introduction
deep learning의 발전으로 인해 end to end의 ASR이 발전했다(Deep speech 1) 이런 end to end 방식은 HMM,clustering 고전적인 방법을 필요없게 만들었다. 이러한 양상 속에서 성능을 높힐 수 있는 방법은 모델의 size를 high computation으로 크게 하거나 모델구조를 개선하거나 데이터를 늘리는 것이다.
우리는 이러한 contribution으로 Mandarin chinese speech trascribe에서 다른 모델보다 더 나은 성능을 보였다.
method
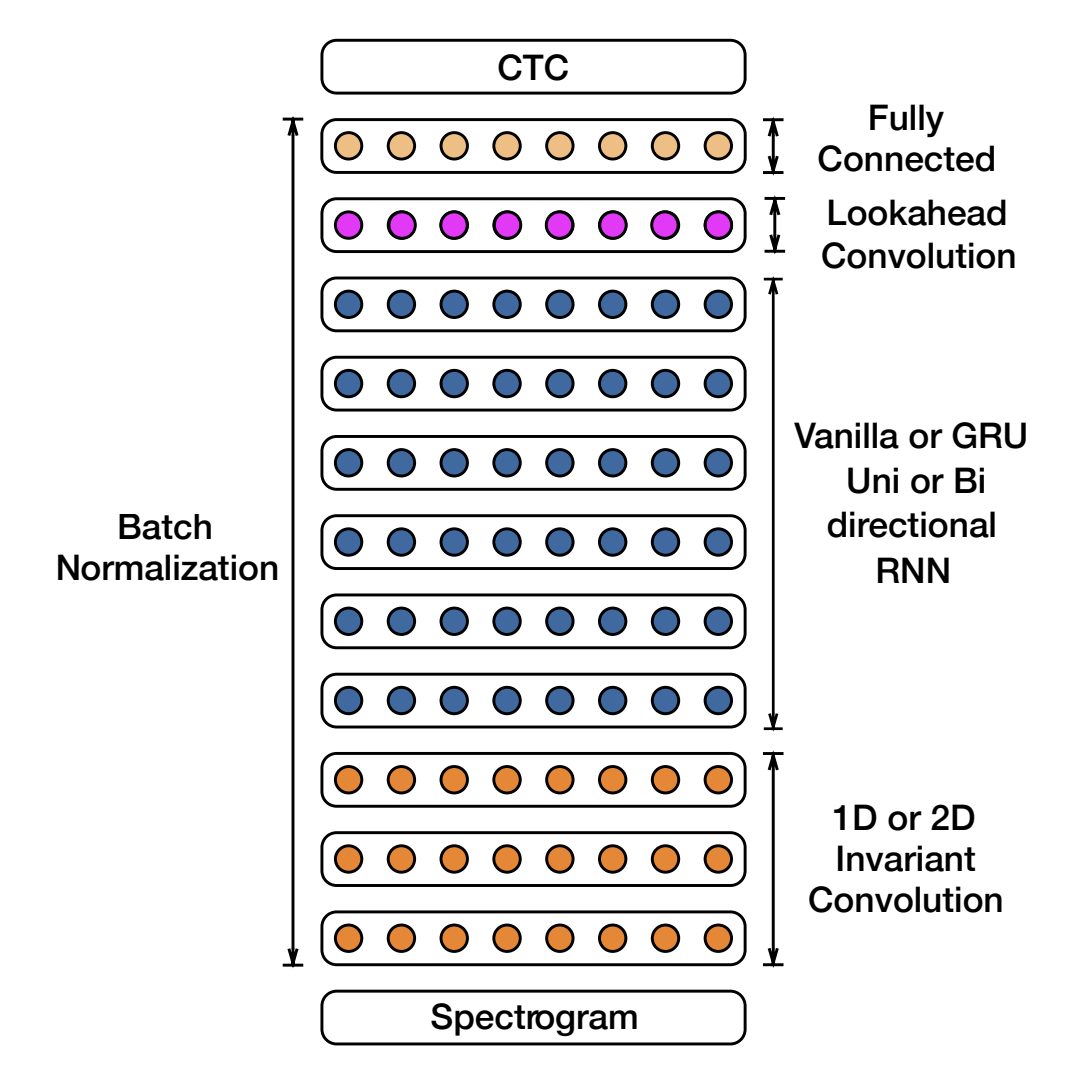
Spectrogram은 다음과 같이
convolution layer -> RNN -> FC layer -> CTC Loss 구조로 되어 있다. 차례차례로 살펴보자.
우선 input은 20ms window의 log-spectrograms이고, output은 alphabet이다.
rnn result는 {a, b, c, . . . , z,space(단어 구분), apostrophe, blank}로 변환된다.
이를 CTC LOSS 로 학습한다
CTC loss란?
kiwi 라는 단어가 있다면 이를 character 단위로 나누면 4 token이 된다.
