
9/25 5세션
A. 숫자형 변수 분석
A-1. 정보의 대표값
평균(mean)
산술평균, 기하평균, 조화평균
# 넘파이 사용
np.mean(titanic['Fare'])
# 판다스 사용
titanic['Fare'].mean()중앙값(median)
자료의 순서 상 가운데 위치한 값
# 넘파이 사용
np.median(titanic['Fare'])
# 판다스 사용
titanic['Fare'].median()최빈값(mode)
가장 빈번한 값
# 판다스 사용
titanic['Pclass'].mode()사분위수(quantity)
air['Ozone'].describe()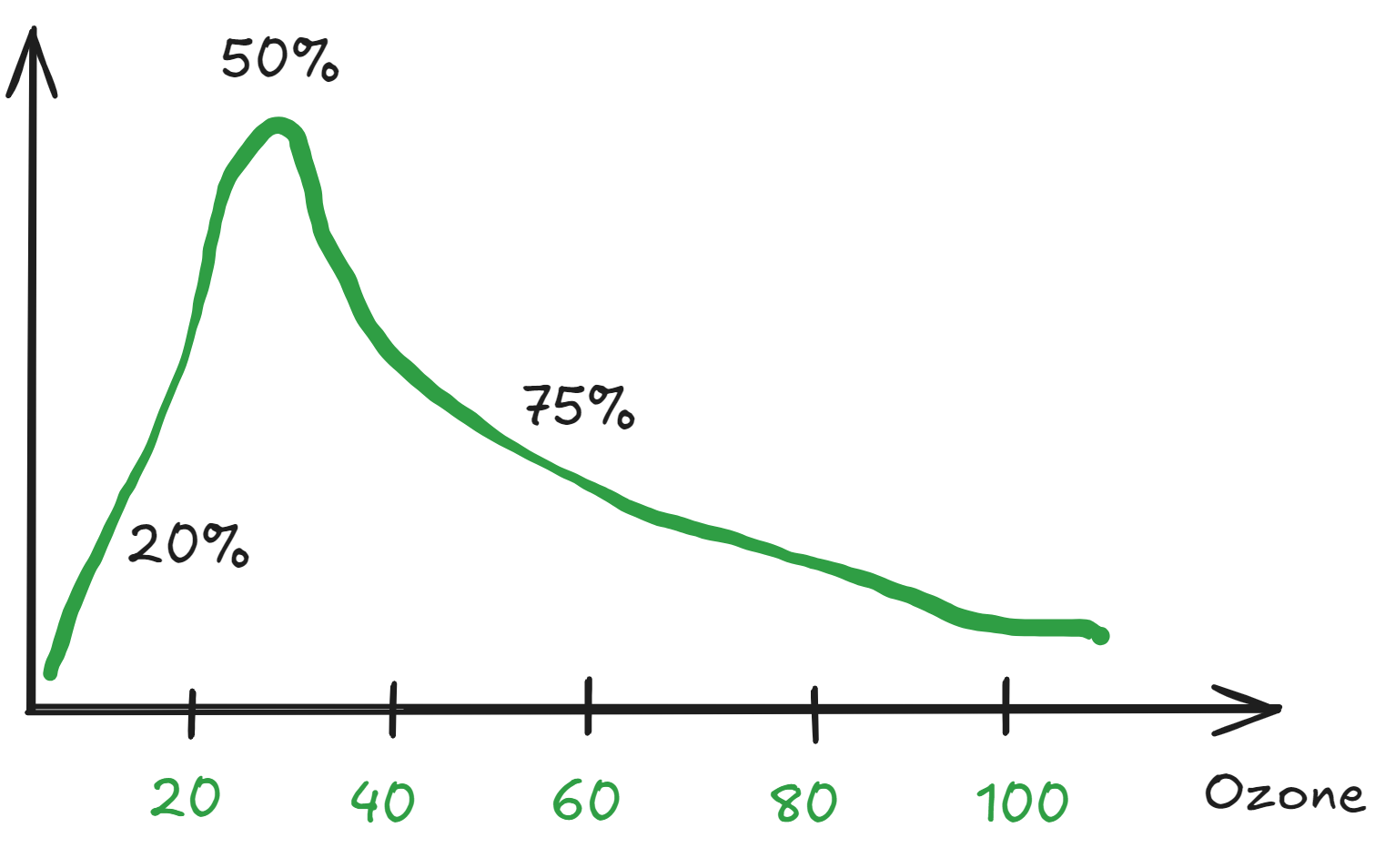
TIP! 평균을 대표값으로 사용할 때의 주의점
작은 값, 큰 값만 많은 경우가 있다!
