
1. 스케쥴링 목적 및 단계
-
스케쥴링은 시스템의 효율성, 안정성, 확장성, 공평성, 반응 시간 보장 및 무한 작업 연기 방지를 위한 목적으로 실행됨.
-
OS 스케쥴링에는 고수준, 저수준, 중간 수준 스케쥴링으로 크게 3가지 스케쥴링 단계로 나뉘어있음.
- 고수준 스케쥴링: OS가 시스템 내에서 전체 작업 수를 조절. 여기서 작업 수는 크게 1개 또는 여러 개의 프로세스 수라고 할 수 있음. 전체적인 시스템 상황을 고려하여 해당 작업을 수행할지 말지 결정.
- 저수준 스케쥴링: 어떤 작업을 CPU에 할당할지 혹은 프로세스 상태를 관리. 일반적으로, CPU 스케쥴러가 여기에 해당.
- 중간 수준 스케쥴링: 중지와 활성화로 전체 시스템에 활성화된 프로세스 수를 조절. 이를 통해 과부화 방지.
2. 스케쥴링 시 고려사항
-
선점형이냐 비선점형이냐?
- 선점형: CPU에서 프로세스 실행 시 다른 프로세스가 CPU 접근하여 실행하고자 하면 이를 허용해주는 구조. 대표적으로 인터럽트 처리를 들 수 있음
- 장점(+): 한 프로세스가 CPU 독점할 수 없음. 대화형 혹은 시분할 시스템에 유리.
- 단점(-): Context Switching Overhead가 증가.
- 비선점형: CPU에서 프로세스 실행 시 다른 어떤 프로세스의 실행이 실행중인 프로세스가 종료할 때까지 실행될 수 없는 구조. 일괄 작업 방식 스케쥴러에 해당
- 장점(+): Context Switching Overhead가 다소 적음.
- 단점(-): 기다리는 프로세스 수가 증가하여 CPU 처리율 낮춤.
- 선점형: CPU에서 프로세스 실행 시 다른 프로세스가 CPU 접근하여 실행하고자 하면 이를 허용해주는 구조. 대표적으로 인터럽트 처리를 들 수 있음
-
CPU bound VS I/O bound
- CPU bound 프로세스의 경우 CPU를 주로 사용하는 프로세스이고, I/O bound 프로세스는 주로 입출력을 사용하는 프로세스
- 일반적으로 CPU 스케쥴링에서는 I/O bound 프로세스를 먼저 실행하고 그 이후 CPU bound 프로세스를 실행시키는 것이 효율적인 방식
-
전면 프로세스 VS 후면 프로세스
- 전면 프로세스: GUI를 사용하는 OS에서 사용자와 화면 맨 앞에서 상호작용하는 프로세스. 대표적으로 컴퓨터에서 맨 앞단에 띄워져있는 웹 브라우저를 예로 들 수 있음.
- 후면 프로세스: 사용자의 입력없이 후면에서 일괄 작업하는 프로세스. 대표적으로 압축프로그램 혹은 워드프로그램 등이 있을 수 있음.
-
대체적으로 우선순위가 높은 프로세스는 커널 프로세스, 전면 프로세스, 대화형 프로세스, I/O bound 프로세스. 우선순위가 낮은 프로세스는 일반(user) 프로세스, 후면 프로세스, 일괄처리 프로세스, CPU bound 프로세스가 있음.
3. 다중 큐(Multi Queue)
- 프로세스 상태(준비, 대기)별로 다중 큐가 존재.
- 다중 큐에서는 가장 상단에 위치한 큐는 I/O bound 프로세스가 배치되어 있고 가장 하단의 큐에는 CPU bound 프로세스가 배치되어 있음. Timeslice도 I/O bound 프로세스가 더 짧게 설정함
- 다단계 피드백 큐(multi-level feedback queue) 스케쥴링에서는 history based heuristic 방식을 활용하여 각 level에 맞는 작업을 배치함(자세한 내용은 하단 필기 참조)
- 준비상태: 프로세스 우선순위별로 각각의 큐에 배치됨. 여기서 OS에서 프로세스에 우선순위를 할당하면 바꿀 수 없는 경우(static)와 바꿀 수 있는 경우(dynamic) 두 가지로 나뉨. 일반적으로 바꿀 수 있는 경우(dynamic)가 CPU 처리율을 높임.
