
주제
- 저시력자를 위한 원화 화폐 분류
목표
- Object Detection을 위한 Data Preprocessing(1일차)
- Implement YOLO(2일차)
개인 목표
- yolo 모델에 대해 공부하기
1. 모델링
YOLOv5 불러오기
- git clone으로 YOLOv5를 colab에 복제
!git clone https://github.com/ultralytics/yolov5- '! 기호': colab에서 쉘 명령어를 실행하기 위한 특수한 명령어
사전학습 모델 불러오기
- YOLOv5 중 원하는 버전을 선택 -> YOLOv5n
!wget -O 파일명 URL주소- wget: URL로부터 파일을 다운로드하기 위한 명령어
- '-O 옵션': 다운로드한 파일을 지정된 파일명으로 저장하도록 지정
학습하기
- 어제 설정한 yaml 파일을 적용하여 학습 진행
- yaml 파일 만들기
!cd yolov5; python train.py \
--data '/content/drive/MyDrive/Datasets/money_images/money.yaml' \
--cfg '/content/yolov5/models/yolov5n.yaml' \
--weights '/content/yolov5/pretrained/yolov5n.pt' \
--epochs 1000 \
--patience 5 \
--img 640 \
--project 'trained' \
--name 'team_money' \
--exist-ok \
--cache ram \
--hyp hyp.scratch-low.yaml- 'money.yaml': 데이터셋 정보
- 'yolov5n.yaml': 모델 구조 정보
- 'yolov5n.pt': 사용할 모델의 가중치 파일
Augmentation 적용하기
- '--hyp.scratch-low.yaml' 파일에서 degree 설정을 바꾸고 적용
학습 결과
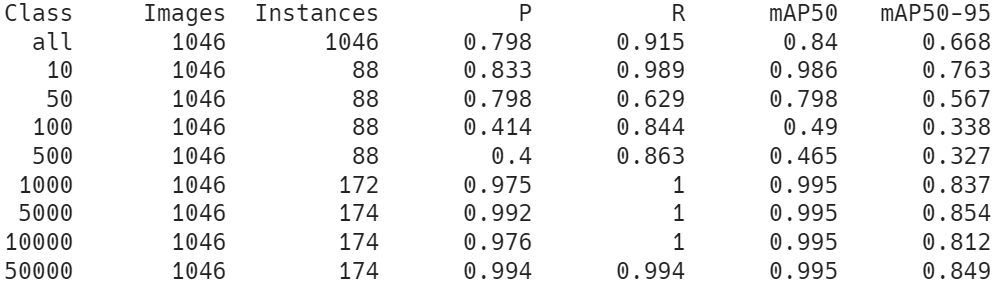
- Augmentation을 적용하기 전에는 mAP50이 0.9 이상을 기록
- 적용 후 학습 결과는 0.9를 넘지 않고 학습이 멈추었음
- patience를 늘리고 학습을 더 시킬 수도 있지만 시간, 컴퓨팅 단위 부족으로 학습 중단
탐지
- 탐지 과정에서 'conf-thres'와 'iou-thres'의 설정이 중요
- conf_thres(confidence threshold): 개체를 감지하는 신뢰도 임계값
- iou_thres(Intersection over Union threshold): 감지된 개체와 실제 개체의 IoU값이 이 임계값보다 큰 경우, 해당 개체를 감지한 것으로 간주
-
종류 의미 높을 때 낮을 때 conf_thres 객체 탐지를 위한 최소 확률값 정확하지만 적은 개체 감지 부정확하지만 더 많은 개체 감지 iou_thres 객체 간의 겹침 정도의 임계값 객체를 더욱 세분화하여 탐지 겹쳐진 객체를 하나의 객체로 인식
conf - 0.2 / iou - 0.7

- 하나의 객체에 다수의 클래스로 탐지

- 잘못된 객체를 탐지함

- 객체 탐지가 많이 되긴 하였으나, 정확도가 다소 떨어짐
conf - 0.5 / iou - 0.5

- 동전에 대해서 미탐지가 다수 발생

- 구겨진 지폐에 대한 conf값 0.61

- 부분 지폐에 대한 conf값 0.71

- 잘못된 탐지

- 지폐 탐지, 동전 미탐지

- 잘못된 탐지, 지폐가 아닌 것에 대한 conf값 0.51

- 정확한 탐지에 대한 최소 conf값 0.55
어려웠던 점
- Augmentation 적용 전에는 지폐에 대한 성능이 매우 떨어졌으나, 적용(이미지 회전) 후에는 다양한 상황에서 탐지가 가능해짐
- 공식 문서를 확인하는 것이 중요
- conf_thres, iou_thres를 조절하는 과정이 매우 어려웠음
- 약 20가지의 조합을 시도해보았으나, 완벽한 탐지는 불가능
- 이를 보완하기 위해서는 '더 나은 전처리'와 '더 나은 모델'일 것
마무리
- 모델링을 잘한다고 하더라도, 이번 프로젝트에서는 강사님이 강조한 것처럼 '전처리 과정'이 매우 중요
- 일반화 성능에 대한 고려 필요
- Augmentation을 적용 시, val score는 감소하였으나, 실제 데이터에 대해서는 더 좋은 성능을 보임
- 실제 데이터를 고려해서 다양한 regularization 기법이 필요 - 가장 작은 모델인 nano를 사용했음에도 불구하고 l,x,s,m과 성능에서 큰 차이를 보이지 않았음
- 모델의 버전(크기)와 속도는 trade-off 관계인 만큼, 주어진 상황, 자원에 맞게 적절한 모델을 선택하는 것 또한 중요

A smooth sea never made a skilled sailor