
10/31 2, 3, 4세션
A. Feature Representation
Hidden Layer 에서 무슨 일이 일어나는가?
- Hidden Layer의 계산된 값 (Z1, Z2 등)은 내부의 정보를 가지고 만든 값
B. Sigmoid
- 이진 분류에서는 모델 생성 시 activation을
sigmoid로 설정 - 값을 0과 1 사이의 확률로 변환
- output 노드도 이진 분류이기 때문에 0 또는 1이 필요하기 때문에 activation을 거쳐서 변환을 시킴
# 메모리 정리
clear_session()
# Sequential 모델 만들기
model = Sequential( [Input(shape = (nfeatures,)),
Dense( 1, activation= 'sigmoid')])
# 모델요약
model.summary()C. binary cross entropy
- 이진 분류에서는 컴파일 시 loss로
binary_crossentropy사용 - 0을 1에 가깝게, 1을 0에 가깝게 예측하면 오차를 키움
model.compile(optimizer = Adam(learning_rate=0.01),
loss = 'binary_crossentropy')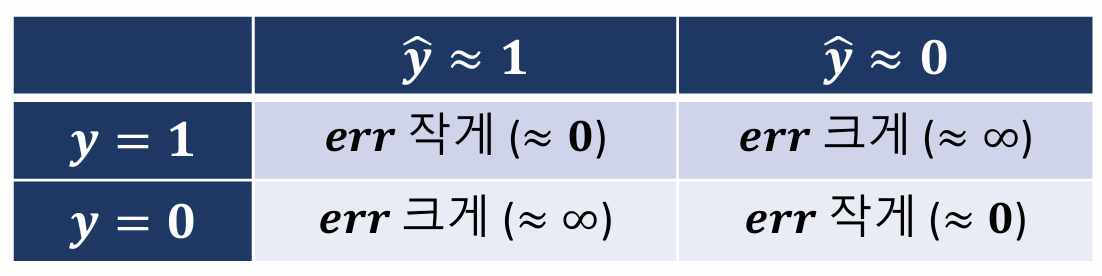
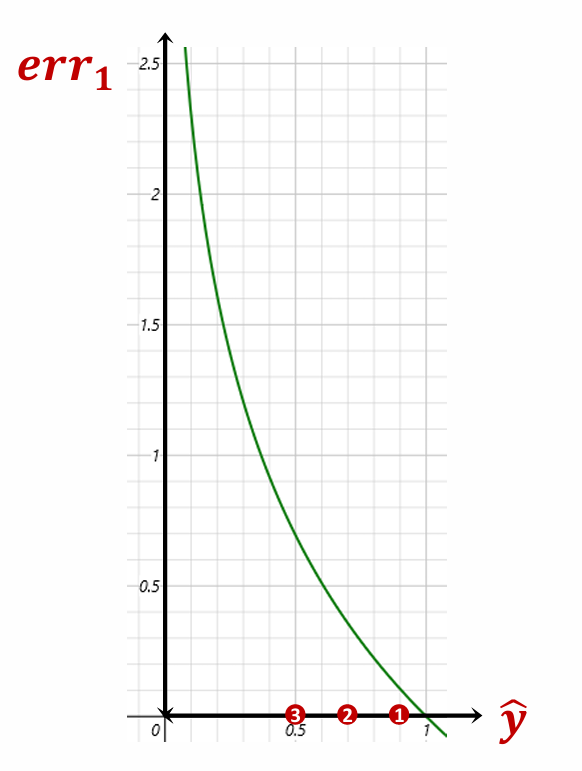
C-1. -log x 함수
- x가 증가하면 y도 계속 증가
D. 다중 분류
- 마지막 노드가 y의
- y에 대해서 반드시 인코딩이 필요
D-1. y 인코딩
- 정수 인코딩 (
loss = 'sparse_categorical_crossentropy') - One hot encoding (
loss = 'categorical_crossentropy')
- 두 loss function 은 수학적으로 동일함. 성능 차이 x
- label encoder 또는 map 사용
D-2. softmax
- activation = 'softmax'
- n개 이상에서의 확률을 구하는 알고리즘
# y 값 정수 인코딩
data['Species'] = data['Species'].map({'setosa':0, 'versicolor':1, 'virginica':2})
# 메모리 정리
clear_session()
# Sequential
model = Sequential( [Input(shape = (nfeatures,)),
Dense( 3, activation = 'softmax')] )
# 모델요약
model.summary()
model.compile(optimizer=Adam(learning_rate=0.1), loss= 'sparse_categorical_crossentropy')
history = model.fit(x_train, y_train, epochs = 50,
validation_split=0.2).historyD-3. np.argmax()
- 넘파이 배열에서 해당 배열 중 가장 큰 숫자의 인덱스 반환
pred.argmax(axis=1): 가로(열) 방향으로 가장 큰 값의 인덱스 반환- confusion matrix 에 넣기 위함
E. 딥러닝 시각화
[https://playground.tensorflow.org/]
