한줄 요약 : 단순히 비정상성을 감소시켜 과도한 정상화를 초래하는 이전 연구들과 달리, 시계열의 정상성을 높이고 내부 메커니즘을 개선하여 비정상 정보를 다시 통합함으로써 데이터 예측 가능성과 모델의 예측 능력을 동시에 향상시키는 효율적인 방법을 제안
[ 요약 ]
- 목적 : 비정상적인 현실 세계 데이터, 즉 시간에 따라 결합 분포가 변화하는 데이터에서 성능 어떻게 높일 것인가?
- 기존 방법 : 시계열 데이터를 정상화하여 비정상성을 줄이고 예측 가능성을 향상시키는 방법
- 발생 문제 : 정상화 과정에서 고유한 비정상성이 제거되면, 실제 발생하는 급격한 사건을 예측하는 데 있어 덜 유용 ⇒ 'over-stationarization ' : 과도한 정상화
- Transformer 모델이 시계열 데이터에 대해 구별할 수 없는 temporal attention을 생성하게 되어 예측 능력 저하
- 기존 방법 : 시계열 데이터를 정상화하여 비정상성을 줄이고 예측 가능성을 향상시키는 방법
- 제안 방법 : 'Non-stationary Transformer'라는 프레임워크
- 구성 : 'Series Stationarization'와 'De-stationary Attention'라는 두 개의 상호 의존적인 모듈로 구성
- Series Stationarization: 추가 매개변수 없이 각 시계열 입력 간의 통계적 특성 정렬에 초점을 맞추어 Transformer가 분포 외 데이터에 대해 일반화할 수 있도록
- De-stationary Attention: 비정상화되지 않은 데이터의 attention mechanism을 근사화 ⇒ 고유한 비정상 정보를 temporal dependencies으로 복원
- 정상화된 시계열의 높은 예측 가능성 & 원래 비정상 데이터에서 발견된 중요한 temporal dependencies를 활용할 수 있음
- 평가 결과 : 주요 Transformer 모델의 MSE를 Transformer에서 49.43%, Informer에서 47.34%, Reformer에서 46.89% 줄이며, 시계열 예측에서 좋은 성능 발성
[ 기여점 ]
- 기존의 정상화 접근 방식이 over - stationarization 문제를 초래하여 Transformer 모델의 예측 능력을 제한한다는 사실을 발견
- 'non-stationarity Transformer'를 제안: 시계열을 더 예측 가능하게 만드는 'Series Stationarization' & 원래 시계열의 비정상성을 다시 통합하여 과도한 정상화 문제를 방지하는 'De-stationary Attention'이 포함
- 제안한 구조는 네 가지 주요 Transformer 모델의 성능을 크게 향상시키며, 여섯 가지 실제 사례에서 최첨단 성능을 달성
[ 문제 정의 ]
- 비정상 시계열은 시간에 따라 통계적 특성과 결합 분포가 지속적으로 변화하는 특징이 있어 예측이 어려움
- 이전 연구에서는 시계열 데이터를 정상화하여 전처리하는 것이 일반적인 방법으로 인식 ⇒ over-stationarization 발생 가능
- '직접 정상화(direct stationarization)' 는 예측 가능성을 높이기 위해 시계열의 비정상성을 완화할 수 있지만, 실제 세계의 시계열이 가지고 있는 고유한 특성들을 간과해서 over-stationarization 발생
- over-stationarization은 트랜스포머가 의미있는 시간적 의존성 포착을 실패하게 만들수도 있고 /모델의 예측 능력을 제한시키거나 /정답과 편차가 큰 아웃풋을 만들게 유도할 수 있음
- 예측 성능을 높이기 위한 해결해야 할 과제 :
- 1) 시계열의 non-stationarity 을 어떻게 약화시키고
- 2) over - stationarization 문제를 어떻게 경감할지
[ 관련 연구 ]
1) Deep Models for Time Series Forecasting
- RNN 기반 모델: 장기 의존성을 모델링하는 한계
- Transformer: 시퀀스 모델링에서 강력한 성능
- 시퀀스 길이에 따라 계산 복잡도가 기하급수적으로 증가하는 문제 존재
- 후속 연구들은 Self-Attention의 복잡성을 줄이는 데 초점
- 시계열 예측에서 Informer는 KL-divergence 기준을 사용해 주요 쿼리를 선택하고, Reformer는 Local-Sensitive Hashing(LSH)를 도입해 유사한 쿼리들을 할당함으로써 attention 근사화