하지만 만약 음성 인식이나 OCR을 한다고 가정하면
원본 데이터는 다음과 같은 형태일 것이다
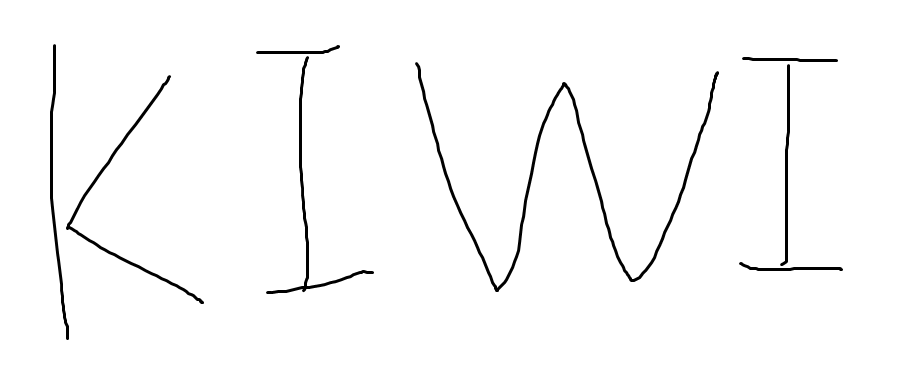
음성이나 이미지 데이터는 토큰으로 구별되는 자연어에 비해 연속된 데이터이기 때문에
target 과의 alignment가 안된다는 문제점이 있다
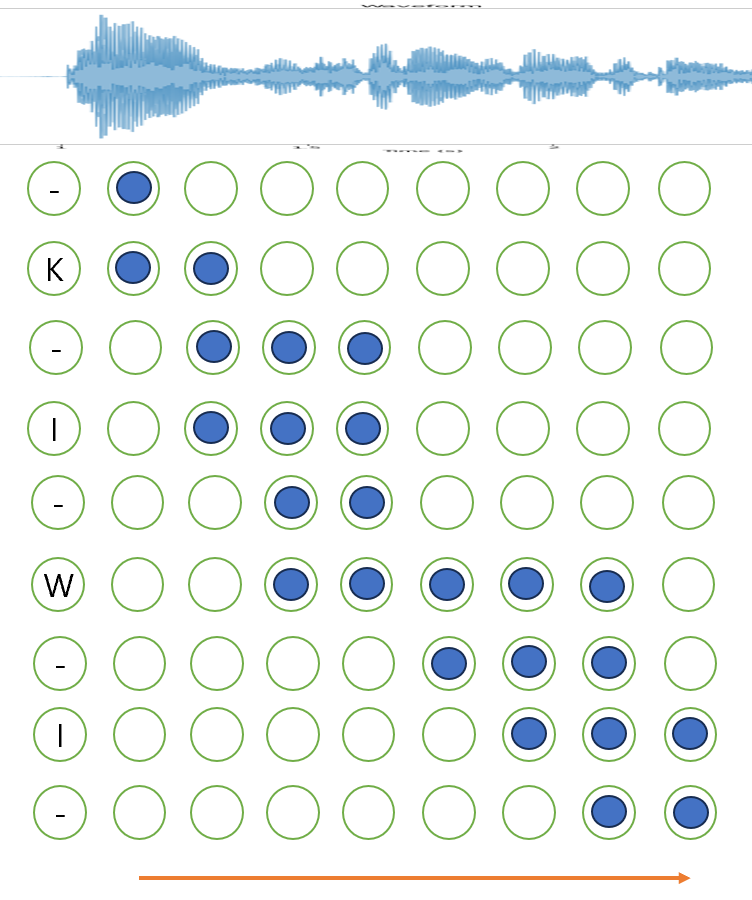
OCR을 한다하면 그림에서 보듯이 W의 크기는 I보다 크고 K 또한 I 보다 크다

손글씨를 일정한 간격으로 자른다고 할 때 K는 4칸, W는 5칸, I는 3칸을 차지한다.
따라서 이에 label을 메기면 output은 KKKKIIIWWWWWIII 가 될 것이다.
이를 음성에 적용을 해도 일정 간격으로 자른다고 하면
KKKIIIII WWWWW II
이런 형태로 라벨링이 될 것이다
이러한 연속적인 데이터의 라벨링 특성을 고려해서 세우는 LOSS식이 CTC loss이다.
output의 후보가 [K,I,W,' ']라고 하고 input segment가 20 개이면
경우의 수는 4^20 이다.
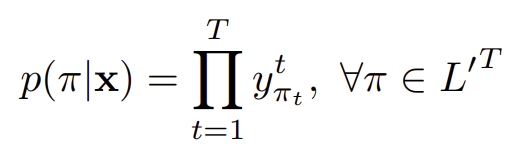
결과 ㅠ가 나올 확률은 위 식과 같이 계산 가능하다.
