
DBtoFile 혹은 FiletoDB 스프링배치 개발시 ItemWriter에서 파일을 처리할 때 파일을 인코딩하는 방식을 지정해줘야 했다. 이 때 EUC-KR과 UTF-8 중 어느 방식을 선택해야 할지 고민이 되었다. 인코딩이란 무엇이고 어떤 경우에 어떤 방식을 선택해야 할까?
인코딩(Encoding)
컴퓨터는 0과 1로만 이루어진 바이너리 숫자(2진수)로 데이터를 저장.
따라서 컴퓨터는 숫자, 알파벳, 한글 등을 표현하기 위해 우리가 사용하는 문자들과 대응하는 숫자를 매핑한다. 예를들면 65 = 'A', 66 = 'B'. 65와 66은 다시 바이너리 숫자로 매핑된다.
이처럼 사용자가 입력한 문자나 숫자들을 컴퓨터가 이해할 수 있는 신호로 변환하는 작업을 인코딩이라 한다.
ASCII
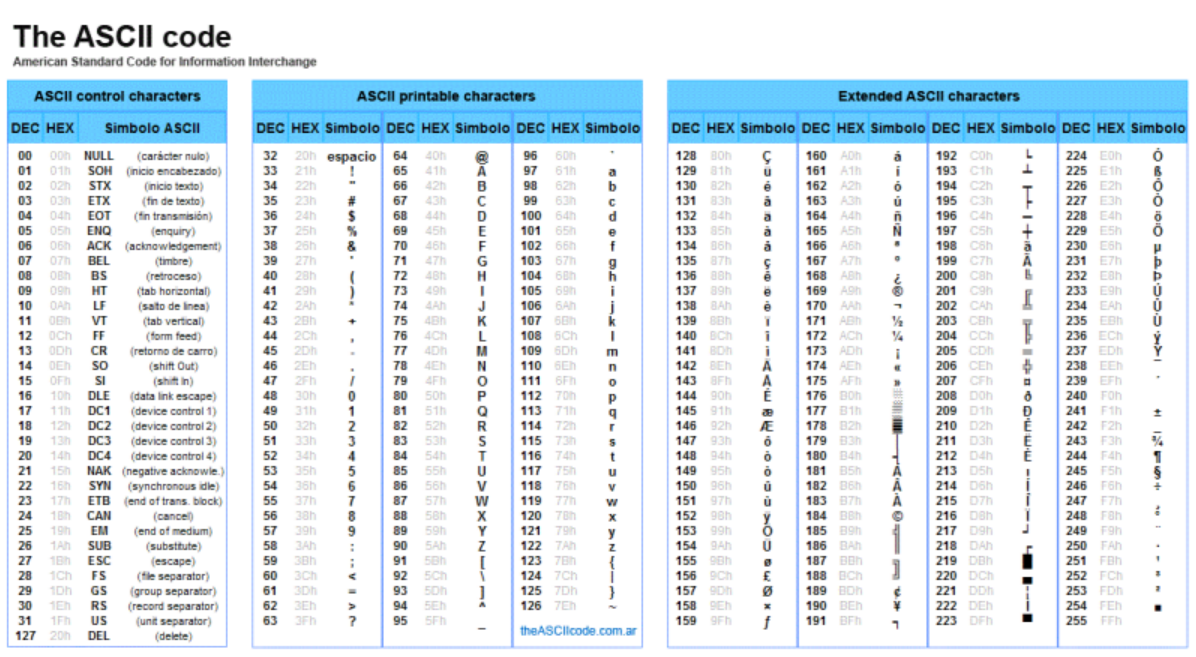
1960년대 ANSI에서 표준화한 7비트 부호 체계로, 영문 알파벳을 사용하는 대표적인 문자 인코딩이다. 아스키코드표는 128개 문자 테이블로 이루어져 있다.
그러나 아스키는 1바이트로 문자를 처리하기 때문에 영어,숫자,기본기호 외 특정 국가에서 사용되는 문자 처리 등 2바이트 이상의 다양한 코드를 표현해야 하는 필요성이 대두됨에 따라 현대에는 유니코드를 더 많이 사용하고 있다.
유니코드
전 세계의 모든 문자를 다루도록 설계된 표준 문자 전산 처리 방식으로, 16바이트로 문자를 처리한다. 유니코드를 사용한 인코딩 방식에는 UTF-8, UTF-16, UTF-32 등이 있고 이 중에서 ASCII와 호환이 가능하면서 가장 크기가 가벼운 UTF-8을 많이 사용한다.
UTF-8
유니코드 범위에 따라 1 ~ 4byte로 인코딩하는 가장 많이 사용되는 가변 길이 유니코드 인코딩.
한글 1글자는 3바이트, 알파벳과 숫자는 1바이트.
사용 빈도가 높은 문자는 적은 공간을 차지하고 사용 빈도가 낮은 문자는 많은 저장 공간을 차지하게 하기 위해 문자마다 다른 크기를 할당.
조합형 인코딩 방식.
e.g.)안녕하세요 -> ㅇ ㅏ ㄴ ㄴ ㅕ ㅇ ㅎ ㅏ ㅅ ㅔ ㅇ ㅛ

EUC-KR
EUC의 일종이며 대표적인 8비트 한글 완성형 인코딩.
한글 1글자는 2바이트, 알파벳과 숫자는 1바이트.
완성형 인코딩 방식.
EUC-KR 경우에는 완성된 단어가 있어야만 표현이 되고, UTF-8의 경우에는 모음 자음으로 나누어져서 조합을 통해 글자가 완성되어 표현. EUC-KR의 경우 완성된 문자가 없을 경우에는 한글이 깨져 보일 수 있다.
e.g.)안녕하세요 -> 안 녕 하 세 요

스프링배치 FIXED 파일 처리 시 문자 인코딩 방식 (UTF-8 vs. EUC-KR)
- UTF-8 방식에서 한자나 한글은 주로 3바이트 영역에 집중되어 있기 때문에 한글로 작성된 파일의 경우 EUC-KR이나 UTF-16에 비해서 파일 크기가 최대 1.5배로 늘어난다.
- FIXED 파일 처리 시 UTF-8이면 한글 한 글자당 3바이트, EUC-KR이면 한글 한 글자당 2바이트 할당.
- 한글 파일을 UTF-8로 인코딩할 경우 가변 길이 방식이기 때문에 길이가 어긋나 잘못된 데이터가 처리될 수 있다.
-> 따라서 한글 파일의 경우 EUC-KR 을 사용하는 것이 안전.
Reference
https://coding-factory.tistory.com/810
https://m.blog.naver.com/ycpiglet/222146759413
https://inkim0927.tistory.com/65
https://namu.wiki/w/%EC%9C%A0%EB%8B%88%EC%BD%94%EB%93%9C
https://gnam.tistory.com/12
https://jcon.tistory.com/135
