
Chapter 3.
3장에서는 데이터를 저장하는 방법을 학습한다.
자바진영에서는 관계형 뎅이터베이스와 SQL을 사용할 때 JDBC, JPA를 가장 많이 사용한다.
Spring Jdbc와 Spring JPA를 활용하면 더욱 쉽게 사용할 수 있다.
JDBC
일단 의존성을 추가하자
- groupId:
org.springframework.boot - artifactId:
springboot-starter-jdbc
그리고 사용하고자 하는 데이터베이스의 의존성도 추가하자
JdbcTemplate 사용하기
Spring JDBC는 JdbcTemplate 객체를 기반으로 Persistence Layer 동작을 수한한다.
Read
데이터를 조회할 때는 query, queryForObject 같은 메소드를 사용한다.
query()
query 메소드는 여러 형태로 제공된다. 그 중 query(String sql, RowMapper method) 하나 이상의 Row를 얻고 싶을 때 사용하며 다음과 같은 형태로 사용된다.
@Override
public Iterable<Ingredient> findAll() {
return jdbc.query(
"SELECT id, name, type FROM Ingredient" // SQL 실행된 후 RowMapper 실행
this::mapRowIngredient); // SQL 실행 결과 Row의 수 만큼 ResultSet, rowNum이 생성되어 RowMapper에게 전달됨
}
// ResultSet에는 SQL에서 요청한 column들의 정보가 key-value 형식으로 제공됨
private Ingredient mapRowIngredient(ResultSet rs, int rowNum) throws SQLException {
return new Ingredient(
rs.getString("id"),
rs.getString("name"),
);
}queryForObject()
하나의 Row만 얻고 싶을 때는 queryForObject를 사용한다.
query에는 T query(sql, rowMapper)가 없기 때문이다. List<T> query(sql, rowMapper)만 있다.
@Override
Ingredient findById(String id) {
return jdbc.queryForObject(
"SELECT id, name, type FROM Ingredient WHERE id = ?",
this::mapRowToIngredient, id);
}위와 같이 ?에 해당하는 녀석들을 마지막에 매개변수로 넘겨줘서 매핑할 수도 있다.
Create / Update / Delete
세 동작 모두 update 메소드를 사용한다.
Create
일반적인 insert SQL에 생성하고자 하는 값들을 매핑만 해주면 된다.
@Override
public Ingredient save(Ingredient ingredient) {
jdbc.update(
"INSERT INTO Ingredient (id, name, type) values (?, ?, ?)",
ingredient.getId(),
ingredient.getName(),
ingredient.getType());
return ingredient;
}조금 더 복잡한 Create
A를 저장한 후 A의 id를 리턴 받아서 기억하고 있다가 B에 A의 id를 포함시키며 저장하는 로직을 수행해보자
위의 로직을 순서대로 살펴본다.
- 먼저, A를 저장한다.
일반적인String타입의 SQL을 사용하지 않고PreparedStatementCreatorFactory를 활용하여PreparedStatement를 생성한다.
private long saveAInfo(A a) {
...
// Factory가 생성하는 PreparedStatement에는 ?에 해당하는 데이터 타입만 매핑해준다.
PreparedStatement psc = new PreparedStatementCreatorFactory(
"INSERT INTO A (name, createdAt) values (?, ?))",
Types.VARCHAR, Types.TIMESTAMP
).newPreparedStatementCreator( // 위에서 등록한 ?에 매핑할 데이터들을 매핑
Arrays.asList(
a.getName(),
new Timestamp(a.getCreatedAt().getTime())
)
);
...
}- 저장한 A의 id를 리턴 받을
KeyHolder객체를 생성하고
jdbc.update(PreparedStatement, KeyHolder)메소드를 통해 저장한다.
private long saveAInfo(A a) {
...
// Factory가 생성하는 PreparedStatement에는 ?에 해당하는 데이터 타입만 매핑해준다.
PreparedStatement psc = new PreparedStatementCreatorFactory(
"INSERT INTO A (name, createdAt) values (?, ?))",
Types.VARCHAR, Types.TIMESTAMP
).newPreparedStatementCreator( // 위에서 등록한 ?에 매핑할 데이터들을 매핑
Arrays.asList(
a.getName(),
new Timestamp(a.getCreatedAt().getTime())
)
);
KeyHolder keyHolder = new GeneratedKeyHolder();
jdbc.update(psc, keyHolder);
return keyHolder.getKey().longValue();
}리턴 받은 id를 활용하여 나머지 저장 로직을 작성하면 된다.
