
목표
자바의 람다식에 대해 학습한다.
학습할 것
람다식(lambda expression)이란?
자바1.8버전에서 도입된 람다식으로 인해, 자바는 객체지향언어인 동시에 함수형 언어가 되었다.
람다식(lambda expression)은 메소드를 하나의 식으로 표현하여, 메소드를 간결하면서도 명확한 식으로 표현한다.
int[] arr = new int[5];
// 배열의 모든 요소를 인자로 전달받은 함수의 반환값으로 채운다.
Arrays.setAll(arr, () -> (int) (Math.random() * 5) + 1);위에서 () -> (int) (Math.random() * 5) + 1)가 바로 람다식이다.
이 람다식을 다시 메소드로 표현하면 다음과 같다.
int method() {
return (int) (Math.randome() * 5) + 1;
}람다식의 장점은
1. 간결하면서도 이해하기 쉽다.
2. 모든 메소드는 클래스에 포함되어야 하므로 클래스를 새로 만들어야하는데, 이 과정 없이 오직 람다식 자체만으로 메소드의 역할을 대신할 수 있다.
3. 메소드의 매개변수로 메소드를 전달할 수 있고, 메소드의 반환값으로 메소드를 반환할 수도 있다. 즉, 메소드를 변수처럼 다루는 것이 가능해진다.
💡 메소드를 람다식으로 표현하면 메소드의 이름과 반환 타입이 없어지므로, 람다식을 익명 함수(anonymous function)라고도 한다.
람다식 작성 방법
람다식은 익명 함수 답게 메소드의 이름과 반환타입을 제거하고, 매개변수 선언부와 구현부 사이에 -> 를 추가한다.
// 기존 메소드
반환타입 메소드이름(매개변수 선언) {
...
}
// 람다식으로 변경
(매개변수 선언) -> {
...
}다음은 두 값 중에서 큰 값을 반환하는 메소드를 람다식으로 변환하는 예시이다.
// 기존 메소드
int max(int a, int b) {
return a > b ? a : b;
}
// 람다식으로 변경
(int a, int b) -> {
return a > b ? a : b;
}특정 경우에는 더 간단한 형태로 변경할 수 있다.
-
첫째, 괄호(
{})안의 문장이 하나일 때는 괄호를 생략할 수 있다. 이 때 문장의 끝에;를 붙이지 않아야 한다.// before (String name, int i) -> { System.out.println(name + "=" + i); } // after (String name, int i) -> System.out.println(name + "=" + i) -
둘째, 반환 값이 있고 괄호(
{})안의 문장이 하나인 메소드의 경우, return문 대신 식(expression) 으로 대신할 수 있다.// before (int a, int b) -> { return a > b ? a : b; } // after (int a, int b) -> a > b ? a : b- 식의 연산결과가 자동적으로 반환값이 된다.
- 이때는 문장(statement) 이 아닌 식(expression) 이므로 끝에
;를 붙이지 않는다.
-
셋째, 매개변수의 타입이 추론 가능한 경우, 타입을 생략할 수 있다.
// before (int a, int b) -> a > b ? a : b // after (a, b) -> a > b ? a : b- 대부분의 경우 생략이 가능하다.
- 반환 타입을 생략하는 경우도 타입 추론이 가능하기 때문이다.
- 여러 매개변수 중 어느 하나의 타입만 생략하는 것은 허용하지 않는다.
-
넷째, 매개변수가 하나뿐인 경우, 괄호(
())를 생략할 수 있다. 단, 매개변수 타입이 있다면 괄호를 생략할 수 없다.//before (a) -> a < 0 ? -a : a // after a -> a < 0 ? -a : a
함수형 인터페이스(Functional Interface)
자바의 모든 메소드는 클래스 내에 포함되어야 하는데, 여태까지 람다식을 작성할 때 어떠한 클래스도 적어주지 않았다.
그렇다면 람다식은 어떤 클래스에 포함되는 것일까?
결론적으로, 람다식은 익명 클래스의 객체와 동등하다.
다음 예제를 살펴보자.
// max()라는 메소드가 정의된 인터페이스
interface MyFunction {
public abstract int max(int a, int b);
}
// 위의 인터페이스를 구현한 익명 객체 생성
Myfunction f = new Myfunction() {
public int max(int a, int b) {
return a > b ? a : b;
}
};
int big = f.max(5, 3); // 익명 객체의 메소드 호출위 코드에서 인터페이스를 구현한 익명 클래스의 객체를 생성하는 부분을 람다식을 사용하여 좀 더 간결하게 표현할 수 있다.
