
9/30 6세션
A. 시계열 데이터란
- 데이터 분석 단위(행) 간에 시간 순서가 있는 데이터
- 행 간 간격이 동일해아 함
- 비즈니스 이해 단계에서 시계열 데이터인지 판단
- 행과 행 사이에는 관계 없는 건 디폴트
A-1. 기존 데이터 분석의 한계
시계열-단변량 숫자형
- 히스토그램으로 나타내면 구간으로만 나와서 정확하지 않다
시계열-단변량 범주형
- 막대그래프, 비율을 나타내는 파이 차트는 딱히 볼 게 없다
시계열-이변량 숫자&숫자
- 종가 그래프 등의 경우 산점도로 나타내면 완전 선형관계로 나온다
- 너무 당연한 가설이다
B. 시계열 데이터 분석
시간의 흐름에 따른 패턴 찾기!
B-1. 시각화
- 라인 차트 사용
sns.lineplot(x, y, data)- 축을 달리하자
# 축을 양쪽에 두고 그립시다.
plt.figure(figsize = (12,5))
# 왼쪽 축
ax1 = sns.lineplot(x = 'Date', y = 'Close', data = kospi, label = 'Close', color = 'blue', linewidth = .5)
plt.legend(loc='upper left')
# 오른쪽 축 생성
ax2 = ax1.twinx()
sns.lineplot(x = 'Date', y = 'Volume_Lag', data = kospi, label = 'Volume', color = 'green', linewidth = .5)
plt.legend(loc='upper right')
# 그래프 출력
plt.show()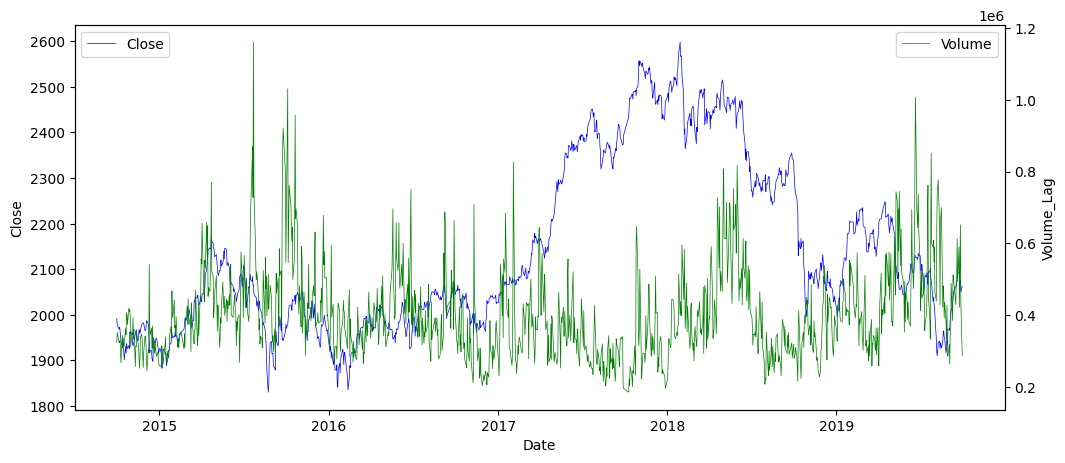
B-2. 시계열 데이터 분해 (Decomposition)
- 시계열 데이터 안에 있는
반복 추세와반복 패턴(주기)을 찾아내는 과정 - 찾아낸 패턴을 하나의 모델로 볼 수 있음
