
1. 수업소개
-
누구나 쉽게 데이터를 정리정돈 할 수 있는 전문적인 소프트웨어 : database
- 관계형 데이터베이스(Relational database)
- MySQL, Oracle, SQL Server, PostgreSQL, DB2, Access 등
- 관계형 데이터베이스(Relational database)
-
MySQL : 무료, 오픈소스, 관계형 데이터베이스의 기능 대부분을 가짐.
- Web이 폭발적으로 성장하면서 웹 개발자들은 정보를 저장할 데이터베이스를 찾기 시작하면서 많이 쓰임.
수업 내용
- MySQL 소개
- 서버, 스키마, 테이블 만드는 법
- 테이블에 데이터를 입력하고, 출력하는 법
- JOIN
- 데이터베이스 클라이언트와 서버의 개념
- MySQL Workbench 사용법
추후 수업을 통해 배울 내용
아래 내용은 DATABASE3 수업을 통해 학습하자.
- 색인
- 백업
- view
- MySQL을 위한 클라우드 컴퓨팅 서비스들
2. 데이터베이스의 목적
스프레드 시트와 데이터베이스의 차이를 통해 데이터베이스의 목적이 무엇인지 학습하자.
- 공통점
- 데이터를 표로 표현해줌
- 차이점
- 스프레드 시트: 사용자가 버튼을 클릭해서 데이터를 조작함
- 데이터베이스: SQL이라는 컴퓨터 언어, 즉 코드를 이용해서 데이터를 조작함
-> 데이터 베이스의 데이터들을 앱, 웹을 사용해 다른 이들에게도 보여줄 수 있고 빅데이터 및 인공지능을 통해 분석할 수 있음.
- 데이터베이스를 사용하는 여러 목적 중 하나!
웹사이트의 정보를 데이터 베이스에 담으면, 즉 연동하면- 전세계의 누구나 웹을 통해 데이터베이스의 정보를 볼 수 있음.
- 사용자가 웹 사이트에 접속해서 글을 쓰면 우리가 데이터 베이스를 조작하지 않아도 자동으로 데이터베이스에 그 정보가 담아짐.
3. MySQL 설치
- 검색: mysql community edition download
- https://www.mysql.com/products/community/
- Download MySQL Community Edition 클릭
- MySQL Community Server 클릭
- 자신에게 맞는 운영체제 선택 후 설치
- 위 방법대로 설치하면 과정이 까다로움. MySQL을 쉽게 설치하는 프로그램을 설치할 것
- bitnami WAMP 설치. 설치방법은 링크 클릭하여 중간에 웹서버 설치(윈도우) <- 참고.
win + R누르고cmd실행하기.> cd c:\Bitnami\wampstack-8.0.12-0\mariadb\bin> mysql -uroot -p입력하면 mysql 비밀번호 입력하는 게 나옴. 비밀번호 입력하면 실습 준비 끝!
4. MySQL의 구조
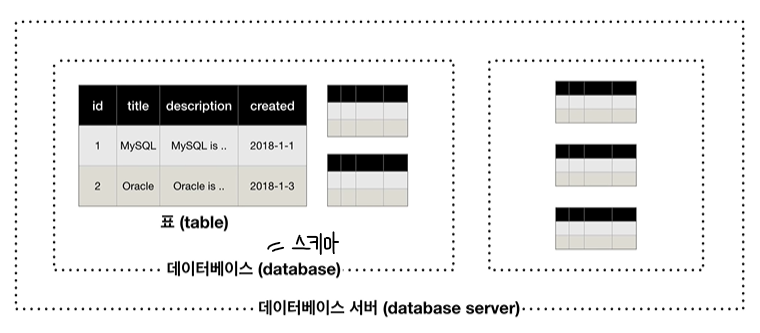
- MySQL data는 표(table)의 형태로 저장됨.
- 많은 연관된 표(table)들을 grouping해서 모은 걸 스키마(=데이터베이스. 우리가 배우는 전체적인 의미의 데이터베이스와 다름!)라고 함.
- 이러한 많은 스키마들이 저장되는 곳: 데이터베이스 서버(database server)
5. 서버접속
-
데이터베이스를 사용하는 데 얻는 이점 중 하나 : 보안
- 사용자에 따라 데이터를 수정하는 데에 권한을 따로 부여할 수 있음. 데이터베이스만의 기능! (읽기만 가능, 쓰기만 가능, 둘 다 가능 등...)
