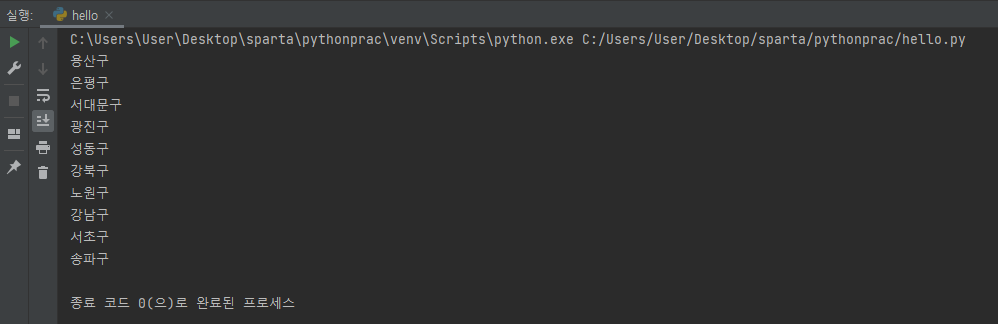
이 글을 작성하는 시각 기준으로는 저번보다 미세먼지 수치가 올라 간듯 하여, 이번엔 미세먼지 수치 80 미만인 지역명을 출력하도록 해보았다. 결과는 다음과 같다
-
전과 같이 html 상에서의 ajax 요청을 통해서도 같은 알고리즘을 구현할 수 있었지만, 비교해 보면 훨씬 더 직관적이고 간편한 형태로 사용이 가능함을 알 수 있다
-
이를 통해 데이터영역(API나 DB와 같은)과 이를 요청하는 함수(라이브러리 / 주로 app.py나 data.py에 저장되는), 결과값을 화면에 구성해주는 프론트 영역(html/css/javascript) 등을 구분하고 나눠서 사용/관리하는 것이 더 편하고 효율적이지 않을까 추측해 볼 수 있었다
3. 웹 스크래핑(크롤링) 기초
3-1) 외부에서 open되어있는 데이터를 가져올 때, 내가 원하는 타겟 데이터를 좀 더 쉽게 선별할 수 있도록 도와주는 Beautiful Soup 패키지를 사용해 보자
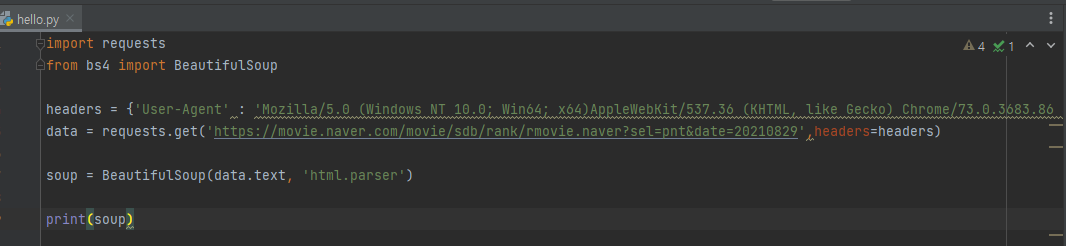
- BeautifulSoup을 import한 다음 해당 내용을 default로 놓고 시작한다
- data부분은 가져올(requests.get) 데이터 url을 의미하는 것일테고 그럼 headers는??
-> 우리가 코드를 통해 내리는 명령이 터미널이 아니라 마치 브라우저에서 요청하는 것처럼 속여주는 도구를 의미한다고 한다 (음... 반응성 향상을 위해서인가?...) - 갑자기 궁금해서 headers 부분을 일괄 삭제하고 돌려봤는데 url 데이터는 똑같이 잘 나온다(...)