- statsmodels.api 의
sm.tsa.seasonal_decompose()사용 period매개변수로 분해 방법 설정
- Original (원본)
- Trend (추세) : period로 설정한 주기의 이동 평균 계산
- Seasonal (반복 주기) : 원본에서 Trend 를 빼고, 동일 주기의 데이터 평균으로 계산
- Residual (잔차)
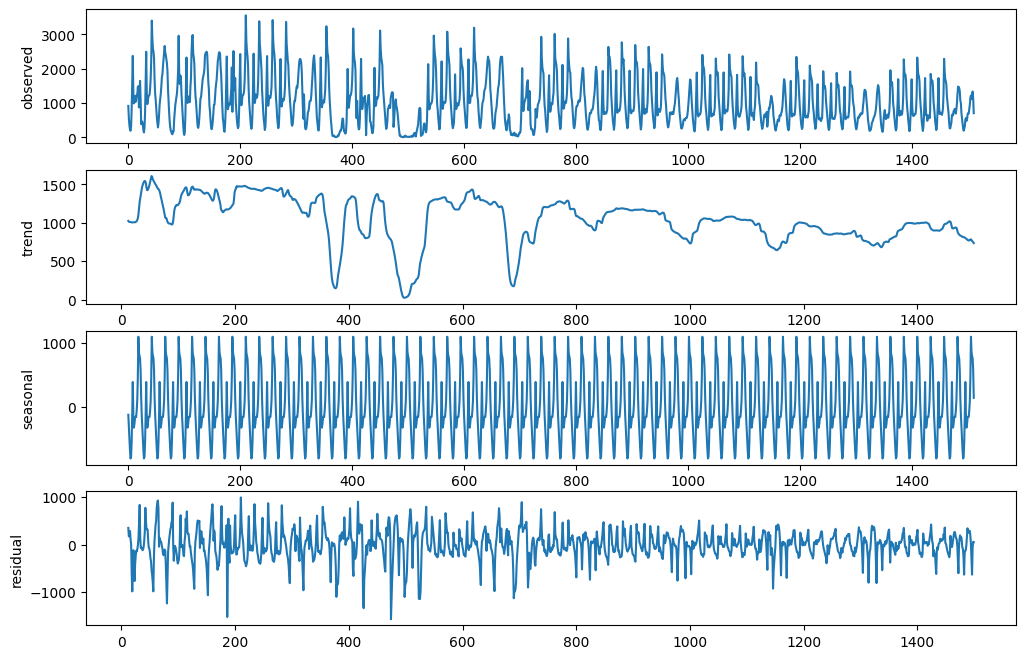
B-3. 시간 흐름을 feature 로 담기
diff() : 차분
특정 시점의 데이터와 이전 시점의 데이터 차이 구하기 (변화량)
shift
rolling
C. 데이터 변화량
- 시리즈에 diff() 사용
> nums = [10, 12, 16, 23, 20, 15, 16, 21, 20, 25, 18]
> nums_diff = pd.Series(nums).diff()
0 NaN
1 2.0
2 4.0
3 7.0
4 -3.0
5 -5.0
6 1.0
7 5.0
8 -1.0
9 5.0
10 -7.0D. 상관분석
D-1. 자기 상관 분석
- 시계열 데이터 내에서 한 시점의 값이 이전 시점 n과 어떤 관계인지를 측정하는 방법
- shift 를 수행해서 이전 시점 데이터를 가지고 있는 새로운 컬럼을 만들어야 함
# 지연 속성 50개 추가
for x in range(1, 51):
temp[f'Count_Lag_{x}'] = temp['Count'].shift(x)
temp.dropna(inplace=True)
또는
# 자기상관함수 모듈
from statsmodels.graphics.tsaplots import plot_acf
# 자기상관 분석 시각화
fig, ax = plt.subplots(figsize=(12, 3))