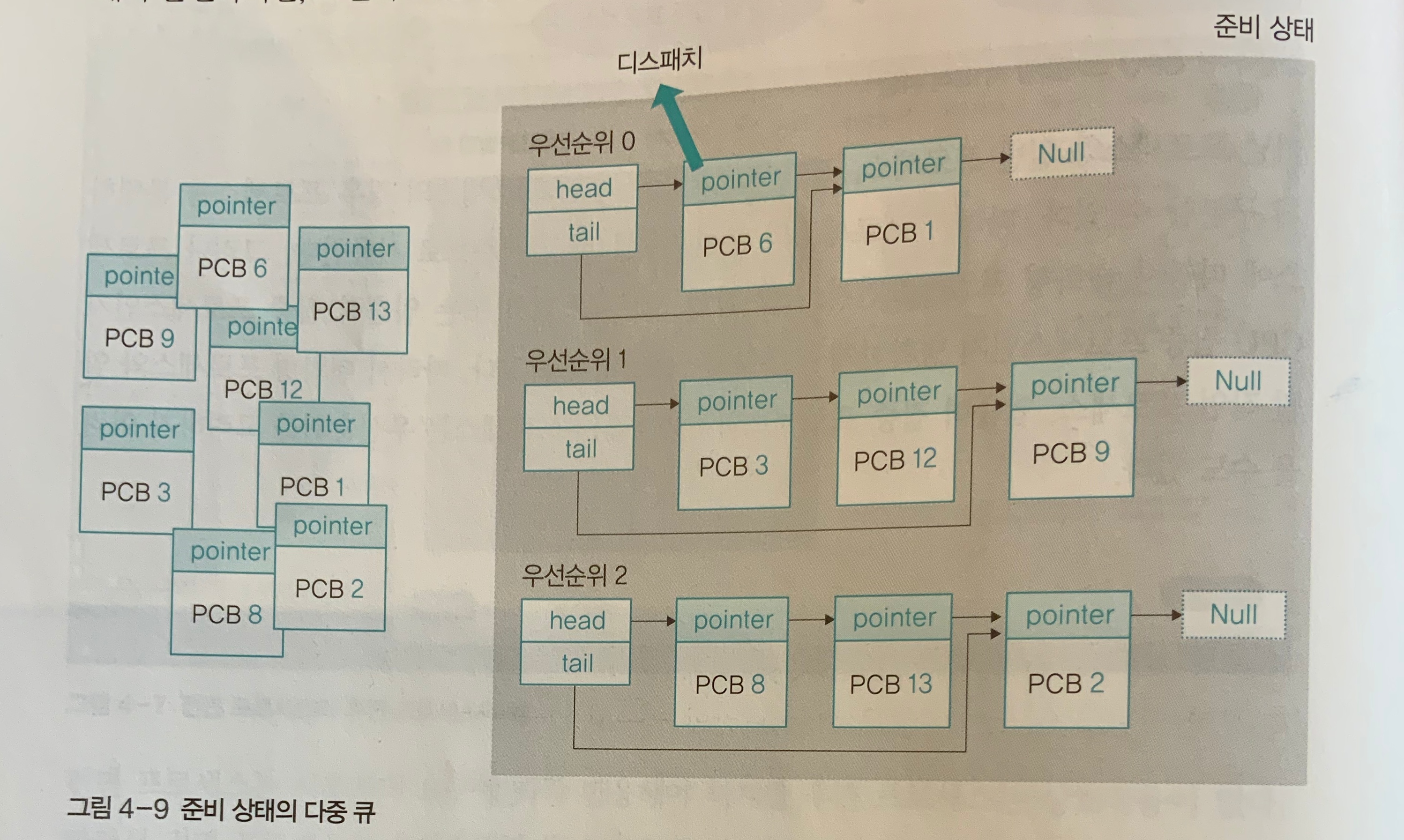
- 대기상태: 입출력 장치별로 분류하여 다중 큐에 담음.
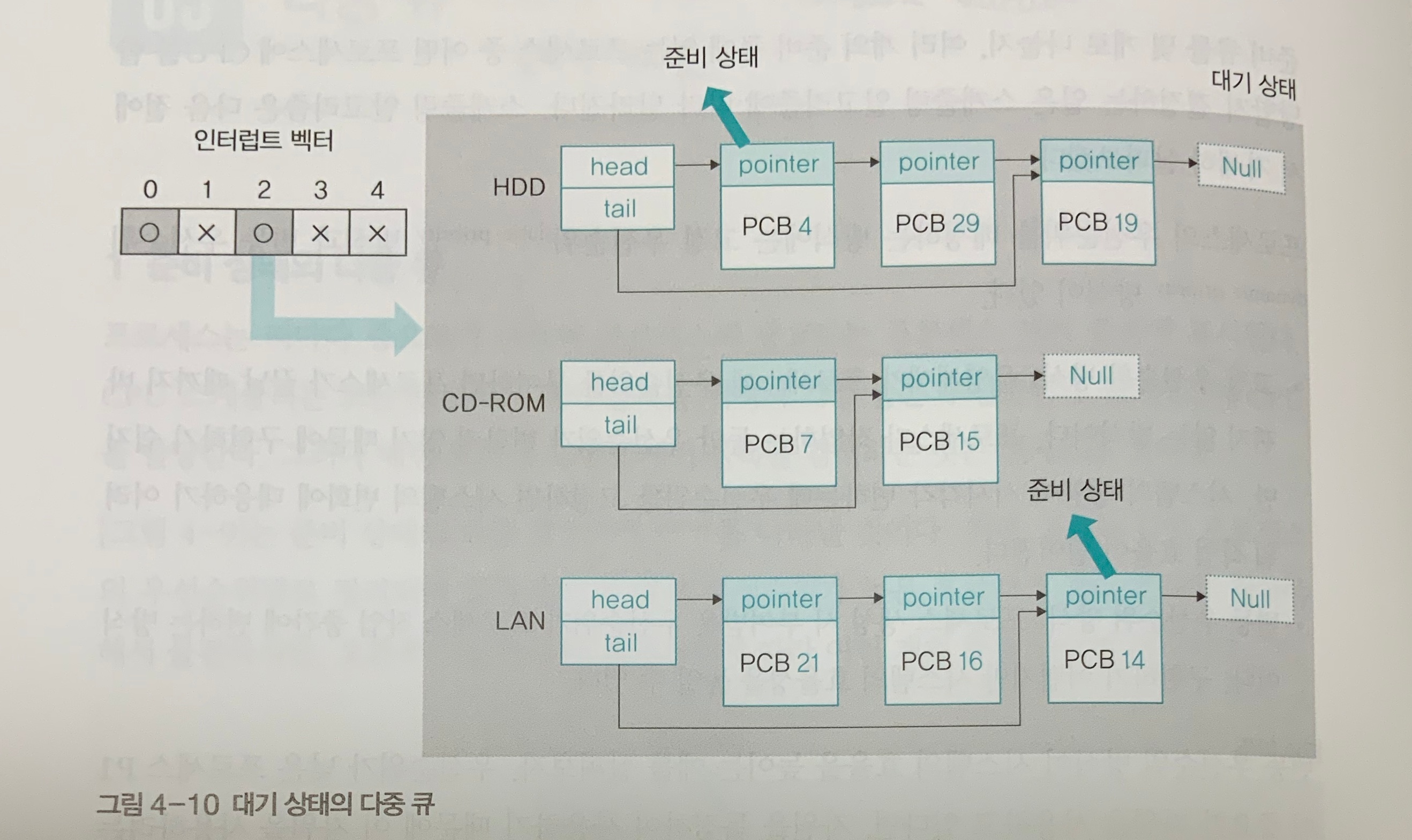
- 준비상태 다중큐에서는 한번에 하나의 작업(프로세스)만 꺼낼 수 있으나 대기상태 다중 큐의 경우 한번에 여러 개의 작업(프로세스)을 꺼내어 준비상태 큐로 옮길 수 있음.
- 전체적인 프로세스 실행 단계는 아래 그림으로 표현할 수 있음.
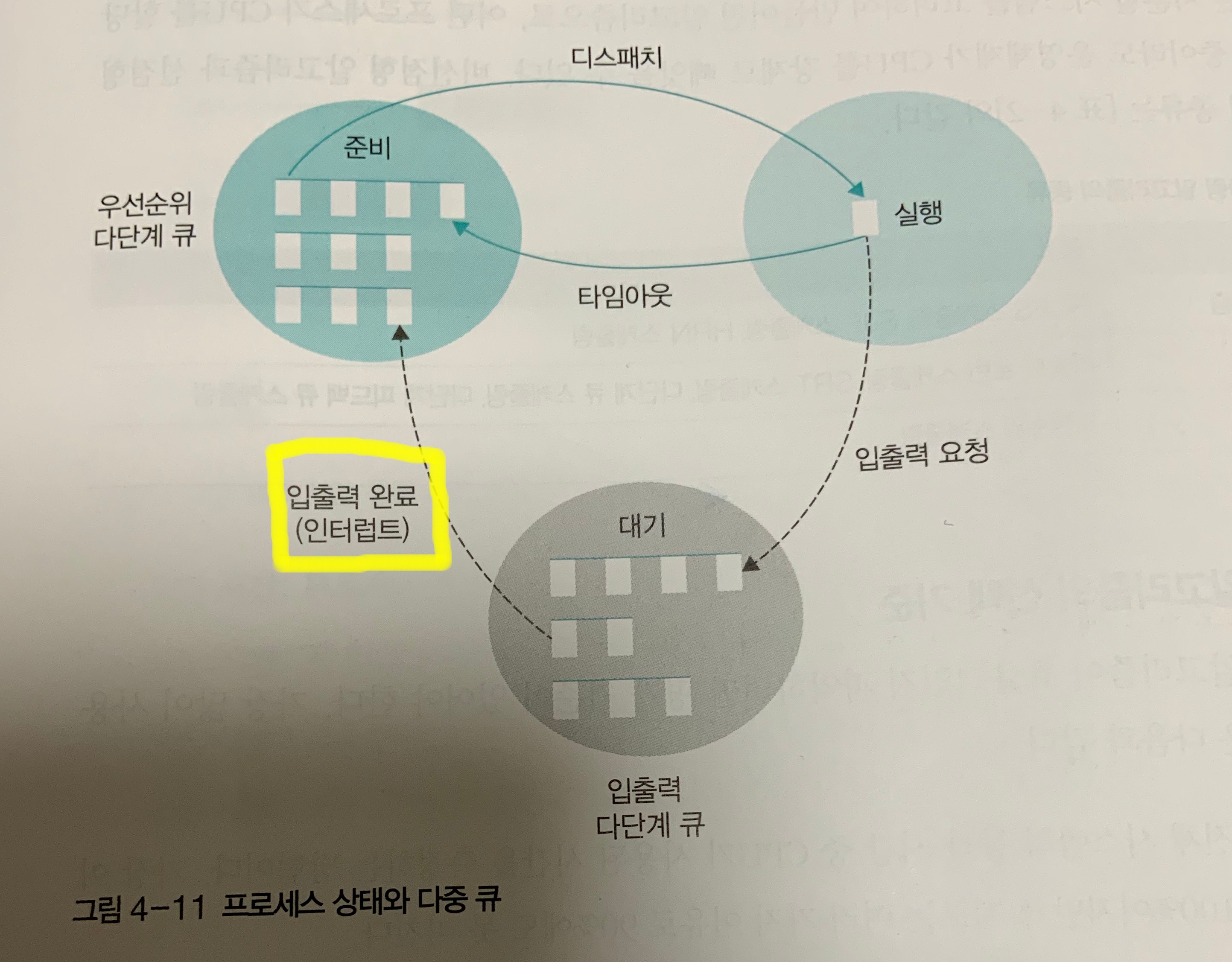
4. 스케쥴링 알고리즘
- 스케쥴링 알고리즘은 CPU 사용률, 처리량, 대기 시간, 응답 시간(대화형 시스템에서 사용자 요구에 반응하는 데까지 걸리는 시간), 반환 시간 이 5가지 기준에 따라 시스템 조건과 상황에 따라 선택하는 알고리즘이 다름.
- 스케쥴링 알고리즘의 성능을 비교할 적에는 주로 평균 대기 시간을 기준으로 함.
