강의 제목 : 머신러닝 & AI 첫걸음 시작하기
3주차
- Naive Bayes Classifier를 이해하고, 코드를 통해 예제를 풀 수 있다.
- KNN(K-Nearest Neighbors Algorithm)을 이해하고, 코드를 통해 예제를 풀 수 있다.
- SVM(Support Vector Machine)을 이해할 수 있다, 코드를 통해 예제를 풀 수 있다.
- 의사결정나무(Decision Tree)를 이해하고, 코드를 통해 예제를 풀 수 있다.
1. Naive Bayes
- 데이터가 각 클래스에 속할 때 특징을 가질 확률(조건부확률)에 기반한 분류 알고리즘.
- 장점 : 간단하고 빠르며 효율적이다.
- 단점 : 모든 특징이 독립이라는 가정이 아닌 경우일 때 적절하지 않다.
- 설명변수
- 연속형 : Gaussian naive bayes classifier
- 이항형 : Bernoulli naive bayes classifier
- 다항형 : Multinomial naive bayes classifier
2. KNN(K-Nearest Neighbors Algorithm)
- 유클리디안 거리 계산법을 이용하여 가까운 개의 다른 데이터를 참조하여 분류하는 알고리즘
- 장점 : 단순하고 효율적
- 단점 : 적절한 를 결정할 수 있어야 한다. 차원의 저주
- 종속변수
- 연속형 : k-nearest neighbors 평균으로 추정
- 범주형 : k-nearest neighbors 중 가장 많이 나타나는 로 추정
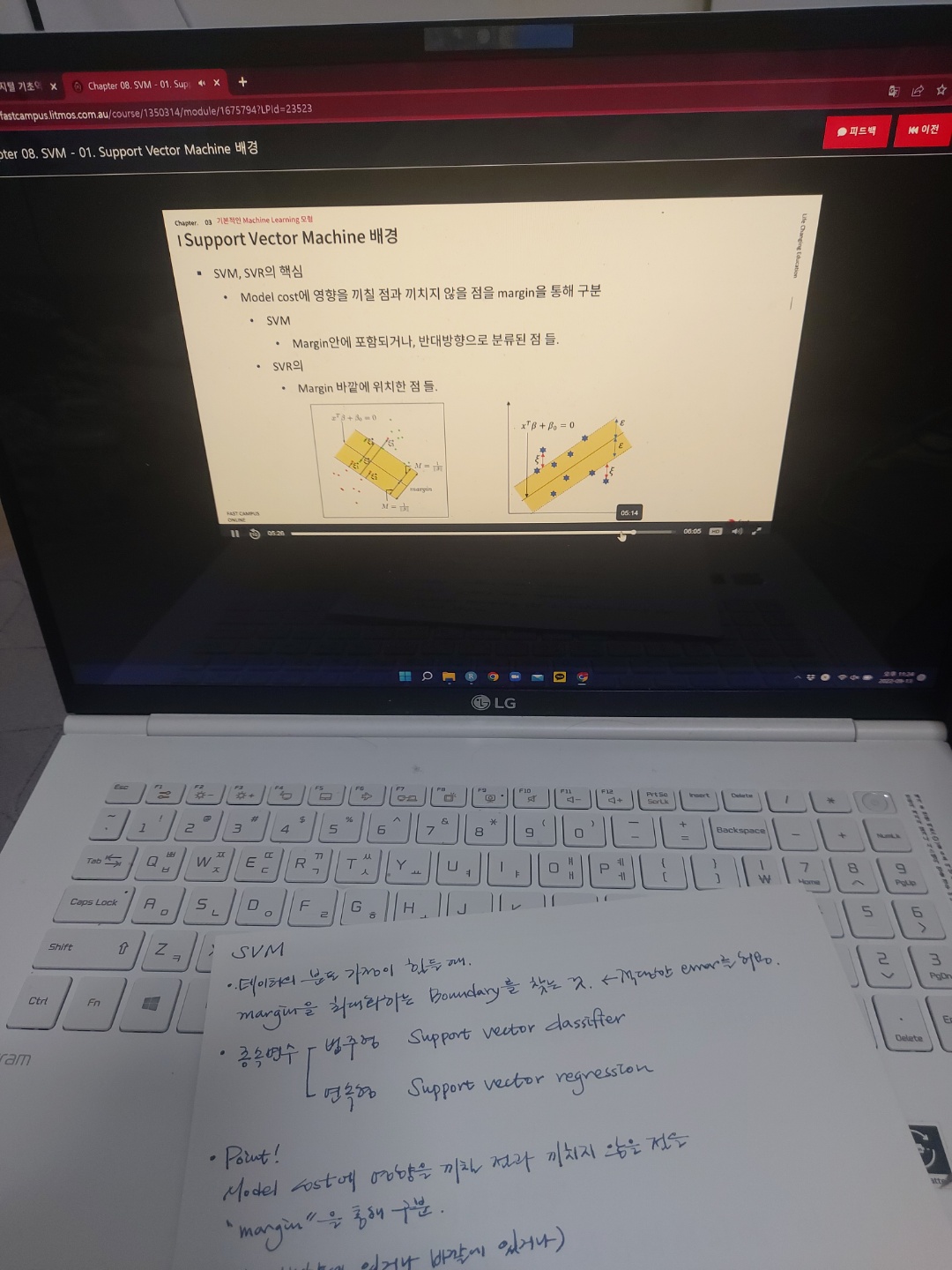
3. SVM(Support Vector Machine)
- 데이터의 분포 가정이 힘들 때, Margin을 최대화하는 Boundary를 찾는 알고리즘.
- 장점 : 범주나 수치 예측 문제에 사용이 가능하다.
- 단점 : 최적의 모형을 찾기 위해 여러 개의 테스트가 필요하다.
- 종속변수
- 연속형 : Support vector regression (SVR)
- 범주형 : Support vector classifier
4. 의사결정나무(Decision Tree)
- 변수들로 기준을 만들고 이를 통해 샘플을 분류하여 집단의 성질로 추정하는 모형
- 장점 : 해석력이 높다. 직관적이다.
- 단점 : 변동성이 크다. 샘플에 민감하다.
- 종속변수
- 연속형 : 회귀(Regreesion) 트리
- 범주형 : 분류(Classification) 트리
느낀점
수학적인 개념에 대해 확실히 이해해야 겠다.
코드를 통해 직접 눈으로 확인하니까 더 재미있었다.
내가 다른 데이터들을 찾아 활용할 수 있을지에 대해서도 고민해봐야겠다.

김나래입니다.