6.1 스레드 동기화의 필요성
1. 문제 상황: 공유 데이터의 훼손
-
발생 가능성:
- 다수의 스레드가 동시에 공유 데이터에 접근 및 수정하면 데이터의 일관성이 깨질 수 있다.
-
주요 사례:
-
두 스레드가 동시에 공유 데이터를 읽을 경우
- 문제는 발생하지 않음(읽기-읽기 충돌 없음).
-
한 스레드는 데이터를 쓰고, 다른 스레드는 데이터를 읽을 경우
- 읽는 데이터가 불완전하거나 중간 상태일 가능성.
-
두 스레드가 동시에 데이터를 쓰는 경우
- 데이터가 훼손되거나, 의도하지 않은 값으로 변경될 위험.
-
-
예시:
- 회원의 은행 회비 계좌에 여러 스레드가 동시에 접근하여 입출금 작업을 수행하는 경우, 정확하지 않은 잔액이 기록될 수 있음.
2. 스레드 동기화(Thread Synchronization)
-
정의:
-
공유 데이터의 일관성을 유지하기 위해 다수의 스레드가 접근할 때 특정 규칙을 적용하는 기법.
-
배타적 독점(Mutual Exclusion)을 통해 데이터 접근을 순서대로 처리.
-
-
목적:
- 공유 데이터가 훼손되지 않도록 보호.
- 스레드 간 작업 순서 보장
📌공유 집계판에 동시에 접근하는 사례
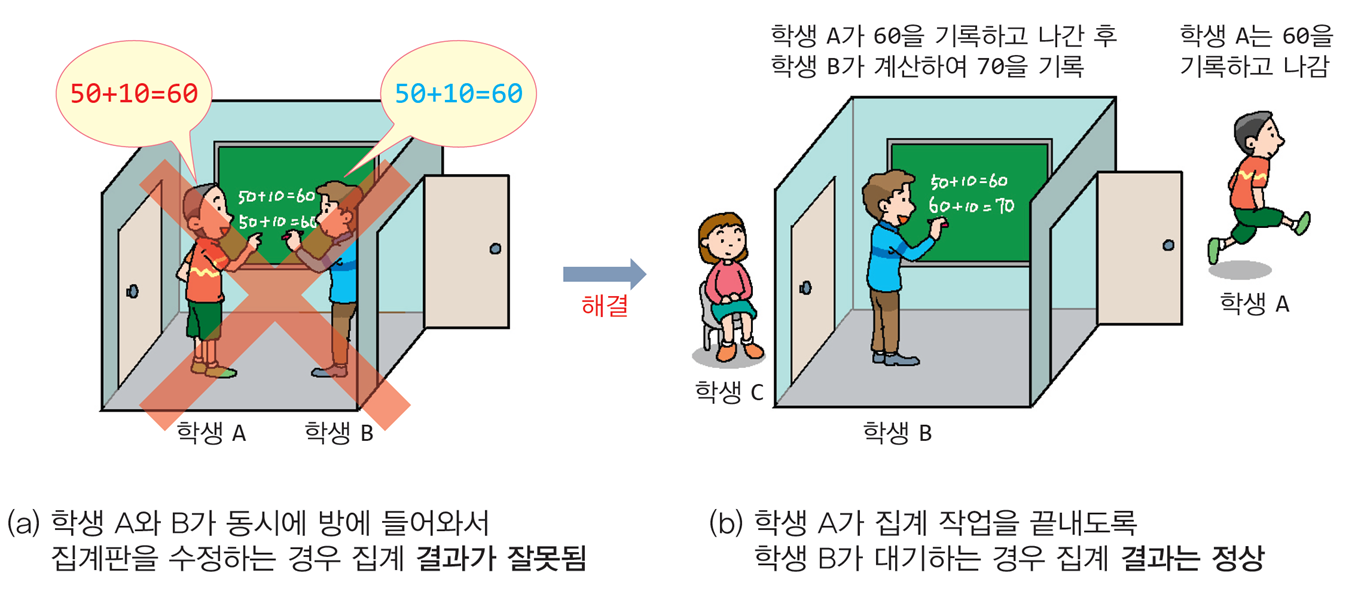
1. 문제 상황
-
상황: 학생들이 집계판에 10씩 더하는 작업을 수행.
-
동시 접근 문제:
-
학생 A와 학생 B가 동시에 방에 들어와 집계판의 데이터를 수정.
-
두 학생이 50에서 시작하여 각각 60으로 계산.
-
결과적으로 집계판에는 잘못된 값(60)이 기록됨.
-
-
이슈:
-
경쟁 상태(Race Condition) 발생.
-
두 스레드(학생)가 동시에 데이터를 수정하면서, 이전 작업 결과가 손실.
-
2. 해결 방법
-
배타적 접근(Mutual Exclusion):
- 한 번에 하나의 작업만 수행하도록 조정.
- 예시: 학생 A가 작업을 완료한 후 학생 B가 들어와 작업을 시작.
-
정상 동작:
- 학생 A가 60을 기록하고 방을 나감.
- 학생 B가 60을 읽은 후 70으로 계산하여 기록.
📌공유 집계판 문제를 프로그램으로 작성
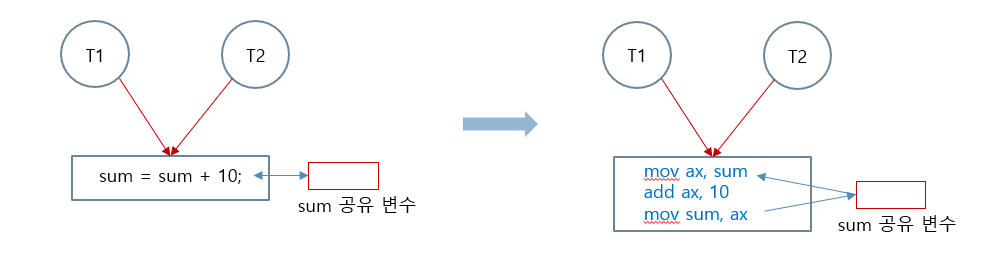
1. 코드 모델
-
참여자:
- 두 학생 = 스레드 T1, T2
- 공유 집계판 = 공유 변수
sum
-
계산식:
sum = sum + 10;- 현재
sum값에 10을 더한 결과를 다시sum에 저장.
2. 문제 상황
-
공유 변수 접근 과정:
-
각 스레드(T1, T2)는 다음 단계를 독립적으로 실행:
sum값을 읽어 레지스터에 저장.- 레지스터에 10을 더함.
- 계산된 결과를
sum에 저장.
-
-
문제 발생:
- T1과 T2가 동시에
sum을 읽는 경우, 동일한 값을 기반으로 계산. - 두 스레드가 계산한 결과가 덮어쓰여, 최종적으로 잘못된 값 저장.
- T1과 T2가 동시에
3. 어셈블리 코드 해석
-
동작 과정:
mov ax, sum: 공유 변수sum을ax레지스터로 복사.add ax, 10:ax값에 10을 더함.mov sum, ax: 계산된 값을 다시sum에 저장.
-
문제:
- 두 스레드가 동시에
mov ax, sum을 실행하면, 동일한 초기 값을 읽게 됨. - 이후 연산 결과가 충돌하며, 최종
sum값이 예상과 다르게 기록됨.
- 두 스레드가 동시에
📌T1과 T2 스레드가 공유 변수 sum에 동시에 접근할 때 발생하는 문제
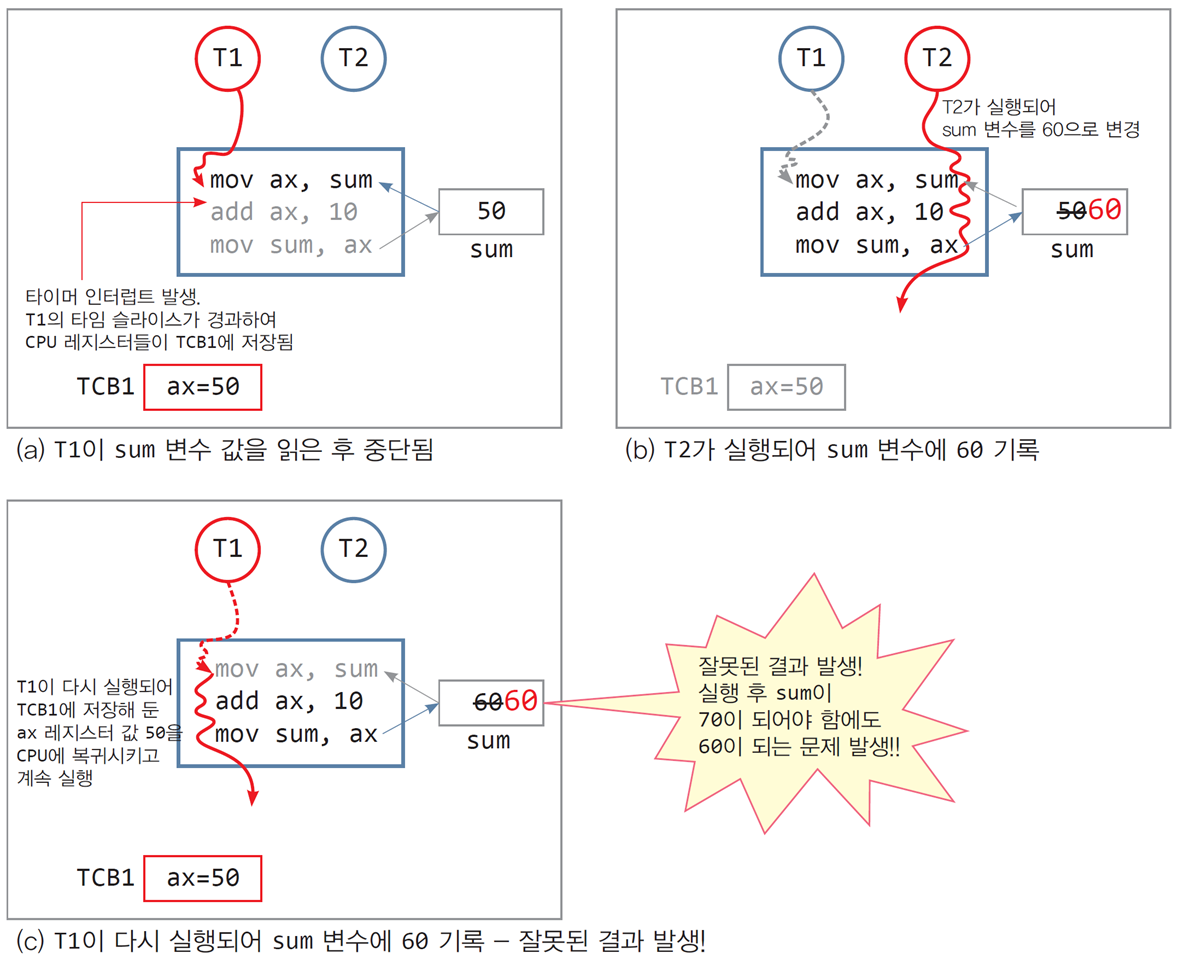
1. 문제 상황
-
T1과 T2 스레드는 공유 변수
sum에 각각 10을 더하는 작업을 수행. -
두 스레드가 동시에
sum을 수정하려 할 때, 결과가 의도한 값(70)이 아닌 잘못된 값(60)으로 기록될 수 있음.
2. 문제 발생 과정
(a) T1 실행 중단
-
T1이
sum값을 읽어 레지스터(ax)에 저장.- 현재
sum= 50. ax= 50으로 설정.
- 현재
-
T1의 실행이 타이머 인터럽트로 중단되고, CPU는 T1의 상태를 TCB1(Task Control Block 1)에 저장.
(b) T2 실행
- CPU가 T2를 스케줄링.
- T2는
sum을 읽고 60으로 계산한 뒤, 결과를sum에 저장.- 현재
sum= 60.
- 현재
(c) T1 재개
-
T1이 다시 실행되고, 이전에 저장된 상태(TCB1)를 복원.
-
레지스터에 남아 있던 값
ax = 50을 기반으로 sum = 60으로 다시 계산하고 저장.- 최종적으로
sum값이 60으로 덮어씌워짐.
- 최종적으로
3. 결과 및 문제점
-
의도한 결과:
- T1과 T2가 각각 10을 더해 70이 되어야 함.
-
실제 결과:
- 동시성 문제로 인해 최종 값이 60으로 잘못 기록됨.
4. 주요 원인
-
공유 자원 동시 접근:
- T1과 T2가 동일한
sum값을 읽고 수정 작업을 수행.