-
서버 접속(3강과 중복 내용 있음)
-
win + R누르고cmd실행하기. -
> cd c:\Bitnami\wampstack-8.0.12-0\mariadb\bin -
> mysql -uroot -p입력하면 mysql 비밀번호 입력하는 게 나옴. 비밀번호 입력하면 서버 접속 성공- -u: user 사용자, -uroot: root 사용자(관리자)로 접속, -uegoing: egoing 사용자로 접속. root 사용자는 모든 권한이 뚫려있기 때문에 데이터 다룰 때 위험함. 사용자를 따로 만들어서 권한을 설정해서 작업하다가 중요하게 모든 권한 사용해야할 때 루트 사용자로 접근하는 것 추천.
-
비밀번호 있었다면 검색어: mysql password forgot
6. 스키마의 사용
- 스키마 사용에 대한 코드 검색어: mysql create database
CREATE DATABASE opentutorials- MariaDB(MySQL)을 열고 위 코드를 작성하면 Query OK 뜸.
- 삭제 관련 코드 검색: mysql delete database
DROP DATABASE opentutorials
- 데이터베이스 확인 관련 코드 검색어: how to show database list in mysql
SHOW DATABASES;
- 표 만들 때 위에서 만든 데이터 베이스를 사용한다는 걸 mysql에게 알려주는 코드
USE opentutorials;
7. SQL과 테이블의 구조
데이터 베이스를 넘어서 스키마를 넘어서 테이블, 표를 만들 과정!
이제 SQL(Structured Query Language) 언어를 배움
-
SQL의 특징 : 쉽다, 중요하다
-
표(table): x축과 y축으로 쪼개서 생각함.
- x축 = 행(= row, record), 데이터 자체.
- y축 = 열(= column). 보통 데이터의 type(구조)이 여기 들어감.
8. 테이블의 생성
-
테이블 생성 관련 검색어 : create table in mysql cheat sheet -> 이미지 검색으로 보기.
-
테이블 하나하나에 넣는 데이터의 type을 제한하는 법 관련 검색어: mysql datatype number
- 데이터베이스는 컬럼(열)의 데이터 타입을 강제할 수 있음.
-
code
CREATE TABLE topic(
-> id INT(11) NOT NULL AUTO_INCREMENT, //id는 열에 오는 값. (11)은 보여질 때 몇개만큼만 보여지는지(노출정도). NOT NULL은 공백 허용 안함. AUTO_INCREMENT는 열 추가시 자동으로 +1씩 숫자가 증가하게 하는 설정.
-> title VARCHAR(100) NOT NULL, // VARCHAR(숫자)에서 숫자는 문자열을 한정시키는 숫자. VARCHAR는 한정된 문자열만큼 끊어서 데이터를 넣는 기능을 함.
-> description TEXT NULL, // TEXT는 VARCHAR보다 더 많은 문자열을 수용함. NULL은 공백값 허용
-> created DATETIME NOT NULL, // DATETIME은 날짜와 시간.
-> author VARCHAR(30) NULL,
-> profile VARCHAR(100) NULL,
-> PRIMARY KEY(id)); // PRIMARY KEY()는 중복되지 않는 고유한 값을 가져야 하는 걸 지정해야 할 때 사용하며 topic 테이블의 id 컬럼이 메인임을 알림. 성능적인 측면과 중복방지 측면에서 좋은 기능.-
데이터베이스의 규제 정책 덕분에 데이터를 깔끔하게, 우리가 원하는 방식으로 정리할 수 있음.
-
테이블 확인:
DESC topic;
9. CRUD
- 데이터베이스가 갖는 4가지 작업: CRUD
- Create. Read는 가장 기본이 되고 중요함.
- Update, Delete는 경우에 따라 죄악시 되고 범죄가 될 수 있음(역사분야나 회계 분야).
즉, 없을 수도 있음.
10. INSERT
-
내용을 추가하는 법 관련 검색어: mysql create row
INSERT INTO 테이블명(컬럼명,컬럼명,..) VALUES(컬럼에 따른 값,컬럼에 따른 값,..); -
코드
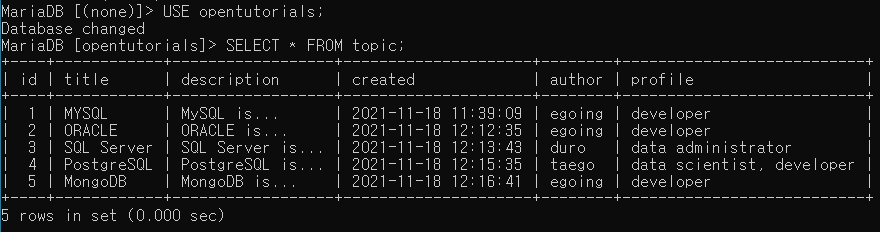
INSERT INTO topic(title,description,created,author,profile) VALUES('MYSQL','MySQL is...',NOW(),'egoing','developer'); -
작성한 내용 확인하는 법 관련 검색어: how to read row in mysql
-
코드
SELECT * FROM topic;
11. SELECT
-
SELECT = 데이터를 읽는 것.