이때 output을 출력하는 parameter는 해당 확률을 argmax 하는 순서 ㅠ를 선택해야 한다.
그 경우의 수는 4^20이다.
이는 연산 비용이 너무 많이 든다는 한계가 있다.
이를 극복하기 위해 CTC 논문에서 t번째 state의 확률 값을 구하기 위해 DP(dynamic programming)을 사용한다.
wav를 GT transcript인 KIWI로 변환하기에 유효한 path는 여러개가 있다
그림에서와 같이
K-I-W-I-
KI--WI--
KI---WI-
KIW---I-
....
그렇다면 wav X 가 들어왔을때 transcript이 KIWI일 확률은 다음과 같이 구할 수 있다
결국 trascript의 확률을 구하기 위해서는 가능한 state의 path의 확률을 구해서 더하면 되는 것이다.
이때 CTC에서는 각 state 별로 독립이라고 가정하기 때문에 한 path의 확률을 구하기 위해서는
로 모든 timestep t 에 대한 상태의 확률을 곱해주면 된다.
그렇다면 이 상태에 대한 확률은 어떻게 구할 것인가?
만약 t=2일때 state가 'k'일 확률을 구하기 위해서는
이렇게 구해주면 된다. 이미 독립이라 가정했기에 이는 p('k') , p('-')만 알면 구할 수 있다. 이렇게 구한 의 값이 CTC score인데 이는 이전 CTC score를 알면 구할 수 있다.
마찬가지로 t=3일때 I인 CTC score는
이런 식으로 마지막이 I or '-' 인 확률도 전부 구할 수 있다.
이는 저번에 말했던 전방 확률, 후방 확률 중 전방 확률에 해당하는데
여기에 마찬가지 원리로 후방 확률을 적용할 수 있다.
t=6이 'I'일 확률을 후방 확률로 구하면
이런 식으로 모든 state에 대하여 전방 확률 , 후방 확률을 구하면 식이 다음과 같은 형태를 보인다 예를 들어 t=3이 'I'인 확률은
이 식을 정리하면 , 3번째가 'I'면서 trascript 'KIWI'를 나타낼 확률은
결국 KIWI 에 대한 확률은 그림에서 가능한 대응되는 CTC score는

해당 부분의 합이 될 것이고
이 된다. a,β 값은 전방,후방으로 구한 값이기 때문에 어떤 시점으로 고정을 해도 결국
p('KIWI'|X)의 값은 똑같다고 한다.
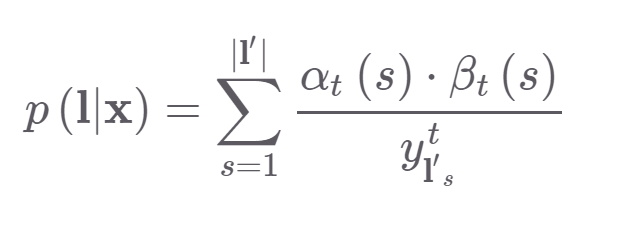
그래서 trascript의 확률 식은 다음과 같고
gradient를 구하기 위해 미분하면

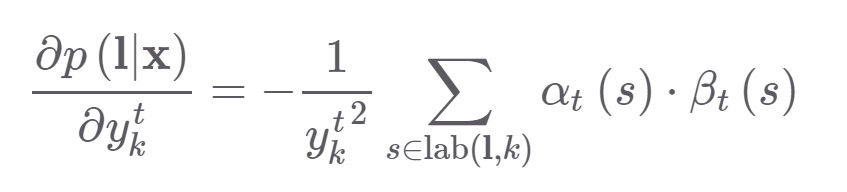
이렇게 되서 전방,후방 state를 기록한 값과 확률 값으로 gradient를 구할 수 있다.
