소유권 이해하기
소유권은 Rust의 가장 독특한 기능이며 언어에 깊은 영향을 미칩니다.
가비지 컬렉터 없이도 메모리 안전성을 보장할 수 있으므로,
소유권이 어떻게 작동하는지 이해하는 것이 중요합니다.
이 장에서는 소유권과 관련된 몇 가지 기능, 즉 차용, 슬라이스, Rust가 메모리에 데이터를 배치하는 방법에 대해 설명합니다.
소유권이란?
소유권은 Rust 프로그램이 메모리를 관리하는 방법을 규정하는 일련의 규칙입니다.
모든 프로그램은 실행 중 컴퓨터의 메모리를 사용하는 방식을 관리해야 합니다.
일부 언어에는 프로그램이 실행되는 동안 더 이상 사용되지 않는 메모리를 정기적으로 찾는 가비지 컬렉션이 있으며,
다른 언어에서는 프로그래머가 명시적으로 메모리를 할당하고 해제해야 합니다.
Rust는 세 번째 접근 방식을 사용합니다.
메모리는 컴파일러가 검사하는 일련의 규칙이 있는 소유권 시스템을 통해 관리됩니다.
규칙 중 하나라도 위반되면 프로그램이 컴파일되지 않습니다.
소유권 기능 중 어떤 것도 프로그램이 실행되는 동안 속도를 저하시키지 않습니다.
소유권은 새로운 개념이기 때문에 많은 프로그래머은 익숙해지는 데 시간이 좀 걸립니다.
좋은 소식은 Rust와 소유권 시스템의 규칙에 익숙해질수록 안전하고 효율적인 코드를 자연스럽게 개발하는 것이 더 쉬워진다는 것입니다.
소유권을 이해하면 Rust의 고유한 기능을 이해할 수 있는 탄탄한 기초를 다질 수 있습니다.
이 장에서는 매우 일반적인 데이터 구조인 문자열에 초점을 맞춘 몇 가지 예제를 통해 소유권을 배우게 됩니다.
스택과 힙
많은 프로그래밍 언어에서는 스택과 힙에 대해 자주 생각하지 않아도 됩니다.
하지만 Rust와 같은 시스템 프로그래밍 언어에서는,
값이 스택에 있는지 힙에 있는지가 언어의 동작 방식과 특정 결정을 내려야 하는데 영향을 미칩니다.
소유권의 일부는 이 장의 뒷부분에서 스택과 힙과 관련하여 설명할 것이므로,
여기서는 이에 대비하여 간략하게 설명합니다.
스택과 힙은 모두 코드에서 런타임에 사용할 수 있는 메모리의 일부이지만 구조는 서로 다릅니다.
스택은 값을 가져온 순서대로 값을 저장하고 반대 순서로 값을 제거합니다.
이를 후입선출이라고 합니다.
접시 더미를 생각해보세요.
접시를 더 추가할 때 접시를 더미 위에 올려놓고, 접시가 필요하면 위에서 접시를 하나씩 떼어내면 됩니다.
중간이나 아래에서 접시를 추가하거나 제거하면 잘 작동하지 않습니다.
데이터를 더하는 것을 스택에 밀어 넣기, 데이터를 제거하는 것을 스택에서 꺼내기라고 합니다.
스택에 저장된 모든 데이터는 알려진 고정된 크기여야 합니다.
컴파일 시 크기를 알 수 없거나 크기가 변경될 수 있는 데이터는 힙에 저장해야 합니다.
힙은 덜 체계적입니다.
데이터를 힙에 넣을 때 일정량의 공간을 요청합니다.
메모리 할당자는 힙에서 충분히 큰 빈 자리를 찾아 사용 중인 것으로 표시하고 해당 위치의 주소인 포인터를 반환합니다.
이 프로세스를 힙에 할당하기라고 하며 그냥 할당하기라고 줄여서 부르기도 합니다(스택에 값을 푸시하는 것은 할당으로 간주되지 않음).
힙에 대한 포인터는 알려진 고정된 크기이므로 스택에 포인터를 저장할 수 있지만 실제 데이터를 원할 때는 포인터를 따라가야 합니다.
식당에 앉아 있다고 생각해보세요.
입장할 때 그룹 인원을 말하면 호스트가 모두에게 맞는 빈 테이블을 찾아서 그 자리로 안내합니다.
그룹 중 누군가가 늦게 오면 호스트는 사용자가 어디에 앉았는지 물어보고 사용자를 찾을 수 있습니다.
스택으로 푸시하는 것이 힙에 할당하는 것보다 빠른 이유는,
할당자가 새 데이터를 저장할 위치를 검색할 필요가 없고 해당 위치가 항상 스택의 맨 위에 있기 때문입니다.
이에 비해 힙에 공간을 할당하려면 할당자가 먼저 데이터를 저장할 수 있는 충분한 공간을 찾은 다음 다음,
할당을 준비하기 위해 장부 정리를 수행해야 하므로 더 많은 작업이 필요합니다.
힙에 있는 데이터에 액세스하는 것은 포인터를 따라가야 하기 때문에 스택에 있는 데이터에 액세스하는 것보다 느립니다.
최신 프로세서는 메모리를 덜 뛰어다니기 때문에 더 빠릅니다.
비유를 계속 이어서, 여러 테이블에서 주문을 받는 레스토랑의 서버를 생각해 보겠습니다.
다음 테이블로 이동하기 전에 한 테이블에서 모든 주문을 받는 것이 가장 효율적입니다.
A 테이블에서 주문을 받은 다음 B 테이블에서 주문을 받고,
다시 A 테이블에서 주문을 받고, 다시 B 테이블에서 주문을 받는 것은 훨씬 느린 프로세스가 될 것입니다.
마찬가지로 프로세서는 멀리 있는 데이터(힙에 있는 데이터)보다는 다른 데이터와 가까운 데이터(스택에 있는 데이터)에서 작업할 때 더 나은 성능을 발휘할 수 있습니다.
코드가 함수를 호출하면 함수에 전달된 값(힙에 있는 데이터에 대한 포인터 포함)과 함수의 지역 변수가 스택에 푸시됩니다.
함수가 끝나면 해당 값은 스택에서 튀어나옵니다.
코드의 어떤 부분이 힙에서 어떤 데이터를 사용하는지 추적하고,
힙에서 중복되는 데이터의 양을 최소화하고,
힙에서 사용하지 않는 데이터를 정리하여 공간이 부족해지지 않도록 하는 것은 모두 소유권으로 해결할 수 있는 문제입니다.
소유권을 이해하면 스택과 힙에 대해 자주 생각할 필요는 없지만,
소유권의 주된 목적이 힙 데이터를 관리하는 것임을 알면 소유권이 왜 그런 식으로 작동하는지 설명하는 데 도움이 될 수 있습니다.
소유권 규칙
먼저 소유권 규칙을 살펴봅시다.
이 규칙을 설명하는 예제를 살펴보면서 이 규칙을 염두에 두세요:
- Rust에서는 모든값은 소유권이 있습니다.