- T1과 T2가 동일한
-
타이머 인터럽트:
- T1이 작업을 마치지 못한 상태에서 T2가 작업을 시작.
📌공유 데이터 접근 문제와 해결책
1. 문제점
-
여러 스레드가 공유 변수에 접근할 때 데이터 무결성이 훼손될 수 있음.
- 스레드 간의 동시 접근으로 인해 데이터 충돌이 발생.
- 결과적으로 의도하지 않은 값이 기록될 가능성.
2. 해결책 - 스레드 동기화(Thread Synchronization)
-
핵심 아이디어:
- 한 스레드가 공유 데이터를 사용하는 동안 다른 스레드가 접근하지 못하도록 제한.
3. 멀티스레드의 경쟁 상황은 얼마나 자주 발생하는가?
-
매우 자주 발생:
-
사용자 프로그램:
- 멀티스레드를 사용하는 사용자 애플리케이션에서 빈번히 발생.
-
커널 코드:
- 운영체제의 커널 레벨에서 경쟁 상황이 자주 나타남.
-
다중 코어 환경:
- 현대의 다중 코어 프로세서 환경에서는 스레드 간의 충돌 가능성이 더욱 높아짐.
-
📌임계구역과 상호배제
1. 임계구역(Critical Section)
-
정의: 공유 데이터에 접근하는 코드 블록.
-
목적: 공유 데이터를 보호하고 데이터의 무결성을 보장.
-
예시:
sum = sum + 10;와 같은 코드가 공유 데이터에 접근하는 경우.
2. 상호배제(Mutual Exclusion)
- 정의: 임계구역을 한 번에 한 스레드만 접근하도록 보장하는 원칙.
3. 적용 예시
-
T1과 T2의 임계구역 접근:
-
T1: 임계구역(
sum = sum + 10;) 실행 중. -
T2: T1이 작업을 마칠 때까지 대기 → 상호배제 성공.
-
4. 공통 활용 사례
-
은행 시스템: 계좌 잔액을 업데이트할 때 발생할 수 있는 동시성 문제 해결.
-
파일 시스템: 여러 스레드가 동일한 파일에 쓰기를 시도하는 경우.
6.2 상호 배제 (mutual exclusion
📌상호 배제를 포함하는 전형적인 프로그램 구성
1. 일반 코드 (Non-critical Code)
-
정의: 공유 데이터를 액세스하지 않는 코드 블록.
-
특징:
- 임계구역 외부에서 실행.
- 동기화가 필요하지 않음.
2. 임계구역 진입 코드 (Entry Code)
-
정의: 임계구역에 들어가기 전 필요한 코드 블록.
-
기능:
- 현재 임계구역을 사용하는 스레드가 있는지 확인.
- 다른 스레드의 접근을 방지하여 상호 배제를 구현.
- 임계구역이 비어 있으면 진입, 그렇지 않으면 대기.
3. 임계구역 코드 (Critical Code)
-
정의: 공유 데이터에 접근하거나 조작하는 코드 블록.
-
중요성:
- 상호 배제를 보장하여 데이터 무결성을 유지.
- 단일 스레드가 실행하도록 제한.
4. 임계구역 진출 코드 (Exit Code)
-
정의: 임계구역을 나갈 때 실행되는 코드 블록.
-
역할:
- 대기 중인 스레드가 임계구역에 접근할 수 있도록 해제.
- 다음 스레드가 안전하게 임계구역에 접근할 수 있도록 상태 초기화.

프로그램 흐름
-
일반 코드 실행.
-
임계구역 진입 코드 실행 → 임계구역 진입 여부 확인.
-
임계구역 코드 실행 → 공유 데이터 접근.
-
임계구역 진출 코드 실행 → 진입 잠금 해제.
-
다시 일반 코드로 돌아감.
📌상호 배제 구현
상호 배제 구현 목표
-
임계구역에 오직 한 개의 스레드만 진입하도록 보장.
- 동시 접근 시 데이터 무결성 유지.
상호 배제 구현 방법
-
소프트웨어적 방법
- Peterson's 알고리즘 등.
- 소프트웨어 단에서 동기화 논리를 구현.
-
하드웨어적 방법
- 하드웨어의 도움을 받아 동기화를 구현.
- 효율적이며, 복잡한 동기화 문제를 해결.
하드웨어적 방법
-
인터럽트 서비스 금지
- 한 스레드가 실행 중일 때 인터럽트를 비활성화.
- 간단하지만 다중 CPU 환경에서는 비효율적.
-
원자 명령 (Atomic Instruction) 사용
-
CPU 명령으로 상호 배제를 보장.
-
원자 명령 예:
- Test-and-Set (TAS).
-
📌상호 배제 구현 방법 1 – 인터럽트 서비스 금지
방법 설명
-
인터럽트 서비스 금지 방법은 특정 임계구역 코드 실행 중 인터럽트를 비활성화하여, 다른 스레드가 CPU를 점유하지 못하도록 함.
- entry 코드: 인터럽트 금지 명령 실행 (
cli- clear interrupt flag). - exit 코드: 인터럽트 허용 명령 실행 (
sti- set interrupt flag).
- entry 코드: 인터럽트 금지 명령 실행 (
동작 과정
-
임계구역 진입 시:
cli명령어를 통해 인터럽트를 비활성화.- 다른 작업이나 스레드가 개입하지 못하게 함.
-
임계구역 종료 시:
sti명령어를 통해 인터럽트를 다시 활성화.- 정상적인 인터럽트 처리 가능.
문제점
-
모든 인터럽트가 무시됨:
- 인터럽트가 금지되면 긴급한 시스템 작업도 처리되지 못할 가능성이 있음.
- 시스템 전반적인 성능 저하 발생.
-
멀티 코어 환경에서 비효율적:
- 다중 CPU를 사용하는 현대 시스템에서 한 코어에서의
cli가 다른 코어에는 영향을 미치지 않음. - 동기화가 제대로 이루어지지 않을 수 있음.
- 다중 CPU를 사용하는 현대 시스템에서 한 코어에서의
📌인터럽트를 금지하지 않은 경우와 금지한 경우의 차이
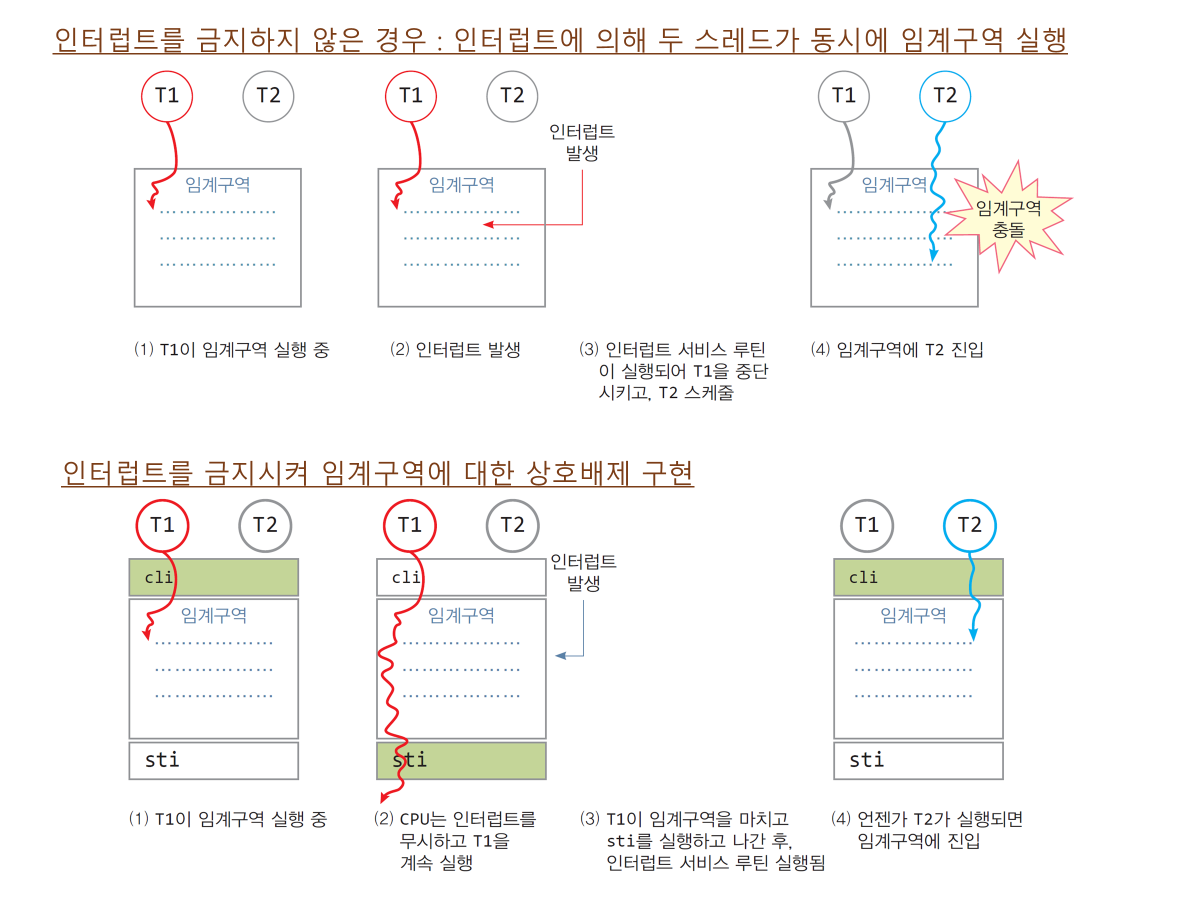
1. 인터럽트를 금지하지 않은 경우
-
문제 발생 과정:
-
T1이 임계구역 실행 중: T1 스레드가 임계구역의 코드를 실행.
-
인터럽트 발생: T1이 실행 중 인터럽트가 발생하여 CPU가 인터럽트 서비스 루틴으로 전환.
-
T2 스케줄링: T2 스레드가 임계구역에 진입.
-
임계구역 충돌: T1과 T2가 동시에 임계구역 코드를 실행하게 되어 데이터 충돌 발생.
-
2. 인터럽트를 금지한 경우
-
문제 해결 과정:
-
T1이 임계구역 실행 중: T1 스레드가
cli명령어를 통해 인터럽트를 금지하고 임계구역 코드를 실행. -
인터럽트 발생 무시: CPU는 인터럽트를 무시하며 T1이 임계구역 실행을 완료할 때까지 진행.
-
임계구역 종료: T1이
sti명령어로 인터럽트를 허용하며 임계구역 실행 종료. -
T2 스케줄링: 이후 T2가 스케줄링되어 임계구역에 진입.
-
차이점
-
인터럽트를 금지하지 않은 경우:
- 스레드 간 동기화 문제가 발생하여 데이터 손상이 생길 가능성이 높음.
-
인터럽트를 금지한 경우:
- 단일 스레드만 임계구역 코드를 실행하도록 보장하여 동기화 문제를 방지.
📌단순 Lock 변수를 이용한 상호배제 시도
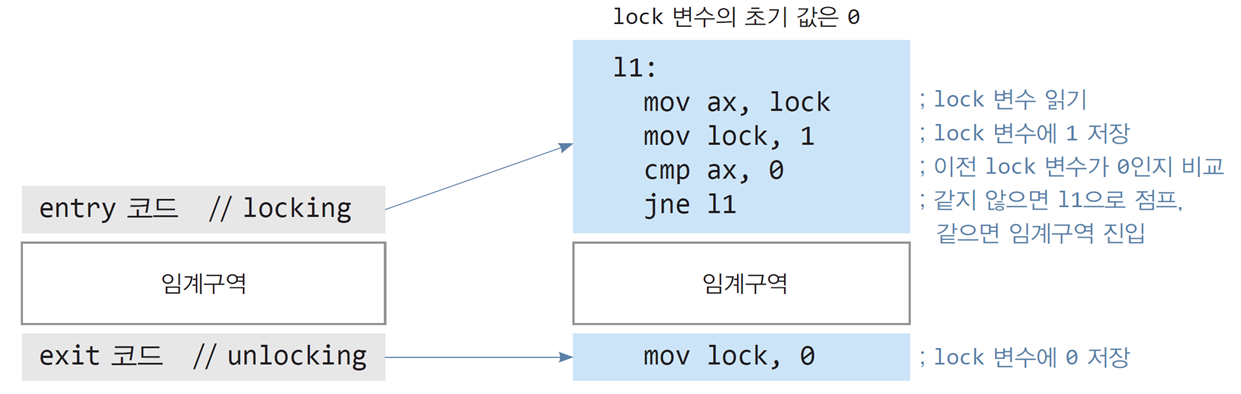
목표
- 임계구역에 진입할 때 Locking/Unlocking 방식으로 상호배제를 구현하고자 함.