CTC에서 추론 시에는 beam search를 사용한다고 한다
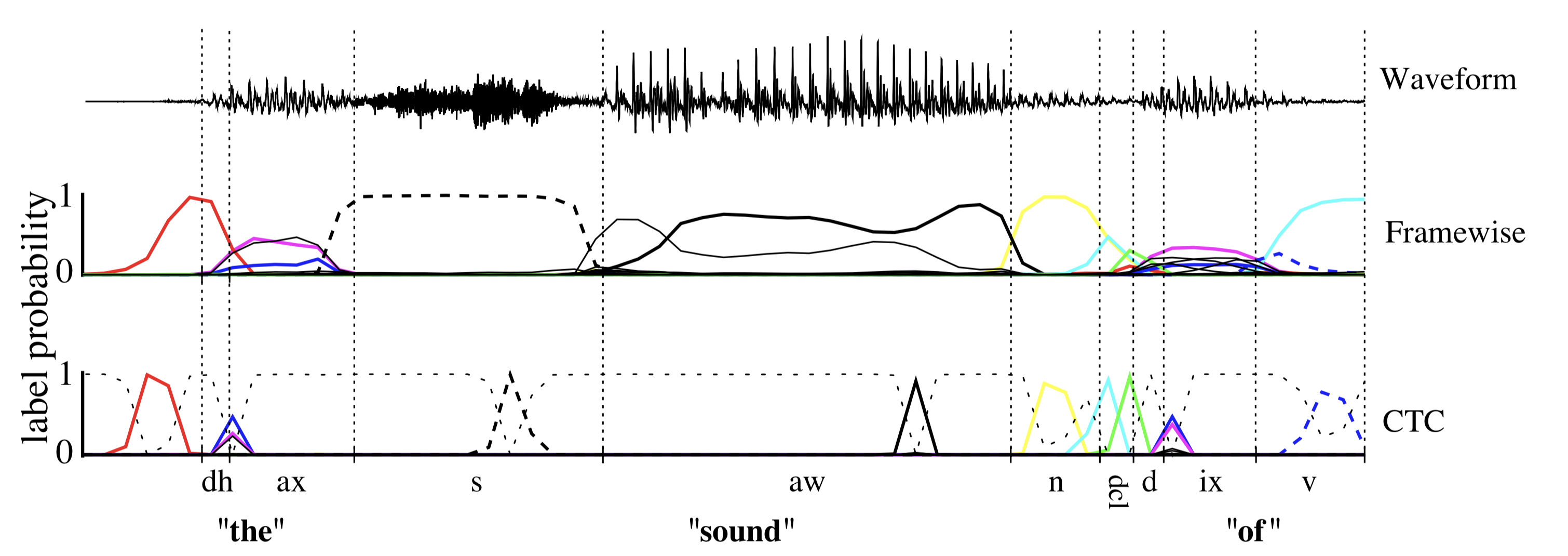
CTC를 적용하면 추론할 때 trascript로 보는 영역이 이렇게 좁고 peaky하게 나온다고 한다
이는 짧게 label이 붙여진다는 단점이 있다.
이제 이러한 CTC로 학습을 한다는걸 알았으니 deep speech2로 돌아와서 추론을 이어나가겠다
deepspeech의 추론 식은 해당 식을 maximize하는 y를 출력한다
Q(y) = log(pRNN(y|x)) + α log(pLM(y)) + βwc(y)
pRNN(y|x) - RNN으로 부터 나온 character 확률
log(pLM(y)) - 언어모델의 확률
wc(y) - trascript에서 단어의 number (이것이 왜 효과 있는지 모르겠음 길면 길수록 점수를 준다?)
α ,β 는 추론 시 설정하는 hyper parameter
batch normalization
layer를 깊게 이어붙이면 gradient descent가 전달되기 어렵다.
따라서 배치 정규화를 실행한다.
배치 정규화는 deep layer에서 데이터에 대해 더욱 generalization을 할 뿐만 아니라 , 수렴 속도도 더욱 빠르게 한다.
RNN에 batch norm의 식은 다음과 같다.
(batch norm 효과 연구된게 2015년이라 식을 자세하게 쓰는 듯함)
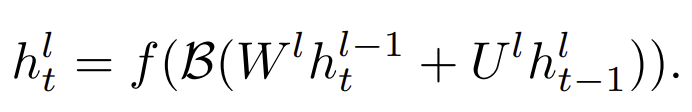
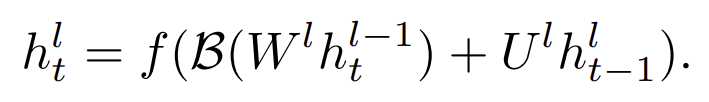
batch norm을 하는 두 가지 방법 중 첫번째 식은 layer-wise , 두번째는 sequence-wise 방식이다.