- 소유자는 한 번에 한 명만 있을 수 있습니다.
- 소유자가 범위를 벗어나면 값이 삭제됩니다.
변수 범위
이제 기본 Rust 구문을 넘어섰으므로,
예제에 모든 fn main() { 코드를 포함하지 않으므로,
따라 하려면 다음 예제를 메인 함수 안에 수동으로 넣어야 합니다.
그 결과, 예제가 좀 더 간결해져서 상용구 코드가 아닌 실제 세부 사항에 집중할 수 있습니다.
소유권의 첫 번째 예로 몇 가지 변수의 범위를 살펴보겠습니다.
범위는 프로그램 내에서 항목이 유효한 범위입니다.
다음 변수를 예로 들어 보겠습니다:
let s = "hello";변수 s는 문자열을 나타내며,
여기서 문자열 값은 프로그램의 텍스트에 하드코딩됩니다.
변수는 선언된 시점부터 현재 범위가 끝날 때까지 유효합니다.
목록 4-1은 변수 s가 유효할 수 있는 위치를 주석으로 표시한 프로그램을 보여줍니다.
{ // s is not valid here, it’s not yet declared
let s = "hello"; // s is valid from this point forward
// do stuff with s
} // this scope is now over, and s is no longer valid
목록 4-1: 변수 및 변수가 유효한 범위
다시 말해, 여기에는 두 가지 중요한 시점이 있습니다:
- s가 범위에 포함되면 유효합니다.
- 범위를 벗어날 때까지 유효합니다.
이 시점에서 범위와 변수가 유효한 시점의 관계는 다른 프로그래밍 언어의 관계와 유사합니다.
이제 이러한 이해를 바탕으로 문자열 유형을 소개하겠습니다.
문자열 타입
소유권 규칙을 설명하기 위해서는 3장의 '데이터 타입' 섹션에서 다룬 것보다 더 복잡한 데이터 타입이 필요합니다.
앞에서 다룬 타입은 크기가 알려져 있고, 스택에 저장했다가 해당 범위가 끝나면 스택에서 꺼낼 수 있으며,
코드의 다른 부분에서 다른 범위에서 동일한 값을 사용해야 하는 경우 빠르고 간단하게 복사하여 새로운 독립적인 인스턴스를 만들 수 있습니다.
하지만 우리는 힙에 저장된 데이터를 살펴보고 Rust가 언제 해당 데이터를 정리해야 하는지 알고 있는 방법을 살펴보고자 하며, 문자열 유형이 좋은 예입니다.
여기서는 소유권과 관련된 문자열 부분을 집중적으로 살펴보겠습니다.
이러한 측면은 표준 라이브러리에서 제공하든 사용자가 직접 만들든 다른 복잡한 데이터 유형에도 적용됩니다.
문자열에 대해서는 8장에서 더 자세히 설명하겠습니다.
이미 문자열 값을 프로그램에 하드코딩하는 문자열을 살펴본 바 있습니다.
문자열 리터럴은 편리하지만 텍스트를 사용해야 하는 모든 상황에 적합하지는 않습니다.
한 가지 이유는 불변이기 때문입니다.
또 다른 이유는 코드를 작성할 때 모든 문자열 값을 알 수 없다는 것입니다.
예를 들어 사용자 입력을 받아 저장하려는 경우 어떻게 해야 할까요?
이러한 상황에 대비해 Rust에는 두 번째 문자열 유형인 String이 있습니다.
이 유형은 힙에 할당된 데이터를 관리하므로 컴파일 시점에 알 수 없는 양의 텍스트를 저장할 수 있습니다.
다음과 같이 from 함수를 사용하여 문자열 리터럴에서 문자열을 생성할 수 있습니다:
let s = String::from("hello");이중 콜론 :: 연산자를 사용하면 string_from과 같은 이름을 사용하는 대신 문자열 유형 아래에서 이 특정 from 함수의 네임스페이스를 지정할 수 있습니다.
이 구문에 대해서는 5장의 "메서드 구문" 섹션과 7장의 "모듈 트리에서 항목을 참조하는 경로"에서 모듈을 사용한 네임스페이스에 대해 설명할 때 자세히 설명하겠습니다.
이러한 종류의 문자열은 값을 변경할 수 있습니다:
let mut s = String::from("hello");
s.push_str(", world!"); // push_str() appends a literal to a String
println!("{}", s); // This will print `hello, world!`
그렇다면 여기서 차이점은 무엇일까요?
String은 변형을 할 수 있지만 문자열 하드코딩은 변형을 할 수 없는 이유는 무엇일까요?
이 두 가지 유형의 차이점은 메모리를 처리하는 방식에 있습니다.
메모리와 할당
문자열 하드코딩의 경우 컴파일 시점에 내용을 알 수 있으므로 텍스트가 최종 실행 파일에 직접 하드코딩됩니다.
이것이 바로 문자열 리터럴이 빠르고 효율적인 이유입니다.
하지만 이러한 속성은 문자열 리터럴의 불변성에서 비롯된 것입니다.
안타깝게도 컴파일 시에는 크기를 알 수 없고 프로그램을 실행하는 동안 크기가 변경될 수 있는 각 텍스트 조각에 대해 바이너리에 메모리 덩어리를 넣을 수는 없습니다.
String 유형을 사용하면 변경 가능하고 확장 가능한 텍스트를 지원하려면 컴파일 시점에 알 수 없는 양의 메모리를 힙에 할당하여 내용을 저장해야 합니다. 즉:
- 메모리는 런타임에 메모리 할당자에게 요청해야 합니다.
- String 작업이 끝나면 이 메모리를 할당자에게 반환하는 방법이 필요합니다.
첫 번째 부분은 우리가 처리합니다.
String::from을 호출하면 해당 구현이 필요한 메모리를 요청합니다.
이는 프로그래밍 언어에서 거의 보편적인 방식입니다.
하지만 두 번째 부분은 다릅니다.
가비지 컬렉터(GC)가 있는 언어에서는 GC가 더 이상 사용되지 않는 메모리를 추적하고 정리하기 때문에 우리는 이에 대해 생각할 필요가 없습니다.
GC가 없는 대부분의 언어에서는 메모리가 더 이상 사용되지 않는 시점을 식별하고 요청할 때와 마찬가지로 코드를 호출하여 명시적으로 메모리를 해제하는 것이 개발자의 책임입니다.
이 작업을 올바르게 수행하는 것은 역사적으로 어려운 프로그래밍 문제였습니다.
잊어버리면 메모리를 낭비하게 됩니다.
너무 일찍 해제하면 유효하지 않은 변수를 갖게 됩니다.
두 번 수행하면 그것도 버그가 됩니다.
정확히 하나의 할당과 정확히 하나의 여유 공간이 짝을 이루어야 합니다.
Rust는 다른 방식을 사용합니다.
메모리를 소유한 변수가 범위를 벗어나면 메모리가 자동으로 반환됩니다.