Lock 변수의 동작 방식
-
Lock 변수의 초기값: 0 (열린 상태)
- Lock = 0: 진입 가능.
- Lock = 1: 다른 스레드가 이미 임계구역을 점유 중임.
-
Entry 코드 (Locking):
- Lock 변수를 읽고, 1로 설정.
- 이전 Lock 값이 0인지 확인.
- 0이면 임계구역 진입.
- 1이면 다른 스레드가 점유 중이므로 대기.
-
Exit 코드 (Unlocking):
- 임계구역 실행 종료 후 Lock 변수를 0으로 재설정.
코드 구현 예제
- Entry 코드:
l1: mov ax, lock ; lock 변수를 읽음
mov lock, 1 ; lock 변수에 1 저장
cmp ax, 0 ; 이전 lock 값이 0인지 비교
jne l1 ; 0이 아니면 다시 점검 (대기)-
임계구역 코드:
- 임계구역의 주요 작업 수행.
-
Exit 코드:
mov lock, 0 ; lock 변수를 0으로 해제문제점
-
경쟁 상태 (Race Condition):
-
Lock 값을 읽고 쓰는 과정이 두 스레드에서 겹치면 동시 접근 문제 발생 가능.
-
예: T1과 T2가 동시에
mov ax, lock을 실행하면, 둘 다 0으로 판단하여 임계구역에 동시 진입.
-
결론
-
단순 Lock 변수로 상호배제를 구현하면 경쟁 상태를 해결하지 못함.
-
해결책:
- 하드웨어적인 도움 (원자 명령, Test-and-Set 명령 등)
📌Lock 변수를 사용한 상호배제 성공 사례
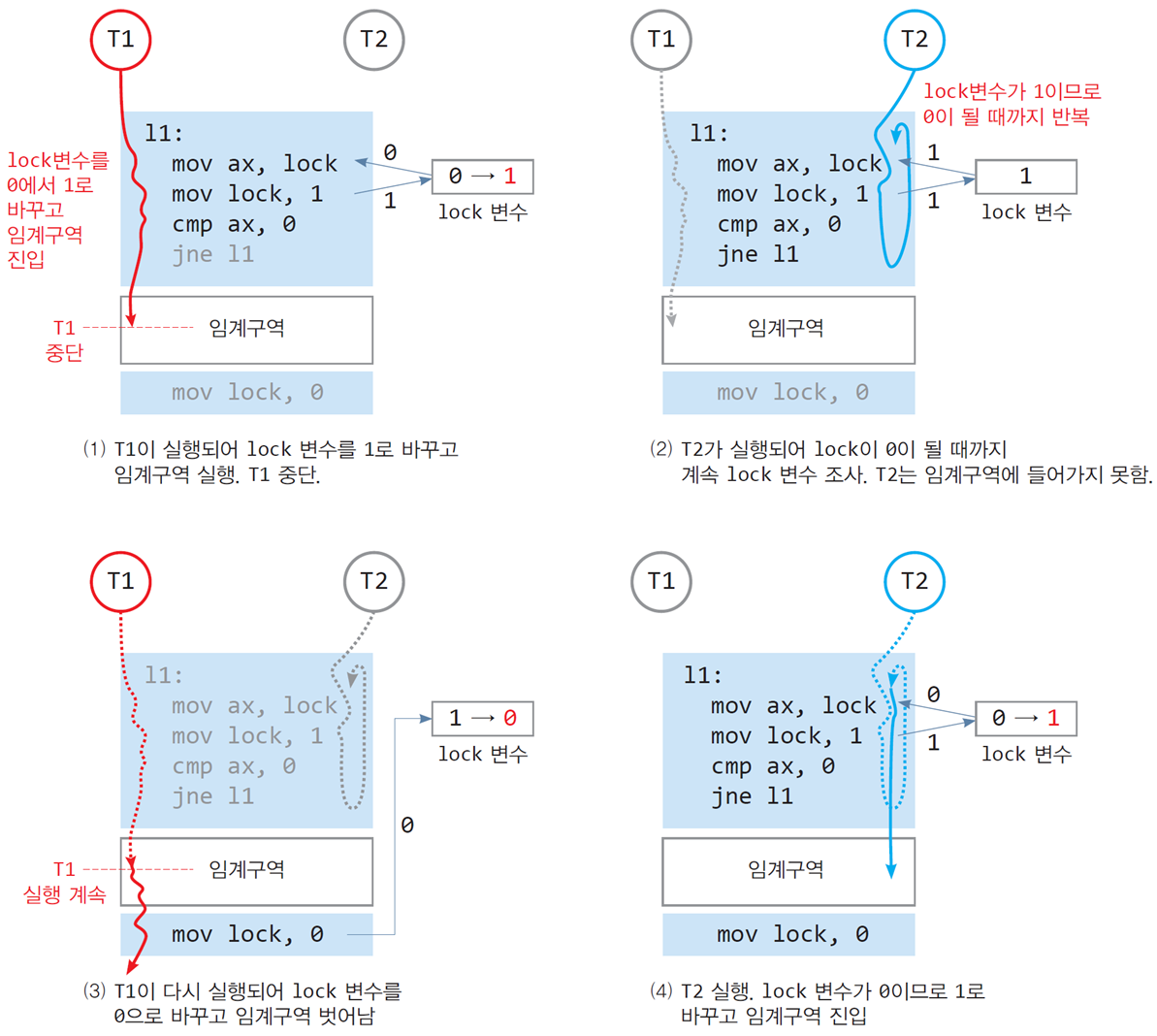
프로세스 흐름
-
T1의 임계구역 진입:
-
T1이
mov ax, lock을 실행해 lock 값을 읽음. -
lock 값이 0이므로
mov lock, 1을 실행하여 lock 값을 1로 설정. -
cmp ax, 0에서 lock이 0이 아니므로 임계구역에 진입.
-
-
T1 실행 중단 및 T2 대기:
-
T1이 임계구역을 실행하는 도중 CPU 스케줄러가 T2로 스위칭.
-
T2가
mov ax, lock으로 lock 값을 읽음. lock 값은 1. -
T2는 lock 값이 0이 될 때까지
jne l1로 대기.
-
-
T1 임계구역 종료 및 lock 해제:
- T1이 임계구역 실행을 종료하고 lock 값을 0으로 설정 (
mov lock, 0).
- T1이 임계구역 실행을 종료하고 lock 값을 0으로 설정 (
-
T2의 임계구역 진입:
-
T2가 lock 값이 0이 된 것을 감지하고
mov lock, 1로 설정. -
T2는 임계구역에 진입하여 실행.
-
-
성공적인 상호배제:
-
T1과 T2는 lock 변수의 상태를 바탕으로 번갈아 가며 임계구역에 진입.
-
lock 값이 0에서 1로 변경되고, 다른 스레드는 lock 값이 0이 될 때까지 대기.
-
-
장점:
-
단순한 구조로 임계구역 접근을 제어 가능.
-
한 스레드가 임계구역을 완료할 때까지 다른 스레드는 대기.
-
-
제한점:
-
lock 변수 조작 과정에서 원자성 보장이 필요.
-
경쟁 상태(race condition)가 발생할 경우 제대로 작동하지 않을 가능성.
-
📌Lock 변수를 사용한 상호배제 실패 사례
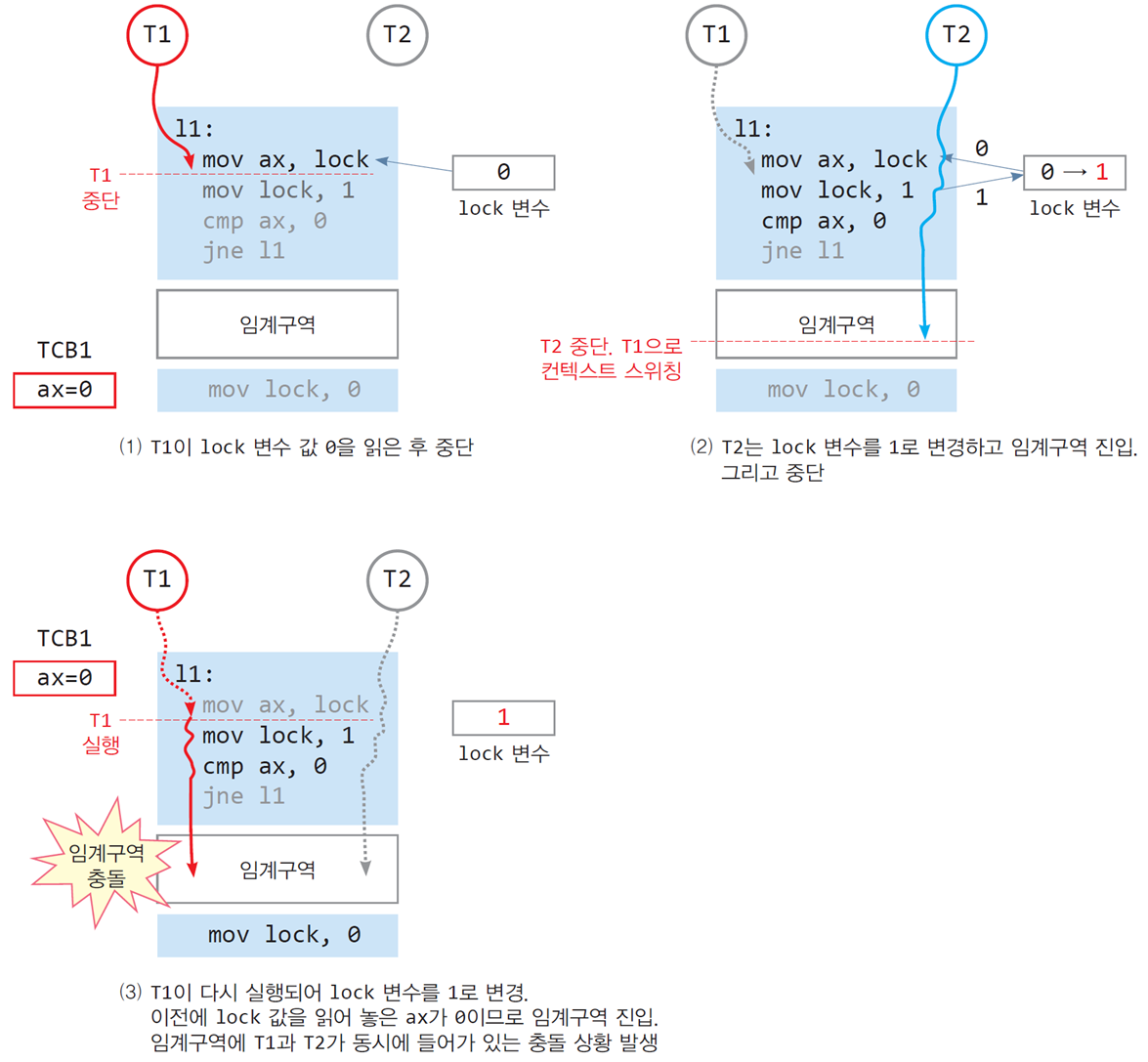
실패 상황의 흐름
-
T1 시작 및 Lock 변수 읽기:
-
T1이
mov ax, lock으로 lock 값을 읽음. -
lock 값은 0이며, T1은 lock 값을 1로 변경하려고 준비.
-
-
T1 중단 및 T2 시작:
-
T1이 lock 값을 1로 설정하기 전에 CPU 컨텍스트가 T2로 스위칭.
-
T2가
mov ax, lock을 실행하여 lock 값(0)을 읽음. -
T2는 lock 값을 1로 설정하고 임계구역에 진입.
-
-
T2 중단 및 T1 재개:
-
T2가 lock 값을 1로 설정한 상태에서 CPU가 다시 T1으로 스위칭.
-
T1은 이전에 읽어둔 lock 값(0)을 기반으로 lock 값을 1로 변경.
-
결과적으로 T1과 T2가 동시에 임계구역에 진입하는 충돌 상황 발생.
-
실패 원인 분석
-
Race Condition:
-
T1과 T2가 lock 값을 동시에 읽고, lock 값을 설정하는 과정에서 경쟁이 발생.
-
Lock 변수 조작이 원자적이지 않아서 두 스레드가 동일한 lock 상태를 기준으로 동작.
-
-
Non-Atomic Operation:
-
mov ax, lock→mov lock, 1→cmp ax, 0이 3단계로 나뉘어 실행. -
각 단계 사이에 컨텍스트 스위칭이 발생하면서 데이터 불일치 문제가 발생.