// max()라는 메소드가 정의된 인터페이스
interface MyFunction {
public abstract int max(int a, int b);
}
// 위의 인터페이스를 구현한 익명 객체를 람다식으로 생성
MyFunction f = (int a, int b) -> a > b ? a : b;
int big = f.max(5, 3);이처럼 MyFunction 인터페이스를 구현한 익명 객체를 람다식으로 대체가능했던 이유는 MyFunction 인터페이스는 추상 메소드 가 오직 하나만 정의(max())되어 있어 MyFunction의 메소드와 람다식을 1:1로 연결할 수 있었기 때문이다.
추상 메소드가 오직 하나만 정의되어 있고 람다식을 다루기 위한 인터페이스를 함수형 인터페이스라고 부르기로 했다.
함수형 인터페이스 작성 방법
@FunctionalInterface
interface MyFunction {
public abstract int max(int a, int b);
}-
함수형 인터페이스의 조건
- 추상 메서드가 오직 하나만 정의되어 있어야 한다.
- static 메소드와 default 메소드의 개수에는 제약이 없다.
@FunctionalInterface가 함수형 인터페이스가 되기 위한 조건을 만족했는지 컴파일 시점에 확인해준다.
- 추상 메서드가 오직 하나만 정의되어 있어야 한다.
-
함수형 인터페이스의 장점 - 코드가 간결하다.
List<String> list = Arrays.asList("abc", "aaa", "bbb", "ddd", "aaa"); // before Collections.sort(list, new Comparator<String>() { public int compare(String s1, String s2) { return s2.compareTo(s1); } }); // after Collections.sort(list, (s1, s2) -> s2.compareTo(s1));
java.util.function 패키지
함수형 인터페이스에 선언된 추상 메소드들은 목적만 다를 뿐 형식이 비슷하다.
여기서 형식이란 매개변수의 수, 반환 값 유무, 매개변수나 반환 타입(만약 제네릭 메소드로 정의하면)을 뜻한다.
@FunctionalInterface
interface MyFunction1 {
public abstract int max(int a, int b);
}
@FunctionalInterface
interface MyFunction2 {
public abstract int min(int a, int b);
}
@FunctionalInterface
interface MyFunction3 {
public abstract int multiple(int a, int b, int c);
}
...따라서 java.util.function 패키지에 일반적으로 자주 쓰이는 형식의 메소드를 함수형 인터페이스로 미리 정의해 놓았다.
매번 새로운 함수형 인터페이스를 정의하지 말고, 가능하면 이 패키지의 인터페이스를 활용하는 것이 좋다.
그래야 함수형 인터페이스에 정의된 메소드 이름도 통일되고, 재사용성이나 유지보수 측면에서도 좋다.
자주 쓰이는 가장 기본적인 함수형 인터페이스는 다음과 같다.
| 함수형 인터페이스 | 메소드 | 설명 |
|---|---|---|
java.lang.Runnable | void run() | 매개변수 ❌ 반환값 ❌ |
Supplier<T> | T get() | 매개변수 ❌ 반환값 ⭕ |
Consumer<T> | void accept(T t) | Suplier와 반대 매개변수 ⭕ 반환값 ❌ |
Function<T, R> | R apply(T t) | 일반적인 함수 매개변수 ⭕ 반환값 ⭕ |
Predicate<T> | boolean test(T t) | 조건식을 표현하는데 사용됨. 매개변수 ⭕ 반환값 ⭕(boolean) |
💡 타입 문자 T는 Type, R은 Return Type을 의미한다.
이제 각 함수형 인터페이스를 하나씩 살펴보자.
조건식의 표현에 사용되는 Predicate
조건식을 람다식으로 표현하는데 사용한다.
Predicate<String> isEmptyStr = s -> s.length() == 0;
String s = "";
if(isEmptyStr.test(s))
System.out.println("This is an empty String.");매개변수가 두 개인 함수형 인터페이스
매개변수의 개수가 2개인 함수형 인터페이스는 이름 앞에 접두사 Bi가 붙는다.
| 함수형 인터페이스 | 메소드 | 설명 |
|---|---|---|
BiConsumer<T, U> | void accept(T t, U u) | 매개변수가 두개인 Consumer |
BiPredicate<T, U> | boolean test(T t, U u) | 매개변수가 두개인 Predicate |
BiFunction<T, U, R> | R apply(T t, U u) | 매개변수가 두개인 Function |
- 세 개 이상의 매개변수를 갖는 함수형 인터페이스가 필요하다면, 다음과 같이 직접 만들어서 써야한다.