다음은 문자열 하드코딩 대신 문자열을 사용하는 목록 4-1의 범위 예제 버전입니다:
{
let s = String::from("hello"); // s is valid from this point forward
// do stuff with s
} // this scope is now over, and s is no
// longer valid문자열에 필요한 메모리를 할당자에게 반환할 수 있는 자연스러운 시점이 있는데,
바로 s가 범위를 벗어날 때입니다.
변수가 범위를 벗어나면 Rust는 우리를 위해 특별한 함수를 호출합니다.
이 함수를 drop이라고 하며, String 작성자가 메모리를 반환하는 코드를 넣을 수 있는 곳입니다. Rust는 닫는 중괄호에서 자동으로 drop을 호출합니다.
참고: C++에서는 항목의 수명이 다할 때 리소스를 할당 해제하는 이 패턴을 리소스 획득 초기화(RAII)라고 부르기도 합니다. RAII 패턴을 사용해 본 적이 있다면 Rust의 드롭 함수가 익숙할 것입니다.
이 패턴은 Rust 코드 작성 방식에 큰 영향을 미칩니다.
지금은 간단해 보일 수 있지만, 힙에 할당된 데이터를 여러 변수가 사용하게 하려는 복잡한 상황에서는 코드의 동작이 예상치 못한 결과를 초래할 수 있습니다.
이제 이러한 상황 중 몇 가지를 살펴보겠습니다.
이동과 상호 작용하는 변수 및 데이터
Rust에서는 여러 변수가 동일한 데이터와 다양한 방식으로 상호 작용할 수 있습니다.
목록 4-2에서 정수를 사용하는 예제를 살펴보겠습니다.
let x = 5;
let y = x;
목록 4-2: 변수 x의 정수 값을 y에 할당하기
이것이 무엇을 하는지 짐작할 수 있을 것입니다:
"값 5를 x에 바인딩한 다음 x에 있는 값의 복사본을 만들어 y에 바인딩합니다."
이제 x와 y라는 두 개의 변수가 생겼고 둘 다 5와 같습니다.
정수는 알려진 고정된 크기의 단순한 값이고, 이 두 개의 5 값이 스택에 푸시되기 때문에 실제로 이런 일이 일어나고 있습니다.
이제 String 버전을 살펴보겠습니다:
let s1 = String::from("hello");
let s2 = s1;
이것은 매우 유사해 보이므로 작동 방식이 동일할 것이라고 가정할 수 있습니다.
즉, 두 번째 줄이 s1의 값을 복사하여 s2에 바인딩하는 것입니다.
하지만 실제로는 그렇지 않습니다.
그림 4-1을 살펴보면 문자열에 어떤 일이 일어나는지 알 수 있습니다.
문자열은 왼쪽에 표시된 것처럼 문자열의 내용을 담고 있는 메모리에 대한 포인터, 길이, 용량의 세 부분으로 구성됩니다.
이 데이터 그룹은 스택에 저장됩니다.
오른쪽은 힙에 있는 메모리로 내용을 담고 있습니다.
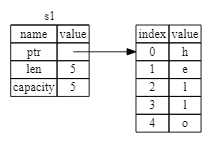
그림 4-1: s1에 바인딩된 "hello" 값이 있는 문자열의 메모리 표현
길이는 문자열의 콘텐츠가 현재 사용하고 있는 메모리 양(바이트)입니다.
용량은 문자열이 할당자로부터 받은 총 메모리 양(바이트)입니다.
길이와 용량의 차이는 중요하지만 이 컨텍스트에서는 중요하지 않으므로 지금은 용량을 무시해도 괜찮습니다.
s1을 s2에 할당하면 문자열 데이터가 복사되므로 스택에 있는 포인터, 길이, 용량을 복사합니다.
포인터가 가리키는 힙의 데이터는 복사하지 않습니다.
즉, 메모리의 데이터 표현은 그림 4-2와 같습니다.
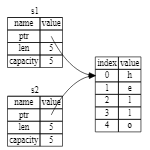
그림 4-2: s1의 포인터, 길이, 용량의 복사본이 있는 변수 s2의 메모리 내 표현
그림 4-3은 Rust가 힙 데이터도 복사하는 경우 메모리가 어떻게 보일지 보여줍니다.
Rust가 이 작업을 수행했다면,
힙의 데이터가 큰 경우 런타임 성능 측면에서 s2 = s1 연산이 매우 비쌀 수 있습니다.
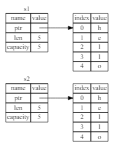
그림 4-3: Rust가 힙 데이터도 복사한 경우 s2 = s1이 수행할 수 있는 또 다른 가능성
앞서 변수가 범위를 벗어나면 Rust가 자동으로 드롭 함수를 호출하고 해당 변수에 대한 힙 메모리를 정리한다고 설명했습니다.
하지만 그림 4-2는 두 데이터 포인터가 모두 같은 위치를 가리키고 있음을 보여줍니다.
이것이 문제입니다.
s2와 s1이 범위를 벗어나면 둘 다 같은 메모리를 해제하려고 시도합니다.
이를 이중 해제 오류라고 하며 앞서 언급한 메모리 안전 버그 중 하나입니다.
메모리를 두 번 해제하면 메모리가 손상되어 잠재적으로 보안 취약점이 발생할 수 있습니다.
메모리 안전성을 보장하기 위해 Rust는 s2 = s1; 줄 이후에는 s1이 더 이상 유효하지 않은 것으로 간주합니다.
따라서 s1이 범위를 벗어날 때 Rust는 아무것도 해제할 필요가 없습니다.
s2가 생성된 후 s1을 사용하려고 하면 어떻게 되는지 확인해 보세요:
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1);
Rust에서 유효하지 않은 참조를 사용할 수 없기 때문에 이와 같은 오류가 발생합니다:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0382]: borrow of moved value:s1
--> src/main.rs:5:28
|
2 | let s1 = String::from("hello");
| -- move occurs becauses1has typeString, which does not implement theCopytrait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{}, world!", s1);
| ^^ value borrowed here after move
|
= note: this error originates in the macro$crate::format_args_nlwhich comes from the expansion of the macroprintln(in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, tryrustc --explain E0382.
error: could not compileownershipdue to previous error
다른 언어로 작업하면서 얕은 복사와 깊은 복사라는 용어를 들어본 적이 있다면,
데이터를 복사하지 않고 포인터, 길이, 용량을 복사하는 개념이 얕은 복사처럼 들릴 수 있습니다.
하지만 Rust에서는 첫 번째 변수도 무효화하기 때문에 얕은 복사라고 하는 대신 이동이라고 합니다.
이 예제에서는 s1이 s2로 이동되었다고 말할 수 있습니다.
실제로 어떤 일이 일어나는지는 그림 4-4에 나와 있습니다.
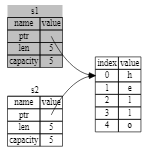
그림 4-4: s1이 무효화된 후 메모리에 표시된 모습
이제 문제가 해결되었습니다.
s2만 유효하므로 범위를 벗어나면 그 자체로 메모리를 확보할 수 있으므로 문제가 해결됩니다.
또한, 여기에는 암시적인 설계 선택이 있습니다: Rust는 데이터의 "심층" 복사본을 자동으로 생성하지 않습니다.
