scikit-learn이란?
scikit-learn 공식홈페이지
이곳으로 들어가면 바로 scikit-learn에서 제공하는 데이터셋의 종류들을 볼 수 있다.
실제 구현해보기
예제 - 붓꽃 분류해보기
scikit-learn의 iris의 데이터에는 150개의 데이터가 들어있고, [sepal length, sepal width, petal length, petal width]형식으로 들어가 있다.
# (1) 필요한 모듈 import
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
# (2) 데이터 준비
iris = load_iris()
iris_data = iris.data
iris_label = iris.target
# (3) train, test 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(iris_data,
iris_label,
test_size=0.2,
random_state=7)
# (4) 모델 학습 및 예측
decision_tree = DecisionTreeClassifier(random_state=32)
decision_tree.fit(X_train, y_train)
y_pred = decision_tree.predict(X_test)
print(classification_report(y_test, y_pred))train, test 데이터 분리
train_test_split : scikit-learn에서 제공하는 데이터셋나누는 메소드
- 1번째 인자: feature
- 2번째 인자: label
- test_size: test dataset의 크기(전체데이터의 몇프로)
- random_state: train데이터와 test데이터를 분리(split)하는데 적용되는 랜덤성
모델 학습 및 예측
sklearn.metrics : scikit-learn에서 성능 평가에 대한 함수들이 모여있는 패키지
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)
accuracy # 0.90.9라는 수치는 90%의 정확도를 보인다는 뜻이다.
머신러닝
- 지도학습 (Supervised Learning) : 정답이 있는 문제에 대해 학습하는 것
- 분류(Classification)
- 입력받은 데이터를 특정 카테고리 중 하나로 분류해내는 문제
- Ex. 키, 시력, 병력 등으로 군대(현역, 공익, 면제) 판정
- 회귀(Regression)
- 입력받은 데이터에 따라 특정 필드의 수치를 맞추는 문제
- Ex. 넷플릭스 추천 시스템, 집에 대한 정보(평수, 위치, 층수 등)를 입력받아 그 집의 가격을 맞추는 것
- 분류(Classification)
- 비지도 학습 (Unsupervised Learning) : 정답이 없는 문제를 학습하는 것
분류 모델
Decision Tree 의사결정트리
참고 사이트
https://ratsgo.github.io/machine%20learning/2017/03/26/tree/
- 분기가 거듭될수록 나뭇가지처럼 쪼개지는 형태를 보이며 데이터를 분리한다.
- terminal node의 총 개수와 root node의 개수가 일치한다. 즉, terminal node간 교집합이 없다.
- 순도(homogeneity)의 증가/불순도(불확실성, entropy)가 최대한 감소하도록 하는 방향으로 학습을 진행
- 엔트로피가 낮을수록 불확실성 감소(=순도증가,정보획득)
- 모델학습과정
- 재귀적분기 : 입력 변수 영역을 두개로 구분
- 가지치기 : 너무 자세히 구분된 영역을 통합
- 결정경계가 데이터 축에 수직이어서 특정 데이터에만 잘 작동할 수 있다는 문제가 있다. 이를 극복하기 위해 제안된 모델이 Random Forest이며, 여러 개의 Decision Tree를 합쳐서 만들어놓은 개념이다.
scikit-learn이 제공하는 Decision Tree model
from sklearn.tree import DecisionTreeClassifier
decision_tree = DecisionTreeClassifier(random_state=32)
print(decision_tree._estimator_type)
decision_tree.fit(X_train, y_train)
y_pred = decision_tree.predict(X_test)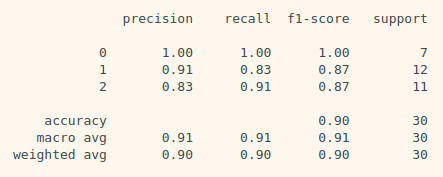
RandomForest
참고사이트
군중은 똑똑하다 — Random Forest
- Random Forest는 여러개의 의사 결정 트리를 모아 놓은것으로, 각각의 의사 결정 트리를 만들기 위해 쓰이는 특성들을 랜덤으로 선택한다.