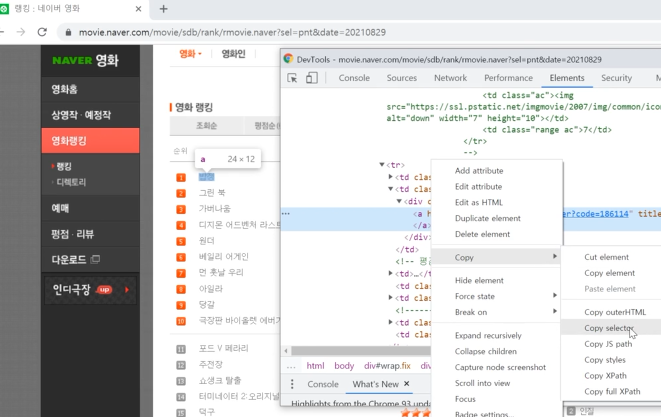
3-2) 원하는 영화의 제목(target title)을 선별하기 위해 해당 url 페이지 개발자 도구를 통해 copy selector을 선택한다
3-3) soup.select_one 메서드를 사용하여 해당 영화 제목만 출력해보자
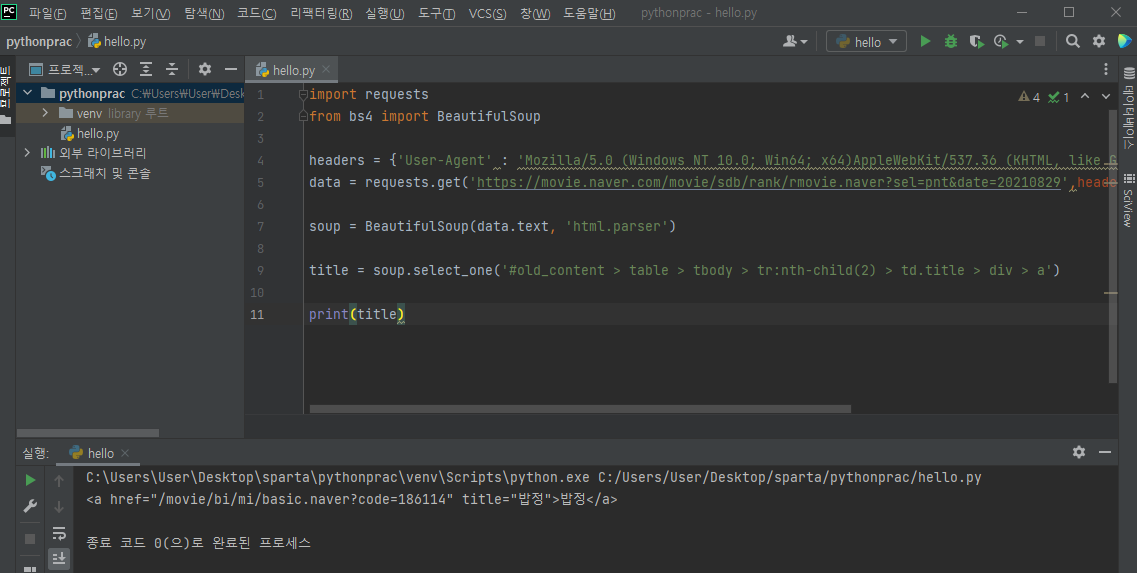
- 영화 제목을 담고있는 영역의 코드가 전체적으로 출력됨을 확인할 수 있다
- 여기서 '밥정'이라는 이름만 빼내고 싶다면 print(title.text)를 통해 텍스트만을 출력해 주면 된다
3-4) copy selector로 가져온 저 path들은 어떤 것을 의미하는 것일까?