SimpleJdbcInsert로 Create 로직 쉽게 수행하기
SimpleJdbcInsert를 사용하면 훨씬 코드가 줄어든다.
- 생성자에서 작업을 하고 싶은 테이블에 해당하는
SimpleJdbcInserter를 생성한다.
private SimpleJdbcInsert orderInserter;
@Autowired
public JdbcOrderRepository(JdbcTemplate jdbc) {
orderInserter = new SimpleJdbcInsert(jdbc)
.withTableName("Order")
.usingGeneratedKeyColumns("id");
}- 생성한
SimpleJdbcinsert인스턴스를 활용하여Create로직을 수행한다.
private long saveOrder(Order order) {
// Map 형태의 파라미터를 넘겨주면 create가 진행된다.
Map<String, Object> values = objectMapper.convertvalue(order, Map.class);
long orderId = orderInserter
.executeAndReturnKey(values)
.longValue();
}org.springframework.core.convert.converter
Converter는 Interface로서 클래스로 구현해서 사용하면 된다. Converter<S, T>의 형태이며 S를 T 타입으로 변환해준다.
thread-safe하며 공유될 수 있다.
public class MyConverter implements Converter<String, Ingredient> {
return ingredientRepository.findById(id);
}새로 알게된 Annotation
@Repository
스테레오 타입 애노테이션 중 하나이다. 스프링에게 이 클래스가 어떤 역할을 하는지 알려준다. Component Scan이 자동으로 찾아와서 스프링 애플리케이션 컨텐스트의 빈으로 생성해준다.
@ModelAttribute
바인딩한 메소드 파라미터나 메소드 리턴값을 지정한 이름의 model attribute에 넣어서 web view에 출력해준다.
메소드 레벨
메소드 레벨에 바인딩한다면 해당 메소드가 하나 이상의 model attribute를 추가하기 위한 목적이라는 것을 나타낸다. @RequestMapping, @GetMapping, @PostMapping 등의 어노테이션도 model attribute 추가를 허용하지만 @ModelAttribute는 요청에 직접적으로 매핑할 수는 없다.
만약 @ModelAttribute가 붙은 메소드가 존재한다면 Spring-MVC는 @RequestMapping 메소드들을 호출하기 전에 가장 먼저 @ModelAttribute가 붙은 메소드를 호출한다.
메소드 파라미터 레벨
HTTP 요청에 들어있는 속성값들을 파라미터에 매핑해준다. View와의 상호작용이 필요하다. 주로 form 데이터를 받을 때 많이 사용한다.
@SessionAttributes
애노테이션에 설정한 이름의 데이터들을 세션에 넣어주는 역할을 한다.
특히, @ModelAttribute는 세션에 존재하는 데이터들도 바인딩하기 때문에 @SessionAttribute와 @ModelAttribute를 조합하여 사용하면 서로 다른 페이지에서 유지하고 있는 정보들을 공유할 수 있다.
사용이 끝난 세션 데이터는 SessionStatus.setComplete()를 호출하여 cleanup을 통해 서버의 과부하를 막아야 한다.
@SuppressWarnings
IntelliJ 기준으로 컴파일러에 의해 노란색 경고가 나타나는 것을 방지해준다.
IDE가 정적분석을 할 떄 해당 노란색 경고를 무시해달라고 요청하는 어노테이션이다.
파라미터는 여러가지 String 타입이 존재한다.
SQL 쿼리 실행시키기
만약 테이블 정의에 관한 SQL을 실행시키고 싶다면 테이블 생성 SQL이 작성된 schema.sql 파일을 src/main/resources에 저장하면 된다.
만약 데이터 생성에 관한 SQL을 실행시키고 싶다면 데이터 생성 SQL이 작성된 data.sql 파일을 src/main/resources에 저장하면 된다.
그러면 Spring Application이 시작될 때 두 SQL 파일을 실행시킨다.
javax.persistence.*
@Entity
해당 클래스가 테이블이라고 선언한다. 반드시 클래스안에 @Id가 선언되어야 한다.
클래스의 이름을 대문자를 기준으로 구분하여 _와 연결시켜서 생성해준다.
ex) orderIngredient -> order_ingredient
@Id
테이블의 기본 키와 매핑한다.
@GeneratedValue( strategy= GenerationType)
자동으로 값이 생성되게한다. TABLE, SEQUENCE, IDENTITY, AUTO전략이 있다.
-
AUTO:@generatedValue의 기본값이다. hibernate가 데이터베이스에 맞는 전략을 선택한다. -
IDENTITY:auto-increment와 같은 의미이다. -
SEQUENCE:SEQUENCE를 이용하여 PK를 생성한다. -
TABLE:TABLE을 이용하여 PK를 생성한다.