-
📌상호배제 구현 방법 2: 원자명령(Atomic Instruction) 사용
문제점: Lock 변수 사용 실패의 원인
-
컨텍스트 스위칭 발생:
-
두 명령어 (
mov ax, lock→mov lock, 1) 사이에 컨텍스트 스위칭이 발생. -
Lock 변수 값을 읽은 상태에서 다른 스레드로 전환되면서 상호배제가 실패.
-

-
명령어 실행 순서 문제:
-
Lock 값을 읽고 수정하는 작업이 여러 단계로 나뉘어 처리됨.
-
이로 인해 명령어가 완료되기 전에 다른 스레드가 임계구역에 진입할 수 있음.
-
해결책: 원자명령(Atomic Instruction) 도입
-
원자적 실행 보장:
-
여러 단계의 명령을 하나의 연산으로 처리.
-
컨텍스트 스위칭이 중간에 발생하지 않도록 보장.
-
-
TSL(Test and Set Lock) 명령어:
-
원자적으로 lock 값을 읽고 수정.
-
TSL ax, lock:-
Lock 값(현재 상태)을 읽어
ax레지스터에 저장. -
동시에 lock 값을 1로 변경하여 다른 스레드의 접근을 방지.
-
-
TSL(Test and Set Lock) 동작 방식
-
T1 실행:
TSL ax, lock실행.- Lock 값을 읽어
ax에 저장하고, lock 값을 1로 설정.
-
T2 대기:
- T2가
TSL실행을 시도하지만, lock 값이 이미 1로 설정되어 있음. - T2는 lock 값이 0으로 변경될 때까지 대기.
- T2가
-
T1 종료 및 Lock 해제:
- T1이 작업을 완료하고 lock 값을 0으로 변경.
- T2는 lock 값을 읽고 임계구역에 진입.
📌임계구역의 entry/exit 코드를 원자명령으로 재작성
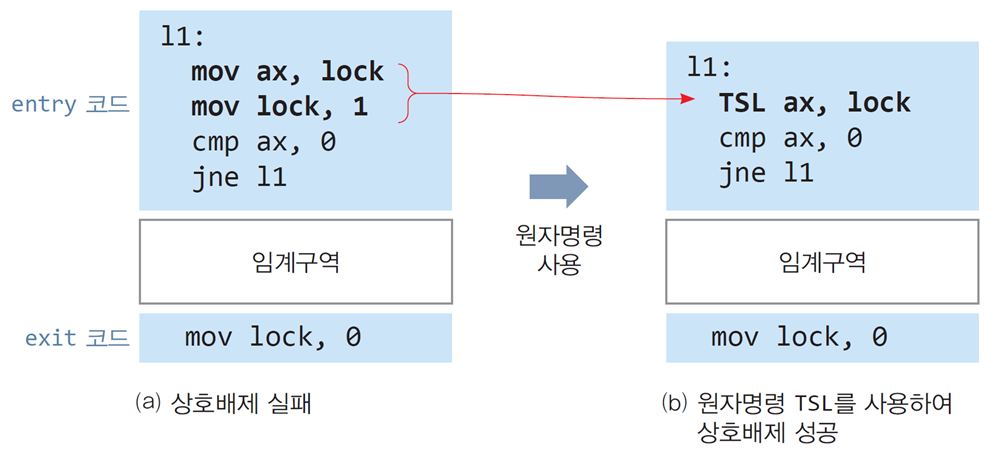
(a) 기존 코드: 상호배제 실패
-
구성
-
mov ax, lock: Lock 값을 읽음. -
mov lock, 1: Lock 값을 1로 설정. -
cmp ax, 0: Lock 값이 0인지 비교. -
jne l1: Lock 값이 0이 아니면 점프.
-
-
문제
-
두 명령 (
mov ax, lock→mov lock, 1) 사이에 컨텍스트 스위칭이 발생할 가능성. -
이로 인해 두 스레드가 동시에 임계구역에 진입하는 상황(상호배제 실패) 발생.
-
(b) 원자명령 TSL(Test and Set Lock)을 사용하여 상호배제 성공
-
구성
-
TSL ax, lock:- Lock 값을 읽고
ax에 저장. - 동시에 Lock 값을 1로 설정 (원자적 수행).
- Lock 값을 읽고
-
cmp ax, 0: 이전 Lock 값이 0인지 확인. -
jne l1: Lock 값이 0이 아니면 점프.
-
-
동작 원리
- 원자명령 TSL은 여러 명령어를 하나의 연산으로 처리하여 컨텍스트 스위칭 발생 가능성을 제거.
- Lock 값이 1이면 다른 스레드는 임계구역에 진입하지 못하고 대기.
출구(exit) 코드
-
mov lock, 0:- Lock 값을 0으로 설정하여 다른 스레드가 임계구역에 진입할 수 있도록 허용.
6.3 멀티스레드 동기화 기법
📌멀티스레드 동기화
멀티스레드 동기화란?
-
정의: 상호배제(Mutual Exclusion) 기반에서, 여러 스레드가 자원을 원활히 공유하도록 하는 기법.
-
핵심 요소: 동기화 프리미티브(Synchronization Primitives)를 활용.
대표적인 기법
-
Locks 방식
-
뮤텍스(Mutex):
- 단일 스레드만 임계구역에 진입할 수 있도록 Lock을 제공.
- Lock을 소유한 스레드가 작업 완료 후 Lock 해제.
-
스핀락(Spinlock):
- Lock이 풀릴 때까지 반복적으로 확인하며 대기.
- CPU 자원을 소모하지만 Lock 대기 시간이 짧은 경우 유리.
-
-
Wait-Signal 방식
- 세마포(Semaphore):
- 여러 자원을 관리하며, 한정된 자원 수(n개)를 m개의 멀티스레드가 공유.
- 자원을 소유하지 못한 스레드는 대기(wait).
- 자원을 반환하면 대기 중인 스레드에 신호(signal)를 보냄.
- 세마포(Semaphore):
기법 비교
| 방식 | 사용 사례 | 특징 |
|---|---|---|
| 뮤텍스 | 단일 자원 보호 | 상호배제 보장, 단순한 구현 |
| 스핀락 | Lock 대기 시간이 짧은 경우 | CPU 자원 소모, 짧은 대기 적합 |
| 세마포 | 다중 자원 관리 | 여러 스레드에서 자원 할당 가능 |
📌뮤텍스(Mutex) 기법
개념
-
목적: 한 스레드만 임계구역에 진입할 수 있도록 보장.
-
대기 방식: 다른 스레드는 큐(queue)에 대기.
-
특징: Sleep-Waiting Lock 기법 사용.
- Lock이 해제될 때까지 스레드가 대기하며 CPU 자원을 소비하지 않음.
뮤텍스 기법의 구성 요소
-
락 변수 (Lock Variable)
- 임계구역에 대한 접근 제어 상태를 관리.
- 상태:
- Locked (1): 다른 스레드가 접근 불가능.
- Unlocked (0): 접근 가능.
-
대기 큐 (Waiting Queue)
- Lock이 설정된 상태에서 임계구역에 진입하지 못한 스레드들이 대기.
- 대기 순서대로 Lock 해제 후 진입.
-
연산 (Operations)
- Lock 연산 (Entry Code):
- 임계구역 진입 전 Lock 변수 설정.
- Lock이 설정되지 않은 상태(0)일 경우에만 Lock을 설정(1).
- Unlock 연산 (Exit Code):
- 임계구역 실행 완료 후 Lock 변수 해제.
- Lock 연산 (Entry Code):
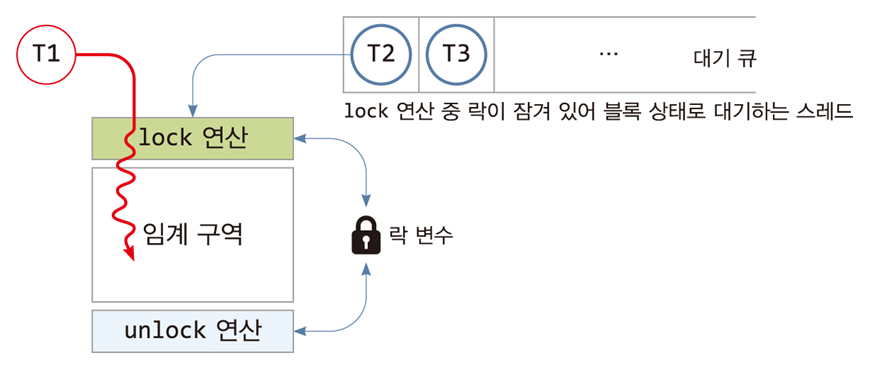
작동 흐름
-
Lock 요청: T1 스레드가 임계구역 진입을 위해 Lock 연산을 수행.
-
임계구역 실행: T1이 Lock을 획득하면 다른 스레드(T2, T3)는 큐에서 대기.
-
Unlock 수행: T1이 임계구역을 빠져나오며 Lock 해제 → 큐의 첫 번째 대기 스레드(T2)가 Lock을 획득.
📌뮤텍스를 활용한 스레드 동기화 과정
과정 설명
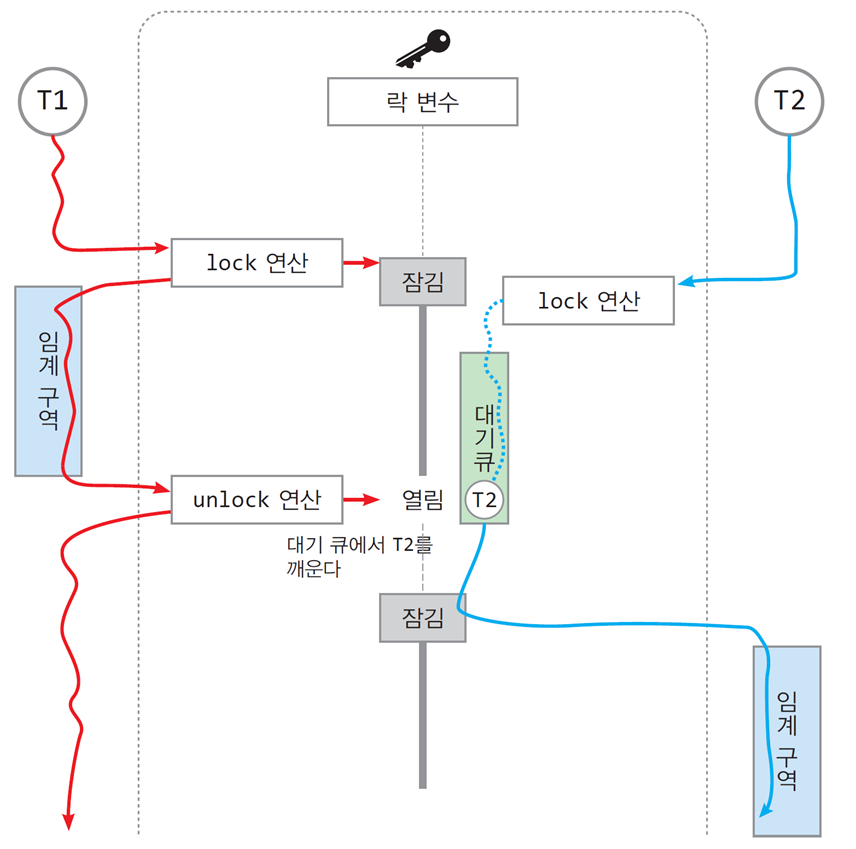
-
T1 스레드의 Lock 연산
- T1이 임계구역에 진입하기 위해 Lock 연산을 수행.
- 락 변수는 "잠김" 상태(1)로 변경됨.
- T1이 임계구역에 성공적으로 진입.
-
T2 스레드의 Lock 대기
- T2 스레드는 락 변수가 잠겨 있어 임계구역에 진입하지 못함.
- 대기 큐에서 대기 상태로 전환.
-
T1의 Unlock 연산
- T1이 임계구역에서 작업을 완료한 후 Unlock 연산 수행.
- 락 변수를 "열림" 상태(0)로 변경.
-
대기 큐에서 T2 스레드 깨우기
- T1이 락을 해제함으로써 대기 큐의 T2 스레드가 활성화됨.
- T2는 Lock 연산을 수행하고 임계구역에 진입.
핵심 요소
-
락 변수: 임계구역 접근 상태를 관리.
-
대기 큐: Lock 해제 시 대기 스레드를 관리.
-
Lock/Unlock 연산: 스레드가 임계구역을 안전하게 사용하도록 제어.
📌뮤텍스의 특징
뮤텍스를 활용한 동기화의 특징
-
효율적 임계구역 관리
- 임계구역 실행 시간이 짧을 경우 효율적.