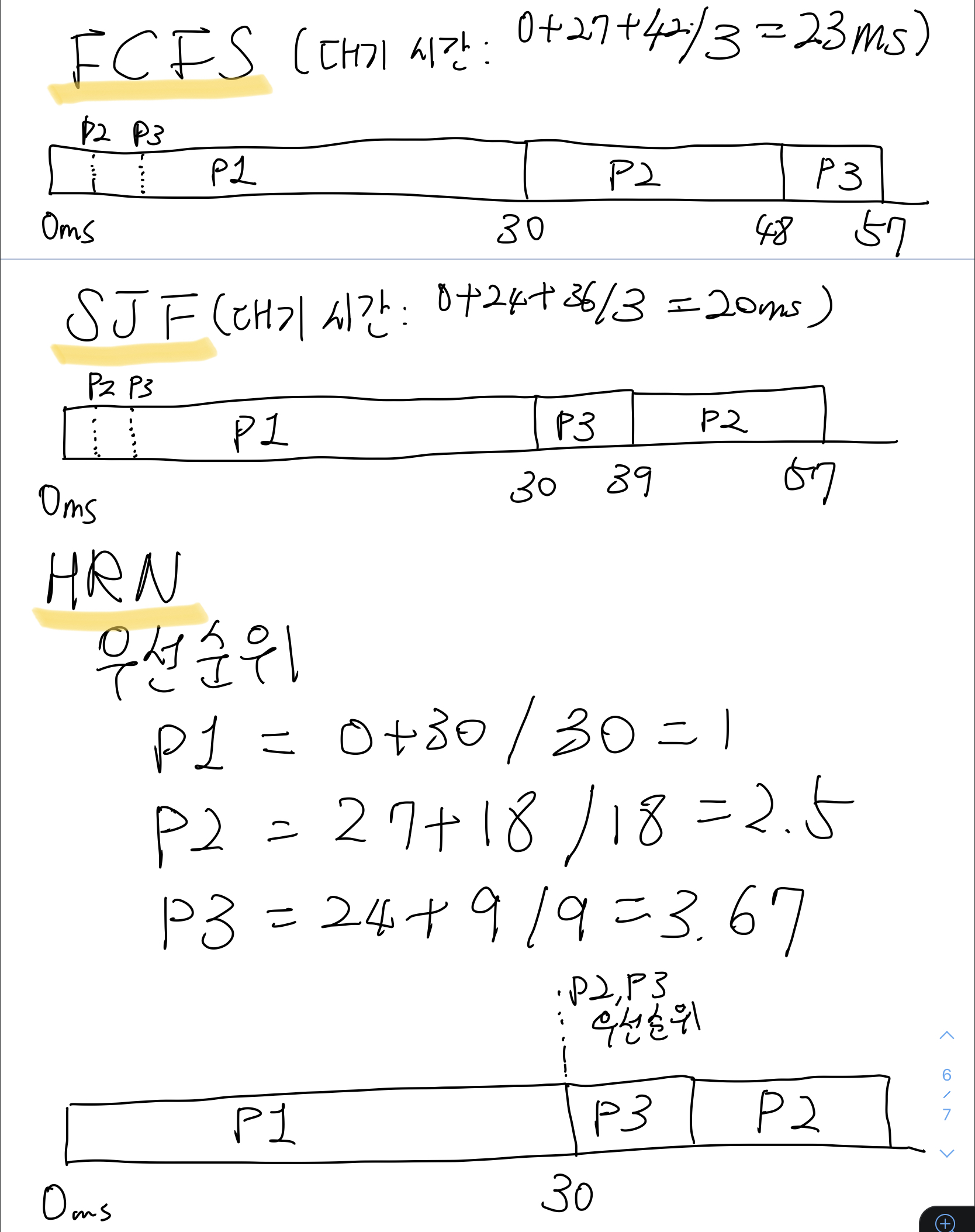
1. 비선점형: FCFS, SJF, HRN
- FCFS: 선입선출로 먼저 오는 프로세스를 먼저 실행시키는 알고리즘. 자료구조의 FIFO와 구분하기 위하여 다음과 같이 표기
- 장점(+): 오는 순서대로 프로세스 실행하기에 로직이 단순하고 공평성을 보장.
- 단점(-): 대기 시간이 길어짐. 이로 인한 비효율적인 CPU 사용.
- SJF: 실행 가능한 프로세스 중 가장 실행 시간이 짧은 프로세스부터 실행시키는 알고리즘.
- 장점(+): FCFS보다 CPU 효율성이 좋아짐.
- 단점(-): 언제 프로세스 시행이 끝날지 알지 못하므로 사용자 반응을 기반으로 하는 대화형 시스템에는 적절하지 못함. Starvation 현상이 발생(프로세스 실행 시간이 긴 경우 무한정 연기될 수 있음).
- HRN: SJF 알고리즘의 Starvation 문제를 해결하기 위해 서비스를 받기 위해 기다린 시간과 CPU 사용 시간을 고려하여 우선순위를 정하고 스케쥴링하는 알고리즘.
