9/26 5세션
A. 이변량 분석
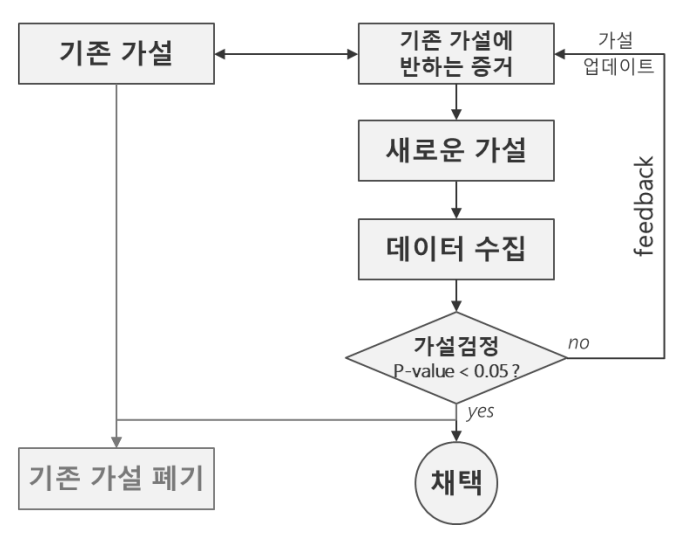
A-1. 가설 검정
- 모집단 : 우리가 알고 싶은 대상 전체 영역
- 표본 : 그 대상의 일부 영역
- 일부분으로 전체를 추정하고자 함
- 가설은 모집단으로 세우고, 확인은 표본으로 한다
- 분포를 알면 위치를 판단할 수 있음
비즈니스 이해단계
- 비즈니스 문제로부터 관심사(Y) 를 도출
- Y 에 영향을 주는 요인(X) 를 뽑아서 초기 가설 수립
귀무 가설
- 기존의 입장, 보수적인 입장
대립 가설
- 기존의 입장에 대해 새로운 입장을 가지고 주장
- 우리가 새운 가설, 새로운 가설, 내가 바라는 바
A-2. 통계적 검정
- 표본으로부터 대립 가설을 확인하고, 모집단에서도 맞을 것이라고 주장함
A-3. 시각화
산점도
- plt.scatter()
- sns.scatterplot()
sns.scatterplot(x='Temp', y='Ozone', data = air)
plt.show()pairplot
- 숫자형 변수들에 대한 산점도를 한번에 그려줌
- 시간이 많이 걸림
sns.pairplot(air, kind='reg' )
plt.show()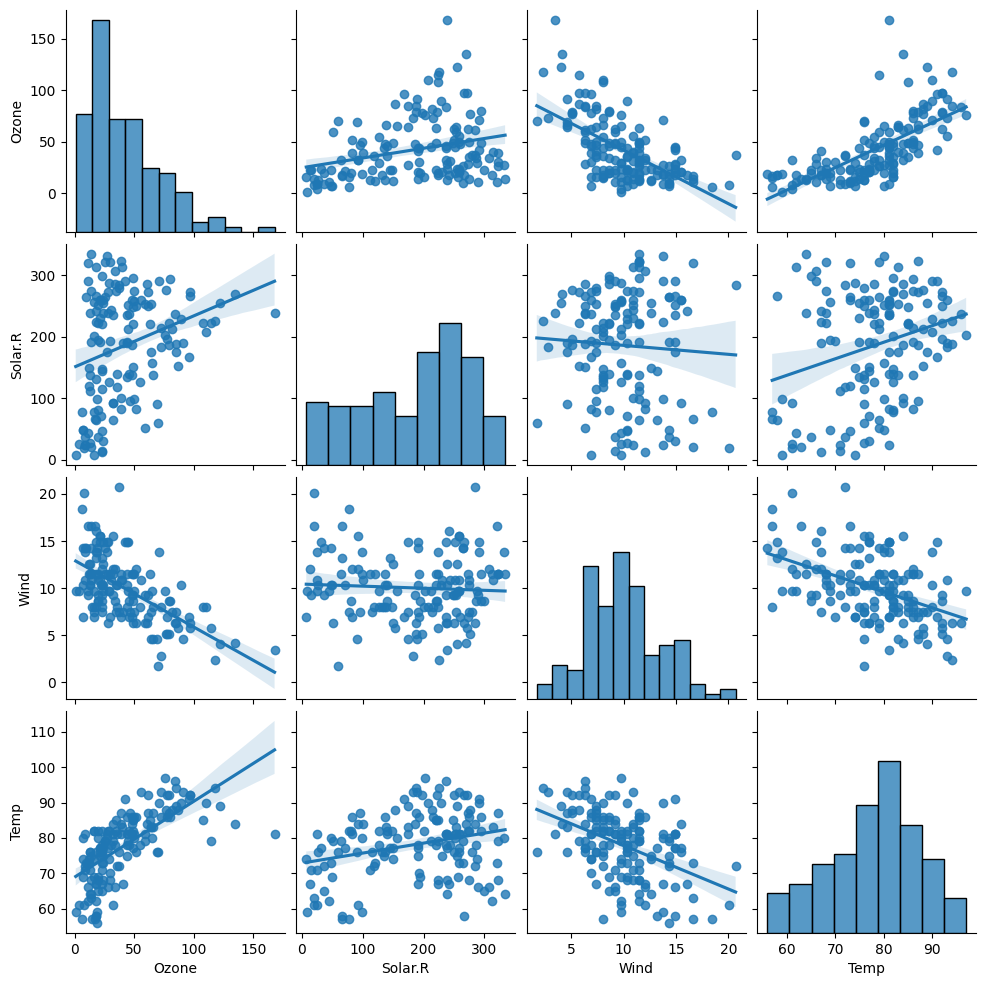
B. 수치화
B-1. 상관계수 (p-value)
- 관계를 숫자로 계산해서 비교
- 상관 계수 (r) : 공분산을 표준화 한 값. -1 ~ 1 사이의 값임. -1 or 1에 가까울 수록 강한 상관관계, 0에 가까울 수록 약한 상관관계
- 상관 분석 : 상관 계수가 유의미한지 검정
강한 : 0.5 < |𝑟| ≤ 1
중간 : 0.2 < |𝑟| ≤ 0.5
약한 : 0.1 < |𝑟| ≤ 0.2
(거의)없음 : |𝑟| ≤ 0.1상관계수 계산
- scipy.stats 라이브러리 사용
- pearsonr() 함수
- 값에 NaN이 있으면 계산되지 않음
> import scipy.stats as spst
> spst.pearsonr(air['Temp'], air['Ozone'])
PearsonRResult(statistic=0.6833717861490114, pvalue=2.197769800200284e-22) #강한 양의 상관관계- 튜플의 첫 번째 값 : 상관계수
- 두번째 값 : p-value
p-value
- p-value < 0.05 : 관계가 있다
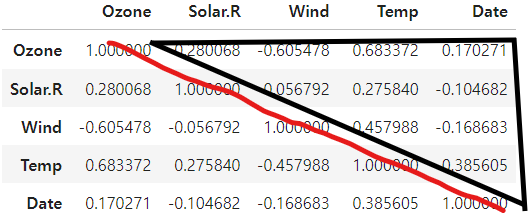
corr()
데이터프레임 한꺼번에 상관계수 구하기
- 대각선은 무시
- 위, 아래 값이 같으므로 둘 중 하나만 보면 됨
air.corr()