OpenSource 읽어보기
제가 open source project 를 선정하는 방식
간단하게 관심있는 opensource 코드들을 읽어보고 분석해보는 시리즈입니다.
리뷰할 Opensource 선정하는 방식은 대부분
1. 제가 관심있는 주제를 고르고
2. 그 주제를 구현한 Rust/Java/Kotlin 오픈소스들을 찾고
3. 이 중 가장 코드가 이해하기 쉽게 정리되어 있거나 유명한(깃헙 스타...)걸 고르기
혹시 추천해주실수 있는 프로젝트가 있다면 제 메일(pandawithcat@gmail.com)으로 편하게 연락주시면 감사하겠습니다!
오늘의 주인공은 Failsafe-rs 입니다!
주제 설명하기
Fail safe의 개념은 말 그래도 매우 간단합니다! request를 처리하는 주체에서 모종의 이유로 에러가 발생했다면 이에 대해 "안전하게" request 실패를 해서 에러가 cascading 하는걸 방지하자! 의 아이디어입니다. 말 그래도 fail할꺼면 safe하게 하자가 그 요점이죠. 이 fail safe 의 개념은 monolithic 한 환경보다는 msa 환경에서 그 중요도가 강조됩니다. 마틴 파울러가 쓴 이 글에 잘 표현되어있는데 요약하자면 네트워크 통신을 통해서 client - supplier(응답을 제공해주는 서버라고 생각하시면 편합니다) 의 관계에서 만약 supplier 가 에러 상태에 있어서 답변이 늦어지는데 이런 리퀘스트들을 빠르게 종료해버리지 않으면 client 는 계속 request를 보내게 되고 상황이 더욱 악화되기 때문에 supplier를 circuit breaker 오브젝트로 감싼 다음 이 circuit breaker 는 지속적으로 supplier 의 request, response 상태를 확인하다가 만약 supplier 가 정상 상태가 아니면 이후 추가적인 request들에는 circuit breaker 가 빠르게 실패 response를 보내서 fail을 safe 하게 하는 방식입니다.
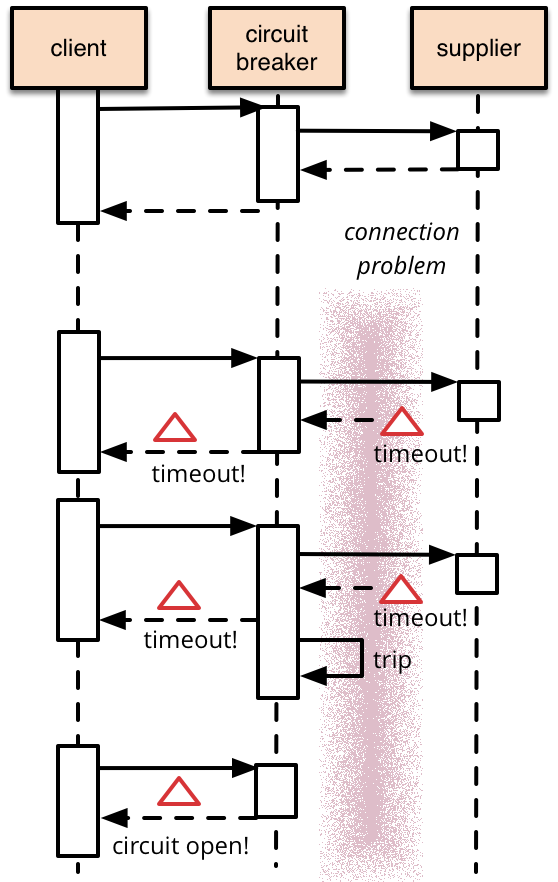
서킷브레이커는 일종의 statemachine 으로 closed, open, half-open 의 상태를 가지고 있습니다.
1. closed: 정상적으로 supplier가 동작하는 상태입니다.
2. open: 정상적으로 현재 동작하지 않는 상태이며 closed에서 특정 실패 임계치를 넘으면 open 상태로 전환합니다
3. half-open: open 후 일정 시간(reset timeout)이 지나면 half-open 상태가 됩니다. 접속을 시도하여 성공하면 closed, 실패하면 open으로 되돌아갑니다.