우선순위 = (대기 시간 + CPU 사용시간) / CPU 사용시간
2. 선점형: Round Robin, SRT, 다단계 큐, 다단계 피드백 큐
- Round Robin: Timeslice를 정하고 준비 큐에 있는 프로세스들을 순차적으로 Context switching하며 실행시키는 알고리즘.
- Timeslice가 너무 큰 경우, 멀티프로세싱 환경에서는 CPU가 동작하지 않는 것처럼 보일 수 있음. 반대로, 너무 작은 경우 Context Switching이 자주 일어나 실제 작업하는 시간이 증가할 수 있음.
- 장점(+): 한 프로세스가 CPU를 독점하는 것을 방지할 수 있음. 공평성 보장
- 단점(-): Context Switching에 따른 오버헤드 증가
- SRT: SJF + Round Robin 방식으로, 기본적으로 Round Robin으로 하되 프로세스 선택 시 남아있는 실행 시간이 짧은 프로세스 위주로 실행)
- 전체적인 대기 시간은 짧아질 수 있으나 준비 큐에서 가장 짧은 실행시간이 남아있는 프로세스를 찾기 위해 탐색해야 하는 시간이 추가로 발생함. 또한, 전체 프로세스 종료 시간을 예측할 수 없어 SJF의 단점인 Starvation이 발생
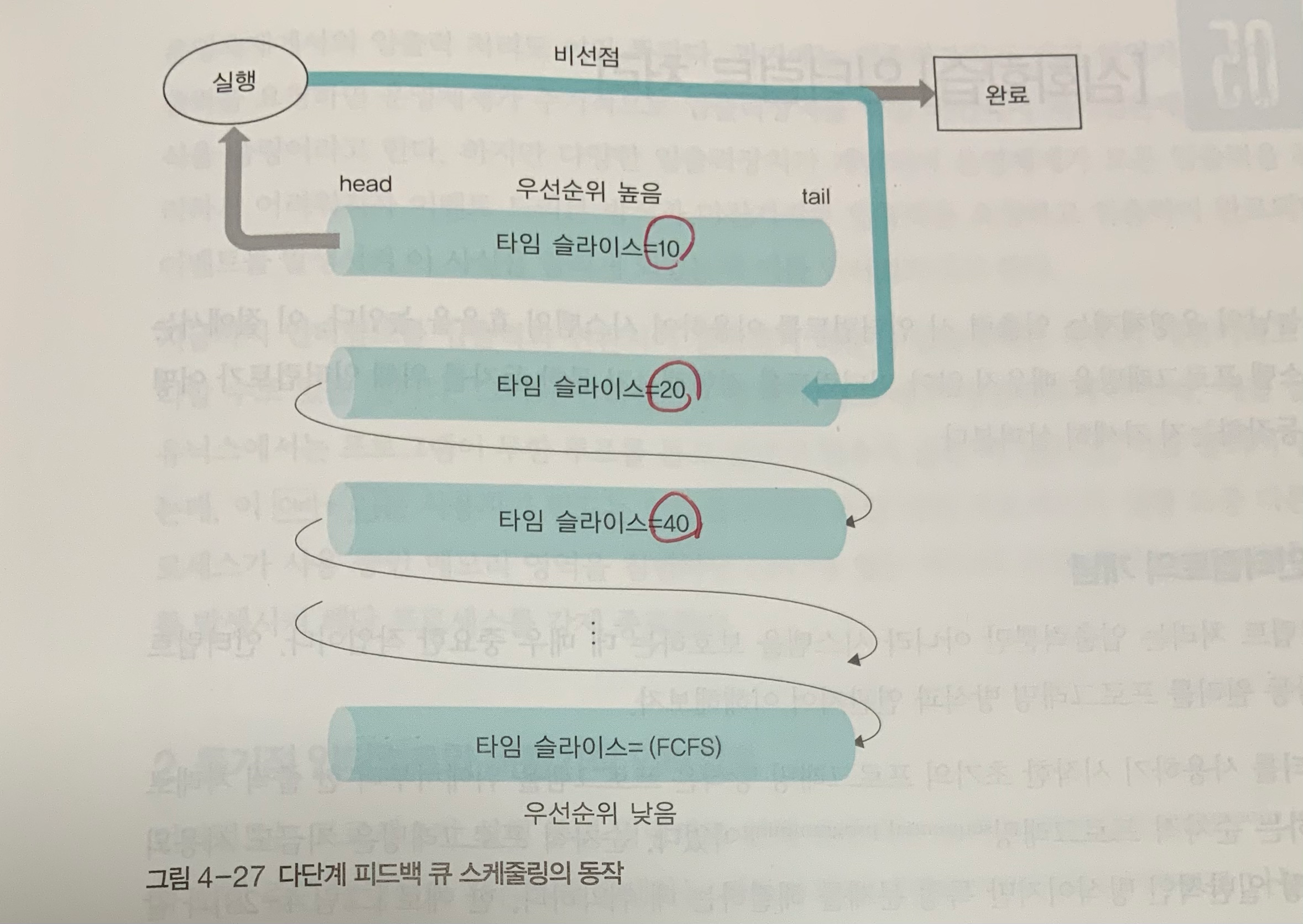
- 다단계 큐: 우선순위를 가진 여러 개의 큐를 활용하여 스케쥴링하는 알고리즘. 각 큐별로 Round Robin 방식으로 운영하며 우선순위가 가장 높은 큐에 있는 작업(프로세스)부터 먼저 시작함. 우선순위에 따라 작업을 실행할 뿐더러 우선순위에 따라 Timeslice를 조절하여 실행할 수 있음. 고정적인 우선순위 방식으로 CPU에서 한번 우선순위가 결정되면 프로세스 종료까지 절대 바뀌지 않음
- 단점(-): 우선순위가 높은 순으로 실행할 때 CPU가 실행중인 프로세스가 종료되지 않으면 그 이하의 우선순위를 가지는 프로세스를 실행할 수 없음. 따라서 우선순위가 낮은 프로세스가 연기되는 현상이 발생
- 다단계 큐의 한계를 보완하고자 다단계 피드백 큐가 등장
- 다단계 피드백 큐: 기본적으로 다단계 큐와 동작원리는 동일하되 우선순위가 높은 작업이 CPU에서 실행되고나면 우선순위가 낮아짐(dynamic priority). (단, 커널 프로세스는 user 프로세스보다 항상 우선순위가 높음)
- 우선순위가 낮아질수록 Timeslice값은 커짐. 따라서, 마지막 우선순위 큐 Timeslice는 무한대에 가까우며 FCFS 방식으로 처리함
- 오늘날의 CPU에서 가장 많이 활용하는 알고리즘 방식(유닉스에서는 Timeslice값을 사용자가 직접 바꿀 수 있음)

5. 인터럽트
-
이벤트 드리븐(Driven)과 유사한 방법으로 입출력 등과 같은 사용자 혹은 시스템 요청이 들어올 시 실행중인 프로세스를 대기 상태 큐로 보내고 요청에 대한 응답이 완료되면 이벤트를 발생시켜 이 사실을 알리는 구조
-
인터럽트의 종류로는 동기적 인터럽트, 비동기적 인터럽트 두 가지가 있다.