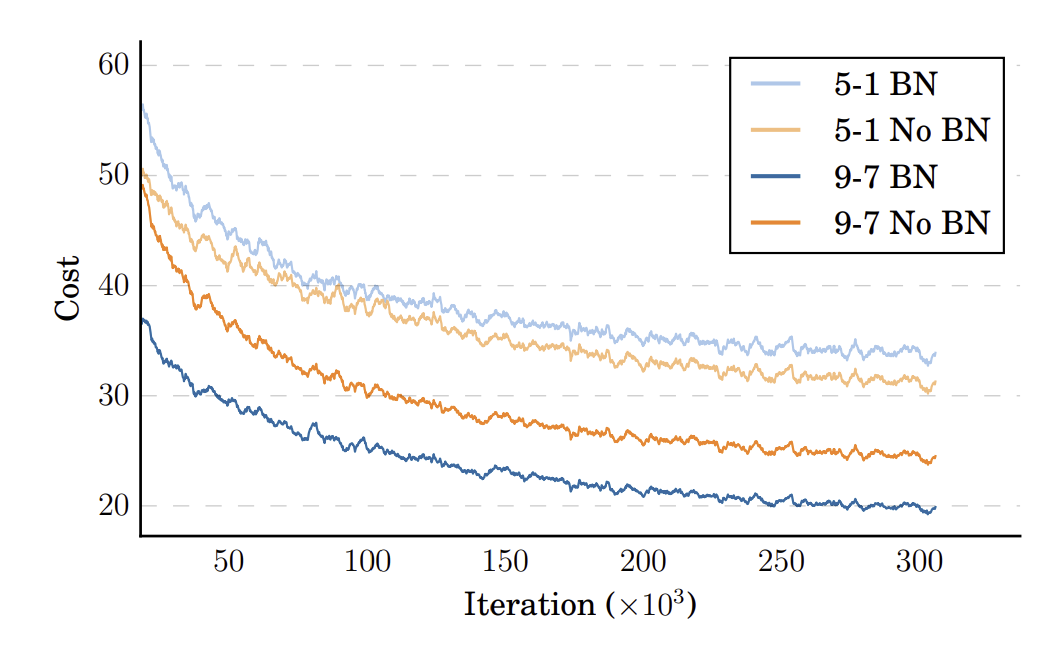
sequence-wise를 적용했을때 no-batch norm 보다 빠르게 수렴하며 성능도 좋다.
//왜 layer norm안하고 batch 하는거지?
SortaGrad
CTC loss를 적용한 학습 또한 불안정하다. 매우 깊은 layer에 대하여 gradient exploding을 하기도 하고 gradient descent로 인해서 very long script에 대해서는 거의 zero의 확률 값을 계산한다.
layer가 깊어지면 tuning 안된 파라미터로 인한 loss값이 매우 커지기 때문에 학습 과정이 불안정하다.
이러한 단점을 극복하기 위해 우리는 SortaGrad라고 부르는 curriculumn learning을 적용한다
** curriculum learning이란? 2009년에 제안된 무작위로 학습하는 대신 학습 방법으로 '난이도'가 낮은 데이터부터 높은 데이터 순서로 학습을 진행하는 것. generalization에 더욱 효과적이다.
여기서는 trasncript의 length를 '난이도'로 보고 , length가 낮은 데이터부터 순차적으로 학습한다.
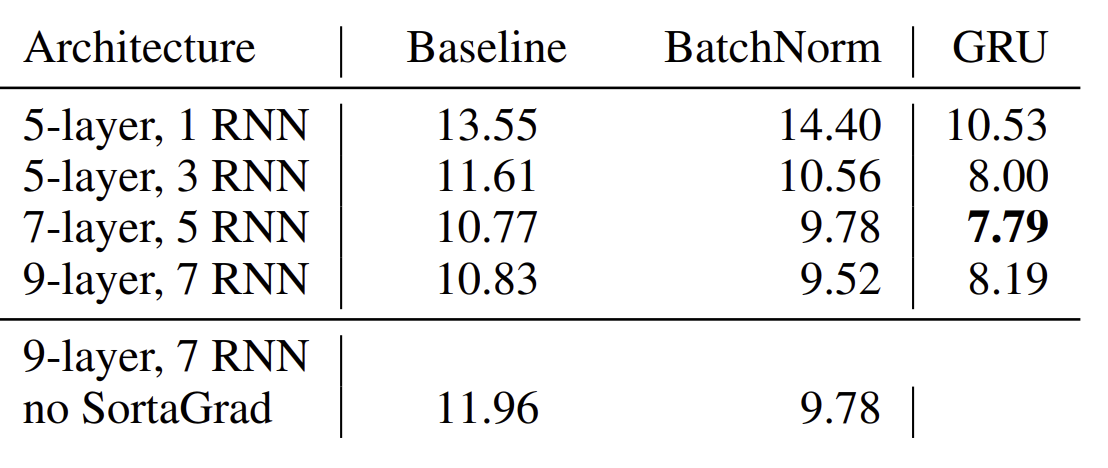
<SortaGrad를 적용한 결과>
frequence convolution
초기 layer에서 convolution을 1d 또는 2d로 선택했다.
1d는 time에 대해서만 conv를 적용하고
2d는 time,frequency domain에 대해서 conv를 적용한다
1D or 2D와 layer 수를 비교해서 결과를 비교해보았다.