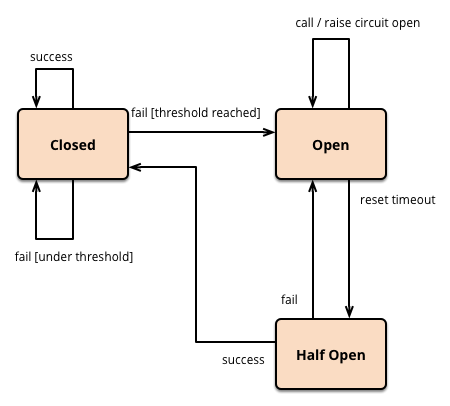
위 그림과 같이 request의 성공/실패 여부로 finite state machine에서 states를 왔다갔다하면서 현재 상태에 맞게 response 를 조절할수 있습니다.
코드 분석하기
간략한 코드 구조는 아래와 같습니다. 아래에서 각각의 파일을 하나씩 간단히 소개합니다.
📦src
┣ 📂futures
┃ ┗ 📜mod.rs
┣ 📜backoff.rs
┣ 📜circuit_breaker.rs
┣ 📜clock.rs
┣ 📜config.rs
┣ 📜ema.rs
┣ 📜error.rs
┣ 📜failure_policy.rs
┣ 📜failure_predicate.rs
┣ 📜instrument.rs
┣ 📜lib.rs
┣ 📜state_machine.rs
┗ 📜windowed_adder.rs
config.rs
Circuit breaker의 config 를 관리하는 모듈로서 Config struct 를 가지고 있는데 이 config struct 는 아래와 같은 구조입니다.
#[derive(Debug)]
pub struct Config<POLICY, INSTRUMENT> {
pub(crate) failure_policy: POLICY,
pub(crate) instrument: INSTRUMENT,
}즉, failure_policy 와 instrument 를 generic 으로 가지고 있는데
이 failsafe-rs 를 가져다 사용하는 입장에서는 결국 아래와 같은 코드를 작성하게 됩니다.
use std::time::Duration;
use failsafe::{backoff, failure_policy, CircuitBreaker}; // Create an exponential growth backoff which starts from 10s and ends with 60s.
let backoff = backoff::exponential(Duration::from_secs(10), Duration::from_secs(60)); // Create a policy which failed when three consecutive failures were made.
let policy = failure_policy::consecutive_failures(3, backoff); // Creates a circuit breaker with given policy.
let circuit_breaker = Config::new().failure_policy(policy).build();즉, backoff와 failure_policy 두개를 결정해서 Config를 만든 다음 build() 함수를 호출해서 내부적으로 circuit breaker state_machine을 만드는 구조입니다. 아래에서 코드를 볼때도 그 두 부분을 주의해서 보면 되는것을 알수 있습니다.
여기서 backoff 는 우리가 아는 그 backoff algorithm을 의미하고 policy 는 failure_policy를 의미하는데 이는 request들의 error rate를 판단해서 supplier의 상태를 판단하는 함수를 뜻합니다. 이는 아래 failure_policy.rs 에서 더 자세히 보실수 있습니다.
backoff.rs
여러 종류의 backoff strategy 의 구현들을 가지고 있습니다. 많이 쓰이는 constant, exponential, equal_jittered, full_jittered등의 방식들을 구현하고 있습니다.
failure_policy.rs
failure_policy는 위의 설명한대로 request들의 성공/실패 여부를 바탕으로 현재 supplier 의 상태를 판단하는데 쓰입니다. 이는 failure_policy trait 을 보면 명확히 이해할수 있습니다.
pub trait FailurePolicy {
fn record_success(&mut self);
fn mark_dead_on_failure(&mut self) -> Option<Duration>;
fn revived(&mut self);
fn or_else<R>(self, rhs: R) -> OrElse<Self, R>
where
Self: Sized,
{
OrElse {
left: self,
right: rhs,
}
}
}즉, 성공은 record_success로 기록하고 실패가 발생할 경우 mark_dead_on_failure를 통해서 만약 현재의 상황을 바탕(기준)으로 supplier가 dead인지 판단해서 그렇다면 backoff algorithm이 주는 backoff 하는 시간을 Some(값)으로 리턴합니다. 만약 실패지만 supplier가 dead라고 판단하지 않는다면 단순히 None을 리턴합니다.
그리고 backoff 만큼 쉰다음 다시 supplier가 정상으로 돌아왔다면 revived 함수를 통해서 스스로의 상태를 초기화(기준에 따라 완전 초기화일수도 있고 예전 숫자를 가지고 있을수도 있습니다)합니다.