-
모든 데이터 화면에 표시:
SELECT * FROM topic; -
한정된 컬럼만 표시:
SELECT id,title,created,author FROM topic; -
SELECT와 관련된 문법 검색어: mysql select syntax
기본문법:SELECT coloums이름; -
값이 egoing인 열만 보고 싶으면
SELECT id,title,created,author FROM topic WHERE author='egoing';
-
정렬 기능: id 기준으로 내림차순 정렬
SELECT id,title,created,author FROM topic WHERE author='egoing' ORDER BY id DESC;
-
노출 제한 걸기: 코드 제일 끝에
LIMIT 2(노출할 수);
12. UPDATE
- 수정은 어떻게 하는지에 관련된 검색어: sql update mysql
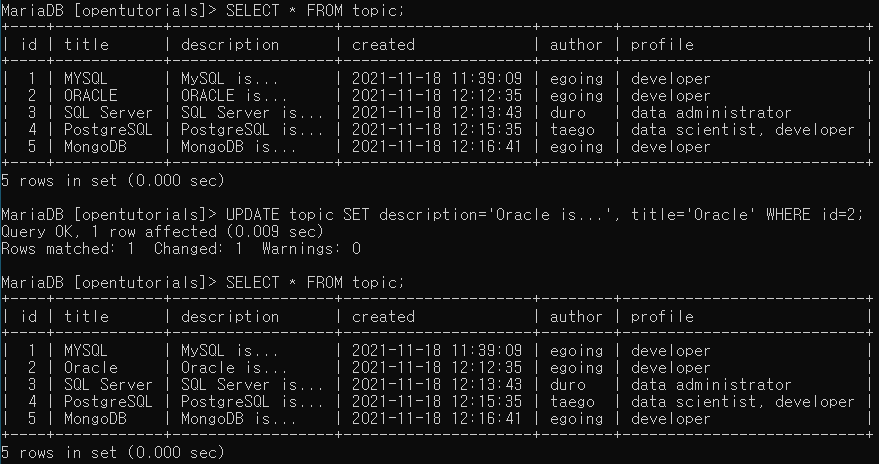
- ORACLE을 Oracle로 바꾸기!
UPDATE topic SET description='Oracle is...', title='Oracle' WHERE id=2;
13. DELETE
- 검색: SQL delete in mysql
- id = 5인 행 삭제하기!
DELETE FROM topic WHERE id = 5;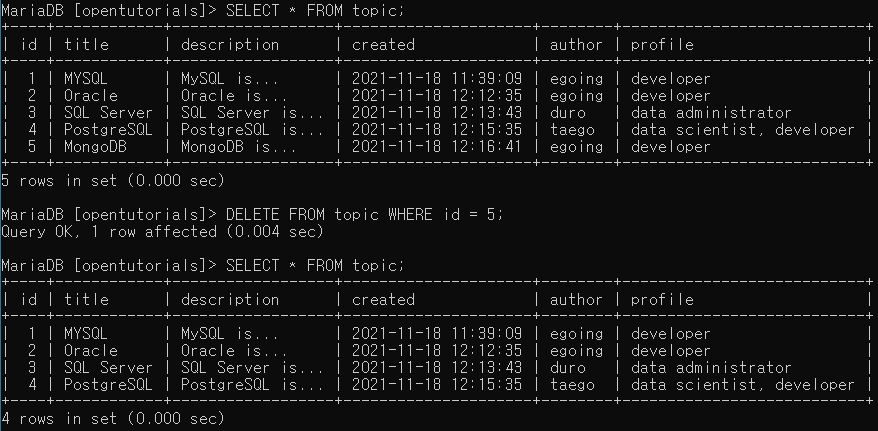
14. 수업의 정상
-
지금 여기가 수업의 정상!
-
데이터베이스라는 말 자체 : 본질(CRUD)
-
관계형 데이터베이스 : 혁신
-> 지금까지의 수업보다 조금 더 어렵고 복잡함. 이제부터는 이 관계형 데이터베이스에 접근할 것.