-
동기적 인터럽트: 프로세스가 실행 중인 명령어로 인해 발생하는 인터럽트
- 오버플로, 언더플로 등의 잘못된 메모리 접근 시 발생하는 인터럽트
- 유닉스의 ctrl+c 등의 강제종료와 같은 사용자의 의도적인 프로세스 중단
- 입출력 장치 등의 주변기기 조작에 의한 인터럽트
- 산술 연산 중 발생하는 인터럽트(예: 0으로 나누기)
-
비동기적 인터럽트: 실행 중인 명령어와 무관하게 발생하는 인터럽트
컴퓨터 하드웨어적인 이슈(정전, 하드디스크 읽기 오류, 메모리 인식 오류 등)로 인하여 발생하는 인터럽트
-
-
처리과정
- 인터럽트 발생 시 먼저, 실행 중인 프로세스를 일시정지 시킴. 또한, 관련 정보를 재시작을 위하여 임시로 저장
- 인터럽트 컨트롤러가 시행되며 각각의 인터럽트마다 부여된 고유 번호(IRQ)가 존재. 이 번호를 가지고 어떤 인터럽트가 발생했는지 확인. 이를 통해 발생한 인터럽트들의 우선순위를 판단하여 처리 순서 결정
- 동시 다발적으로 발생할 수 있는 인터럽트를 하나로 묶어서 관리하는 '인터럽트 벡터'가 존재하여 인터럽트 처리 순서에 따라 해당 번호의 인터럽트 헨들러를 발생시켜 연결된 함수를 시행
- 인터럽트 헨들러 처리 완료 후 일시 정지된 프로세스를 재시작하거나 혹은 종료시킴
-
인터럽트와 이중모드
- 프로세스는 크게 일반 프로세스, 커널 프로세스가 존재하는데 각각의 프로세스가 시행되는 상태를 user mode, kernel mode라고 함
- 자원을 보호하기 위하여 다음과 같이 나뉘었는데 일반 프로세스는 kernel mode에 진입할 수 없음. 따라서, 사용자가 하드디스크 접근, 프로세스 생성 등과 같은 커널 기능을 사용하려면 시스템 호출을 해야함. 이때 발생하는 것이 인터럽트.
- 사용자가 직접적인 시스템 호출 이외에도 API를 통한 커널 자원 접근이 가능
사용자가 커널 모드에 진입하려면, 1. 시스템 호출(자발적) 2. 인터럽트 발생(비자발적) 둘 중 한 가지 이벤트가 발생하여야 함
6. CPU 스케쥴러
1. Linux O(1) 스케줄러
- Task 개수와 관계없이 select/add task하는 데 필요한 시간이 상수 시간인 스케줄러
- Round Robin 방식을 기반으로 Timeslice를 low priority task에는 작은 값을, high priority task에는 큰 값을 할당함
- 선점형&priority-based task 환경에 적합
- task sleep time(waiting/idling) 길이에 따라 priority 설정됨.
longer sleep일 경우 I/O bound와 같은 interactive task라 판단하여 priority를 올림(Runqueue의 맨 위, 맨 처음에 위치시킴)
smaller sleep일 경우 compute-based task라 판단하여 priority를 낮춤(Runqueue의 맨 아래, 맨 뒤에 위치시킴) - Runqueue Data Structure(Multiple queue와 유사한 개념)를 가지고 있음. 2개의 배열로 구성됨(Active VS Expired)