A-2. 히스토그램
수치형 변수의 분포를 볼 때 사용
plt.hist()형으로 사용bins: 구간 개수 변경- 구간을 쪼개는 개수에 따라 얻을 수 있는 내용이 다름
# matplotlib 사용
plt.hist(titanic.Fare, bins = 5, edgecolor = 'gray')
plt.xlabel('Fare')
plt.ylabel('Frequency')
plt.show()
# seaborn 사용
sns.histplot(x= 'Fare', data = titanic, bins = 20)
plt.show()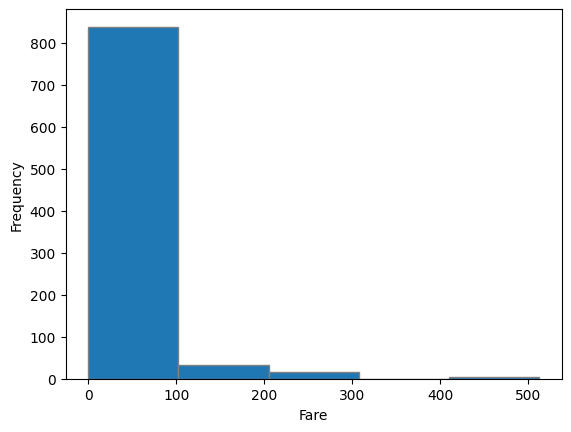
bins 를 변경하면서 그리기
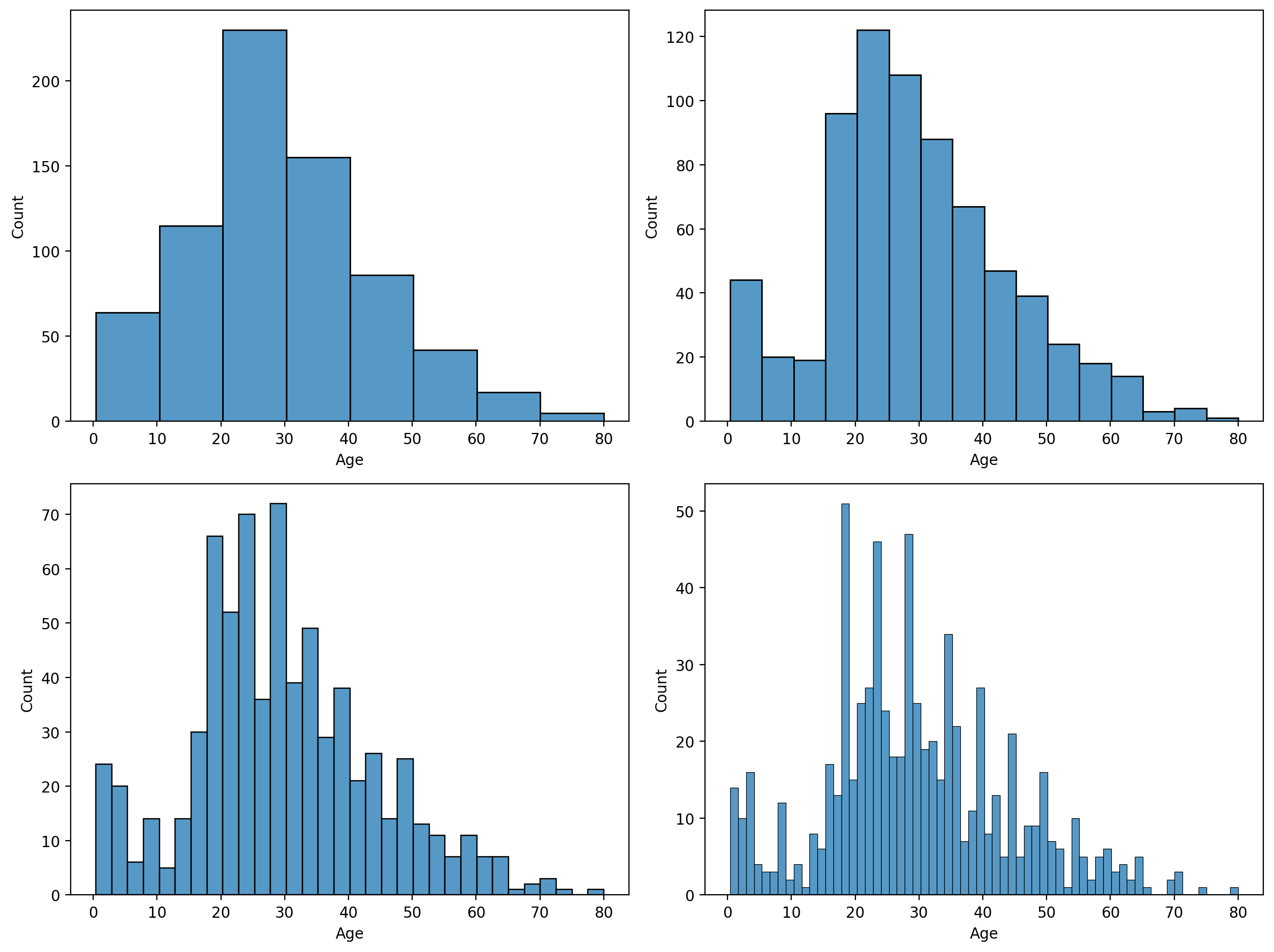
TIP! seaborn 의 장점
seaborn 은 x label, y label, edgecolor 가 자동으로 지정된다