from sklearn.ensemble import RandomForestClassifier
X_train, X_test, y_train, y_test = train_test_split(iris_data,
iris_label,
test_size=0.2,
random_state=25)
random_forest = RandomForestClassifier(random_state=32)
random_forest.fit(X_train, y_train)
y_pred = random_forest.predict(X_test)Support Vector Machine(SVM)
참고사이트
http://hleecaster.com/ml-svm-concept/
https://excelsior-cjh.tistory.com/66?category=918734
from sklearn import svm
svm_model = svm.SVC()
svm_model.fit(X_train, y_train)
y_pred = svm_model.predict(X_test)Stochastic Gradient Descent Classifier (SGDClassifier)
from sklearn.linear_model import SGDClassifier
sgd_model = SGDClassifier()
sgd_model.fit(X_train, y_train)
y_pred = sgd_model.predict(X_test)Logistic Regression 로지스틱회귀
from sklearn.linear_model import LogisticRegression
logistic_model = LogisticRegression()
logistic_model.fit(X_train, y_train)
y_pred = logistic_model.predict(X_test)모델 성능 지표
정답과 오답을 구분하여 표현하는 방법을 오차행렬(confusion matrix)라고 한다.
오차행렬은 예측결과를 TN(True Negative), FP(False Positive), FN(False Negative), TP(True Positive)로 구분한다.
정확도(Accuracy)
전체 개수 중 맞은 것의 개수의 수치
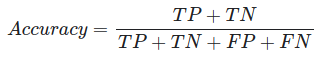
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)
accuracy정확도의 함정
정확도는 정답의 분포에 따라 모델의 성능을 잘 평가하지 못할 수 있다. (불균형한 데이터에서 많이 발생할 수 있다)
Precision 정밀도
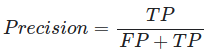
Recall(Sensitivity) 재현율
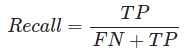
F1 score
Recall과 Precision의 조화평균
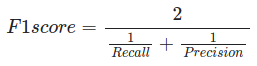
Specificity
예시
Precision
- 스팸메일분류 : 스팸메일을 못 거르는 것은 괜찮지만 정상메일을 스팸메일로 분류하는 것이 더 큰 문제
Recall
- 암 진단 : 양성을 음성으로 판단하면 안되기 때문
classification_report
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))- Micro Averaging : 클래스별 f-score 점수에 가중치를 주지 않는다. 클래스 크기에 상관없이 모든 클래스를 같은 비중으로 다룬다.
- Weighted Averaging : 클래스별 샘플 수로 가중치를 두어 f-score의 평균을 계산한다.
- Macro Averaging : 모든 클래스의 거짓양성, 거짓음성, 진짜 양성의 총 수를 헤아린 다음 정밀도, 재현율, f-score를 이 수치로 계산한다.
pandas
파이썬에서 표 형태로 이루어진 2차원 배열 데이터를 다루는 데에 가장 많이 쓰이는 도구
iris_df = pd.DataFrame(data=iris_data, columns=iris.feature_names)
iris_df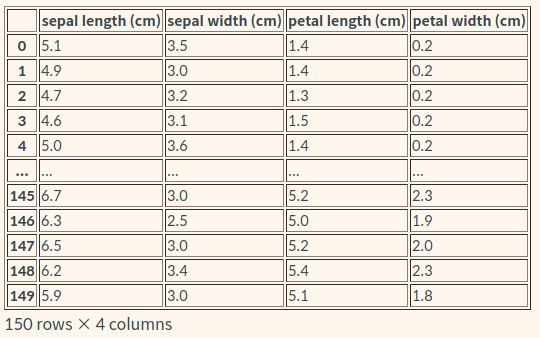
정답 데이터도 추가
iris_df["label"] = iris.target
iris_df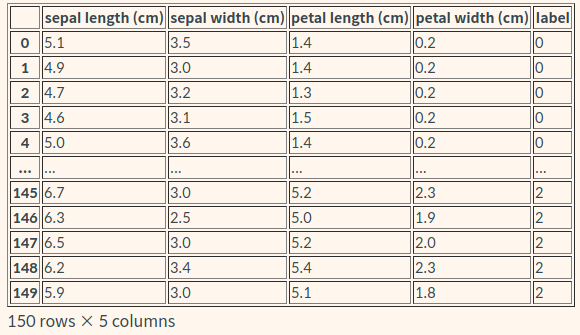
- 문제지 : 머신러닝 모델에게 입력되는 데이터. feature라고 부르기도 한다. 변수 이름으로는 X를 많이 사용한다.
- 정답지 : 머신러닝 모델이 맞추어야 하는 데이터. label, 또는 target이라고 부르기도 한다. 변수 이름으로는 y를 많이 사용한다.