- 단점(-): interactive task에서는 performance issue가 있음, Jitter가 잦음, task별 편차가 심함(공평성에 어긋남)
- O(1) 스케줄러의 한계를 보완한 스케줄러인 CFS 스케줄러가 등장. 현재 Linux 스케줄러 표본으로 활용되고 있음
2. CFS 스케줄러
- Non-real time task를 처리하기 위하여 Runqueue상에서 공정한 task 배분이 이루어질 수 있도록 하는 스케줄러(real-time task는 real-time 스케줄러가 관리함)
- Runqueue 데이터 구조: Red-Black Tree
- Virtual 런타임 크기에 따라 정렬됨(Tree에서 왼쪽은 작은 값, 오른쪽은 큰 값)
- 항상 leftmost node를 선택. leftmost node 시간을 기준으로 스케줄링(virtual 런타임은 주기적으로 조정됨)
- Virtual Progress rate: Virtual runtime이 증가하는 속도. Virtual Progress rate 증가폭이 작으면 높은 우선순위의 task이고 크면 낮은 우선순위 task
- Performance: select(O(1)), add(O(logN))
7. Multi-Processor Scheduling
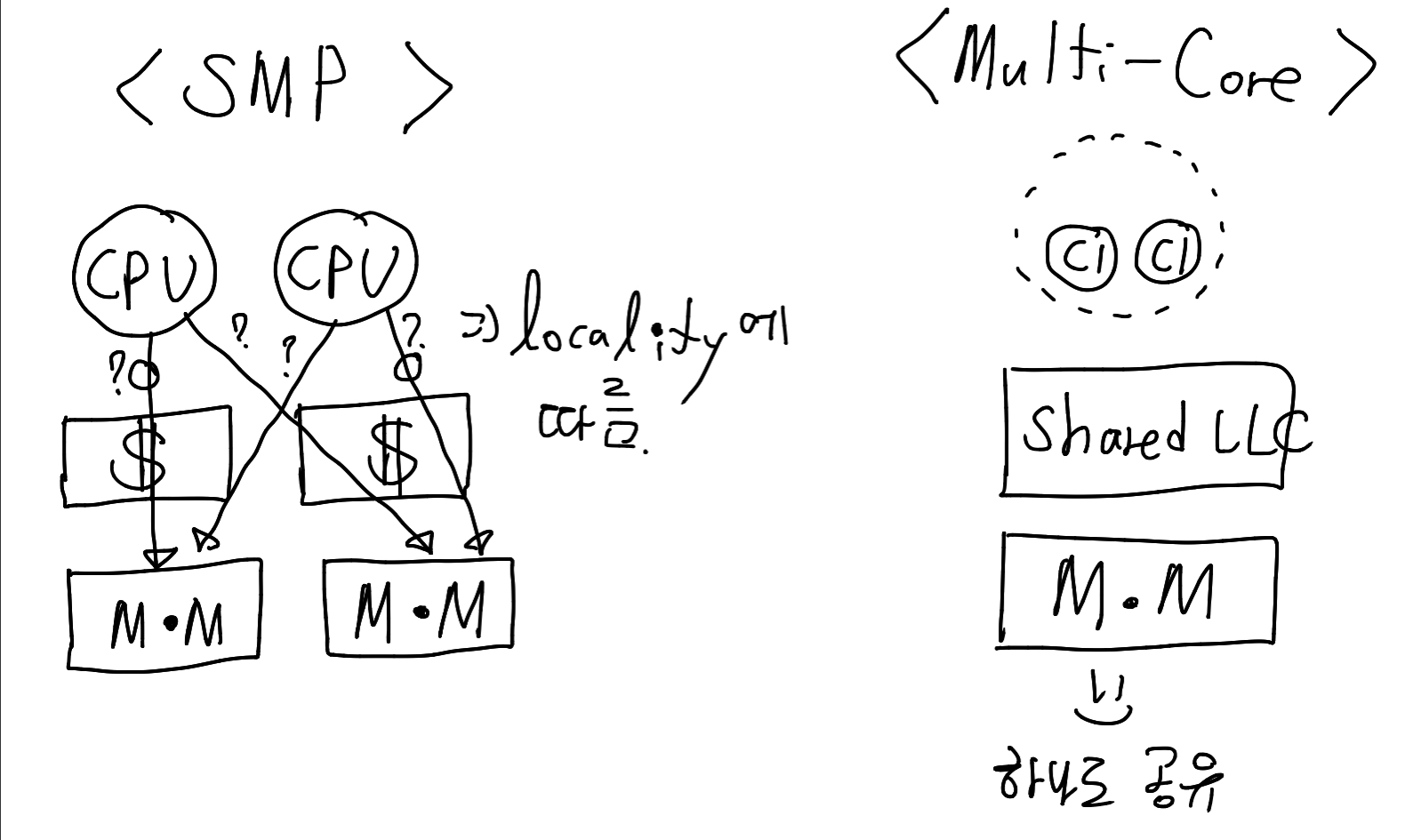
1. SMP 구조
- 여러 개의 메모리 노드들을 각각의 multi-processor socket에서 가까운 메모리에 접근하는 방식
- 스레드마다 캐시 사용량이 다 다를 수 있기에 'keep task on the same CPU as much as possible!' => 여기서 load-balancing이라는 개념이 등장
2. multi-core 구조
- 하나의 CPU안에 여러 개의 core로 구성하여 한 개의 shared LLC(cache)와 Main Memory에 접근하여 처리하는 방식
Hyperthreading
- CPU안의 register들간의 multi-threading으로 통신하는 방법. Single CPU안의 register간의 context switching을 가능하게 하는 방식으로 빠른 속도 지원
- Boot-up시 hyperthreading enable/disable 결정 가능. enable 시 하나의 CPU안의 레지스터같은 하드웨어들을 각각의 독립된 context로 인식
- 만약 시행하고자 하는 스레드가 idle 상태일 때보다 context-switching 시간이 더 짧다면 latency를 없애기 위한 context switching 실행
- 이론적으로는 CPU bound thread와 memory bound thread를 적절하게 섞어 실행하면 CPU 성능을 최대치로 낼 수 있으나 현실적으로는 불가능
- Hardware-counter value(IPC, cache usage, power&energy data 등)으로 CPU bound vs memory bound 구분 가능(각각의 필요한 리소스 정보를 알아낼 수 있음)
참고자료: 쉽게 배우는 운영체제, Introduction to Operating System(Udacity), Operating System concepts 9th