이 라이브러리에서 제공하는 failure_policy들은 다음과 같습니다(자세한 계산법은 코드를 참조하시면 됩니다)
1. SuccessRateOverTimeWindow: ema를 사용해서 최신 성공 값들의 개수에 조금 더 비중을 둔 기준법이니다.
2. ConsecutiveFailures: maximum number of failure를 정해놓고 이를 넘어가면 supplier가 죽었다고 판단합니다.
ema.rs
exponential moving average(EMA) 를 사용하는 policy들 위해 EMA관련된 struct 와 함수의 모음입니다.
EMA 값은 대충 아래와 같은 방식으로 계산할수 있습니다.
EMA = (K x (C - P)) + P
Where:
C = Current Value
P = Previous periods EMA (A SMA is used for the first periods calculations)
K = Exponential smoothing constant
Period(window라고도 표현합니다)의 기준은 parameter 값으로 처음에 ema struct 생성시에 주입합니다.
clock.rs
실제 라이브러리에서는 사용되지 않지만 테스트 및 벤치마크에서 thread local storage 에 있는 mock clock을 사용해서 시간을 조절하면서 circuit breaker의 정상 작동을 확인하는 모듈입니다.
failure_predicate.rs
error가 발생했을때 이 error를 request 실패로 볼지를 판단하는 trait 인 failure_predicate를 가지고 있습니다. circuit breaker를 실제로 사용할때 이 trait을 구현하는 predicate를 사용해야 합니다. 자세한 건 아래 circuit_breaker.rs에서 예시와 함께 설명하겠습니다.
circuit_breaker.rs
Circuit breaker을 실제로 사용하기 위해서는 만들어진 위에서 언급했듯이 supplier를 circuit breaker 로 감싸야하는데 여기서 감싸는 방법들에 대해서 정의하고 있습니다.
핵심적인 함수는 call, 과 call_with 로 아래와 같습니다
#[inline]
fn call<F, E, R>(&self, f: F) -> Result<R, Error<E>>
where
F: FnOnce() -> Result<R, E>,
{
self.call_with(failure_predicate::Any, f)
}
fn call_with<P, F, E, R>(&self, predicate: P, f: F) -> Result<R, Error<E>>
where
P: FailurePredicate<E>,
F: FnOnce() -> Result<R, E>;이것만으로는 바로 사용법이 와닿지 않기 때문에 crate에 있는 아래의 예시를 한번 보시죠
use failsafe::{Config, CircuitBreaker, Error}; // A function that sometimes failed.
fn dangerous_call() -> Result<(), ()> {
if thread_rng().gen_range(0, 2) == 0 { return Err(()) } Ok(())
} // Create a circuit breaker which configured by reasonable default backoff and // failure accrual policy.
let circuit_breaker = Config::new().build(); // Call the function in a loop, after some iterations the circuit breaker will // be in a open state and reject next calls.
for n in 0..100 {
match circuit_breaker.call(|| dangerous_call()) {
Err(Error::Inner(_)) => { eprintln!("{}: fail", n); },
Err(Error::Rejected) => {
eprintln!("{}: rejected", n);
break;
},
_ => {}
}
}즉, call은 내부적으로 failure_predicate::Any를 사용해서 call_with를 부르게 되는데 failure_predicate::Any 는 디폴트 failure_predicate로 모든 에러에 대해 항상 참을 반환합니다(즉, 모든 에러는 request 실패입니다) 만약 custom failure_predicate을 사용한다면 바로 call_with를 사용해주면 됩니다. 이렇게 call, call_with 로 dangerous_call 같은 supplier 함수를 한번 감싸서 우리가 원하는 circuit breaker를 사용할수 있습니다.
instrument.rs
state machine 에 대한 instrumentation(markovian actions: on_call_rejected, on_open, on_half_open, on_closed)를 표현한 trait 인 Instrument 를 구현하고 있습니다.
state_machine.rs
위에서 계속 언급되었던 state_machine 에 대한 실제 구현이 있습니다. 하지만 사실 위에서 이미 state machine 내부 state 들 사이의 transtion 들을 다 설명했고 코드도 매우 명확해서 강조해서 볼만한 부분만 보도록 하겠습니다.