15. 관계형데이터베이스의 필요성
-
중복되는 데이터는 개선할 여지가 있음. 왜냐면 데이터가 수천수만개로 커질 때 중복으로 인한 오류가 생길 수 있고 유지 보수가 힘들 수 있기 때문.
-
저장은 분산해서, 보여줄 땐 합쳐서 보여지는 것이 중요. 직관성이 있고 중복으로 인한 오류 및 유지보수의 어려움을 타파할 수 있기 때문에.
-
다음 강의에 우리가 할 것 -> 서로 다른 두 테이블을 하나로 합치는 것!
16. 테이블 분리하기
-
기존의 테이블 확인:
SHOW TABLES; -
테이블 이름 변경:
RENAME TABLE topic to topic_backup; -
새롭게 테이블 2개를 만들고 (topic과 author), author의 id값을 서로 join 시킬 것.
-> 이건 다음 시간에. -
코드
--
-- Table structure for table `author`
--
CREATE TABLE `author` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL,
`profile` varchar(200) DEFAULT NULL,
PRIMARY KEY (`id`)
);
--
-- Dumping data for table `author`
--
INSERT INTO `author` VALUES (1,'egoing','developer');
INSERT INTO `author` VALUES (2,'duru','database administrator');
INSERT INTO `author` VALUES (3,'taeho','data scientist, developer');
--
-- Table structure for table `topic`
--
CREATE TABLE `topic` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(30) NOT NULL,
`description` text,
`created` datetime NOT NULL,
`author_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
);
--
-- Dumping data for table `topic`
--
INSERT INTO `topic` VALUES (1,'MySQL','MySQL is...','2018-01-01 12:10:11',1);
INSERT INTO `topic` VALUES (2,'Oracle','Oracle is ...','2018-01-03 13:01:10',1);
INSERT INTO `topic` VALUES (3,'SQL Server','SQL Server is ...','2018-01-20 11:01:10',2);
INSERT INTO `topic` VALUES (4,'PostgreSQL','PostgreSQL is ...','2018-01-23 01:03:03',3);
INSERT INTO `topic` VALUES (5,'MongoDB','MongoDB is ...','2018-01-30 12:31:03',1);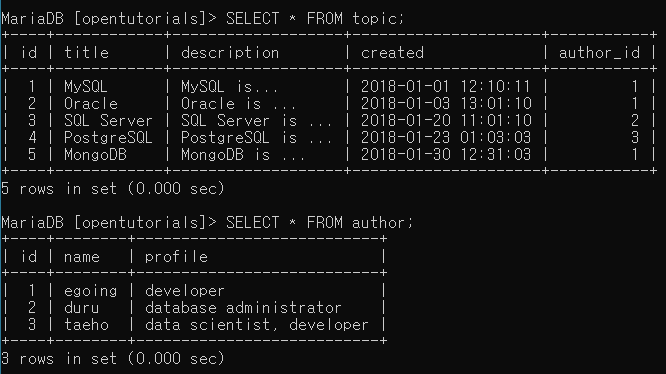
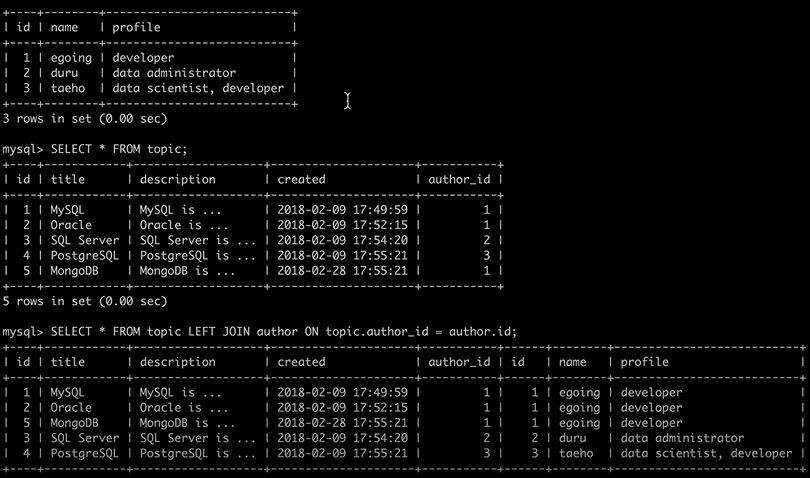
17. 관계형 데이터베이스의 꽃 JOIN
- 독립적으로 분리된 table을 join을 통해 읽을 때 하나인 것처럼 합쳐서 읽을 수 있음.
