[논문 리뷰] Multi-Layer domain adaptation method for rolling bearing fault diagnosis
0
Transfer learning Seminar
목록 보기
2/3

Motivation
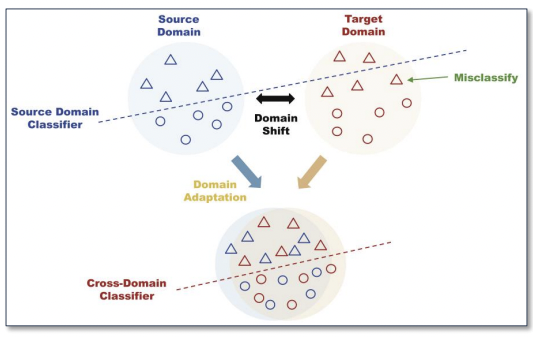
- 일반적으로 Fault diagnosis를 위한 Data-driven한 방법은 Train data와 Test data가 동일한 분포를 따른다는 가정 하에 수행된다. 그러나 현실 세계에서는 Domain shift로 인해 해당 가정이 성립하지 않는다. 또한 Domain shift는 Sour domain에서 Label이 있는 데이터로 학습한 결과로 알 수 있는 Pattern knowledge를 Target domain에서의 Label이 없는 Test 데이터에 적용하는 Generalization ability를 저하시킨다.
- 추가적으로 Target domain에서 유효한 Labeling하는 과정이 쉽지 않다.
Contribution
- 본 논문에서는 DL 기반 Bearing fault diagnosis을 위한 새로운 Domain adaptation 방법을 제안한다. Domain shift 문제를 해결하기 위해 최종 Layer가 아닌 개별 Layer 각각의 MMD loss를 최소화하며 Multi-kernel도 사용한다.
- 이는 Unsupervised Domain adaptation에 대한 대부분의 기존 연구는 최종 layer에서 추출된 High-level feature의 분포 불일치만을 최소화하고 있다는 점을 지적하며 제안한 구조이다.
Maximum Mean Discrepancy (MMD)
- 두 분포의 불일치성을 표현하는 지표로, Source와 Target을 Hilbert space로 Mapping한 다음 분포의 차이를 계산하는 것
- 논문에서는 이때 사용하는 Kernel function의 차원을 여러개 사용하는 Multi-kernel을 도입하였다.
1D CNN
- 이미지가 아닌 시계열 분석이나 텍스트 분석에 자주 사용되는 모델
- Convolution 연산을 위한 Kernel과 적용하는 데이터의 Sequence가 1차원의 모양을 가짐
Proposed Method
Architecture
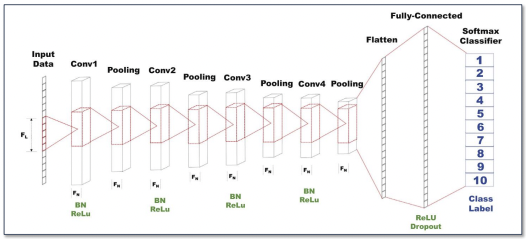
- 4개의 1D CNN layer를 가지며, Convolution layer를 거칠때 마다 Max pooling을 수행한다.
- 4개의 Conv. layer와 4개의 Pooling layer를 거친 feature는 Flatten을 통해 펼쳐지게되고, Fully-Connected layer를 통과하여 Classification을 진행하게 된다.
Optimization Objective
- 마지막 layer에서만 Distribution discrepancy를 최소화하는 것은 Source domain과 Target domain 사이의 Bias를 효과적으로 제거할 수 없기 때문에 layer마다 MMD loss를 최소화하는 구조를 제안한다.
- 최종 loss function은 Cross entropy loss와 MMD loss의 합으로 계산된다.
Proposed domain adaptation method
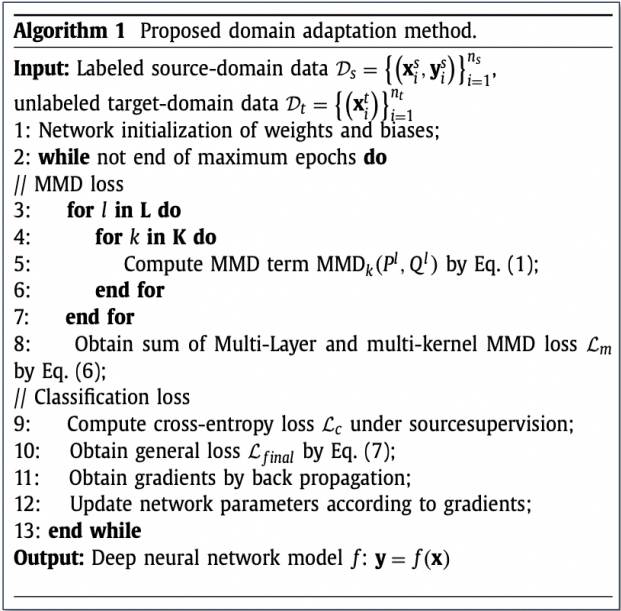
- 센서에서 수집된 진동 데이터가 Input data로 사용되며, Labeled source domain data와 Unlabeled target domain data가 사용된다.
- 4개의 Conv. layer와 Pooling layer를 통해 Domain invariant한 Feature가 추출된다.
- 이후 Test 과정에서는 Target domain testing sample이 사용된다.
Experiments
- 가동조건에 따라 Domain shift가 발생한다는 가정하에 진행한 실험으로, 총 6가지 Transfer task가 진행되었다.
Dataset
CWRU dataset
- Case Western Reserve University의 Bearing Data Center에서 수집된 데이터로 정상과 불량 상황을 세팅하고 측정을 진행한 데이터이다.
- 불량의 정도를 다르게 하여 데이터를 수집하였으며 총 10개의 Health condition class를 가진다.
Result
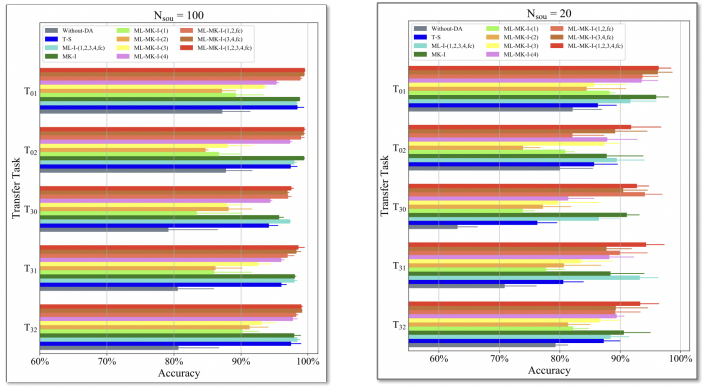
- 다양한 Variation으로 실험을 진행한 결과, 제안하는 모델인 Multi-layer & Multi-kernel을 가진 모델이 모든 케이스에서 우수한 성능을 보였다.

- 또한, Fully-conneted layer를 시각화해봤을 때 제안 모델을 활용했을 때 Clustering이 잘된것을 알 수 있다.
Conclusion
- Machinery data에 Domain Adaptation을 수행하는 새로운 모델을 제안하였으며, 비교 모델 대비 가장 우수한 Domain adaptation 성능을 보였다.
- Label이 있는 Train data가 적을 때도 우수한 성능을 보이는 Overfitting에 강한 모델이라고 할 수 있다.
- Visualization을 통해 제안 모델이 Domain Invariant한 Feature를 추출할 수 있음을 확인하였다.

Researcher