1 layer 1D에서 3 layer 2D로 바꾸었더니 최대 WER가 23%이상 개선되었다. 이로써 frequency domain 도 conv 하는게 더욱 성능을 향상 시켜준다는 것을 보인다.
lookahead convolution
데이터가 계속 online 으로 들어오는 음성인식 같은 경우 bidirectional RNN을 사용하기에는 무리가 있다. 하지만 uni RNN은 그보다 성능이 떨어진다. 따라서 여기서는
미래의 context를 반영하는 lookahead convolution을 적용한다
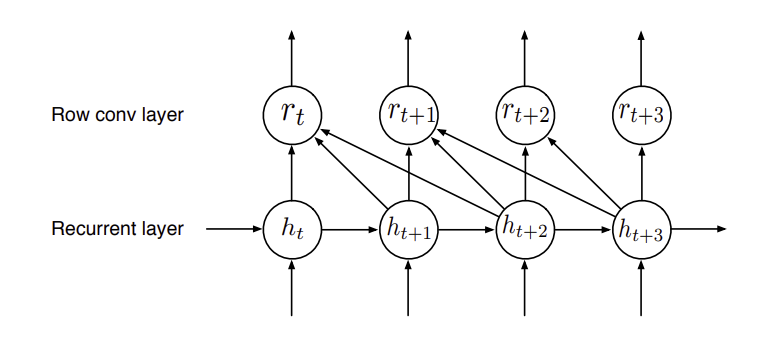
rnn의 결과물에서 context를 2로 했을때 2단계 미래의 vector도 반영하여 취합한다. 이렇게 해서 더욱 fine graned output이 가능하다고 한다
Training data
엄청나게 큰 data를 학습에 사용한다