- 불필요한 컨텍스트 스위칭을 방지하여 성능 향상.
POSIX 표준 라이브러리를 활용한 뮤텍스 동기화
-
뮤텍스 락 변수
pthread_mutex_t lock;선언으로 뮤텍스 락 생성.
-
뮤텍스 조작 함수
pthread_mutex_init(): 뮤텍스 초기화.pthread_mutex_lock(): 뮤텍스 잠금 (Entry 코드).pthread_mutex_unlock(): 뮤텍스 해제 (Exit 코드).pthread_mutex_destroy(): 뮤텍스 제거.
-
대기 큐 관리
- POSIX pthread 라이브러리 내부에서 대기 큐 구현 및 관리.
뮤텍스를 활용한 코드 사례
pthread_mutex_t lock; // 뮤텍스 락 생성
pthread_mutex_init(&lock, NULL); // 뮤텍스 초기화
...
pthread_mutex_lock(&lock); // 임계구역 코드 시작
// 임계구역 코드
pthread_mutex_unlock(&lock); // 임계구역 코드 종료
...
pthread_mutex_destroy(&lock); // 뮤텍스 제거📌스핀락(Spinlock) 기법
스핀락 기법의 특징
-
busy-waiting 방식
- 락을 획득할 때까지 반복적으로 확인하며 대기.
- 대기 큐를 사용하지 않아 단순한 구조.
-
뮤텍스와의 차이점
- 스핀락은 busy-waiting으로 인해 CPU 리소스를 지속적으로 사용.
- 대기 상태에서도 스레드가 스케줄링되며 반복문을 실행.
-
효율적인 사용
- 락 소유 스레드만 자원 배타적으로 사용 가능.
- 공유 자원이 적거나 짧은 시간만 락이 필요한 경우 적합.
스핀락 기법의 구성 요소
-
락 변수
- 락 상태를 나타내는 변수(0: 잠금 해제, 1: 잠금 상태).
-
연산
- lock 연산
- 락이 풀릴 때까지 무한 루프를 돌며 락을 획득 시도.
- unlock 연산
- 락을 해제하여 다른 스레드가 접근 가능하도록 설정.
- lock 연산
장점
- 구현이 단순하며 대기 큐가 필요하지 않음.
- 임계구역 접근 시간이 짧을 경우 효율적.
단점
- busy-waiting으로 인해 CPU 자원 낭비 가능.
- 긴 임계구역에서는 비효율적.
📌스핀락을 활용한 스레드 동기화 사례
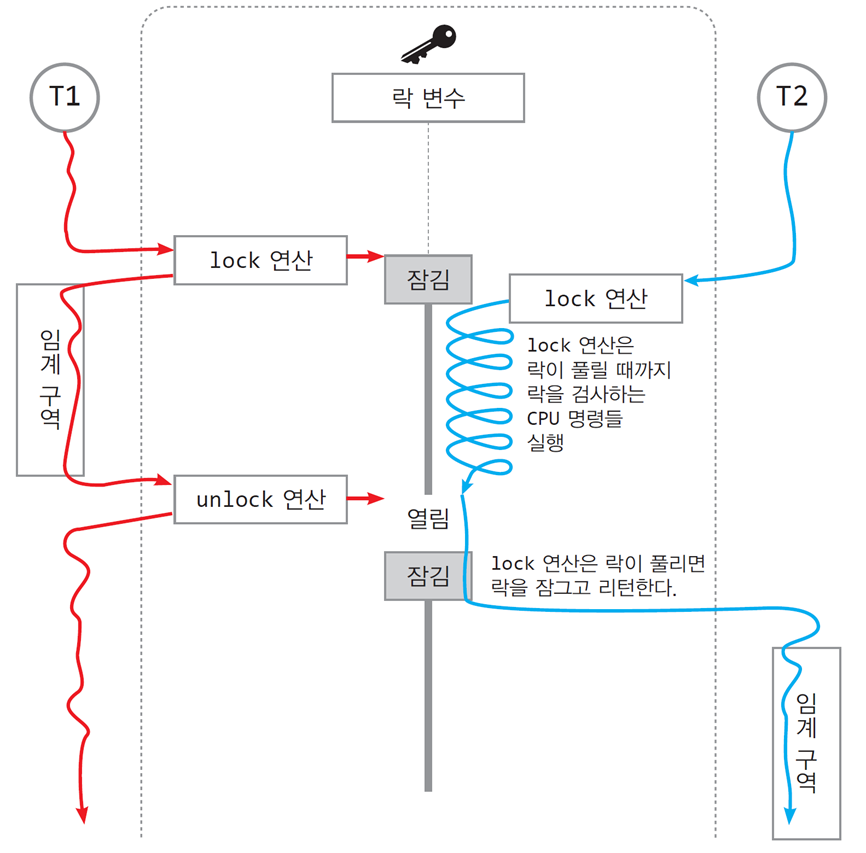
T1의 동작 과정
-
락 획득 시도 (lock 연산)
- T1은 락 변수를 확인하여 임계구역에 진입 가능 여부를 확인.
- 락이 해제 상태라면 락을 획득하고 임계구역에 진입.
-
임계구역 실행
- T1은 임계구역에서 필요한 작업을 수행.
-
락 해제 (unlock 연산)
- 작업을 마친 후 락을 해제하여 다른 스레드가 임계구역에 접근할 수 있도록 함.
T2의 동작 과정
-
락 획득 시도 (lock 연산)
- T2는 락 변수가 잠금 상태라면 락이 해제될 때까지 busy-waiting 수행.
- 락이 해제되면 락을 획득하고 임계구역에 진입.
-
임계구역 실행
- T2는 임계구역에서 작업을 수행.
특징
-
busy-waiting:
- T2는 락을 획득하기 전까지 반복적으로 확인(바쁜 대기).
- 락이 해제되면 즉시 작업에 착수 가능.
-
락 상태 전환:
- 락 해제(unlock) 후 대기 중인 스레드(T2)가 즉시 락을 획득하고 작업을 시작.
📌스핀락의 특징
특징
-
Non-blocking 모델:
- 스핀락은 뮤텍스의 blocking 방식과 달리 busy-waiting을 통해 대기함.
- 락을 얻을 때까지 CPU를 계속 사용.
-
효율성:
- 단일 CPU(단일 코어) 환경에서 비효율적.
- 임계구역의 실행 시간이 짧을 경우 적합.
-
비효율성:
- 멀티코어나 CPU 스케줄링이 필요한 환경에서는 busy-waiting으로 인한 자원 낭비 가능.
POSIX 표준 라이브러리
스핀락을 사용하는 함수 및 변수는 POSIX 표준에 정의되어 있음.
스핀락 변수
pthread_spinlock_t lock;
스핀락 조작 함수
-
pthread_spin_init(): 스핀락 초기화. -
pthread_spin_lock(): 스핀락 획득. -
pthread_spin_unlock(): 스핀락 해제. -
pthread_spin_destroy(): 스핀락 자원 해제.
코딩 사례
pthread_spinlock_t lock; // 스핀락 변수 생성
pthread_spin_init(&lock, NULL); // 스핀락 초기화
pthread_spin_lock(&lock); // 스핀락 획득
// 임계구역 코드
pthread_spin_unlock(&lock); // 스핀락 해제📌뮤텍스와 스핀락의 적합한 사용 상황
-
락이 잡히는 시간이 긴 경우
-
뮤텍스(Mutex): 락을 오래 유지해야 할 경우 적합.
-
스핀락(Spinlock): 락 잡는 시간이 짧은 경우 효율적.
-
-
단일 CPU 시스템
- 뮤텍스(Mutex): 단일 CPU에서는 context switching 비용이 적으므로 적합.
-
멀티 코어 시스템
- 스핀락(Spinlock): 임계구역 코드가 짧아 CPU 낭비를 줄일 수 있는 경우 적합.
-
사용자 응용 프로그램 및 커널 코드
-
뮤텍스(Mutex): 사용자 응용 프로그램에서 일반적으로 사용.
-
스핀락(Spinlock): 커널 코드나 인터럽트 서비스 루틴처럼 빠른 처리 필요.
-
-
주의 사항
- 스핀락 사용 시 기아(Starvation) 문제가 발생할 가능성이 있음.
📌뮤텍스(Mutex)와 스핀락(Spinlock) 비교
| 구분 | 뮤텍스(Mutex) | 스핀락(Spinlock) |
|---|---|---|
| 대기 큐 | 있음 | 없음 |
| 블록 가능 여부 | 락이 잡혀 있으면 블록됨 (blocking) | 락이 잡혀 있어도 블록되지 않고 계속 락 검사 (non-blocking) |
| lock/unlock 연산 비용 | 저비용 | CPU를 계속 사용하므로 고비용 |
| 하드웨어 관련 | 단일 CPU에서 적합 | 멀티코어 CPU에서 적합 |
| 주 사용처 | 사용자 응용 프로그램 | 커널 코드, 인터럽트 서비스 루틴 |
📌세마포(Semaphore)란?
-
멀티스레드 간 공유 자원 관리 기법.
-
n개의 공유 자원을 다수의 스레드가 효율적으로 사용할 수 있도록 제어.
구성 요소
-
자원:
- n개의 공유 자원.
-
대기 큐:
- 자원이 부족할 때 스레드가 대기하는 큐.
-
카운터 변수:
- 사용 가능한 자원의 개수를 나타냄.
- 초기값:
n(자원의 총 개수).
-
P/V 연산:
- P 연산 (wait 연산): 자원 요청 시 수행.
- 자원 개수를 1 감소.
- 자원이 부족하면 대기 큐에 스레드 추가.
- V 연산 (signal 연산): 자원 반환 시 수행.
- 자원 개수를 1 증가.
- 대기 중인 스레드가 있으면 큐에서 스레드 제거 후 실행.
- P 연산 (wait 연산): 자원 요청 시 수행.
📌세마포어의 필요성을 이해하기 위한 대여 시스템 사례
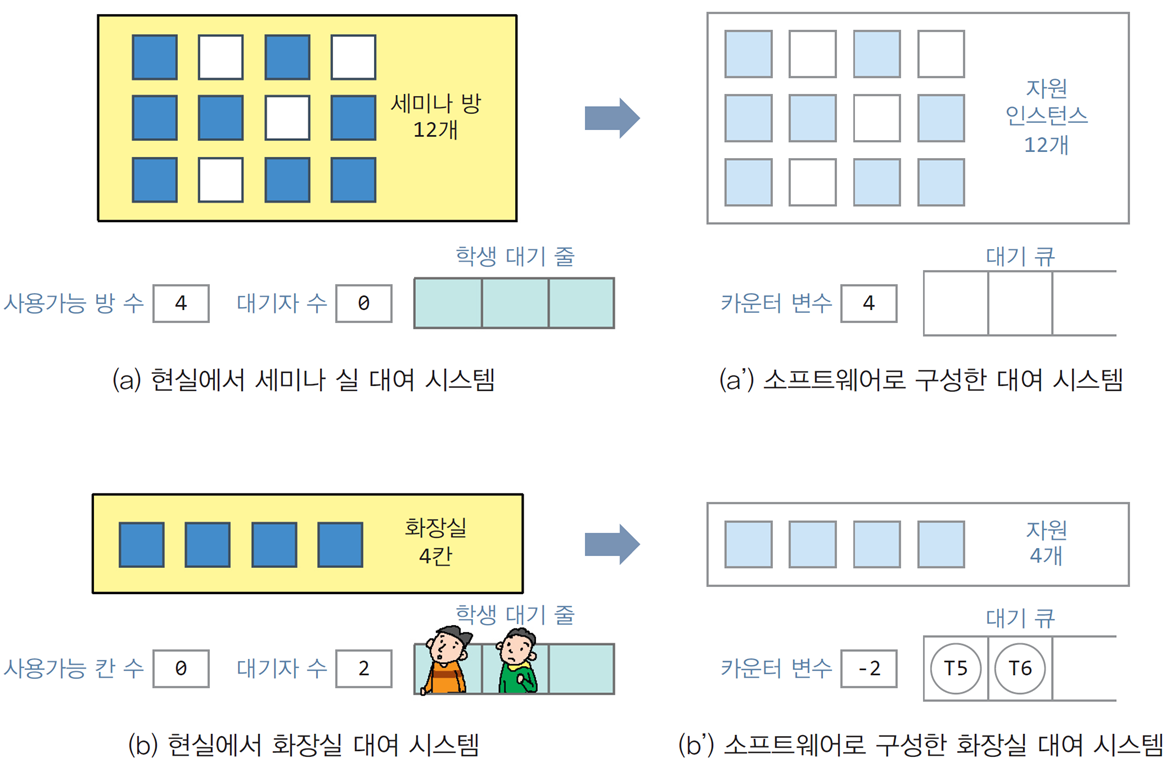
1. 세미나 실 대여 시스템
-
현실 시스템:
- 12개의 세미나 방 중 사용 가능한 방은 4개.