@FunctionalInterface interface TriFunction<T, U, V, R> { R apply(T t, U u, V v); }
Function의 또 다른 변형 - UnaryOperator와 BinaryOperator
Function + 매개변수의 타입과 반환타입이 모두 일치
| 함수형 인터페이스 | 메소드 | 설명 |
|---|---|---|
UnaryOperator<T, U> | T apply(T t) | Function의 자손 Function과 달리 매개변수와 결과의 타입이 같다. |
BinaryOperator<T, U> | T apply(T t, T t) | BiFunction의 자손 BiFunction과 달리 매개변수와 결과의 타입이 같다. |
기본형을 사용하는 함수형 인터페이스
지금까지 소개한 함수형 인터페이스는 매개변수와 반환값의 타입이 모두 제네릭 타입이었는데, 기본형 타입의 값을 처리할 때 wrapper 클래스를 사용했다.
하지만 기본형 대신 wrapper클래스를 사용하는 것은 비효율적이다.
그래서 보다 효율적으로 처리할 수 있도록 기본형을 사용하는 함수형 인터페이스들이 제공된다.
| 함수형 인터페이스 | 메소드 | 설명 |
|---|---|---|
AToBFunction( DoubleToIntFunction) | B applyAsB(A a)( int applyAsInt(double d)) | 입력은 A 타입, 출력은 B타입인 Function |
ToAFunction<T>( ToIntFunction<T>) | A applyAsA(T value)( int applyAsInt(T value)) | 입력은 제네릭, 출력은 A타입인 Function |
AFunction<R>( IntFunction<R>) | R apply(A a)( R apply(int i)) | 입력은 A타입, 출력은 제네릭인 Fuction |
ObjAConsumer<T>( ObjIntConsumer<T>) | void accept(A a, T t)( void accept(int i, T t)) | 입력은 제네릭과 A타입, 출력은 없는 Consumer |
그 밖에도 IntSuplier, IntConsumer 등 다양하다.
기본 함수형 인터페이스에서 추상메서드 외의 디폴트 메소드와 static 메소드
java.util.function 패키지의 함수형 인터페이스에는 추상메서드 외에도 default 메소드와 static 메소드가 정의되어 있다.
Function과 Predicate에 정의된 메소드만 살펴보고, 다른 함수형 인터페이스의 메소드는 이와 비슷하므로 넘어간다.
Function의 합성
수학에서 두 함수를 합성해서 하나의 새로운 함수를 만들어낼 수 있는 것처럼, 두 람다식을 합성해서 새로운 람다식을 만들 수 있다.
람다식f.andThen(람다식g)default <V> Function<T, V> andThen(Function<? super R, ? extends V> after)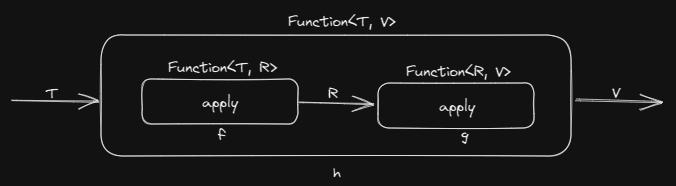
- 예제 - 문자열을 숫자로 변환하는 람다식 f와 숫자를 2진 문자열로 변환하는 람다식 g를 합성하여 새로운 람다식 h를 만든다.
Function<String, Integer> f = s -> Integer.parseInt(s, 16); Function<Integer, String> g = i -> Integer.toBinaryString(i); Function<String, String> h = f.andThen(g);
- 예제 - 문자열을 숫자로 변환하는 람다식 f와 숫자를 2진 문자열로 변환하는 람다식 g를 합성하여 새로운 람다식 h를 만든다.
람다식g.compose(람다식f)default <V> Function<V, R> compose(Function<? super V, ? extends T> before)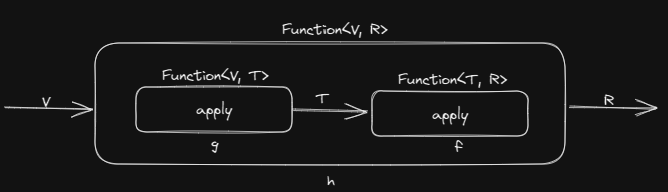
- 예제 - 문자열을 숫자로 변환하는 람다식 f와 숫자를 2진 문자열로 변환하는 람다식 g를 합성하여 새로운 람다식 h를 만든다.