pub struct StateMachine<POLICY, INSTRUMENT> {
inner: Arc<Inner<POLICY, INSTRUMENT>>,
}
struct Inner<POLICY, INSTRUMENT> {
shared: Mutex<Shared<POLICY>>,
instrument: INSTRUMENT,
}
struct Shared<POLICY> {
state: State,
failure_policy: POLICY,
}state_machine은 내부적으로 Arc로 감싼 inner 를 들고 있고 inner는 내부에 mutex로 감싼 shared 를 들고 있습니다. 즉, 이를 통해서 우리는 이 failsafe-rs는 하나의 statemachine이 멀티쓰레딩 환경에서 동작할수 있도록 구현하려고 했다는 사실을 알수 있습니다. Arc<Mutex> 조합은 평소에도 많이 보는 조합이어서 많은 분들이 바로 눈치 채셨을것입니다.
futures/mod.rs
비록 rust초기에는 비동기에 대한 지원이 없었지만 2022년 현재 rust는 비동기를 적극적으로 지원하고 있는 언어입니다. 당연히 failsare-rs도 이러한 비동기 흐름에 맞추어서 비동기 context 에서 circuit breaker를 지원하고 있으며 이는 간단히 circuit_breaker trait 의 리턴 타입을 일반 함수에서 future로 감싸주기만 하면 됩니다.
fn call_with<F, P>(
&self,
predicate: P,
f: F,
) -> ResponseFuture<F, Self::FailurePolicy, Self::Instrument, P>
where
F: TryFuture,
P: FailurePredicate<F::Error>;
/// A circuit breaker's future.
#[pin_project]
pub struct ResponseFuture<FUTURE, POLICY, INSTRUMENT, PREDICATE> {
#[pin]
future: FUTURE,
state_machine: StateMachine<POLICY, INSTRUMENT>,
predicate: PREDICATE,
ask: bool,
}위와 같이 call_with 함수의 리턴타입이 responsefuture 로 바뀐것을 볼수 있으면 supplier 의 함수는 비동기로 쓰일수 있게 tryfuture 만 구현하고 있으면 됩니다(tryfuture이기 때문에 tokio, async-std 모두 사용이 가능합니다). Responsefuture는 당연히 future trait을 구현하고 있으면 poll 함수에 대한 내부 로직은 크게 어려울게 없어서 여기서는 생략하도록 하겠습니다.
windowed_adder.rs
Time windowed counter로 벤치마크를 사용할때 helper struct, function 으로 사용되는 helper들입니다. 단순 산수 계산이어서 여기서 다루지는 않겠습니다.
error.rs
해당 라이브러리에서 발생할수 있는 에러에 대한 wrapper type 입니다.
이 외에 Code 읽으면서 배운/복습한 개념들
Jitter
https://aws.amazon.com/ko/blogs/architecture/exponential-backoff-and-jitter/
일단 기본이 되는 backoff 알고리즘은 exponential backoff 이다. exponential을 코드로 간단하게 표현을 하면
fn exponential_backoff_seconds(attempt: u32, base: Duration, max: Duration) -> u64 {
((1_u64 << attempt) * base.as_secs()).min(max.as_secs())
}가 되는데 exponential을 사용했을 경우 backoff 하는 시간이 점점 길어져서 비효율적일수가 있다. 그래서 이 점을 보완해서 만든게 full_jittered인데 이는 수식으로 표현하면
let exp = exponential_backoff_seconds(self.attempt, self.start, self.max);
let seconds = self.rng.gen_range(0, exp + 1);즉, 0과 exponential 값 사이에서 랜덤하게 수를 선택해서 이 값만큼 쉬는걸 뜻한다.
다만 이렇게 되면 exponential backoff의 값이 커질수록 random 의 범위가 너무 커진 다는 단점이 있어서 이를 조금 상쇄시키고자 equal_jittered도 많이 사용하게 되는데 수식은 아래와 같다.
let exp = exponential_backoff_seconds(self.attempt, self.start, self.max);
let seconds = (exp / 2) + self.rng.gen_range(0, (exp / 2) + 1);즉, exponential 값의 절반을 고정으로 잡고 나머지는 0과 exponential값 절반 사이에서 랜덤으로 뽑아서 사용한다는 특징이 있다.
Thread Local Storage
https://docs.microsoft.com/en-us/cpp/parallel/thread-local-storage-tls?view=msvc-170
https://doc.rust-lang.org/std/thread/struct.LocalKey.html
Rust: How to create DLL
https://doc.rust-lang.org/reference/linkage.html
Reference