따라서 자동 복사는 런타임 성능 측면에서 비용이 적게 든다고 가정할 수 있습니다.
clone과 상호 작용하는 변수 및 데이터
스택 데이터뿐만 아니라 문자열의 힙 데이터까지 깊은 복사하고 싶다면,
복제라는 일반적인 메서드를 사용할 수 있습니다.
5장에서 메서드 구문에 대해 설명하겠지만, 메서드는 많은 프로그래밍 언어에서 흔히 볼 수 있는 기능이기 때문에 아마 한 번쯤은 보셨을 것입니다.
다음은 클론 메서드가 실제로 사용되는 예제입니다:
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {}, s2 = {}", s1, s2);
이것은 정상적으로 작동하며 그림 4-3에 표시된 동작을 명시적으로 생성하며, 힙 데이터가 복사됩니다.
복제에 대한 호출이 표시되면 임의의 코드가 실행되고 있으며 해당 코드가 비용이 많이 들 수 있음을 알 수 있습니다.
이는 뭔가 다른 일이 진행되고 있다는 시각적 지표입니다.
스택 전용 데이터: 복사
아직 언급하지 않은 또 다른 부분이 있습니다.
정수를 사용하는 이 코드(일부가 목록 4-2에 표시됨)는 작동하며 유효합니다:
let x = 5;
let y = x;
println!("x = {}, y = {}", x, y);
하지만 이 코드는 우리가 방금 배운 것과 모순되는 것처럼 보입니다.
복제 호출이 없지만 x는 여전히 유효하며 y로 이동되지 않았습니다.
그 이유는 컴파일 시 크기가 알려진 정수와 같은 유형은 스택에 완전히 저장되므로,
실제 값의 복사본을 빠르게 만들 수 있기 때문입니다.
즉, 변수 y를 생성한 후 x가 유효하지 않게 할 이유가 없다는 뜻입니다.
즉, 여기서는 깊은 복사와 얕은 복사 사이에 차이가 없으므로 복제를 호출해도 일반적인 얕은 복사와 달라지는 것이 없으므로 생략해도 됩니다.
Rust에는 정수처럼 스택에 저장된 타입에 복사 특성이라는 특수 어노테이션이 있습니다(10장에서 특성에 대해 자세히 설명하겠습니다).
타입이 Copy 특성을 구현하면 이를 사용하는 변수는 이동하지 않고 살짝 복사되어 다른 변수에 할당된 후에도 여전히 유효합니다.
Rust는 유형 또는 그 일부가 Drop 특성을 구현한 경우 Copy로 유형에 주석을 달 수 없습니다.
값이 범위를 벗어날 때 유형에 특별한 일이 발생해야 하는데,
해당 유형에 Copy 어노테이션을 추가하면 컴파일 타임 오류가 발생합니다.
유형에 Copy 어노테이션을 추가하여 특성을 구현하는 방법에 대해 알아보려면 부록 C의 "파생 가능한 특성"을 참조하세요.
그렇다면 어떤 유형이 Copy 특성을 구현할까요?
해당 유형에 대한 설명서를 확인하여 확인할 수 있지만, 일반적으로 단순한 스칼라 값 그룹은 모두 Copy를 구현할 수 있으며,
할당이 필요하거나 리소스 형태인 어떤 것도 Copy를 구현할 수 없습니다.
다음은 Copy를 구현하는 몇 가지 유형입니다:
- u32와 같은 모든 정수 타입
- 논리 연산자 타입 true 혹은 false
- float64와 같은 모든 부동 소수
- 튜플에 Copy도 구현하는 유형만 포함된 경우. 예를 들어 (i32, i32)는 Copy를 구현하지만 (i32, String)은 구현하지 않습니다.
소유권 및 기능
함수에 값을 전달하는 메커니즘은 변수에 값을 할당할 때의 메커니즘과 유사합니다.
변수를 함수에 전달하면 할당할 때와 마찬가지로 이동 또는 복사됩니다.
목록 4-3에는 변수가 범위 안으로 들어오고 범위 밖으로 나가는 위치를 보여주는 주석이 있는 예제가 있습니다.
파일명: src/main.rs
fn main() {
let s = String::from("hello"); // s comes into scope
takes_ownership(s); // s's value moves into the function...
// ... and so is no longer valid here
let x = 5; // x comes into scope
makes_copy(x); // x would move into the function,
// but i32 is Copy, so it's okay to still
// use x afterward
} // Here, x goes out of scope, then s. But because s's value was moved, nothing
// special happens.
fn takes_ownership(some_string: String) { // some_string comes into scope
println!("{}", some_string);
} // Here, some_string goes out of scope and `drop` is called. The backing
// memory is freed.
fn makes_copy(some_integer: i32) { // some_integer comes into scope
println!("{}", some_integer);
} // Here, some_integer goes out of scope. Nothing special happens.목록 4-3: 소유권 및 범위가 주석 처리된 함수
takes_ownership을 호출한 후에 s를 사용하려고 하면 Rust는 컴파일 타임 오류를 발생시킵니다.
이러한 정적 검사는 실수로부터 우리를 보호합니다.
s와 x를 사용하는 코드를 메인에 추가하여 사용할 수 있는 곳과 소유권 규칙으로 인해 사용할 수 없는 곳을 확인해 보세요.
Return Values and Scope
값을 반환하면 소유권을 이전할 수도 있습니다.
목록 4-4는 목록 4-3과 유사한 어노테이션을 사용하여 어떤 값을 반환하는 함수의 예를 보여줍니다.
파일명: src/main.rs
fn main() {
let s1 = gives_ownership(); // gives_ownership moves its return
// value into s1
let s2 = String::from("hello"); // s2 comes into scope
let s3 = takes_and_gives_back(s2); // s2 is moved into
// takes_and_gives_back, which also
// moves its return value into s3
} // Here, s3 goes out of scope and is dropped. s2 was moved, so nothing
// happens. s1 goes out of scope and is dropped.
fn gives_ownership() -> String { // gives_ownership will move its
// return value into the function
// that calls it
let some_string = String::from("yours"); // some_string comes into scope
some_string // some_string is returned and
// moves out to the calling
// function
}
// This function takes a String and returns one
fn takes_and_gives_back(a_string: String) -> String { // a_string comes into
// scope
a_string // a_string is returned and moves out to the calling function
}목록 4-4: 반환 값의 소유권 이전
변수의 소유권은 매번 동일한 패턴을 따르는데, 값을 다른 변수에 할당하면 변수가 이동합니다.
힙에 데이터가 포함된 변수가 범위를 벗어나면 데이터의 소유권을 다른 변수로 옮기지 않는 한 값이 Drop 방식으로 정리됩니다.
이 방법은 작동하지만 모든 함수에서 소유권을 가져온 다음 소유권을 반환하는 것은 약간 지루합니다.
함수가 값을 사용하되 소유권을 가져가지 않도록 하려면 어떻게 해야 할까요?