A-3. 밀도 함수 그래프 (Destiny Plot, kde Plot)
- 히스토그램의 단점 : 구간(bin)의 너비를 어떻게 잡는지에 따라 전혀 다른 모양이 될 수 있음
- 막대의 너비를 가정하지 않고 모든 점에서 데이터의 밀도를 추정
- 밀도 함수 그래프 아래 면적은 1
sns.kdeplot(titanic['Fare'])
# sns.kdeplot(x='Fare', data = titanic)
plt.show()히스토그램 & Kde
sns.histplot(x='Age', data=titanic, kde=True)
plt.show()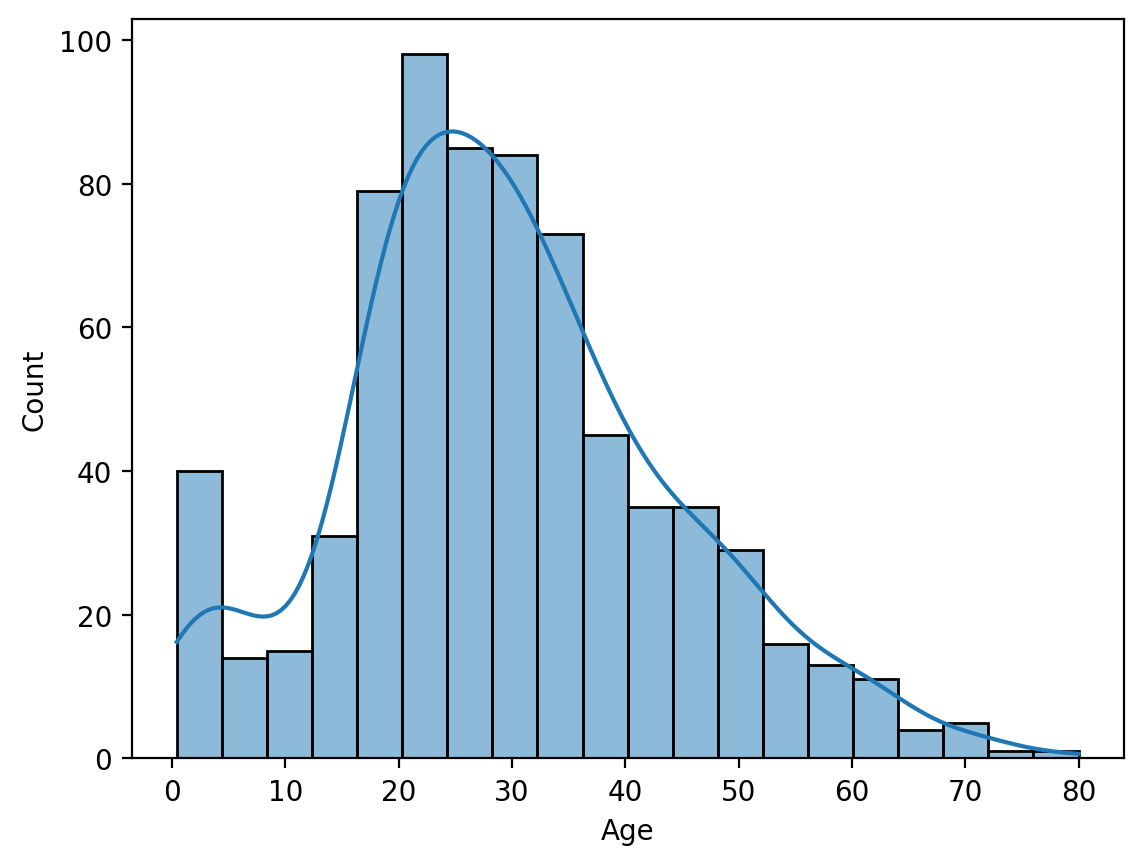
A-4. boxplot
- 값에 NaN 이 있으면 그래프가 그려지지 않음
박스와수염으로 구성- 박스 : 박스 맨 처음(Q1), 중간(Q2), 박스 끝(Q3)
- 4분위를 알 수 있다.