Function<String, Integer> f = s -> Integer.parseInt(s, 16); Function<Integer, String> g = i -> Integer.toBinaryString(i); Function<Integer, Integer> h = f.compose(g);
- 예제 - 문자열을 숫자로 변환하는 람다식 f와 숫자를 2진 문자열로 변환하는 람다식 g를 합성하여 새로운 람다식 h를 만든다.
Function.identity()static <T> Function<T, T> identity()- f(x) = x 즉, 항등 함수가 필요할 때 사용
Function<Sring, String> f = x -> x; Function<String, String> f = Function.identity(); // 위의 문장과 동일- 잘 사용되지 않으며
map()으로 변환작업할 때, 변환없이 그대로 처리하고자할 때 사용한다.
Predicate의 결합
여러 조건식을 논리 연산자 &&(and), ||(or), !(not)로 연결해서 하나의 식을 구성하듯이, 여러 Predicate를 and(), or(), negate()로 연결해서 하나의 새로운 Predicate로 연결할 수 있다.
Predicate<Integer> p = i -> i < 100;
Predicate<Integer> q = i -> i < 200;
predicate<Integer> r = i -> i % 2 == 0;
Predicate<Integer> notP = p.negate();
// 100 >= i && && (i < 200 || i % 2 == 0)
Predicate<Intger> all = notP.and(q.or(r));
System.out.println(all.test(100));true또한, static 메소드인 isEqual()은 두 대상을 비교하는 Predicate를 만들 때 사용한다.
Predicate<String> p = Predicate.isEqual(str1);
boolean result = p.test(str2); // str1과 str2가 같은 지 비교하여 결과를 반환이제 java.util.function 패키지에 정의된 기본적인 함수형 인터페이스가 사용되는 곳을 살펴보자.
컬렉션 프레임워크와 함수형 인터페이스
컬렉션 프레임워크의 인터페이스에 디폴트 메소드가 추가되었는데, 그 중의 일부는 함수형 인터페이스를 사용한다.
다음은 그 메소드들의 목록이다.
| 인터페이스 | 메소드 | 설명 |
|---|---|---|
Collection | boolean removeIf(Predicate<E> filter) | 조건에 맞는 요소를 삭제 |
List | void replaceAll(UnaryOperator<E> Operator) | 모든 요소를 변환하여 대체 |
Iterable | void forEach(Consumer<T> action) | 모든 요소에 작업 action을 수행 |
Map | V compute(K key, BiFunction<K, V, V> f) | 지정된 키의 값에 작업 f를 수행 |
V computeAbsent(K key, Function<K, V> f) | 키가 없으면, 작업 f 수행 후 추가 | |
V computeIfPresent(K key, BiFunction<K, V, V> f) | 지정된 키가 있을 때, 작업 f 수행 | |
V merge(K key, V value, BiFunction<V, V, V> f) | 모든 요소에 병합 작업 f를 수행 | |
void forEach(BiConsumer<K, V> action) | 모든 요소에 작업 action을 수행 | |
void replaceAll(BiFunction<K, V, V> f) | 모든 요소에 치환 작업 f를 수행 |
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(i);
}
// list의 모든 요소 출력.
list.forEach(i -> System.out.print(i + ","));
System.out.println();
// list에서 2 또는 3의 배수 제거.
list.removeIf(x -> x%2 == 0 || x%3 == 0);
System.out.println(list);
// list의 각 요소에 10을 곱함.
list.replaceAll(i -> i*10);
System.out.println(list);
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", "2");
map.put("3", "3");
map.put("4", "4");
// map의 모든 요소를 {k, v}의 형식으로 출력한다.
map.forEach((k, v) -> System.out.print("{" + k + ", " + v + "}, "));
System.out.println();0,1,2,3,4,5,6,7,8,9,
[1, 5, 7]
[10, 50, 70]
{1, 1}, {2, 2}, {3, 3}, {4, 4}, 메소드 참조(method reference)
지금까지 람다식으로 메소드를 매우 간단하게 표현해왔다.
하지만 람다식이 하나의 메소드만 호출하는 경우, 메소드 참조라는 방법으로 람다식을 더욱 더 간단하게 표현할 수 있다.
예를 들어 문자열을 정수로 변환하는 람다식은 아래와 같다.
Function<String, Integer> f = (String s) -> Integer.parseInt(s);이 람다식이 하는 일은 단지 값을 받아서 Integer.parseInt()로 넘겨주는 것만 하고 있다.
따라서 아래와 같이 메소드 참조로 더욱 더 간단하게 표현할 수 있다.
Function<String, Integer> f = Integer::parseInt;컴파일러는 생략된 부분을 우변의 parseInt 메소드의 선언부로부터, 또는 좌변의 Function 인터페이스에 지정된 제네릭 타입으로부터 쉽게 알아낼 수 있다.