함수를 다시 사용하려면 전달한 모든 데이터를 다시 전달해야 하고, 반환하려는 함수 본문에서 생성된 데이터도 함께 반환해야 한다는 점이 상당히 번거롭습니다.
Rust에서는 목록 4-5에 표시된 것처럼 튜플을 사용하여 여러 값을 반환할 수 있습니다.
파일명: src/main.rs
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("The length of '{}' is {}.", s2, len);
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() returns the length of a String
(s, length)
}목록 4-5: 매개변수의 소유권 반환
그러나 이것은 일반적인 개념에 비해 너무 많은 형식과 많은 작업이 필요합니다.
다행히도 Rust에는 소유권을 이전하지 않고 값을 사용할 수 있는 기능인 Reference라는 기능이 있습니다.
참조 및 대여
목록 4-5의 튜플 코드의 문제는 String이 calculate_length로 이동했기 때문에,
calculate_length를 호출한 후에도 String을 계속 사용할 수 있도록 호출 함수에 String을 반환해야 한다는 점입니다.
대신 문자열 값에 대한 참조를 제공할 수 있습니다.
참조는 해당 주소에 저장된 데이터에 액세스하기 위해 따라갈 수 있는 주소라는 점에서 포인터와 비슷하지만,
해당 데이터는 다른 변수에 의해 소유됩니다.
포인터와 달리 참조는 해당 참조의 수명 동안 특정 유형의 유효한 값을 가리키도록 보장됩니다.
값의 소유권을 갖는 대신 객체에 대한 참조를 매개변수로 갖는 calculate_length 함수를 정의하고 사용하는 방법은 다음과 같습니다:
파일명:src/main.rs
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{}' is {}.", s1, len);
}
fn calculate_length(s: &String) -> usize {
s.len()
}먼저, 변수 선언과 함수 반환 값의 모든 튜플 코드가 사라진 것을 확인합니다.
둘째, calculate_length 에 &s1을 전달하고 그 정의에서 String이 아닌 &String을 취하고 있음을 주목하세요.
이러한 앰퍼샌드는 references를 나타내며,
이를 통해 소유권을 가지지 않고도 어떤 값을 참조할 수 있습니다.
그림 4-5는 이 개념을 설명합니다.
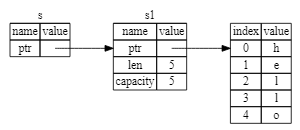
그림 4-5: 문자열 s1을 가리키는 &String s 다이어그램
참고: &를 사용하여 참조하는 것과 반대되는 것이 역참조이며, 역참조 연산자 *를 사용하여 수행됩니다. 8장에서 역참조 연산자의 몇 가지 용도를 살펴보고 15장에서 역참조에 대한 자세한 내용을 설명하겠습니다.
여기서 함수 호출을 자세히 살펴보겠습니다:
let s1 = String::from("hello");
let len = calculate_length(&s1);
s1 구문을 사용하면 s1의 값을 참조하지만 소유하지 않는 참조를 만들 수 있습니다.
값을 소유하지 않기 때문에 참조가 더 이상 사용되지 않을 때 참조가 가리키는 값이 삭제되지 않습니다.
마찬가지로 함수의 시그니처에는 &를 사용하여 매개변수 s의 유형이 참조임을 나타냅니다.
몇 가지 설명 주석을 추가해 보겠습니다:
fn calculate_length(s: &String) -> usize { // s is a reference to a String
s.len()
} // Here, s goes out of scope. But because it does not have ownership of what
// it refers to, it is not dropped.변수 s가 유효한 범위는 함수 매개변수의 범위와 동일하지만, 참조가 가리키는 값은 s가 더 이상 사용되지 않을 때 삭제되지 않는데, 이는 s에 소유권이 없기 때문입니다. 함수에 실제 값 대신 참조를 매개변수로 사용하는 경우, 소유권이 없으므로 소유권을 반환하기 위해 값을 반환할 필요가 없습니다.
우리는 참조를 생성하는 행위를 참조 차용이라고 부릅니다.
실생활에서와 마찬가지로,
어떤 사람이 무언가를 소유하고 있다면 그 사람에게서 빌릴 수 있습니다.
빌린 후에는 돌려주어야 합니다. 여러분은 그것을 소유하지 않습니다.
그렇다면 빌린 것을 수정하려고 하면 어떻게 될까요?
목록 4-6의 코드를 시도해 보세요.
스포일러 경고: 작동하지 않습니다!
파일명: src/main.rs
fn main() {
let s = String::from("hello");
change(&s);
}
fn change(some_string: &String) {
some_string.push_str(", world");
}목록 4-6: 빌린 값을 수정하려는 시도
오류 내용은 다음과 같습니다:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0596]: cannot borrow*some_stringas mutable, as it is behind a&reference
--> src/main.rs:8:5
|
7 | fn change(some_string: &String) {
| ------- help: consider changing this to be a mutable reference:&mut String
8 | some_string.push_str(", world");
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^some_stringis a&reference, so the data it refers to cannot be borrowed as mutable
For more information about this error, tryrustc --explain E0596.
error: could not compileownershipdue to previous error
변수가 기본적으로 불변인 것처럼 참조도 마찬가지입니다.
참조가 있는 것을 수정할 수 없습니다.
수정 가능한 References
목록 4-6의 코드를 수정하여 변경 가능한 참조를 사용하는 몇 가지 작은 조정만으로 빌린 값을 수정할 수 있습니다:
파일명: src/main.rs
fn main() {
let mut s = String::from("hello");
change(&mut s);
}
fn change(some_string: &mut String) {
some_string.push_str(", world");
}먼저 s를 mut로 변경합니다
. 그런 다음 변경 함수를 호출하는 위치에 &mut s로 변경 가능한 참조를 생성하고,
일부_string: &mut 문자열로 변경 가능한 참조를 허용하도록 함수 서명을 업데이트합니다.
이렇게 하면 변경 함수가 차용한 값을 변경한다는 것을 매우 명확하게 알 수 있습니다.
변경 가능한 참조에는 한 가지 큰 제한이 있습니다.
값에 대한 변경 가능한 참조가 있으면 해당 값에 대한 다른 참조를 가질 수 없다는 것입니다.
s에 대한 두 개의 변경 가능한 참조를 만들려고 시도하는 이 코드는 실패합니다:
파일명:src/main.rs
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{}, {}", r1, r2);
오류 내용은 다음과 같습니다:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0499]: cannot borrowsas mutable more than once at a time
--> src/main.rs:5:14
|
4 | let r1 = &mut s;
| ------ first mutable borrow occurs here
5 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
6 |
7 | println!("{}, {}", r1, r2);
| -- first borrow later used here
For more information about this error, tryrustc --explain E0499.
error: could not compileownershipdue to previous error
이 오류는 s를 한 번에 두 번 이상 변경 가능으로 빌릴 수 없기 때문에 이 코드가 유효하지 않다고 말합니다.
첫 번째 가변 참조는 r1에 있으며 println! 에서 사용될 때까지 지속되어야 하지만,
해당 가변 참조를 생성하고 사용하는 사이에 r1과 동일한 데이터를 차용하는 다른 가변 참조를 r2에 생성하려고 했습니다.