- 대기자 줄은 비어 있음.
-
소프트웨어 구현:
- 자원 인스턴스 12개로 모델링.
- 카운터 변수는 4로, 사용 가능한 방의 수를 나타냄.
- 대기 큐는 없음.
2. 화장실 대여 시스템
-
현실 시스템:
- 4개의 화장실 중 모든 칸이 사용 중.
- 대기자 2명이 줄을 서 있음.
-
소프트웨어 구현:
- 자원 인스턴스 4개로 모델링.
- 카운터 변수는 2, 현재 대기자 수를 나타냄.
- 대기 큐에는 T5, T6가 대기 중.
핵심 개념
-
세마포어는 공유 자원의 사용 가능 상태를 관리하여 여러 프로세스가 자원을 효율적으로 사용할 수 있도록 함.
-
카운터 변수:
- 양수: 사용 가능한 자원의 수.
- 음수: 대기 중인 프로세스 수.
-
대기 큐는 자원이 부족할 경우 접근을 조정함.
📌세마포가 필요한 상황
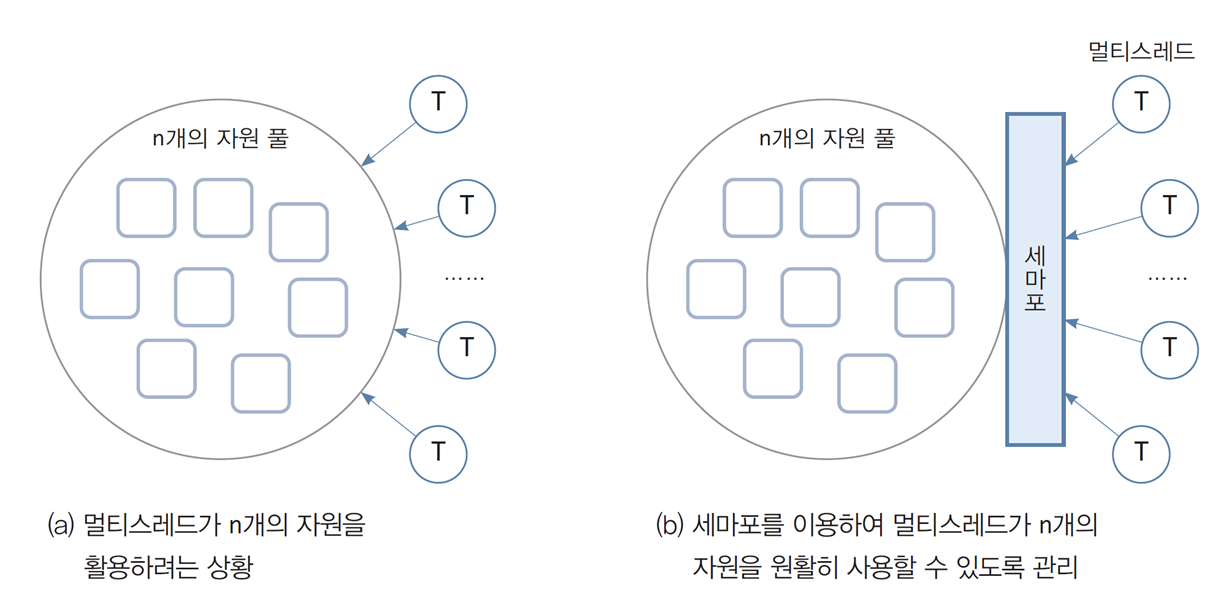
(a) 멀티스레드와 n개의 자원 풀
-
여러 개의 멀티스레드가 동시에 n개의 자원 풀에 접근하려는 상황을 설명.
-
자원 관리가 이루어지지 않으면 충돌이나 비효율적인 자원 사용이 발생할 수 있음.
(b) 세마포를 통한 자원 관리
-
세마포(semaphore)를 사용하여 멀티스레드가 자원을 원활히 사용하도록 제어.
-
작동 방식:
- 세마포는 n개의 자원을 추적하는 카운터 역할을 함.
- 스레드가 자원에 접근하려면 세마포에서 허가를 받아야 함.
- 사용 가능한 자원이 없으면 스레드는 대기 큐에 대기.
세마포를 이용한 멀티스레드 자원 관리의 구조
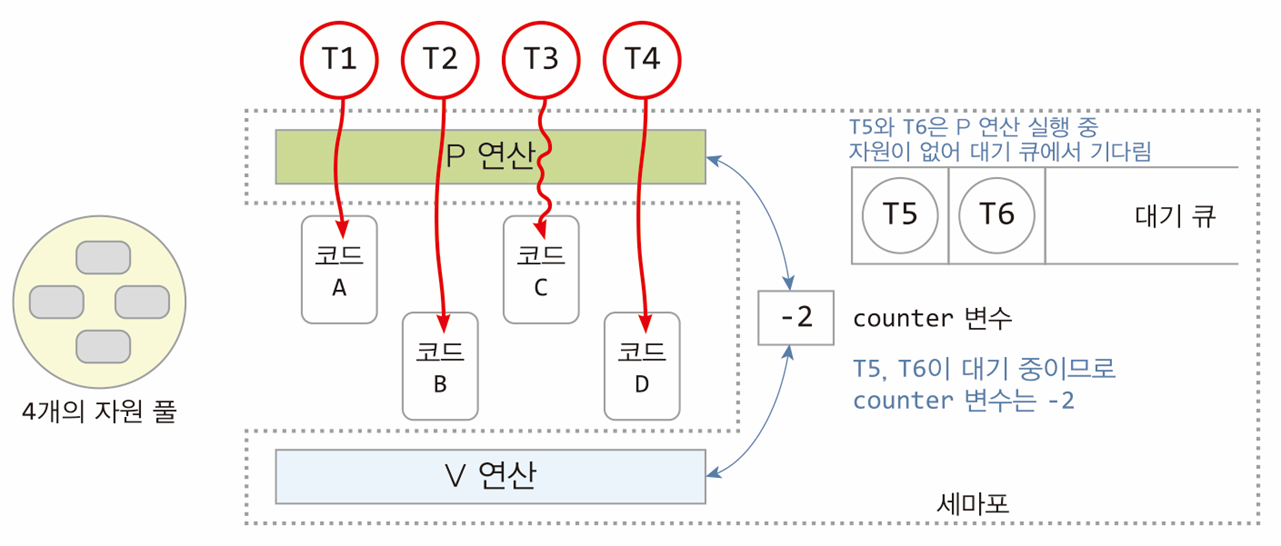
설명
-
자원의 인스턴스 수:
- 4개의 자원이 존재.
- 총 4개의 스레드(T1, T2, T3, T4)가 각 자원을 할당받아 사용 중.
-
대기 중인 스레드:
- T5와 T6는 현재 자원이 없어 대기 큐에 대기 중.
-
카운터 변수:
- 자원의 사용 가능 상태를 나타냄.
- 음수인 경우: 대기 중인 스레드의 수를 의미.
- 현재
counter = -2: 대기 중인 스레드가 2개(T5, T6).
구조의 핵심
-
P 연산:
- 스레드가 자원을 요청할 때 수행.
- 자원이 없을 경우, 해당 스레드는 대기 큐에 추가.
-
V 연산:
- 스레드가 자원을 반환할 때 수행.
- 대기 중인 스레드가 있을 경우, 큐에서 제거 후 실행 가능 상태로 전환.
-
대기 큐:
- 자원이 부족할 경우 스레드들이 대기하는 공간.
실제 동작
-
T1~T4: 현재 자원을 사용 중.
-
T5, T6: 자원 반환(V 연산)이 발생하면 차례로 자원을 할당받아 실행.
특징
-
자원의 효율적 사용: 여러 스레드가 자원을 동시에 활용 가능.
-
대기 관리: 자원이 부족할 경우 큐를 통해 질서 있게 관리.
-
확장성: 자원 수와 대기 큐 크기를 조정하여 다양한 상황에 대응.
📌P 연산과 V 연산

세마포의 두 가지 종류
-
Sleep-wait 세마포
-
자원을 요청했지만 할당받지 못한 스레드는 대기 큐에 들어가 잠자기 상태로 전환.
-
자원이 반환되면 대기 큐에서 스레드를 깨워 자원을 할당.
-
-
Busy-wait 세마포
-
자원을 기다리는 동안 무한 루프로 자원의 생성을 계속 확인.
-
자원이 생길 때까지 CPU를 사용하며 대기.
-
P 연산 (Wait Operation)
-
Sleep-wait 방식:
counter--: 자원 요청 시 감소.if (counter < 0): 자원이 없으면 대기 큐에 스레드를 삽입.
- Busy-wait 방식:
while (counter <= 0): 자원이 생길 때까지 무한 루프.counter--: 자원을 획득 시 감소.
V 연산 (Signal Operation)
-
Sleep-wait 방식:
counter++: 자원 반환 시 증가.if (counter <= 0): 대기 큐에서 한 스레드를 깨움.
-
Busy-wait 방식:
counter++: 자원 반환 시 증가.
비교
-
Sleep-wait 세마포:
- 효율적. CPU를 낭비하지 않고 대기 큐를 통해 스레드를 관리.
- 사용 사례: 멀티스레드 환경에서 자원이 제한적이고, 대기 시간이 긴 경우.
-
Busy-wait 세마포:
- 비효율적. CPU를 계속 사용하여 자원 상태를 확인.
- 사용 사례: 짧은 대기 시간 또는 단일 CPU 환경.
📌세마포 활용을 위한 POSIX 표준 라이브러리
세마포 구조체
sem_t s;세마포 구조체로, 내부적으로 counter 변수와 대기 큐를 포함하여 자원 관리.
세마포 조작 함수
-
sem_init()- 세마포 초기화 함수.
- 특정 자원 수(
counter)로 초기화.
-
sem_destroy()- 세마포 제거 함수.
- 사용이 끝난 세마포를 파괴하여 리소스 해제.
-
sem_wait()- P 연산 (blocking call).
- Sleep-wait 방식으로 동작.
- 가용 자원이 없으면 대기 큐에서 잠자기 상태로 전환.
-
sem_trywait()- P 연산 (non-blocking call).
- 가용 자원이 있다면
counter--후 0 반환. - 자원이 없으면 -1 반환하며 대기하지 않음.
-
sem_post()- V 연산.
- 자원을 반환하며
counter++. - 대기 중인 스레드가 있다면 대기 큐에서 깨워 자원 할당.
-
sem_getvalue()- 현재 세마포의
counter값을 반환. - 대기 큐 상태 확인 가능.
- 현재 세마포의
사용 예제
sem_t sem; // 세마포 구조체 생성
sem_wait(&sem); // P 연산. 자원 요청 (가용 자원이 없으면 대기).
// ... 자원 사용 ...
sem_post(&sem); // V 연산. 자원 반환.
sem_destroy(&sem); // 세마포 파괴.
📌카운터 세마포와 이진 세마포
1. 카운터 세마포 (Counter Semaphore)
-
여러 개의 자원을 관리.
-
Counter 변수로 관리하는 방식.예: 세마포의 counter가
n이라면 최대n개의 스레드가 자원을 사용할 수 있음.
2. 이진 세마포 (Binary Semaphore)
-
한 개의 자원만을 관리하는 세마포.
-
뮤텍스(Mutex)와 기능적으로 유사.
-
Counter 값이 0 또는 1만 가질 수 있음.
이진 세마포 구성 요소
-
세마포 변수 S
0또는1값을 가지며, 초기값은1.
-
대기 큐
-
스레드 스케줄링 알고리즘이 필요.
-
자원이 사용 중일 때 대기하는 스레드가 큐에 저장됨.
-
-
두 가지 원자 연산
-
wait 연산 (P 연산): 자원 요청. -
signal 연산 (V 연산): 자원 반환.
-
이진 세마포 특징
-
하나의 자원만을 관리하므로 간단한 동기화에 적합.
-
뮤텍스와 달리 소유권 개념이 없음.(뮤텍스는 소유한 스레드만 잠금을 해제할 수 있음.)
-
단순 자원 관리와 접근 제어에 효율적.
