
10/30 1, 2, 3세션
A. 딥러닝이란
- 뇌 세포 (뉴런) 은 다음 뉴런과 연결되는데, 학습을 통해 연결의 강도를 조정 (가중치)
- 인공신경망 : 신경망을 인공적으로 구현
- 보편 근사 정리 : 어떤 연속 함수든, 모두 뉴럴넷으로 구현할 수 있다
- 생성형 AI의 기본은 Transformer 구조
- 최근의 AI 연구는 대부분 딥러닝 기반
- 파이썬 딥러닝 라이브러리로는 TensorFlow, Pytorch, keras(TensorFlow 라이트 버전) 등이 있다.
A-1. 딥러닝 개념
가중치
- 평균은 모두 같은 가중치를 가지고 있다.
- 최적의 모델은 오차가 가장 적은 모델
- 조금씩 weight 를 조정하면서 오차가 줄어드는 지 확인
- 학습 == 가중치를 찾는 것
학습 절차
- model.fit()을 하면,
- 가중치에 초기값을 할당
- 예측 결과를 뽑음
- 오차 계산 (실제 값 - 예측 값)
- 오차를 줄이는 방향으로 가중치 조정
- 1~4를 반복
Optimizer : 가중치를 조절하는 역할 (adam, GD 등)
Hypter Parameter
- epochs : 반복 횟수
- learning rate : 보폭. 얼만큼 조절할 지
A-2. 딥러닝 구조
- Input -> Task1 -> Task2 -> TaskN -> Output
- Task 레이어는 Hidden Layer 라고 한다
Dense
- Input : Input(shape=(, )) : 분석 단위에 대한 Shape
- Output : Dense(n) : 예측 결과가 n개 변수 (y가 n개)
- Param : 가중치 (= 파라미터). 커지면 모델이 커진(복잡해진)다.
컴파일
- 선언된 모델에 대해 몇 가지 설정을 한 후, 컴퓨터가 이해할 수 있는 형태로 변환하는 작업
- optimizer : 오차를 최소화하도록 가중치를 업데이트. adam 이 가장 좋음.
- loss : 오차 함수 (회귀 : mse / 분류 : cross entropy)
Learning rate
- 학습률
- 가중치 조정 정도
학습
- validation_split : 검증셋 분리
학습 곡선
- 모델의 오차가 줄어드는 과정을 그린 그래프
- 초기 epoch 에서는 오차가 크게 줄음
- 오차 하락이 꺾이는 구간 존재. (elbow)
- 점차 완만해짐
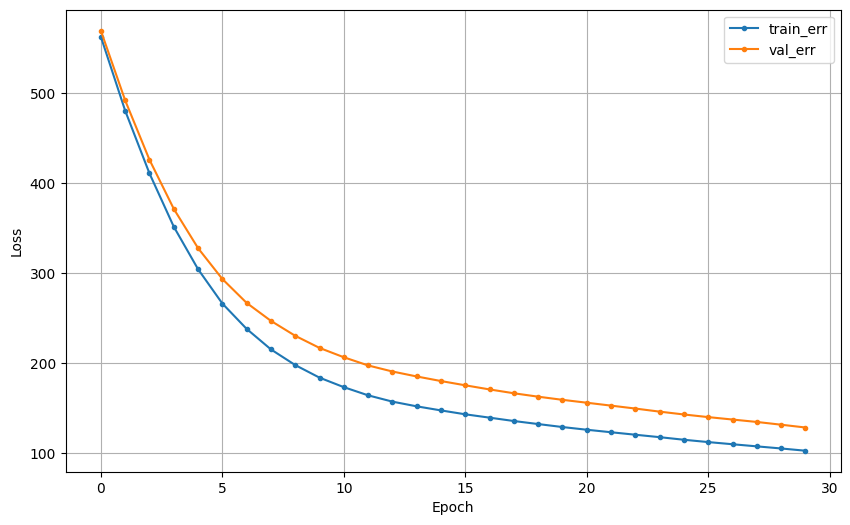
참고
모델을 처음 선언하면 가중치가 random 이지만 한 번 선언한 후 재학습시키면 이전 가중치에서 시작해서 계속해서 학습한다.
B. Hidden Layer
Input과 Output 사이의 Layer
model3 = Sequential([Input(shape=(nfeatures, )),
Dense(2, activation = 'relu'),
Dense(1)])- Input shape는 첫번째 layer 만 필요
- Activation : 활성함수. 보통 relu를 많이 사용
B-1. Activation Function
= 활성화 함수
- 현재 레이어의 결과값을 다음 레이어로 어떻게 전달할지 결정/변환하는 함수
B-2. 파라미터 개수 세기
| 1층 (Input) | 2층 (Hidden) | 3층 (output) |
|---|---|---|
| 12 | 2 | 1 |
이라고 할 때, 모든 층에는 절편 값 (bias) 가 하나 더 붙는다
그러므로, 1층의 결과는 (12+1) * 2 = 26
2층의 결과는 2+1 = 3이다.
모두 합하면 29이다.
기타) MAPE 가 크게 나오는 이유
MAPE는 오차율의 절대값들의 합을 개수로 나눈 것이다.
그런데 0은 나눌 수 없다. 실제값이 0이면 계산이 불가능한것.
대신에 분모가 0이면 0이 아닌 아주 작은 다른 값으로 나눈다.
그래서 MAPE가 아주 큰 수가 나온다.