- 이 논문은 기존의 아키텍처 설계에 초점을 맞춘 연구들과 달리, 시계열 예측 과제를 정상성이라는 기본적인 관점에서 분석
- 정상화는 시계열의 예측 가능성에 중요한 속성으로, 현실의 시계열은 항상 비정상성을 보임
2) Stationarization for Time Series Forecasting
- Adaptive Norm: 샘플링된 집합의 전역 통계를 사용해 각 시계열 조각에 대해 z-score 정규화 적용
- DAIN: 비선형 신경망을 사용해 관찰된 훈련 분포에 맞추어 시계열을 적응적으로 정상화
- RevIN: 모델 입력과 출력을 각각 변환하여 각 시리즈의 차이를 줄이는 두 단계의 인스턴스 정규화 도입
[ 제안한 방법 구조 ]
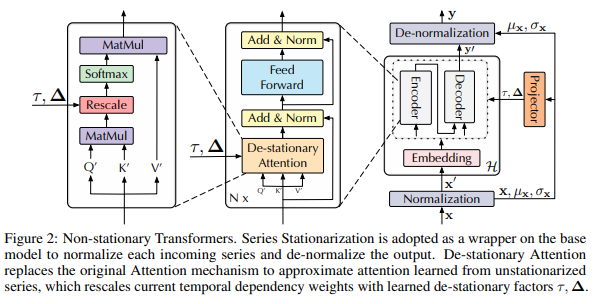
1) Series Stationarization
-
(1) Normalization module
-
시간 축을 따라 슬라이딩 윈도우 방식을 사용하여 정상화를 수행
-
정규화 모듈 공식 :
- S와 C는 각각 시퀀스의 길이와 변수의 수
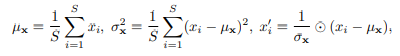
- 입력 시계열 간의 분포 차이를 줄여 모델 입력의 분포를 보다 안정적
- S와 C는 각각 시퀀스의 길이와 변수의 수
-
-
(2) De-normalization module
- model H가 길이 O의 미래 값을 예측한 후 비정상화 과정을 통해 모델 출력을 변환
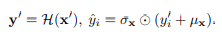
- 이중 변환을 통해, 기본 모델은 안정적인 분포를 따르는 정상화된 입력을 받아 더 일반화하기 쉬워짐
- 시계열의 평행 이동과 스케일링 변화에 대하여 모델을 동등하게 만들어, 실제 시계열 예측에 유리하게 함
2) De-stationary Attention
-
기존 문제점 :
- 1) 각 시계열의 통계 특성을 명시적으로 예측에 반영하더라도, 비정상적인 원래 시계열은 비정규화만으로는 완전히 복구될 수 없음
- 2) 비정상적인 시계열 데이터가 정규화되어 동일한 평균과 분산을 가진 여러 시계열 조각으로 분할될 때, 지나치게 정상적이고 특이사항이 없는 출력을 생성할 가능성이 높아짐
-
지나친 정상화화 문제를 해결하기 위해 “정상화 없이 얻은 Attention을 근사”하고, “원래 비정상 데이터에서 특정 시간적 의존성을 발견할 수 있는 메커니즘”을 제안
-
(1) Analysis of the plain model
-
고유의 비정상적 정보를 사라지게 하는 것으로 부터 과도한 정상화 문제가 발생함.
-
기존 비정상적인 시계열의 Attention을 근사
- 정상화 모듈 이후, 모델은 정상화된 입력 x′=(x−1μx⊤)/σx를 받음
- 모든 요소가 1인 벡터임. 선형 특성 가정에 기반하여, Attention 레이어는 Q’= (Q − 1µ⊤Q)/σx 를 얻게 됨
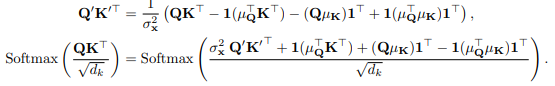
-
정상화된 시계열 데이터를 기반으로 attention을 계산하는 과정
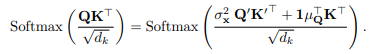
- Q′,K′는 정상화된 입력에서 얻은 것이며, 추가적인 항목들이 이를 조정하여 원래의 비정상화된 데이터에서의 attention 계산을 근사
- Softmax 함수는 입력의 행 방향으로 동일한 변환에 대해 불변이기 때문에, 변환된 형태의 Q와 K를 사용해도 원래의 결과를 유지
-
-
(2) De-stationary Attention
-
(5) 번 식에 의거하여 핵심은 양의 스케일링 스칼라 1) 과 시프팅 벡터 2) 를 근사하는 것
-
깊은 모델에서 선형 특성은 거의 유지되지 않기 때문에, 실제 요인을 추정하고 활용 X
-
비정상화인 x, Q, K의 통계로부터 비정상화 요인을 MLP 레이어를 통해 직접 학습하려고 함
- Q′, K′로부터는 제한된 비정상적 정보를 발견할 수 있기 때문에, 비정상성을 보완할 수 있는 방법은 정규화되지 않은 원래의 x를 사용하는 것
-
De-stationary Attention 계산 식 :
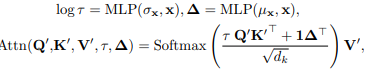
-
1) 과 2)는 모든 레이어에서 비정상적 어텐션을 수행하기 때문에, 비정상적 어텐션 매커니즘은 시간적 의존성을 정상적 시계열인 Q′, K′과 비정상적 시계열인 x, µx, σx에서 학습하고 정상화된 값 V’에 곱함