@ManyToMany
각기 다른 테이블에 존재하는 컬럼 사이에 M:N 관계를 매핑할 떄 사용한다.
@PrePersist
새로운 entity 객체가 생성되기 전에 지정한 메소드의 코드가 동작한다.
@PrePersist
void createdAt() {
this.createdAt = new Date();
}JPA
CrudRepository<T, ID>
T에는 entity 클래스를 넣고 ID에는 entity 클래스의 id의 자료형을 넣는다.
T save(T)Iterable saveAll(T)Optinal<T> findById(ID)boolean existsById(ID)Iterable<T> findAll()Iterable<T> findAllById(Iterable<ID>)long count()void deleteById(ID)void delete(T)void deleteAll(Iterable<T>)void deleteAll()
JpaRepository<T, ID>
CrudRepository의 메소드를 포함하면서
-
void flush() -
S saveAndFlush(T) -
void deleteInBatch(Iterable<T>) -
void deleteAllInBatch() -
T getOne(ID)와 같은 메소드가 추가되었다.
메소드 시그니처로 쿼리짜기
Spring Data는 Repository에 정의한 메소드의 시그니처를 분석하여 수행되어야 할 쿼리를 결정한다.
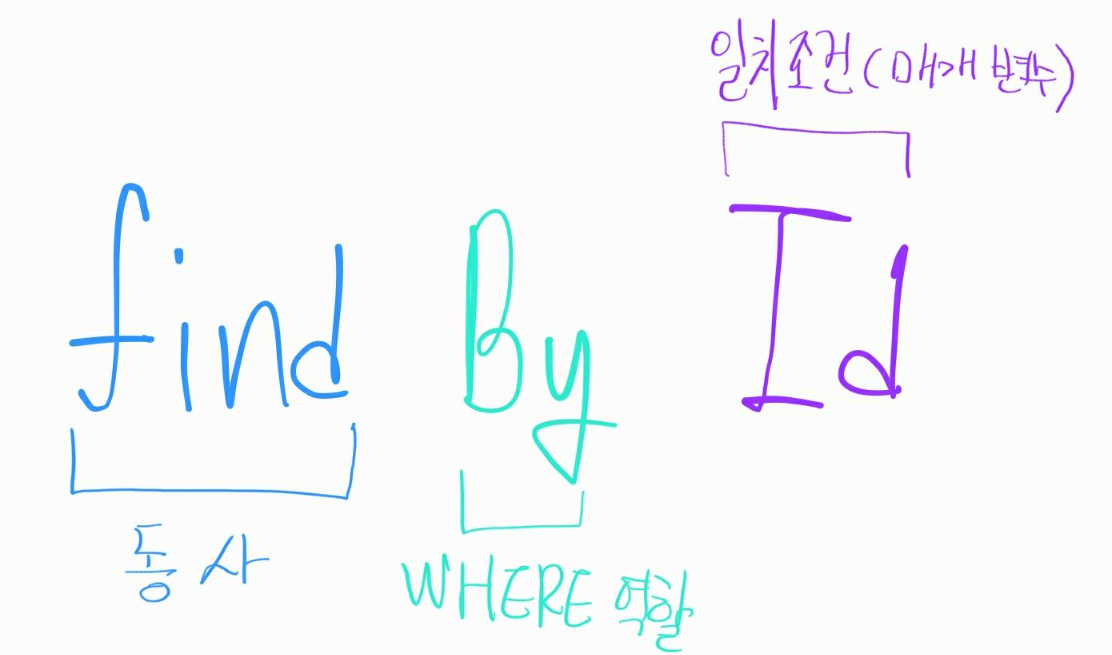
이외에도 정렬, 대소관계비교, 포함 등 복잡하지 않은 동작을 메서드 시그니처로 대체할 수 있다.
@Query()
메서드 시그니처로 대체할 수 없는 경우 직접 Query를 작성한다.
CommandLineRunner
Spring Boot에서 지원하는 인터페이스로서 Spring Application 구동 시점에 특정 코드를 실행 시킬 때 사용한다.
void run(String... args) throws Exception; 를 오버라이딩하여 사용한다.
@Bean
public CommandLineRunner dataLoader(OrderRepository repo) {
return new CommandLineRunner() {
@Override
public void run() throws Exception {
repo.save(new Order());
}
};
}
// lambda식으로 대체
@Bean
public CommandLineRunner dataLoader(OrderRepository repo) {
return args -> {
repo.save(new Order());
};
}.jpg)