-
RNN(순환신경망)
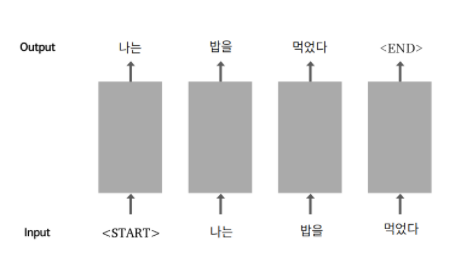 RNN에
RNN에 <start>라는 특수한 토큰을 맨 앞에 추가해서 문장의 시작을 알린다. 예를들어, '나는'이라는 단어가 나오면 확률적으로 높은 단어가 다음에 연결되고 계속해서 순환적으로 연결되는 구조이다. 문장이 끝이나면 인공지능이<end>라는 특수한 토큰을 생성한다.입력데이터(문제지):
<start>나는 밥을 먹는다.
출력데이터(답안지): 나는 밥을 먹는다.<end>1. 데이터를 불러온다.
import glob import os,re import numpy as np import tensorflow as tf txt_file_path = os.getenv('HOME')+'/aiffel/lyricist/data/lyrics/*' txt_list = glob.glob(txt_file_path) row_corpus=[] for txt_file in txt_list: with open(txt_file,'r') as f: raw=f.read().splitlines() raw_corpus.extend(raw)glob를 이용하여 모든 txt 파일을 읽어온 후 raw_corpus 리스트에 문장 단위로 저장한다.
-
append VS extend
a=[1,2,3]
a.append([4])
a=[1,2,3,[4]]
리스트로 추가됨a=[1,2,3]
a.extend([4])
a=[1,2,3,4]
원소로 추가됨2. 데이터 전처리
1) 정제함수
소문자로 변경, 공백 처리, 특수문자 처리, 특수토큰 추가
def preprocess_sentence(sentence): sentence = sentence.lower().strip() sentence = re.sub(r"([?.!,¿])", r" \1 ", sentence) sentence = re.sub(r'[" "]+', " ", sentence) sentence = re.sub(r"[^a-zA-Z?.!,¿]+", " ", sentence) sentence = sentence.strip() sentence = '<start> ' + sentence + ' <end>' return sentence모델의 입력이 되는 문장 : source sentence - x_train
모델의 출력이 되는 문장 : target sentence - y_train2) 정제된 문장들 모으기
corpus = [] for sentence in raw_corpus: #raw_corpus는 문장 단위로 저장한 리스트 # 공백이거나 : 일 경우 건너뛰기 if len(sentence) == 0: continue if sentence[-1] == ":": continue preprocessed_sentence = preprocess_sentence(sentence) corpus.append(preprocessed_sentence)3) 토큰화하기
def tokenize(corpus): #corpus는 정제된 문장들의 리스트 tokenizer = tf.keras.preprocessing.text.Tokenizer( num_words=12000, filters=' ', oov_token="<unk>) tokenizer.fit_on_texts(corpus) # corpus를 Tensor로 변환하기(숫자로 변환한 데이터) tensor = tokenizer.texts_to_sequences(corpus) # 입력데이터의 시퀀스를 padding으로 맞춰주기, 최대 토큰 길이는 15 tensor = tf.keras.preprocessing.sequence.pad_sequences(tensor,maxlen=15, padding='post') print(tensor,tokenizer) return tensor, tokenizer4) tensor로 입력문장, 출력문장 정의하기
src_input=tensor[:,:-1] tgt_input=tensor[:,1:]출력문장은
<start>를 포함하면 안되기때문에 인덱스 1부터 시작하게했고, 입력문장은 출력문장과 배열을 같게 해주기 위해 슬라이싱해줬다.
입력문장의 마지막은 0으로 padding되어있을 가능성이 높아서 슬라이싱 해줘도 된다.5) 데이터셋 객체 생성하기
tf.data.Dataset객체는 텐서플로우에서 사용할 경우 데이터 입력 파이프라인을 통한 속도 개선 및 각종 편의 기능을 제공한다.
BUFFER_SIZE=len(src_input) BATCH_SIZE=256 steps_per_epoch=BUFFER_SIZE/BATCH_SIZE VOCAB_SIZE=tokenizer.num_words+1 dataset=tf.data.Dataset.from_tensor_slices((src_input,tgt_input)) dataset=dataset.shuffle(BUFFER_SIZE) dataset=dataset.batch(BATCH_SIZE,drop_remainder=True) dataset
완벽한 shuffle을 위해 데이터 세트의 전체 크기보다 크거나 같은 BUFFER_SIZE가 필요하다.
전체 트레이닝 데이터를 통째로 신경망에 넣으면 비효율적이기때문에 BATCH_SIZE를 통해 트레이닝셋을 작게 여러번 나눈다.
tokenizer가 구축한 단어사전과 여기 포함되지 않은
<pad>도 포함하기 위해 VOCAB_SIZE에 1을 더했다.
tf.data.Dataset.from_tensor_slices()를 이용해 corpus 텐서를 tf.data.Dataset객체로 변환했다.