- 2위 그린 북과 3위 가버나움에 대해서 똑같이 copy selector로 코드를 가져왔을 때의 결과이다
- 밥정에 관한 코드를 가져왔을 때와 마찬가지로 #old_content > table > tbody > tr: 까지의 경로가 똑같이 지정되어있음을 확인할 수 있었다(결국 각 영화를 분간하는 선택자는 tr 이후 부분이라는 얘기)
3-5) 일단 공통 부분까지의 선택자가 어떤 형태를 띄고 있는지 확인해 보자
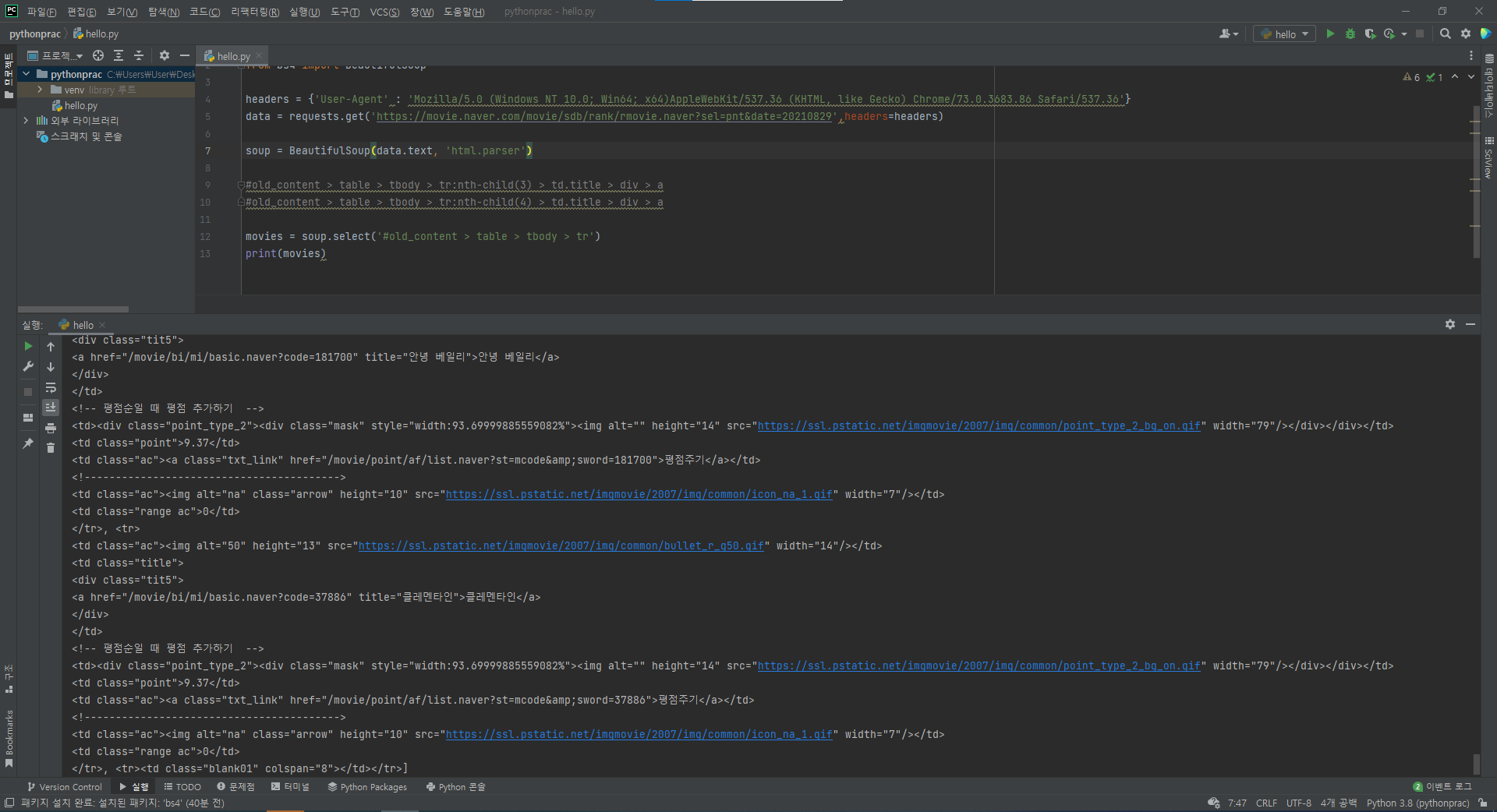
- 해당부분을 직접 print로 찍어보면 해당 영역의 데이터들은 전부 순위권에 올라온 영화들로 이루어진 리스트 형태였음을 알 수 있었다.