📌동기화 이슈: 우선순위 역전
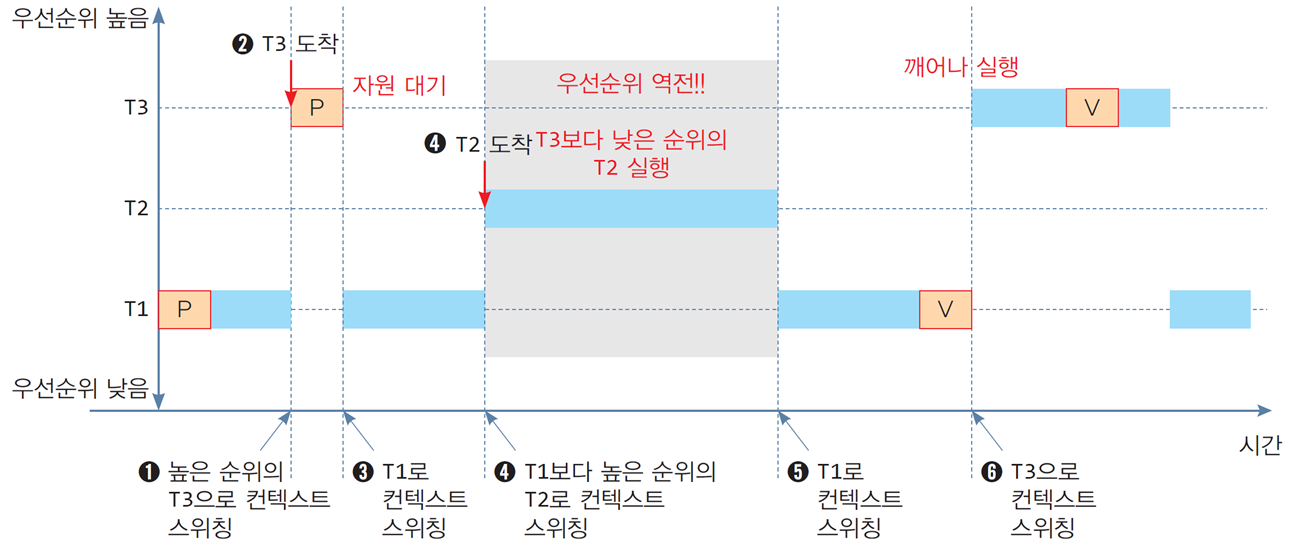
1. 시나리오 배경
-
3개의 스레드:
- T3 (높은 우선순위)
- T2 (중간 우선순위)
- T1 (낮은 우선순위)
-
T1과 T3는 공유 변수를 사용하며, 이를 세마포로 동기화.
-
T2는 공유 변수에 접근하지 않음.
2. 상황 진행
-
T1 시작:
- T1이 먼저 실행되어 P 연산으로 자원을 획득.
-
T3 도착:
- 높은 우선순위의 T3가 도착했지만, T1이 공유 변수 자원을 사용 중이므로 대기 상태로 전환.
-
T2 실행:
- T2는 중간 우선순위로 공유 변수와 무관하므로 실행 가능.
- 그러나 T3보다 우선순위가 낮은 T2가 실행됨으로써 우선순위 역전이 발생.
-
T1 실행 재개 및 종료:
- T1이 종료되면서 V 연산으로 자원을 해제.
-
T3 실행:
- 높은 우선순위의 T3가 깨워져 실행.
3. 우선순위 역전 문제점
-
T3와 같이 높은 우선순위의 스레드가 T1(낮은 우선순위) 때문에 블록되며, 그 사이에 T2(중간 우선순위)가 실행됨.
-
이로 인해 높은 우선순위의 작업이 불필요하게 지연됨.
📌우선순위 역전 해결책
1. 우선순위 올림(priority ceiling)
-
정의: 공유 자원을 사용하는 스레드의 우선순위를 미리 정해진 높은 우선순위로 일시적으로 올려주는 방법이다.
-
특징:
- 공유 자원에 접근하는 동안 스레드의 우선순위를 특정한 값으로 올림.
- 자원에 접근하는 스레드가 선점되지 않고 빠르게 실행이 완료되도록 함.
2. 우선순위 상속(priority inheritance)
-
정의: 공유 자원을 가진 스레드의 우선순위를 자원을 요청한 다른 스레드의 우선순위보다 높게 설정하여 빠르게 실행되도록 하는 방법이다.
-
특징:
- 공유 자원을 가진 스레드(T1)의 우선순위를 자원을 기다리는 스레드(T3)의 우선순위로 올림.
- 우선순위를 상속받음으로써 선점 문제를 해결하고 자원의 처리가 빠르게 진행되도록 함.
6.4 생산자 소비자 문제
📌응용프로그램에 존재하는 생산자 소비자 문제 사례
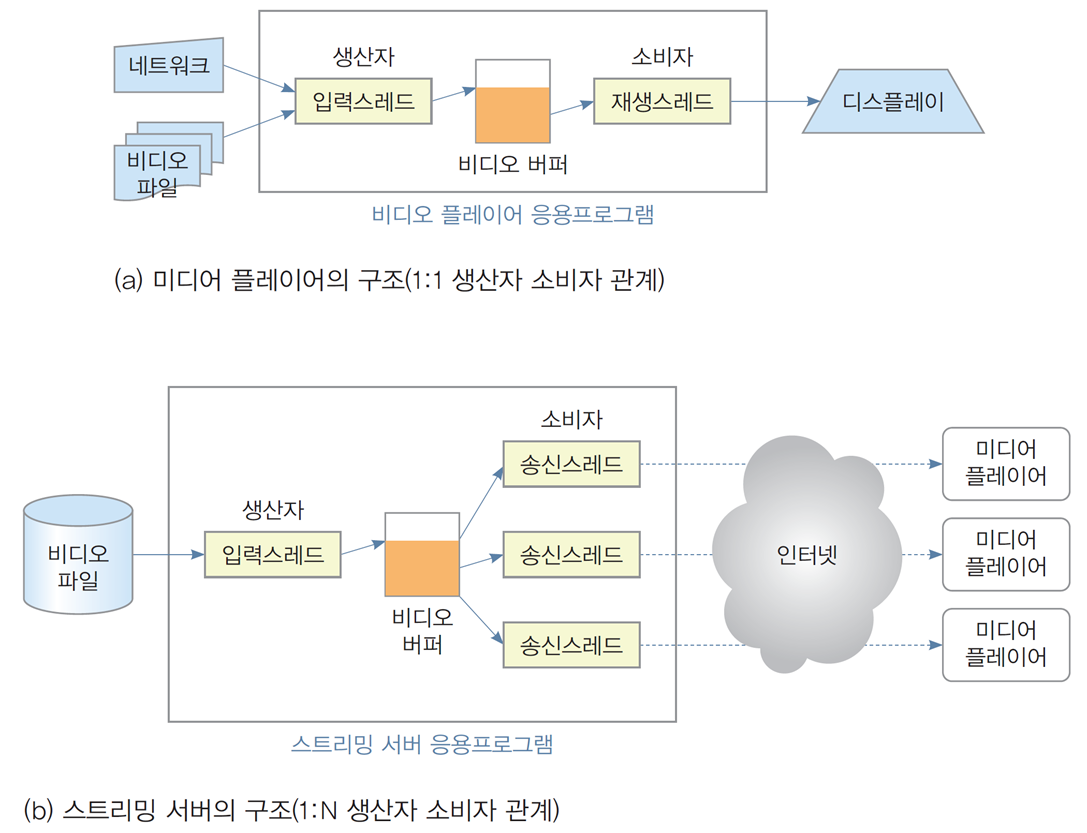
(a) 미디어 플레이어 구조: 1:1 생산자-소비자 관계
-
구조 설명:
-
생산자 역할: 입력 스레드가 네트워크 또는 비디오 파일로부터 데이터를 읽어들인다.
-
버퍼: 생산자가 데이터를 버퍼에 저장하며, 이 버퍼는 소비자(재생 스레드)와 공유된다.
-
소비자 역할: 재생 스레드가 버퍼에서 데이터를 읽어 디스플레이로 출력한다.
-
-
문제:
-
생산자가 데이터를 버퍼에 추가하기 전에 소비자가 버퍼를 읽으려 하면 빈 버퍼 문제 발생.
-
반대로 소비자가 데이터를 처리하기 전에 생산자가 버퍼를 가득 채우면 버퍼 오버플로우 문제 발생.
-
(b) 스트리밍 서버 구조: 1:N 생산자-소비자 관계
-
구조 설명:
-
생산자 역할: 입력 스레드가 비디오 파일에서 데이터를 읽고 버퍼에 저장.
-
버퍼: 데이터를 여러 소비자 스레드(송신 스레드)로 전달.
-
소비자 역할: 각 송신 스레드가 네트워크를 통해 데이터를 클라이언트(미디어 플레이어)로 전송.
-
-
문제:
-
여러 소비자가 동시에 버퍼를 읽으려 할 때 경쟁 조건 발생 가능.
-
생산자와 여러 소비자 간 데이터의 정확한 전달을 보장해야 하며, 이를 위해 적절한 동기화가 필요.
-
📌생산자 소비자 문제의 정의
1. 생산자-소비자 문제란?
-
구조: 생산자 스레드와 소비자 스레드가 공유 버퍼를 통해 데이터를 주고받는다.
-
역할:
- 생산자: 데이터를 생성하여 공유 버퍼에 저장.
- 소비자: 공유 버퍼에서 데이터를 읽고 처리.
-
문제 핵심:
- 생산자와 소비자가 동시에 공유 버퍼에 접근할 때 발생하는 동기화 문제를 해결하는 것이다.
- 이를 통해 생산자와 소비자가 문제 없이 협력하여 데이터를 주고받을 수 있도록 한다.
2. 생산자-소비자 문제의 구체적인 3가지 문제
-
문제 1 - 상호 배제 해결
-
공유 버퍼는 여러 스레드가 동시에 접근할 수 없다.
-
해결:
- 뮤텍스(Mutex)를 사용하여 단 하나의 스레드만 버퍼를 접근하도록 제한.
-
-
문제 2 - 비어 있는 공유 버퍼 문제
- 소비자가 데이터를 읽으려고 할 때, 버퍼에 데이터가 없는 경우 발생.
- 해결:
- 세마포어나 조건 변수를 사용해 소비자가 데이터를 기다리도록 구현.
-
문제 3 - 꽉 찬 공유 버퍼 문제
- 생산자가 데이터를 추가하려 할 때, 버퍼가 가득 차 있는 경우 발생.
- 해결:
- 생산자를 대기 상태로 두고, 소비자가 데이터를 소비한 후 공간을 확보하면 다시 실행.
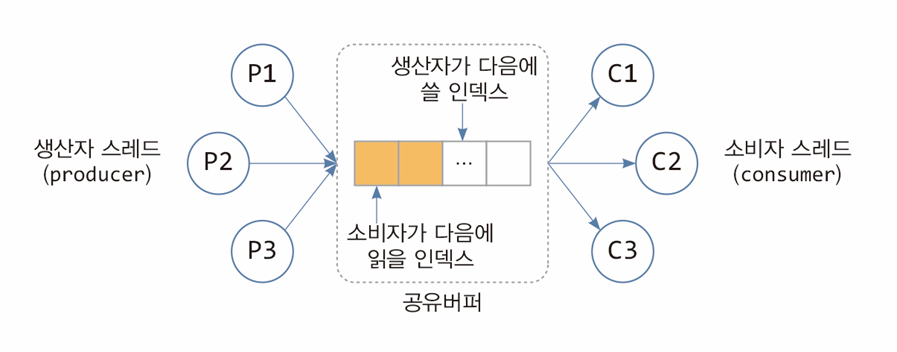
-
공유 버퍼 구조:
-
P1, P2, P3: 생산자 스레드.
-
C1, C2, C3: 소비자 스레드.
-
공유 버퍼: 데이터를 저장하는 공간으로 생산자가 데이터를 추가하고, 소비자가 읽는다.
-
동기화 포인트: 생산자와 소비자가 버퍼에 동시에 접근하지 않도록 관리.
-
📌비어 있는 버퍼 문제 해결
문제 상황
-
공유 버퍼가 비어 있을 때 소비자가 데이터를 읽으려고 하면 문제가 발생.
-
소비자는 읽을 데이터가 없기 때문에 대기 상태가 되어야 함.
해결 방법: 세마포어를 활용한 동기화
- 세마포어 R을 사용하여 읽기 가능한 버퍼 개수를 추적.
- P 연산과 V 연산으로 소비자와 생산자의 작업을 제어.