동일한 데이터에 대한 여러 개의 변경 가능한 참조를 동시에 허용하지 않는 제한으로 인해 변경은 가능하지만 매우 제한된 방식으로 이루어집니다.
대부분의 언어에서는 원할 때마다 변형을 허용하기 때문에 Rust를 처음 접하는 사람들이 어려움을 겪는 부분입니다.
이러한 제한의 장점은 컴파일 시 데이터 경주를 방지할 수 있다는 것입니다.
데이터 경합은 경쟁 조건과 유사하며 다음 세 가지 동작이 발생할 때 발생합니다:
- 두 개 이상의 포인터가 동시에 동일한 데이터에 액세스 하는 경우
- 포인터 중 하나 이상이 데이터에 쓰는 데 사용되고 있는 경우
- 데이터에 대한 액세스를 동기화하는 데 사용되는 메커니즘이 없는 경우
데이터 경합은 정의되지 않은 동작을 유발하고 런타임에 이를 추적하려고 할 때 진단 및 수정이 어려울 수 있습니다.
Rust는 데이터 경합이 있는 코드 컴파일을 거부하여 이 문제를 방지합니다!
항상 그렇듯이 중괄호를 사용하여 새 범위를 생성하면 동시 참조가 아닌 여러 개의 변경 가능한 참조를 허용할 수 있습니다:
let mut s = String::from("hello");
{
let r1 = &mut s;
} // r1 goes out of scope here, so we can make a new reference with no problems.
let r2 = &mut s;
Rust는 변경 가능한 참조와 변경 불가능한 참조를 결합할 때 비슷한 규칙을 적용합니다.
이 코드는 오류를 발생시킵니다:
let mut s = String::from("hello");
let r1 = &s; // no problem
let r2 = &s; // no problem
let r3 = &mut s; // BIG PROBLEM
println!("{}, {}, and {}", r1, r2, r3);
오류 내용은 다음과 같습니다:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrowsas mutable because it is also borrowed as immutable
--> src/main.rs:6:14
|
4 | let r1 = &s; // no problem
| -- immutable borrow occurs here
5 | let r2 = &s; // no problem
6 | let r3 = &mut s; // BIG PROBLEM
| ^^^^^^ mutable borrow occurs here
7 |
8 | println!("{}, {}, and {}", r1, r2, r3);
| -- immutable borrow later used here
For more information about this error, tryrustc --explain E0502.
error: could not compileownershipdue to previous error
또한 동일한 값에 대한 불변 참조가 있는 동안 변경 가능한 참조를 가질 수 없습니다.
변경 불가능한 참조를 사용하는 사용자는 갑자기 값이 변경될 것을 예상하지 못합니다.
그러나 데이터를 읽기만 하는 사람은 다른 사람의 데이터 읽기에 영향을 줄 수 없으므로 여러 개의 불변 참조가 허용됩니다.
참조의 범위는 참조가 도입된 위치에서 시작하여 해당 참조가 마지막으로 사용된 시점까지 계속된다는 점에 유의하세요.
예를 들어, 이 코드는 변경 불가능한 참조의 마지막 사용인 println! 이 변경 가능한 참조가 도입되기 전에 발생하므로 컴파일됩니다:
let mut s = String::from("hello");
let r1 = &s; // no problem
let r2 = &s; // no problem
println!("{} and {}", r1, r2);
// variables r1 and r2 will not be used after this point
let r3 = &mut s; // no problem
println!("{}", r3);
불변 참조 r1과 r2의 범위는 마지막으로 사용된 println! 이후,
즉 변경 가능한 참조 r3이 생성되기 전에 끝납니다.
이러한 범위는 겹치지 않으므로 이 코드는 허용됩니다.
컴파일러는 범위가 끝나기 전 지점에서 참조가 더 이상 사용되지 않는다는 것을 알 수 있습니다.
차용 오류는 때때로 실망스러울 수 있지만, Rust 컴파일러가 잠재적인 버그를 조기에(런타임이 아닌 컴파일 타임에) 지적하고 문제가 있는 위치를 정확히 알려준다는 점을 기억하세요.
그러면 데이터가 생각했던 것과 다른 이유를 추적할 필요가 없습니다.
Dangling References
포인터를 사용하는 언어에서는 해당 메모리에 대한 포인터를 보존하면서 일부 메모리를 해제하여 dangling 포인터(다른 사람에게 제공되었을 수 있는 메모리 내 위치를 참조하는 포인터)를 실수로 생성하기 쉽습니다.
반면 Rust에서는 컴파일러가 참조가 절대 댕글링 참조가 되지 않도록 보장합니다.
즉, 어떤 데이터에 대한 참조가 있는 경우 컴파일러는 데이터에 대한 참조가 범위를 벗어나기 전에 데이터가 범위를 벗어나지 않도록 보장합니다.
Dangling reference를 생성하여 Rust가 어떻게 컴파일 타임 오류로 이를 방지하는지 확인해 보겠습니다:
파일명:src/main.rs
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s
}오류 내용은 다음과 같습니다:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0106]: missing lifetime specifier
--> src/main.rs:5:16
|
5 | fn dangle() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the'staticlifetime
|
5 | fn dangle() -> &'static String {
| +++++++
For more information about this error, tryrustc --explain E0106.
error: could not compileownershipdue to previous error
이 오류 메시지는 아직 다루지 않은 기능인 수명에 관한 것입니다.
수명에 대해서는 10장에서 자세히 설명하겠습니다.
하지만 수명에 대한 부분을 무시하더라도 이 메시지에는 이 코드가 왜 문제가 되는지에 대한 핵심이 포함되어 있습니다:
이 함수의 반환 유형에는 빌린 값이 포함되어 있지만, 빌릴 값이 없습니다.
dangle 함수 코드의 각 단계에서 정확히 어떤 일이 일어나는지 자세히 살펴봅시다:
파일명: src/main.rs
fn dangle() -> &String { // dangle returns a reference to a String
let s = String::from("hello"); // s is a new String
&s // we return a reference to the String, s
} // Here, s goes out of scope, and is dropped. Its memory goes away.
// Danger!s는 dangle 함수 내부에 생성되므로 댕글 코드가 완료되면 s는 할당 해제됩니다.
하지만 우리는 그것에 대한 참조를 반환하려고 했습니다.
즉, 이 참조가 잘못된 문자열을 가리키고 있다는 뜻입니다.
이건 좋지 않습니다. Rust는 이 작업을 허용하지 않습니다.
여기서 해결책은 문자열을 직접 반환하는 것입니다:
fn no_dangle() -> String {
let s = String::from("hello");
s
}이것은 문제없이 동작할 것입니다.
소유권이 이전되고 아무것도 할당 해제되지 않습니다.
참조의 규칙
참조에 대해서 다시 한번 복습해봅시다.
- 언제든지 변경 가능한 참조를 하나 혹은 불변 참조를 여러 개 가질 수 있습니다.
- 참조는 항상 유효해야 합니다.
