
10/16 1, 2, 3세션
A. KNN (K-Nearset Neighbor)
k개의 초근접 이웃
- 회귀와 분류에 모두 사용 가능하다
- 학습용 데이터에서 K개의 최근접 이웃의 값을 찾아 그 값들로 새로운 값을 예측하는 알고리즘
- 다른 알고리즘에 비해 이해하기 쉽지만, 연산 속도가 느리다

A-1. K 값의 중요성
- K에 따라 데이터를 다르게 예측할 수도 있음
K = 1: 이웃이 하나. 너무 편향된 정보다. 예민한 (복잡한) 모델이 됨.K = 데이터 개수: 회귀에서는 평균, 분류에서는 최빈값으로 예측한다.- 기본 값 : 5
- 검증 데이터로 가장 정확도가 높은 K 를 찾아 K 로 사용함 (튜닝)
A-2. 거리 구하기
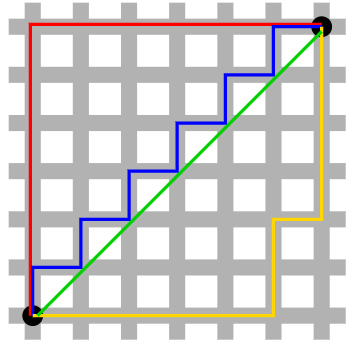
유클리드 거리
- 두 점 사이의 직선 거리
- 피타고라스 정리를 기반으로 계산
맨해튼 거리
- 두 점 사이의 수평 밎 수직 축을 따라 이동하는 거리 측정
- 격자형 도로에서 유래, 좌표 차이의 절대값을 차원 별로 더함
A-3. Scaling
- 거리의 숫자의 단위가 달라서 가까운 것이 멀게 계산되고, 먼 것이 가깝게 계산됨
- 거리 개념이 들어가는 알고리즘을 사용할 때는 변수의 단위를 0~1 사이로 맞춰야 한다! => 스케일링
- 머신러닝에서는 스케일링이 필수는 아니다
- 평가용 데이터도 학습용 데이터를 기준으로 스케일링 수행
정규화
- 각 변수의 값이 0과 1 사이 값이 됨
- 이상치에 민감하기 때문에, 이상치가 많다면 추천되지 않음 (최대값과 최소값은 보통 이상치)
표준화
- 각 변수의 평균이 0, 표준 편차가 1이 됨
- 이상치의 영향을 정규화보다 덜 받음
B. KNN 함수
B-1. 정규화 함수
sklearn.preprocessing import MinMaxScaler사용- 스케일러를 거치면 데이터프레임이 배열이 되기 때문에 컬럼 이름 삭제
- 다른 변수로 받아주는 것이 필요
# 모듈 불러오기
from sklearn.preprocessing import MinMaxScaler
# 정규화
scaler = MinMaxScaler()
scaler.fit(x_train) # 학습 데이터의 최소값, 최대값 찾는 과정
x_train_s = scaler.transform(x_train) # 학습 데이터 정규화
x_test_s = scaler.transform(x_test) # 테스트 데이터 정규화
# 다른 방법 - fit(x_train) 생략
# x_train_s = scaler.fit_transform(x_train) # 피팅 후 정규화 진행
# x_test_s = scaler.transform(x_test)B-2. 표준화 함수
from sklearn.preprocessing import StandardScaler사용
from sklearn.preprocessing import StandardScaler
# 정규화
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train) # 학습 데이터 정규화
x_test = scaler.transform(x_test) # 테스트 데이터 정규화B-3. KNN 모델링
# 1단계: 불러오기
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import mean_absolute_error, r2_score
# 2단계: 선언하기
model = KNeighborsRegressor()
# 3단계: 학습하기
model.fit(x_train, y_train)
# 4단계 예측하기
y_pred = model.predict(x_test)
# 5단계: 평가하기
print('MAE :', mean_absolute_error(y_test, y_pred))
print('R2 :', r2_score(y_test, y_pred))