
9/27 3, 4, 5세션
A. 범주형 이변량 분석
A-1. 시각화
sns.barplot()- 평균 비교
- 두 평균에 차이가 크고, 신뢰 구간은 겹치지 않을 때 대립 가설이 맞다고 볼 수 있다.
- 신뢰구간이 좁을 수록 믿을만하다
A-2. T-test
t 통계량
spst.ttest_ind(a, b)- 두 그룹의 평균 간 차이를 표준 오차로 나눈 값. (두 평균의 차이)
- 보통, t 값이 -2보다 작거나, 2보다 크면 차이가 있다고 본다.
예시) 생존 여부에 따라 운임에 차이가 있을까?
> sns.barplot(x='Survived', y='Fare', data=titanic)
> plt.grid()
> plt.show()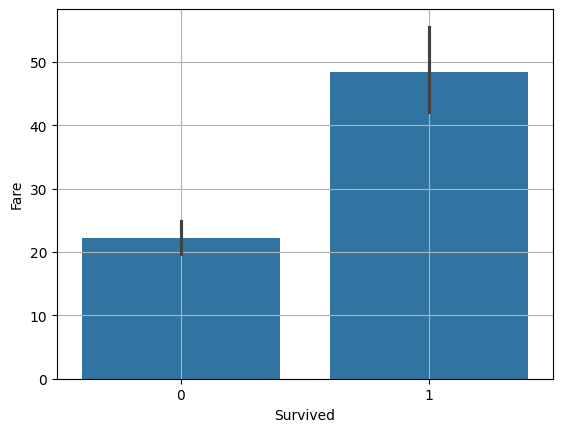
> died = titanic.loc[titanic['Survived']==0, 'Fare']
> survived = titanic.loc[titanic['Survived']==1, 'Fare']
> spst.ttest_ind(died, survived)
TtestResult(statistic=-7.939191660871055, pvalue=6.120189341924198e-15, df=889.0)- t-통계량이 -7이므로 평균에 유의미한 차이가 있다
- p-value가 0.05 보다 훨씬 작으므로 유의미한 차이가 있다
B. 분산분석 (anova)
- n개 이상의 집단 간 분석
- 집단 내 분산과 집단 간 분석 비교
- F 통계랑 (분산비) : 집단 간 분산 / 집단 내 분산
- 분산비가 클 수록 차이가 있다 (겹치지 않는다)
- 분산비가 2~3 이상이면 차이가 있다고 판단
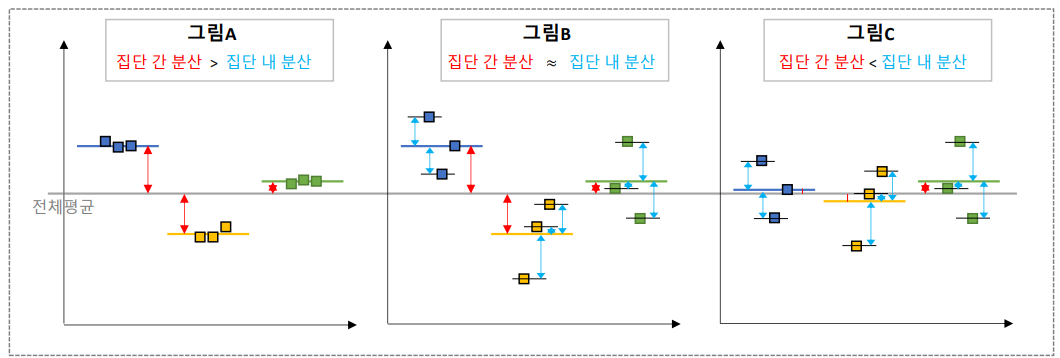
B-1. 분산분석 코드
spst.f_oneway(P_1, P_2, P_3)- 매개변수 순서 바뀌어도 같은 값 나옴
> P_1 = temp.loc[temp.Pclass == 1, 'Age']
> P_2 = temp.loc[temp.Pclass == 2, 'Age']
> P_3 = temp.loc[temp.Pclass == 3, 'Age']
> spst.f_oneway(P_1, P_2, P_3)
F_onewayResult(statistic=57.443484340676214, pvalue=7.487984171959904e-24)- f-통계량이 2보다 훨씬 크다 -> 각 그룹이 완전 떨어져있다
- 1, 2, 3 등급 내에서의 분산이 전체의 분산보다 57배 크다
B-2. t-test와 분산분석 간 관계
- t 통계량을 제곱하면 f 통계량이다
- p-value 는 동일하다
> died = titanic.loc[titanic['Survived']==0, 'Fare']
> survived = titanic.loc[titanic['Survived']==1, 'Fare']
> t = spst.ttest_ind(died, survived)
> f = spst.f_oneway(died, survived)
> print(t)
> print(f)
> print(t[0] ** 2)
TtestResult(statistic=-7.939191660871055, pvalue=6.120189341924198e-15, df=889.0)
F_onewayResult(statistic=63.03076422804448, pvalue=6.120189341921873e-15)
63.0307642280445