다음으로 다른 종류의 참조인 slice를 살펴보겠습니다.
slice 유형
Slice를 사용하면 전체 컬렉션이 아닌 컬렉션의 연속된 요소 시퀀스를 참조할 수 있습니다.
slice는 일종의 참조이므로 소유권이 없습니다.
공백으로 구분된 단어 문자열을 받아 해당 문자열에서 찾은 첫 번째 단어를 반환하는 함수를 작성하는 작은 프로그래밍 문제를 예로 들어보겠습니다.
함수가 문자열에서 공백을 찾지 못하면 전체 문자열이 한 단어여야 하므로 전체 문자열을 반환해야 합니다.
Slice를 사용하지 않고 이 함수의 시그니처를 작성하는 방법을 살펴보고 slice로 해결할 수 있는 문제를 이해해 보겠습니다:
fn first_word(s: &String) -> ?first_word 함수에는 매개변수로 &String이 있습니다.
우리는 소유권을 원하지 않으므로 괜찮습니다.
하지만 무엇을 반환해야 할까요?
문자열의 일부에 대해 이야기할 수 있는 방법은 없습니다.
하지만 공백으로 표시된 단어 끝의 인덱스를 반환할 수 있습니다.
목록 4-7에 표시된 것처럼 시도해 보겠습니다.
파일명:src/main.rs
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
목록 4-7: 문자열 매개 변수에 바이트 인덱스 값을 반환하는 first_word 함수
문자열을 요소별로 살펴보고 값이 공백인지 확인해야 하므로 as_bytes 메서드를 사용하여 문자열을 바이트 배열로 변환합니다.
let bytes = s.as_bytes();
다음으로, iter 메서드를 사용하여 바이트 배열에 대한 반복자를 생성합니다:
for (i, &item) in bytes.iter().enumerate() {
이터레이터에 대해서는 13장에서 더 자세히 설명하겠습니다.
지금은 iter가 컬렉션의 각 엘리먼트를 반환하는 메서드이고,
enumerate는 iter의 결과를 래핑하고 대신 각 엘리먼트를 튜플의 일부로 반환한다는 것만 알아두세요.
enumerate에서 반환되는 튜플의 첫 번째 요소는 인덱스이고 두 번째 요소는 요소에 대한 참조입니다.
인덱스를 직접 계산하는 것보다 조금 더 편리합니다.
enumerate 메서드는 튜플을 반환하므로 패턴을 사용해 해당 튜플을 해체할 수 있습니다.
패턴에 대해서는 6장에서 자세히 설명하겠습니다.
for 루프에서는 튜플의 인덱스에 i를, 튜플의 단일 바이트에 &item을 사용하는 패턴을 지정합니다.
.iter().enumerate()에서 요소에 대한 참조를 가져오기 때문에 패턴에 &를 사용합니다.
for 루프 내부에서는 바이트 리터럴 구문을 사용하여 공백을 나타내는 바이트가 있는지 검색합니다.
공백을 찾으면 그 위치를 반환합니다.
그렇지 않으면 s.len()을 사용하여 문자열의 길이를 반환합니다.
if item == b' ' {
return i;
}
}
s.len()
이제 문자열에서 첫 번째 단어 끝의 인덱스를 찾을 수 있는 방법이 생겼지만 문제가 있습니다. usize를 자체적으로 반환하고 있지만,이는 &String의 컨텍스트에서만 의미 있는 숫자일 뿐입니다.
즉, 문자열과는 별개의 값이기 때문에 향후에도 여전히 유효하다는 보장이 없습니다.
목록 4-7의 first_word 함수를 사용하는 목록 4-8의 프로그램을 살펴봅시다.
파일명: src/main.rs
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s); // word will get the value 5
s.clear(); // this empties the String, making it equal to ""
// word still has the value 5 here, but there's no more string that
// we could meaningfully use the value 5 with. word is now totally invalid!
}목록 4-8: first_word 함수를 호출한 후 문자열 내용을 변경한 결과 저장하기
이 프로그램은 오류 없이 컴파일되며, s.clear()를 호출한 후 word를 사용해도 컴파일됩니다.
단어는 s의 상태와 전혀 연결되어 있지 않기 때문에 단어에는 여전히 5라는 값이 포함됩니다.
이 값 5를 변수 s와 함께 사용하여 첫 번째 단어를 추출할 수 있지만,
5를 word에 저장한 이후 s의 내용이 변경되었으므로 이는 버그가 될 수 있습니다.
단어의 인덱스가 s의 데이터와 동기화되지 않는 것에 대해 걱정해야 하는 것은 지루하고 오류가 발생하기 쉽습니다.
second_word 함수를 작성하면 이러한 인덱스 관리는 훨씬 더 까다로워집니다.
그 함수의 signature는 다음과 같아야 합니다:
fn second_word(s: &String) -> (usize, usize) {이제 시작 인덱스와 종료 인덱스를 추적하고 있으며,
특정 상태의 데이터에서 계산되었지만 해당 상태와 전혀 관련이 없는 값이 훨씬 더 많이 있습니다.
동기화 상태를 유지해야 하는 관련 없는 변수가 세 개나 떠다니고 있습니다.
다행히도 Rust에는 이 문제를 해결할 수 있는 문자열 slice라는 솔루션이 있습니다.
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
hello는 전체 문자열에 대한 참조가 아니라 추가 [0..5] 비트에 지정된 문자열의 일부에 대한 참조입니다.
시작 인덱스..끝 인덱스]를 지정하여 괄호 안의 범위를 사용하여 슬라이스를 생성하는데,
여기서 시작 인덱스는 슬라이스의 첫 번째 위치이고 끝 인덱스는 슬라이스의 마지막 위치보다 하나 더 많은 위치입니다.
내부적으로 슬라이스 데이터 구조는 슬라이스의 시작 위치와 길이를 저장하는데,
이는 끝 인덱스에서 시작 인덱스를 뺀 값에 해당합니다.
따라서 let world = &s[6..11]; 의 경우, 세계는 길이 값이 5인 s의 인덱스 6에 있는 바이트에 대한 포인터를 포함하는 슬라이스가 됩니다.
그림 4-6은 이를 다이어그램으로 보여줍니다.
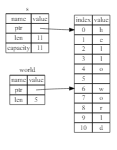
그림 4-6: String의 일부를 참조하는 문자열 슬라이스
Rust의 .. 범위 구문을 사용하면 인덱스 0에서 시작하려면 두 마침표 앞의 값을 삭제하면 됩니다.
즉, 이것들은 동일합니다:
let s = String::from("hello");
let slice = &s[0..2];
let slice = &s[..2];
마찬가지로 슬라이스에 문자열의 마지막 바이트가 포함된 경우 후행 숫자를 삭제할 수 있습니다.
즉, 이들은 동일합니다:
let s = String::from("hello");
let len = s.len();
let slice = &s[3..len];
let slice = &s[3..];
두 값을 모두 삭제하여 전체 문자열의 일부를 가져올 수도 있습니다. 따라서 이 값은 동일합니다:
let s = String::from("hello");
let len = s.len();
let slice = &s[0..len];
let slice = &s[..];
참고: 문자열 슬라이스 범위 인덱스는 유효한 UTF-8 문자 경계에서 발생해야 합니다.
