이번 편에서는 model 후보로 올라온 ViT와 efiicientNet에 대해서 소개하고자 한다.
ViT
우선 Transformer가 무엇인지 알아야한다. Transformer는 2017년 구글이 발표한 "Attention is all you need"에서 나온 모델로 RNN을 사용하지 않고, Attention만을 이용하여 인코더-디코더 구조로 설계되었다. (참고)
ViT는 Vision Transfomer의 약자로, Vision 관련 Task에 Transformer 구조를 사용한 것을 말한다. AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE을 시작으로 많은 ViT 모델이 SOTA를 달성하고 있다. 논문에 대한 리뷰는 여기에서 잘 설명하고 있으니 참고하기 바란다.
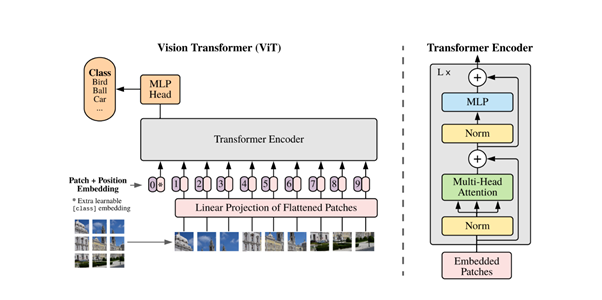
전체적인 동작은 간단하다. 이미지를 정해진 크기로 쪼개고, Patch Embedding을 통해 Position 정보를 유지한 채로 1차원으로 만든다. 이를 Transformer Encoder의 입력으로 넣는다. 출력을 MLP Head에 넣어 Classification한다.
ViT는 Lage Dataset을 사전학습 한 뒤 작은 task에 대해서 fine-tuning을 할 경우 충분히 훌륭한 결과를 볼 수 있다는 점이다. 또한, 사전학습보다 fine-tuning에 사용하는 image의 해상도가 높을 경우 더 좋은 성능을 보인다.

우리가 ViT에 기대하는 부분은 Transformer 기반이기 때문에 이미지에서 음식에 집중(attention) 하는 것이다.
efficientNet
efficientNet은 2019년에 발표된 EfficientNet, Rethinking Model Scaling for Convolutional Neural Networks 논문에서 소개된 모델이다. 기존 CNN에서 layer의 개수인 depth, filter의 개수인 width, input image의 resolution 3가지의 요소를 모두 고려해 모델의 크기를 scaling up하는 scaling compound method를 사용한다.
논문에서는 제한된 resource 내에서 앞서 말한 3가지 요소의 효율적인 조합을 어떻게 찾을지 연구한다.
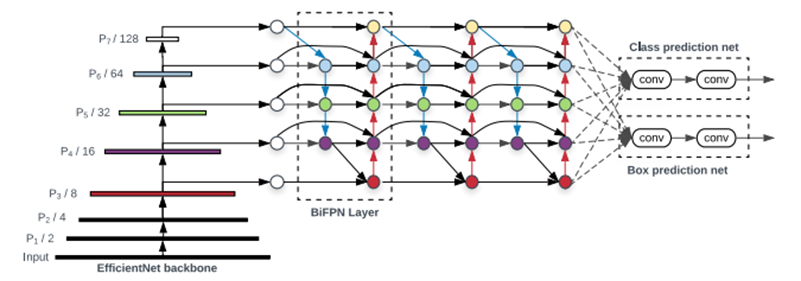
efficientNet은 stage를 나누고 각 stage마다 동일한 CNN을 수행한다.
적은 수의 parameter로 높은 수준의 정확도를 보이는 효율적인 모델이다.