-
즉 정상화된 시계열의 예측 가능성에서 이점을 얻으면서 원시 시계열의 고유한 시간적 의존성을 동시에 유지 가능
-
-
(3) 전체 아키텍쳐 설명
- 인코더는 과거 관측에서 정보를 추출
- 디코더는 과거 정보를 집계하여 단순한 초기화에서 예측을 정제
- 일반적인 비정상 Transformer는 표준 Transformer의 입력과 출력 모두에 시계열 정상화를 적용하고, Self-Attention을 제안된 비정상 Attention으로 대체하여 기본 모델의 비정상 시계열 예측 능력을 향상
- Transformer 변형 모델들 [17, 37, 35]에 대해서는 Softmax(·) 내부의 항목들을 비정상 요인 τ, Δ로 변환하여 비정상 정보를 다시 통합
-
[ 실험 ]
- 6개 벤치마크 데이터를 활용해서 제안한 프레임 워크를 평가함
- 데이터 셋 :
- Electricity, ETT, Exchange, ILI, Traffic, Weather
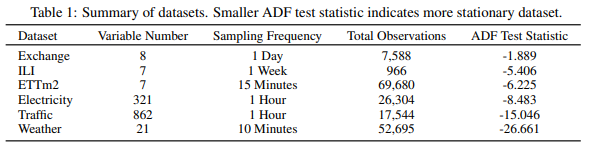
- Electricity, ETT, Exchange, ILI, Traffic, Weather
- 실험 설정:
- PyTorch / single NVIDIA TITAN V 12GB GPU / ADAM 옵티마니저를 사용해 L2 loss 최소화 하도록 학습 / 초기 학습률 : 10−4 / batch size : 32/ 각 트랜스포머 모델은 2개의 인코더 레이어와 한개의 디코더 레이어로 구성/ 하이퍼파라미터 검색의 효율성을 고려하여 De-stationary Attention에서 히든 차원이 {64, 128, 256}으로 설정된 2층 퍼셉트론 투영기를 사용
- 평가 방법:
- 각 실험은 서로 다른 랜덤 시드로 세 번 반복, 다양한 예측 길이(O = 96, 192, 336, 720)에서 테스트
- 전력 소비량 예측에서는 O = 96일 때 96시간 후의 전력 소비량을 예측하는 것을 뜻함
- MSE/MAE와 표준 편차
- 각 실험은 서로 다른 랜덤 시드로 세 번 반복, 다양한 예측 길이(O = 96, 192, 336, 720)에서 테스트
[ 평가 결과 ]
- Non-stationary Transformer를 사용한 결과를 다양한 벤치마크와 예측 길이에서 평가
- 예측 결과 :
-
다변량 예측 결과 에 따르면, 제안한 프레임워크를 탑재한 기본 Transformer 모델은 모든 벤치마크와 예측 길이에서 일관되게 좋은 성능
-
특히, 비정상성이 높은 데이터셋에서 다른 딥러닝 모델들보다 뛰어난 성과 보임
-
예를 들어, 예측 길이가 336인 경우 Exchange 데이터셋에서 17% MSE 감소(0.509 → 0.421), ILI 데이터셋에서 25% 감소(2.669 → 2.010)를 달성
구체적인 결과:
-
다양한 예측 길이(O = 96, 192, 336, 720)에서의 다변량 및 단변량 예측 결과는 표 2와 표 3에 요약
-
모델별로 적용된 프레임워크에 따른 성능 향상을 보여줌. 평균적으로, Transformer, Informer, Reformer, Autoformer 모델에서 각각 49.43%, 47.34%, 46.89%, 10.57%의 성능 향상을 달성
-
특히, 비정상성이 강한 데이터셋(Exchange, ILI, ETTm2 등)에서 더 큰 성능 개선을 확인가능
-
Ablation Study
- 품질 평가 :
- TTm2 데이터셋에 대해 세 가지 모델인 기본 Transformer, Series Stationarization만 적용한 Transformer, 그리고 Non-stationary Transformer의 예측 결과를 비교
- 비정상 정보를 다시 통합하는 접근 방식을 탐색하기 위해, 학습된 µ(평균)과 σ(표준편차)를 피드포워드 레이어에 다시 통합하는 실험을 진행
- 실험 결과는 비정상 정보를 attention에 다시 통합하는 데 있어 우리의 설계가 효과적임을 추가로 검증
[ 비판적 사고(comment) ]
- Non-stationarity가 모델 성능에 끼치는 영향을 정량적으로 잘 분석
- 주요 baseline에 대한 성능 비교가 robust하게 잘 이루어짐
- 이미 성능 극대화가 진행된 Benchmark 데이터셋 외 Distribution shift나 Non-stationarity가 강한 실제 데이터셋에 대한 강건성 역시 추후 검증 필요