멀티바이트 문자 중간에 문자열 슬라이스를 만들려고 하면 프로그램이 오류와 함께 종료됩니다.
문자열 슬라이스를 소개하기 위해 이 섹션에서는 ASCII만 사용한다고 가정하고,
UTF-8 처리에 대한 자세한 내용은 8장의 '문자열로 인코딩된 텍스트 저장하기' 섹션을 참조하세요.
이 모든 정보를 염두에 두고 슬라이스를 반환하도록 first_word를 다시 작성해 보겠습니다.
"문자열 슬라이스"를 나타내는 유형은 &str로 작성됩니다:
파일명: src/main.rs
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
목록 4-7에서와 동일한 방식으로 공백의 첫 번째 발생을 찾아 단어 끝에 대한 인덱스를 얻습니다.
공백을 찾으면 문자열의 시작과 공백의 인덱스를 시작 및 끝 인덱스로 사용하여 문자열 조각을 반환합니다.
이제 first_word를 호출하면 기초 데이터에 연결된 단일 값을 반환합니다.
이 값은 슬라이스의 시작점에 대한 참조와 슬라이스의 요소 수로 구성됩니다.
슬라이스를 반환하는 것은 second_word 함수에서도 작동합니다:
fn second_word(s: &String) -> &str {이제 컴파일러가 문자열에 대한 참조가 유효한 상태로 유지되도록 보장하기 때문에 엉망이 되기 훨씬 어려운 간단한 API를 갖게 되었습니다.
목록 4-8의 프로그램에서 인덱스를 첫 번째 단어의 끝으로 가져온 다음 문자열을 지워 인덱스가 유효하지 않은 버그를 기억하시나요?
이 코드는 논리적으로 올바르지 않았지만 즉각적인 오류는 표시되지 않았습니다.
비어 있는 문자열로 첫 단어 인덱스를 계속 사용하려고 하면 나중에 문제가 나타날 수 있습니다.
슬라이스를 사용하면 이러한 버그가 불가능해지며 코드에 문제가 있음을 훨씬 더 빨리 알 수 있습니다.
첫 번째 단어의 슬라이스 버전을 사용하면 컴파일 타임 오류가 발생합니다:
파일명:src/main.rs
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // error!
println!("the first word is: {}", word);
}오류 내용은 다음과 같습니다:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrowsas mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let word = first_word(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("the first word is: {}", word);
| ---- immutable borrow later used here
For more information about this error, tryrustc --explain E0502.
error: could not compileownershipdue to previous error
차용 규칙에서 무언가에 대한 불변 참조가 있으면 변경 가능한 참조도 가져올 수 없다는 점을 기억하세요.
clear는 문자열을 잘라내야 하므로 변경 가능한 참조를 가져와야 합니다.
clear 호출 뒤의 println! 은 word의 참조를 사용하므로 변경 불가능한 참조는 그 시점에서도 여전히 활성 상태여야 합니다.
Rust는 clear의 변경 가능한 참조와 word의 변경 불가능한 참조가 동시에 존재하는 것을 허용하지 않으며, 컴파일이 실패합니다.
Rust를 통해 API를 더 쉽게 사용할 수 있게 되었을 뿐만 아니라 컴파일 시 전체 오류 클래스도 제거되었습니다.
slice로서 하드코딩된 문자열
하드코딩된 문자열의 slice를 가지고 올수 있다는 것과 String의 값을 알면 첫 번째 단어에서 한 가지 더 개선할 수 있는데, 이것이 바로 signature입니다:
fn first_word(s: &String) -> &str {경험이 많은 러스트 사용자라면 목록 4-9에 표시된 서명을 대신 작성할 텐데,
이는 &String 값과 &str 값 모두에 동일한 함수를 사용할 수 있기 때문입니다.
fn first_word(s: &str) -> &str {
목록 4-9: s 매개변수 유형에 문자열 슬라이스를 사용하여 first_word 함수 개선하기
문자열 슬라이스가 있다면 이를 직접 전달할 수 있습니다.
String이 있다면 문자열의 슬라이스나 문자열에 대한 참조를 전달할 수 있습니다.
이러한 유연성은 15장의 '함수와 메서드를 사용한 암시적 강제 참조해제 '에서 다룰 기능인 디레프 강제 기능을 활용합니다.
문자열에 대한 참조 대신 문자열 슬라이스를 취하는 함수를 정의하면 기능을 잃지 않으면서도 API를 더 일반적이고 유용하게 만들 수 있습니다:
파일명: src/main.rs
fn main() {
let my_string = String::from("hello world");
// `first_word` works on slices of `String`s, whether partial or whole
let word = first_word(&my_string[0..6]);
let word = first_word(&my_string[..]);
// `first_word` also works on references to `String`s, which are equivalent
// to whole slices of `String`s
let word = first_word(&my_string);
let my_string_literal = "hello world";
// `first_word` works on slices of string literals, whether partial or whole
let word = first_word(&my_string_literal[0..6]);
let word = first_word(&my_string_literal[..]);
// Because string literals *are* string slices already,
// this works too, without the slice syntax!
let word = first_word(my_string_literal);
}다른 Slices
문자열 슬라이스는 상상할 수 있듯이 문자열에만 해당됩니다.
하지만 더 일반적인 슬라이스 유형도 있습니다. 이 배열을 살펴보겠습니다:
let a = [1, 2, 3, 4, 5];
문자열의 일부를 참조하는 것처럼 배열의 일부를 참조하고 싶을 수도 있습니다.
이렇게 하면 됩니다:
let a = [1, 2, 3, 4, 5];
let slice = &a[1..3];
assert_eq!(slice, &[2, 3]);
이 슬라이스의 유형은 &[i32]입니다.
첫 번째 요소와 길이에 대한 참조를 저장하여 문자열 슬라이스와 동일한 방식으로 동작합니다.
이런 종류의 슬라이스는 다른 모든 종류의 컬렉션에 사용할 수 있습니다.
이러한 컬렉션에 대해서는 8장에서 벡터에 대해 이야기할 때 자세히 설명하겠습니다.
요약
소유권, 차용 및 슬라이스라는 개념은 컴파일 시 Rust 프로그램에서 메모리 안전을 보장합니다.
Rust 언어는 다른 시스템 프로그래밍 언어와 동일한 방식으로 메모리 사용량을 제어할 수 있지만,
데이터 소유자가 범위를 벗어나면 해당 데이터가 자동으로 정리되므로,
이러한 제어 기능을 얻기 위해 추가 코드를 작성하고 디버깅할 필요가 없습니다.
소유권은 Rust의 다른 많은 부분이 작동하는 방식에 영향을 미치므로,
이 책의 나머지 부분에서 이러한 개념에 대해 더 자세히 설명하겠습니다.
5장으로 넘어가서 구조체에서 데이터 조각을 함께 그룹화하는 방법을 살펴보겠습니다.