- 이를 통해 우리는 반복문을 통해 해당 리스트안에서 우리에게 필요한 몇가지 데이터(순위/제목/평점)만을 골라 가져오면 된다는 결론에 도달할 수 있다
3-6) 우선 순위대로 각 영화의 제목들만 나오게끔 출력해 보자
- 공통 경로였던 tr까지는 이미 movies에 담아 놓은 상태이다
- nth-child(n)은 상위 요소였던 tr에 대한 자식 요소에 대한 선택자, 즉 몇번 째 tr인지(몇번 째 영화인지)를 나타내 주는 것이므로 반복문을 통해(자동으로) 표현된다
- 그렇다면 반복문을 돌면서 남은 경로인 td.title > div > a 만을 출력해주기만 하면 된다
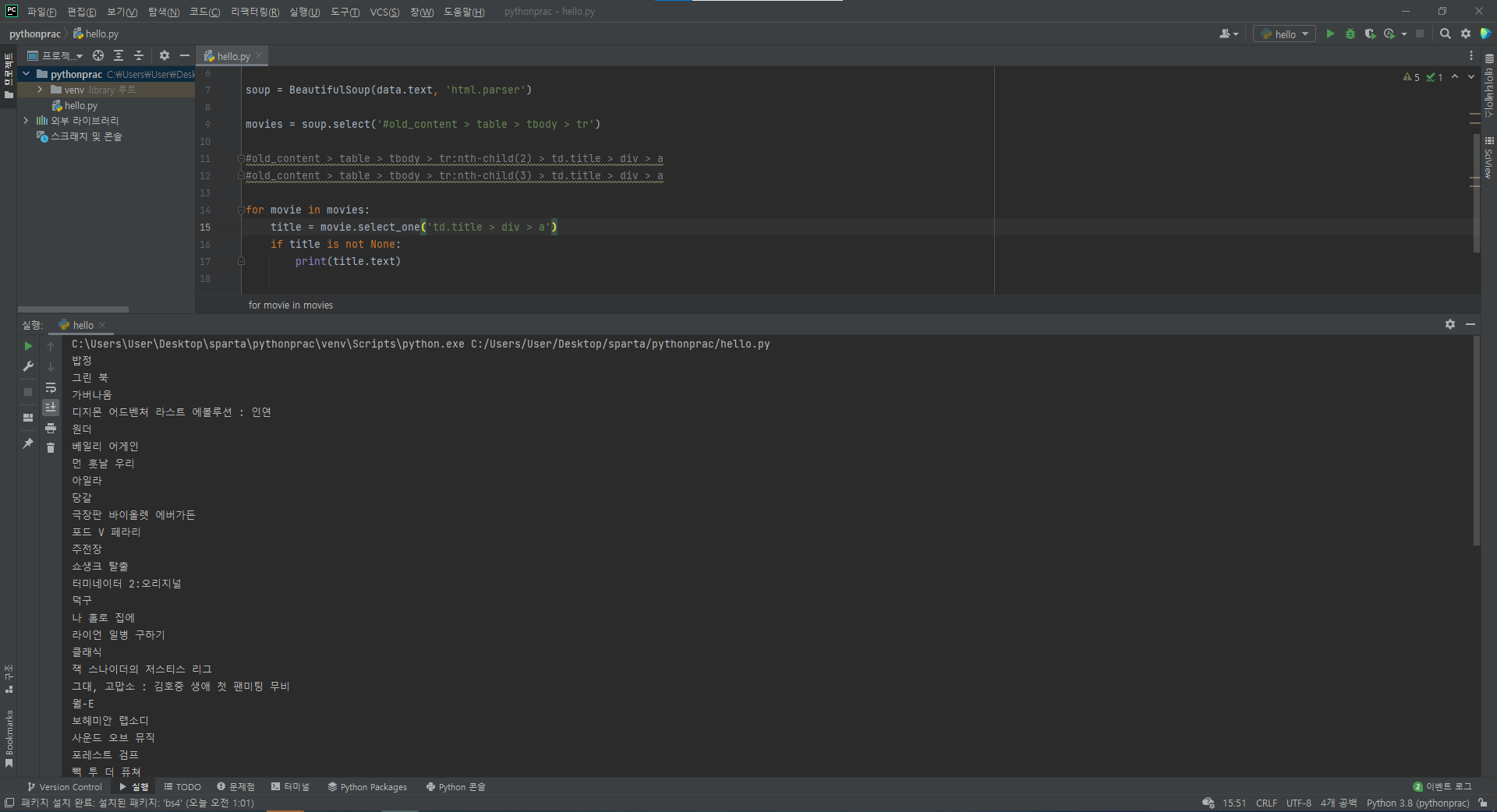
#if title is not None: 을 조건부로 필터링 한 것은 해당 url페이지에서 순위 10계단마다 사이에 넣어둔 공백란을 제외하고 출력하기 위한 방편이다
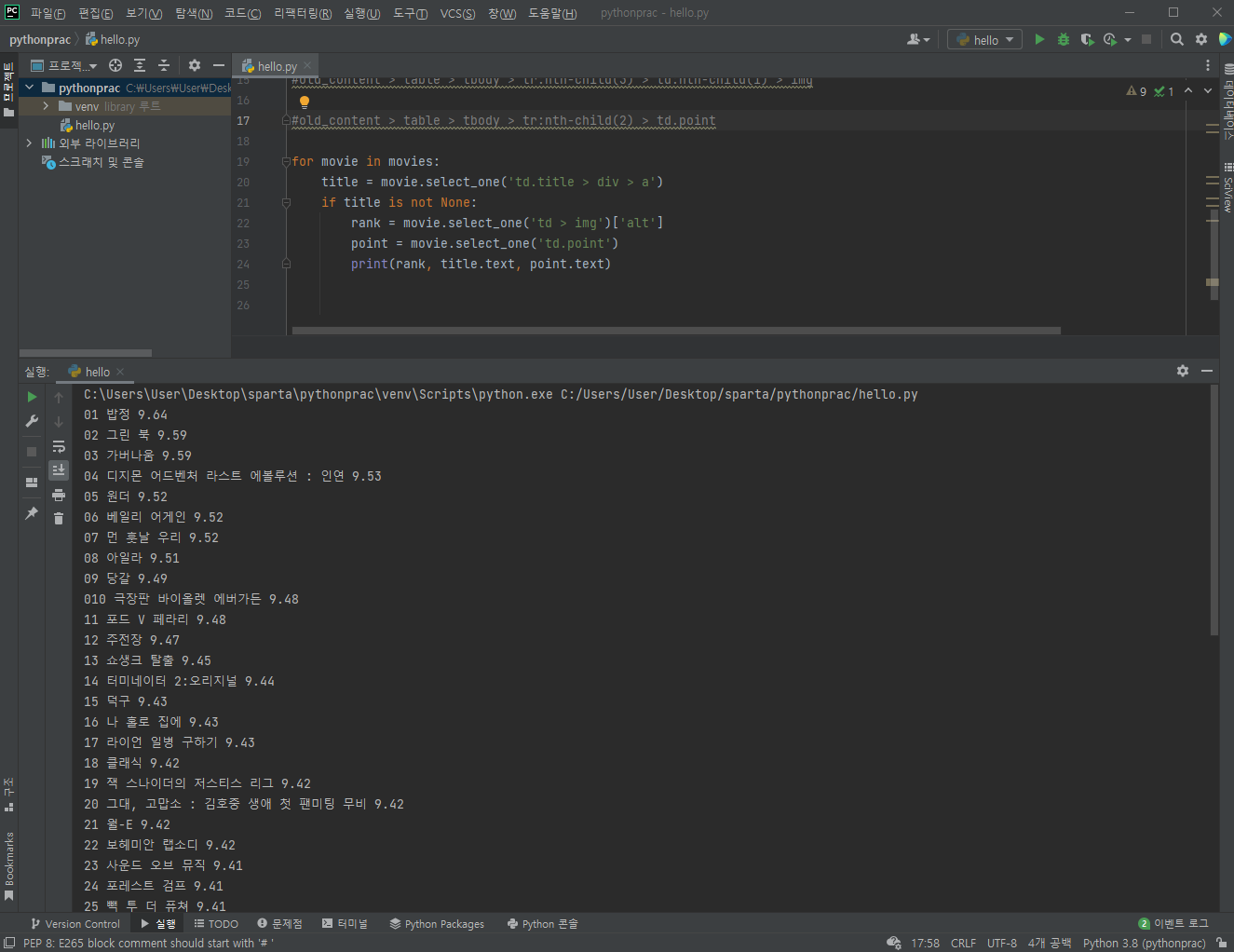