SELECT * FROM topic LEFT JOIN author ON topic.author_id = author.id;

- topic 테이블의 author_id 값과, author테이블의 id 값 같음. 즉 중복됨.
-> SLECTE로 중복되는 값 제외하여 보기 편하게 바꾸자!
SELECT topic.id,title,description,created,name,profile FROM topic LEFT JOIN author ON topic.author_id = author.id;
-> id는 토픽id임을 나타내고 싶음.
SELECT topic.id AS topic_id,title,description,created,name,profile FROM topic LEFT JOIN author ON topic.author_id = author.id;
- 테이블의 분리를 통한 이점.
테이블이 특정 식별자를 가지고 있다면, JOIN을 통해 얼마든지 관계를 맺을 수 있다.
-> 이를 통해 하나를 수정하면 전체를 한번에 수정 가능함.
-> JOIN은 관계형 데이터베이스를 관계형 데이터베이스 답게 만드는 명령어!
18. 인터넷과 데이터베이스
폰 노이만: 수학은 이해하는 것이 아니라 익숙해지는 것이다
-
database server 를 알기 전 인터넷에 대해 알아야함.
- 인터넷이 동작하기 위해 필요한 컴퓨터 : 최소 2대
- Client(클라이언트): 서비스를 요청하는 함.
- Server(서버): 그 요청에 응답함.
- 인터넷은 클라이언트와 서버가 정보를 '요청' 하고 '응답' 하면서 동작하는 서비스.
- 인터넷이 동작하기 위해 필요한 컴퓨터 : 최소 2대
-
데이터베이스도 이처럼 클라이언트와 서버가 나누어져있음.
데이터베이스 서버를 다룰 때, 어떠한 형태이든 간에 데이터베이스 클라이언트를 통해야만 함. -
우리는 지금까지 MySQL monitor라는 명령어 기반의 데이터베이스 클라이언트 프로그램을 통해 데이터베이스 서버에 접근해 데이터를 쓰고 읽고 수정하고 삭제했음.
-
하나의 DB 서버에 여러 클라이언트들이 접근해 데이터를 활용할 수 있음.
-
이러한 개념이 어려워도 걱정말자. 모든 건 이해하는 게 아니라 익숙해지는 거!
19. MySQL Client
- MySQL monitor는 MySQL 서버를 설치하면 함께 설치되는 클라이언트 프로그램. 어디에서나 사용 가능.
GUI가 아니라 명령어를 통해 제어하는 CLI(Command-line interface,명령어 기반) 프로그램.
-
MySQL Workbench는 GUI 기반의 클라이언트 프로그램. 시각적으로 접근하기 편하지만 프로그래머에 따라 이 기능을 사용하지 않는 게 있어 쓰이는 장소가 한정적임.
-
검색: mysql client
-> 여러 mysql 클라이언트 프로그램을 알 수 있음.
20. MySQL Workbench
-
mysql에 접근할 때 코드:
mysql -uroot -p -h도메인주소 또는 아이피 또는 개인컴이면 localhost 또는 127.0.0.1 -
h 생략시 기본적으로 로컬호스트 가리킴.
-
자신에게 맞는 mysql 클라이언트를 찾는것이 중요하다.
21.수업을 마치며
-
SQL의 CRUD 중 R이 굉장히 까다로움. 익숙해지기 위해서 많은 연습이 필요함.
-
데이터가 많아지면 필요한 정보를 꺼내기가 어려움. index를 통해 정리정돈이 필요함.
데이터베이스에도 index 이용 가능. 검색으로 관련 내용 찾아보자!
- 데이터가 많아질 수록 테이블을 효율적으로 중복없이 설계할 것인지 modeling이 중요.
-> 정규화, 비정규화, 역정규화 등...
-> 나중에 modeling 키워드로 찾아보자! - backup 아주 중요!
-> 관련 키워드: mysqldump, binarylog - cloud: 서버를 임대해서 사용하는 것. 백업도 거기에서 바로 가능. -> 원격제어(사이트 접속)를 통해 다루게 됨.
-> 관련 키워드: AWS RDS, Google Cloud SQL for MySQL, ZAURE Database for MySQL - programing: 데이터베이스를 부품으로해서 여러 것들은 만듦. 웹 애플리케이션의 데이터를 분석하는데 쓰이거나 함. 그러기 위해선 큰 틀의 여러 프로그래밍 언어가 필요함. 그 프로그래밍 언어로 데이터베이스 서버에 sql을 던질 수 있는 방법을 알아야함.
-> Python mysql api, Java mysql api 등...