방금 본 예시는 Static 메소드 참조이다.
static 메소드 참조이외에도 인스턴스 메소드 참조, 특정 객체 인스턴스 메소드 참조가 존재한다.
| 종류 | 람다 | 메소드 참조 |
|---|---|---|
| static 메소드 참조 | (x) → ClassName.method(x) | ClassName::method |
| 인스턴스 메소드 참조 | (obj, x) → obj.method(x) | ClassName::method |
| 특정 객체 인스턴스 메소드 참조 | (x) → obj.method(x) | obj::method |
-
인스턴스 메소드 참조
다음은 두 개의 문자열을 받아서boolean을 반환하는 람다식이다.// 메소드 참조로 변경하기 전 BiFunction<String, String, Boolean> f = (s1, s2) -> s1.equals(s2); // 메소드 참조로 변경한 후 BiFunction<String, String, Boolean> f = String::equals;두 개의 문자열을 받아서
boolean을 반환하는 메소드는 다른 클래스에도 존재할 수 있기 때문에equals앞에 클래스 이름은 필수이다. -
특정 객체 인스턴스 메소드 참조
- 이미 생성된 객체의 메소드를 람다식에서 사용한 경우, 클래스 이름 대신 그 객체의 참조변수를 적어줘야 한다.
MyClass obj = new MyClass(); // 메소드 참조로 변경하기 전 Function<String, Boolean> f = (x) -> obj.equals(x); // 메소드 참조로 변경한 후 Function<String, Boolean> f2 = obj::equals;
생성자의 메소드 참조
생성자를 호출하는 람다식도 메소드 참조로 변환할 수 있다.
// 메소드 참조로 변경하기 전
Supplier<MyClass> s = () -> new MyClass();
// 메소드 참조로 변경한 후
Supplier<MyClass> s = MyClass::new;배열을 생성할 때는 다음과 같이 한다.
// 메소드 참조로 변경하기 전
Function<Integer, int[]> f = x -> new int[x];
// 메소드 참조로 변경한 후
Function<Integer, int[]> f2 = int[]::new; Variable Capture
멤버 메소드 내부에서 생성한 객체가 멤버 메소드 내부의 지역 변수를 사용할 경우는 다음의 문제를 발생시킨다.
멤버 메소드 내부에서 생성한 객체는 멤버 메소드의 실행이 끝난 이후에도 heap 영역에 존재하므로 사용할 수 있지만,
멤버 메소드 내부의 지역 변수는 멤버 메소드 실행이 끝난 이후에는 stack 영역에서 사라져 사용할 수 없다.
따라서 멤버 메소드 실행이 끝난 후에 객체가 멤버 메소드의 지역 변수를 호출할 경우에는 문제가 생긴다.
@FunctionalInterface
interface MyFunction {
void method();
}
class VariableCapture {
MyFunction returnFunction() {
int val = 30;
MyFunction f = () -> {
System.out.println(val); // 객체 내부에서 returnFunction() 메소드의 지역 변수인 val 를 사용한다.
}
return f;
}
}
class VariableCapturePractice {
public void main(String[] args) {
VariableCapture vc = new VariableCapture();
MyFunction f = vc.returnFunction();
f.method(); // returnFunction() 메소드 실행이 끝난 후므로 해당 메소드의 지역 변수인 val은 사라진 상태이다. 따라서 error 발생
}
}이런 문제를 방지하기 위해 자바는 Variable Capture라는 것을 수행한다.
Variable Capture는 컴파일 시점에 멤버 메소드의 지역 변수를 멤버 메소드 내부에서 생성한 객체가 사용할 경우 객체 내부로 값을 복사해서 사용한다.
하지만 모든 값을 복사해서 사용할 수 있는 것은 아니며 어느정도 제약이 존재한다.
그러므로 람다식의 실행 코드 블록 내에서는 클래스의 멤버 필드와 멤버 메소드는 특별한 제약 없이 사용 가능하지만, 지역변수를 사용함에 있어서는 제약이 존재한다.
어떤 제약이 있는것일까?
멤버 메소드 내부의 지역변수가 final 키워드로 작성 되었거나, final 키워드로 선언된 것은 아니지만 값이 한 번만 할당 되어야 한다.
왜냐하면 값을 이미 복사했는데 이후에 값이 변경이 가능할 경우 문제가 발생하기 때문이다.
Reference
- 자바의 정석 3rd Edition, 남궁성 지음
- 15주차 : 람다식