영어에는 11940 hours의 8 million utterances 사용하며
중국어에는(Mandarian) 9400 hours의 11 million utterances 사용한다
data construction
deepspeech는 데이터 구축에서도 contribution이 크다.
음성 데이터는 몇 시간동안 이어지는 것도 있으며 이를 학습에 넣기에는 어렵다.
우선 transcript이 있는 데이터로 CTC loss + biRNN 으로 학습을 한다.
그리고 보유한 음성 데이터를 넣어서 output으로 blank가 지속적으로 출현하면 그 부분을 segment한다
또한 음성과 transcript이 불일치한 경우도 있다. 그래서 수천 명의 크라우드 소싱을 통해 음성 trascript을 만들고 이 음성을 학습한 모델에 넣어서 정답과 너무 차이가 나면 그 데이터는 버린다.
거기에 데이터에 noise를 더해 robustness를 키운다. 실험에서 40% 랜덤으로 noise를 더하니까 성능이 더욱 좋아졌다고 한다.
results

clean한 데이터는 human을 뛰어넘었다
accent는 human과 보다 약간 못하며
noisy는 사람보다 많이 못했다.
합성적인 noise를 사용한다고 real noise를 커버하는건 아닌 것을 볼 수 있다.
다만 이 모델은 1d conv를 사용했다고 한다 (2d 는 아직 거의 안쓰기에)
code
16년에 나온 논문인지라 코드는 어려운 편은 아니다.
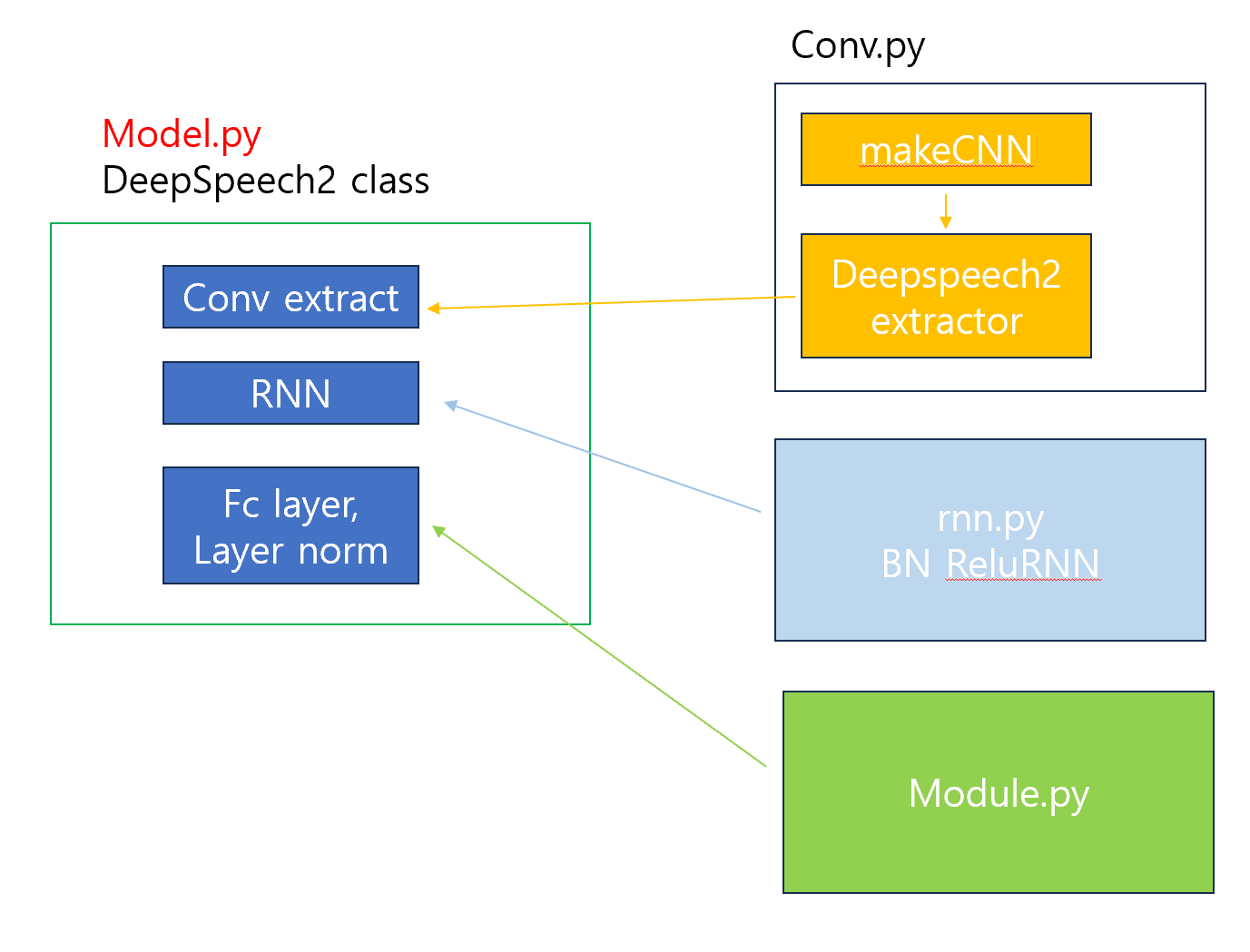
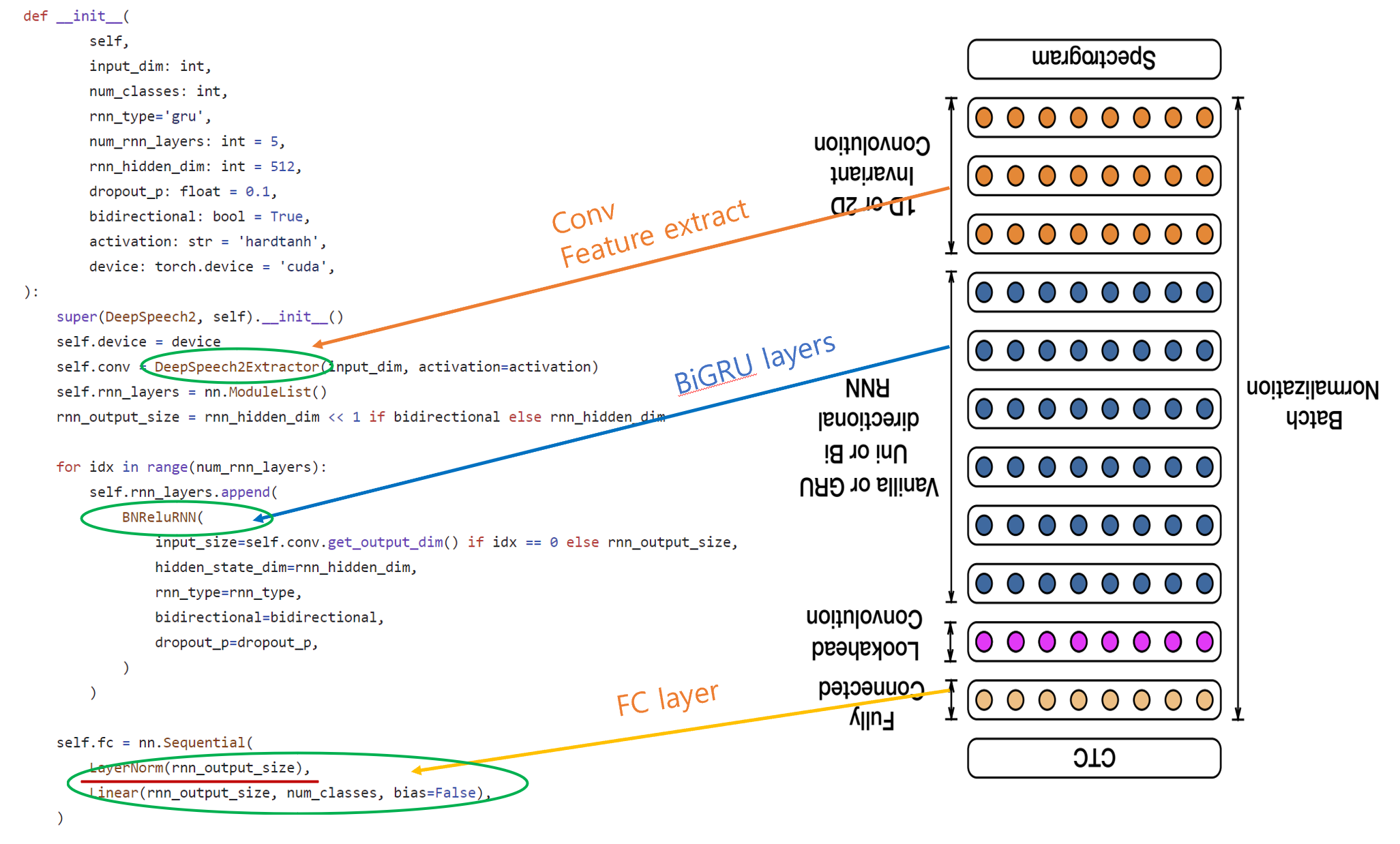
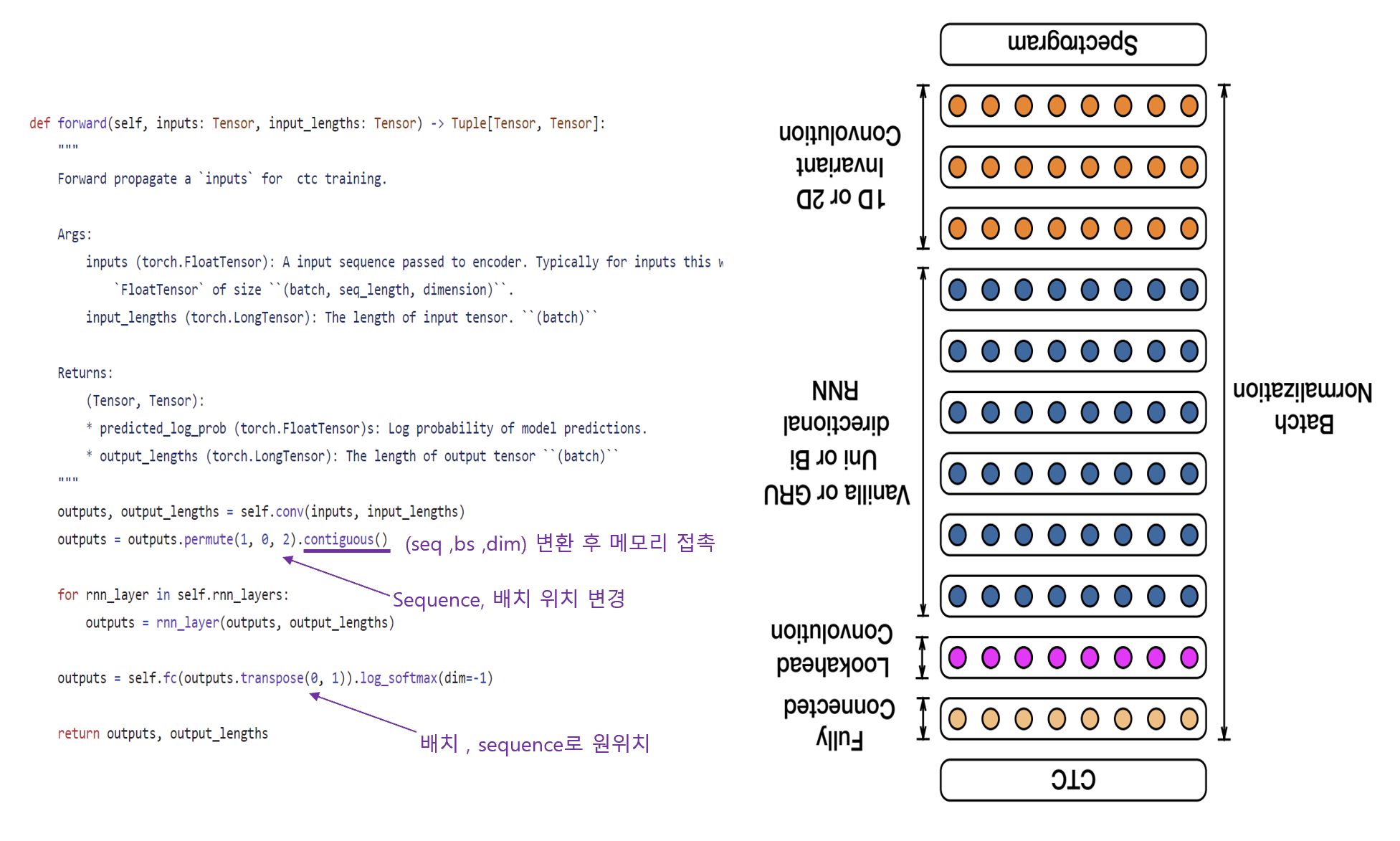



<<학습 코드>>



CTC loss 가 어떻게 작동하는지 알 수 있는 유익한 포스트네요! 좋은 정리 감사합니다