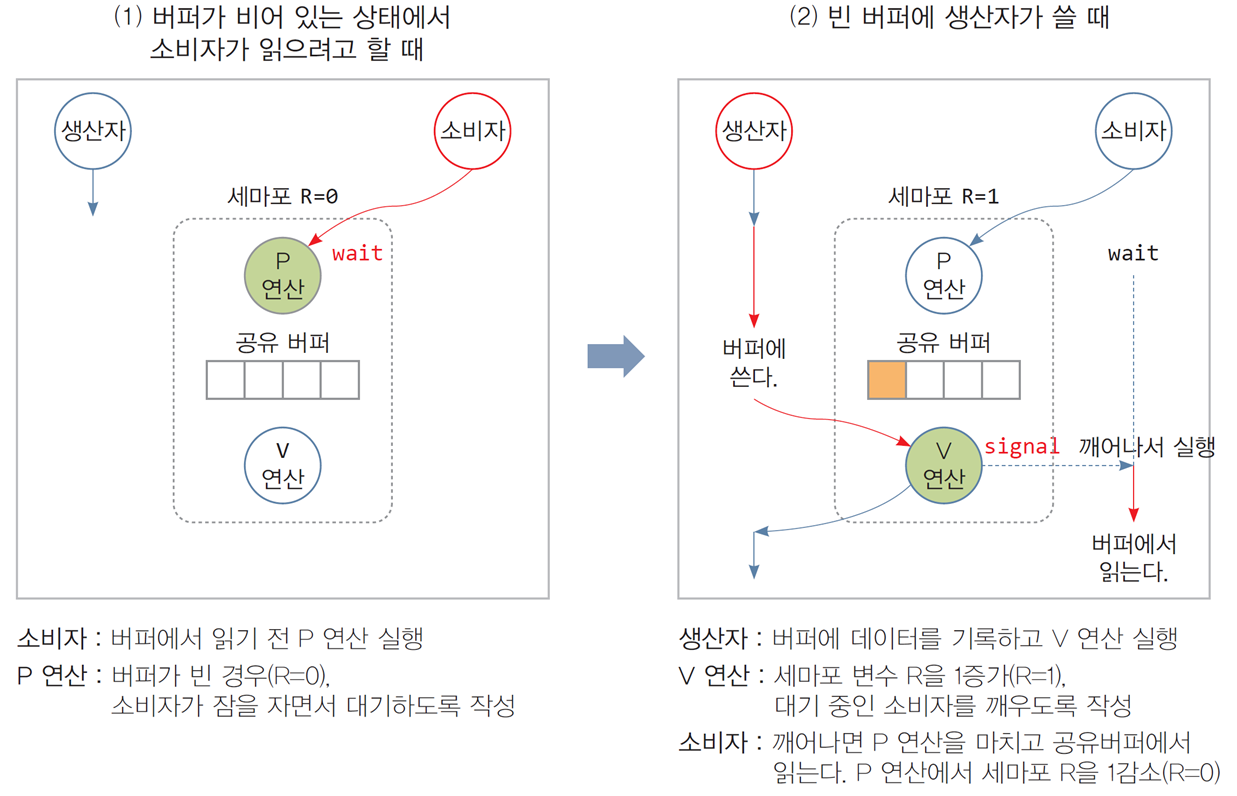
1. 소비자가 읽으려 할 때 (왼쪽 그림)
-
세마포어 R = 0 (버퍼 비어 있음).
-
소비자는 P 연산을 수행:
- P 연산은 세마포어 값을 감소.
- 세마포어 값이 0이면 소비자는 대기(wait) 상태로 전환.
-
생산자가 데이터를 추가하면, V 연산으로 세마포어 값을 증가시키며 대기 중인 소비자를 깨운다.
2. 생산자가 쓰려 할 때 (오른쪽 그림)
-
생산자는 버퍼에 데이터를 추가하고 V 연산 수행:
- V 연산은 세마포어 값을 증가(R = 1).
- 대기 상태에 있는 소비자를 signal(깨움) 처리.
-
깨워진 소비자는 다시 P 연산을 수행하여 공유 버퍼에서 데이터를 읽는다.
- 데이터를 읽은 후, P 연산에서 세마포어 값을 감소(R = 0).
동작 과정 요약
-
소비자 동작:
-
P 연산 수행.
-
세마포어 값이 0이면 대기(wait).
-
생산자가 데이터를 추가하면 V 연산으로 대기 상태 종료.
-
공유 버퍼에서 데이터를 읽는다.
-
-
생산자 동작:
-
데이터를 버퍼에 추가.
-
V 연산으로 세마포어 값을 증가.
-
대기 중인 소비자를 깨운다.
-
중요 포인트
-
세마포어 값 R은 읽기 가능한 데이터의 개수를 나타냄.
-
P/V 연산으로 소비자와 생산자의 작업 순서를 효율적으로 동기화.
-
결과: 소비자와 생산자는 버퍼가 비어 있거나 가득 찼을 때 적절히 대기하거나 실행할 수 있다.
📌꽉 찬 공유 버퍼 문제 해결
문제 상황
-
공유 버퍼가 꽉 찼을 때 생산자가 데이터를 쓰려고 하면 문제가 발생.'
-
생산자는 더 이상 데이터를 쓸 공간이 없기 때문에 대기 상태가 되어야 함.
해결 방법: 세마포어를 활용한 동기화
- 세마포어 W를 사용하여 쓰기 가능한 버퍼의 개수를 추적.
- P 연산과 V 연산으로 생산자와 소비자의 작업을 제어.
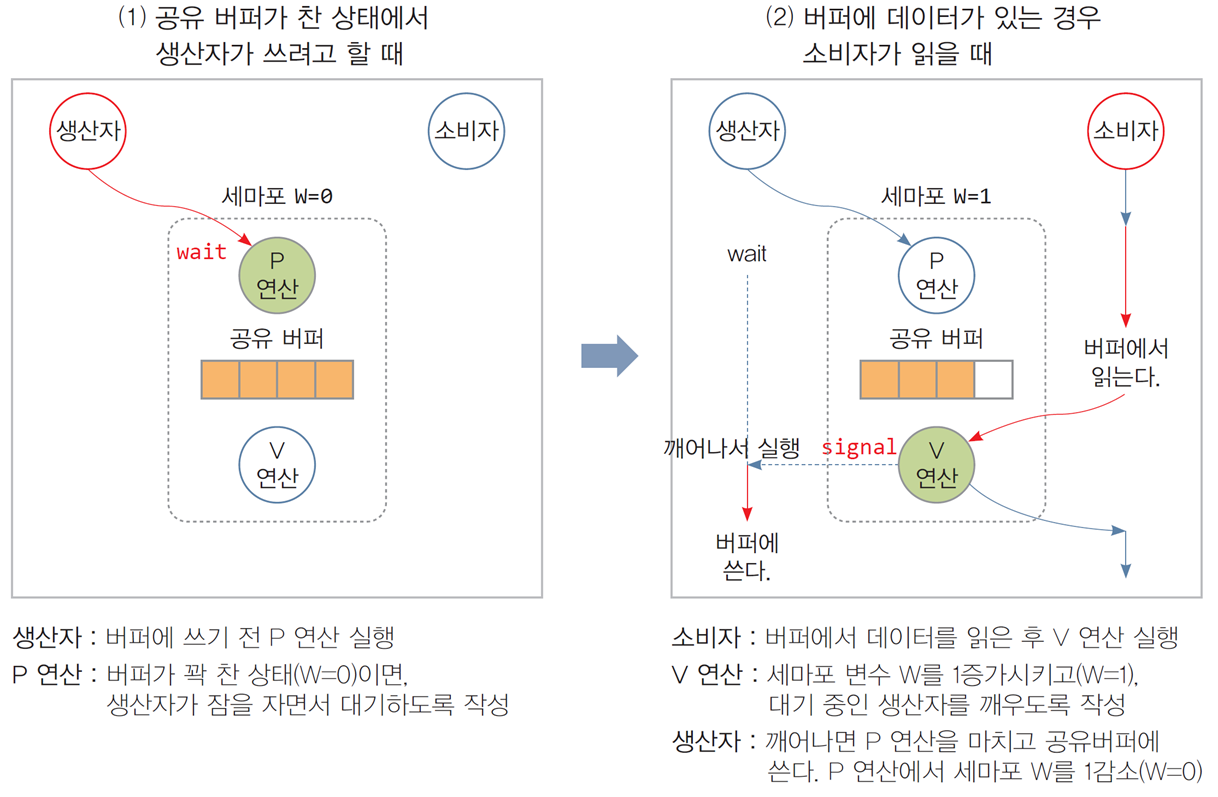
1. 생산자가 쓰려 할 때 (왼쪽 그림)
-
세마포어 W = 0 (버퍼가 꽉 참).
-
생산자는 P 연산을 수행:
- P 연산은 세마포어 값을 감소.
- 세마포어 값이 0이면 생산자는 대기(wait) 상태로 전환.
-
소비자가 데이터를 읽으면, V 연산으로 세마포어 값을 증가시키며 대기 중인 생산자를 깨운다.
2. 소비자가 읽으려 할 때 (오른쪽 그림)
-
소비자가 데이터를 읽기 전, P 연산을 수행:
- P 연산은 세마포어 값을 감소(W = 1 → 0).
- 데이터를 읽은 후, V 연산을 통해 생산자를 깨운다.
-
생산자는 깨워진 후 P 연산을 다시 수행하고 공유 버퍼에 데이터를 쓴다.
동작 과정 요약
-
생산자 동작:
-
P 연산 수행.
-
세마포어 값이 0이면 대기(wait).
-
소비자가 데이터를 읽어 V 연산을 수행하면 대기 상태 종료.
-
공유 버퍼에 데이터를 쓴다.
-
-
소비자 동작:
-
데이터를 읽기 전, P 연산 수행.
-
세마포어 값을 감소.
-
데이터를 읽은 후, V 연산으로 세마포어 값을 증가.
-
대기 중인 생산자를 깨운다.
-
중요 포인트
-
세마포어 값 W는 쓰기 가능한 버퍼 공간의 개수를 나타냄.
-
P/V 연산으로 생산자와 소비자의 작업을 효율적으로 동기화.
-
결과: 생산자와 소비자는 버퍼가 비거나 꽉 찼을 때 적절히 대기하거나 실행할 수 있다.
📌생산자와 소비자 알고리즘
알고리즘 개요
-
R: 버퍼에서 읽기 가능한 버퍼 개수(비어 있으면 0).
-
W: 버퍼에 쓰기 가능한 버퍼 개수(꽉 차 있으면 0).
-
M: 뮤텍스(Mutex)로 생산자와 소비자 모두 사용.
소비자 알고리즘 (Consumer)
while(true) {
P(R); // 세마포 R에 대해 P 연산 수행
// 읽기 가능한 버퍼가 없으면 대기
뮤텍스(M)를 잠금;
공유 버퍼에서 데이터를 읽는다. // 임계구역 코드
뮤텍스(M)를 연다;
V(W); // 세마포 W에 대해 V 연산 수행
// 대기 중인 생산자를 깨운다.
}-
P(R):
- 읽기 가능한 버퍼가 없으면 대기.
-
뮤텍스 잠금:
- 공유 버퍼에서 데이터를 읽는 동안 다른 스레드가 접근하지 못하도록 보호.
-
뮤텍스 해제:
- 데이터를 읽은 후 다른 스레드가 접근 가능하도록 잠금 해제.
-
V(W):
- 쓰기 가능한 버퍼 공간을 늘리고 대기 중인 생산자를 깨운다.
생산자 알고리즘 (Producer)
while(true) {
P(W); // 세마포 W에 대해 P 연산 수행
// 쓰기 가능한 버퍼가 없으면 대기
뮤텍스(M)를 잠금;
공유 버퍼에 데이터를 저장한다. // 임계구역 코드
뮤텍스(M)를 연다;
V(R); // 세마포 R에 대해 V 연산 수행
// 대기 중인 소비자를 깨운다.
}-
P(W):
- 쓰기 가능한 버퍼가 없으면 대기.
-
뮤텍스 잠금:
- 공유 버퍼에 데이터를 쓰는 동안 다른 스레드가 접근하지 못하도록 보호.
-
뮤텍스 해제:
- 데이터를 쓴 후 다른 스레드가 접근 가능하도록 잠금 해제.
-
V(R):
- 읽기 가능한 버퍼 공간을 늘리고 대기 중인 소비자를 깨운다.
알고리즘 특징
-
세마포 R:
- 읽기 가능한 버퍼의 개수 관리.
-
세마포 W:
- 쓰기 가능한 버퍼의 개수 관리.
-
뮤텍스 M:
- 공유 버퍼 접근을 동기화하여 경쟁 상태를 방지.