3-7) 이제 순위와 평점도 함께 출력할 수 있도록 한다
- 한 가지 유의해야 할 점은 단순히 td.point에 담긴 text만을 출력하면 되는 평점과는 달리, 순위 섹션에서는 해당 코드 안의 'alt'로 표기된 부분을 타겟으로 지정해줘야 한다는 점이다
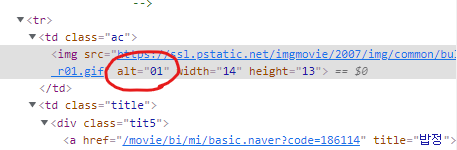
- 변수 rank를 선언할때 한번에 지정해 줘도 좋고, 최종 출력시에 rank['alt']를 해주어도 좋다
#몇번정도 반복을 해보면서 느낀점... 크롤링 할 때에는 코드작성도 물론 유의해야 하겠지만 무엇보다도 이 소스를 작성한 사람이 어떤 구조로 틀을 만들었는지 더 집중해서 관찰해야 한다는 것이었다.
#언젠가 나도 오픈소스를 개발해 공익적인 활동을 하고자 할 때가 올텐데..(너무 먼 얘긴가 ㅎ,ㅎ;;) 다른사람들이 좀더 쉽고 간편하게 소스를 가져갈 수 있게 하려면 훨씬 더 많이 공부하고 클린코드에 대해서도 공부해야겠구나... 라는 쓸데없는 생각도 해보게 되었다 ^_^........