plot_acf(data['Count'], lags=50, alpha=0.05, ax=ax)
plt.show()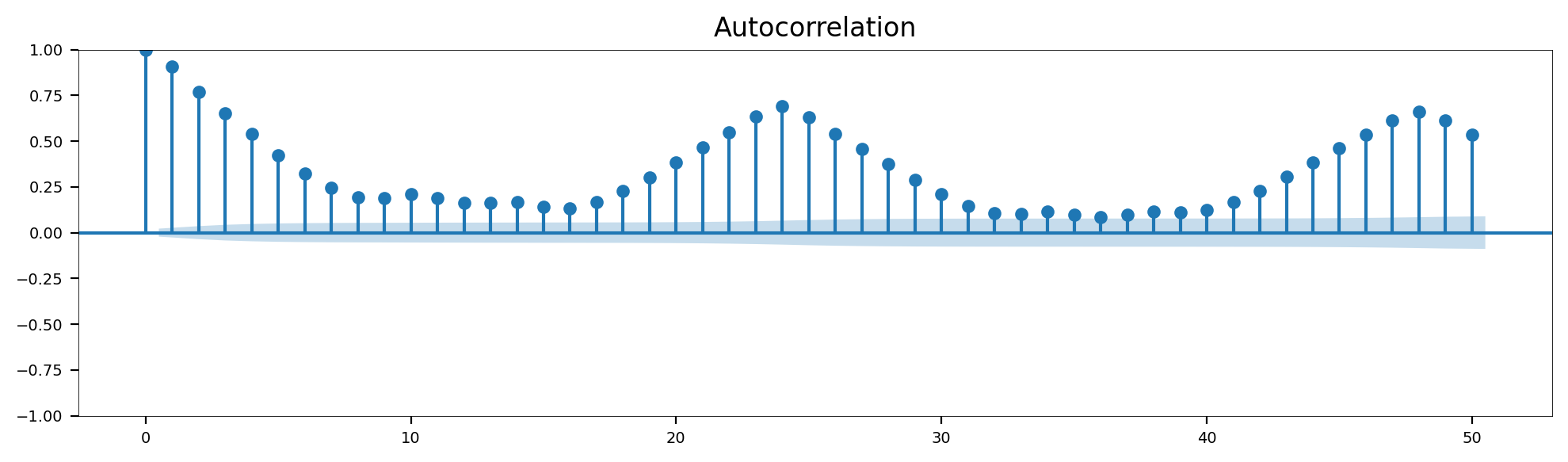
D-2. 교차 상관 분석
- 두 시계열 데이터 집합 사이의 상관관계
# 모듈 불러오기
from statsmodels.tsa.stattools import ccf
# 교차 상관 계수 계산
ccf_values = ccf(data['Count'], data['Temperature'])[:50]
# 시각화
plt.figure(figsize=(12, 3))
plt.bar(range(50), ccf_values)
plt.title('Cross-Correlation(Count, Temperature)', size=12, pad=10)
plt.show()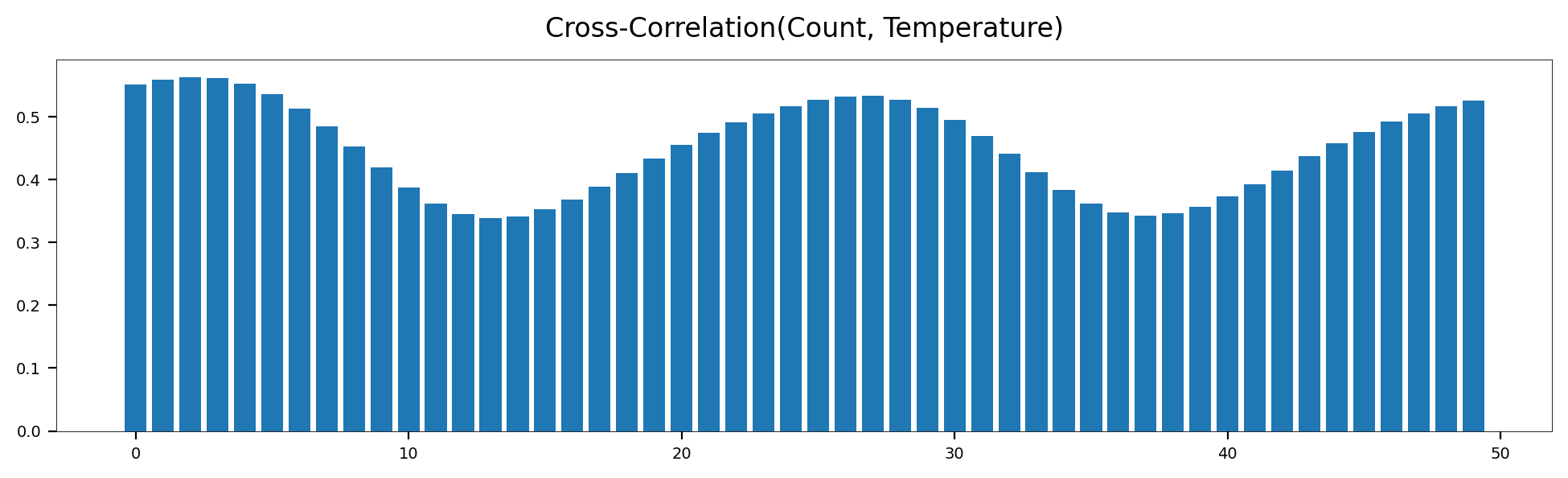
E. 시계열 데이터 가변수화
- 카테고리 형으로 변환
- 카테고리 형은 sorting 도 리스트의 순서로 됨
# 가변수화
seasons = ['Spring', 'Summer', 'Autumn','Winter']
weekday = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
holiday = ['No Holiday', 'Holiday']
x['Seasons'] = pd.Categorical(x['Seasons'], categories=seasons)
x['Weekday'] = pd.Categorical(x['Weekday'], categories=weekday)
x['Holiday'] = pd.Categorical(x['Holiday'], categories=holiday)
x = pd.get_dummies(x, drop_first=True, dtype=int)