3. 인공지능 학습시키기
1) 평가 데이터셋 분리
from sklearn.model_selection import train_test_split
enc_train, enc_val, dec_train, dec_val = train_test_split(src_input,
tgt_input,
test_size=0.2,
random_state=32)2) 모델 만들기
- 모델 구조
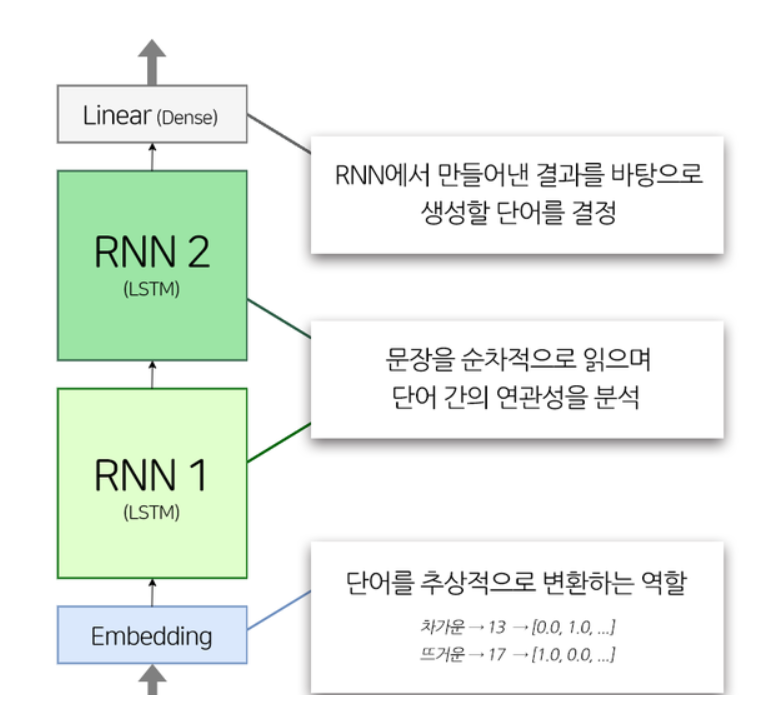
1개의 Embedding 레이어, 2개의 LSTM 레이어, 1개의 Dense 레이어로 구성
class TextGenerator(tf.keras.Model):
def __init__(self, vocab_size, embedding_size, hidden_size):
super().__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_size)
self.rnn_1 = tf.keras.layers.LSTM(hidden_size, return_sequences=True)
self.rnn_2 = tf.keras.layers.LSTM(hidden_size, return_sequences=True)
self.linear = tf.keras.layers.Dense(vocab_size)
def call(self, x):
out = self.embedding(x)
out = self.rnn_1(out)
out = self.rnn_2(out)
out = self.linear(out)
return out
embedding_size = 256
hidden_size = 1024
model = TextGenerator(tokenizer.num_words + 1, embedding_size , hidden_size)embedding_size 는 단어가 추상적으로 표현되는 크기이다
예를들어 embedding_size=2 일때, 저런식으로 표현할 수 있다.차갑다: [0.0, 1.0]
뜨겁다: [1.0, 0.0]
미지근하다: [0.5, 0.5]
hidden_size는 모델에 얼마나 많은 일꾼을 두느냐로 볼 수 있다.
3)학습시키기
optimizer = tf.keras.optimizers.Adam()
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True,
reduction='none')
model.compile(loss=loss,optimizer=optimizer)
model.fit(dataset,epochs=10)4. 평가하기
여기서 평가한다는 것은 인공지능에게 작문을 시켜보고 우리가 직접 평가하는 것이다. generate_text 함수를 만들어 모델에게 시작 문장을 전달하면 모델이 시작 문장을 바탕으로 작문을 진행을 한다.
1)작문 함수 만들기
def generate_text(model,tokenizer,init_sentence='<start>',max_len=20):
test_input = tokenizer.texts_to_sequences([init_sentence])
test_tensor = tf.convert_to_tensor(test_input, dtype=tf.int64)
end_token = tokenizer.word_index["<end>"]
while True:
predict = model(test_tensor)
predict_word = tf.argmax(tf.nn.softmax(predict, axis=-1), axis=-1)[:, -1]
test_tensor = tf.concat([test_tensor, tf.expand_dims(predict_word, axis=0)], axis=-1)
if predict_word.numpy()[0] == end_token: break
if test_tensor.shape[1] >= max_len: break
generated = ""
for word_index in test_tensor[0].numpy():
generated += tokenizer.index_word[word_index] + " "
return generated2)작사시켜보기
generate_text(model, tokenizer, init_sentence="<start> you raise", max_len=20)
good!!