- 밀집도를 알 수 있다. 구간이 넓을수록 밀집도가 낮다.
- IQR (Inter Quartile Range) : 1사분위 ~ 3사분위까지의 길이. 즉, 박스의 길이
- IQR * 1.5 : 수염의 길이를 나타내는 공식. 이 값에서 제일 가까운 데이터를 수염의 최소, 최대로 설정한다. 이 선을 나가는 데이터는 이상치.
# matplotlib 사용
plt.boxplot(temp['Age'])
plt.grid()
plt.show()
# seaborn 사용 - NaN 이 자동으로 제외됨
sns.boxplot(x = titanic['Age'])
plt.grid()
plt.show()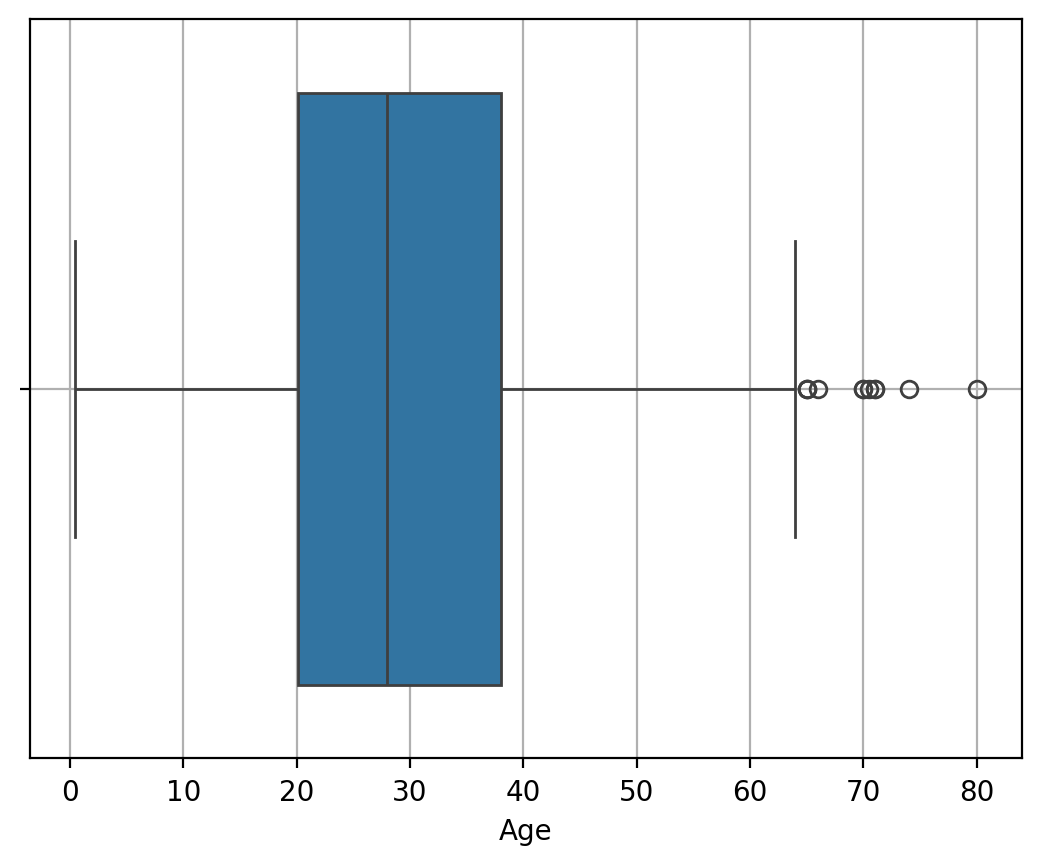
A-5. 그래프 읽기
- 축의 의미 파악하기
- x, y 축의 의미
- 값의 분포로부터 파악하기
- 희박한 구간, 밀집 구간
- 비즈니스 의미 파악
- 왜 그런 지 생각하기
