크롤링하다가 에브리타임 계정 차단 당함... 다들 미리 알아보고 조심합시당...
그래서 크롤링 준비 작업은?
이번 프로젝트는 로그인을 해야 데이터를 수집할 수 있어 가상브라우저를 통해서 자동로그인을 실행하고 크롤링을 진행했다.
크롤링에 대해 무지했던 나는 header에 정보를 넣지 않은채 크롤러를 돌려서 차단을 당했다😭 header정보가 중요한 이유는 자동화 봇이라는 것을 속이기 위함이다! 백엔드 개발자들이 크롤링을 정말 싫어하는 이유는 브라우저와 서버사이 요청과 응답을 통해서 데이터를 주고 받는데 자동화 봇으로 인해 요청이 쌓이다보면 서버가 다운될 수 있기때문이다....다들 서버에 무리가지 않게 크롤링하도록..! 아무튼 크롤링할 때 서버에 내가 봇이 아니라는 것을 인지시켜주어야 이유이다.
1. robots.txt로 확인할 것
웹사이트의 최상위 페이지에서 robots.txt를 적용하기
ex) www.example.com/robots.txt
그러면 파일이 다운된다.
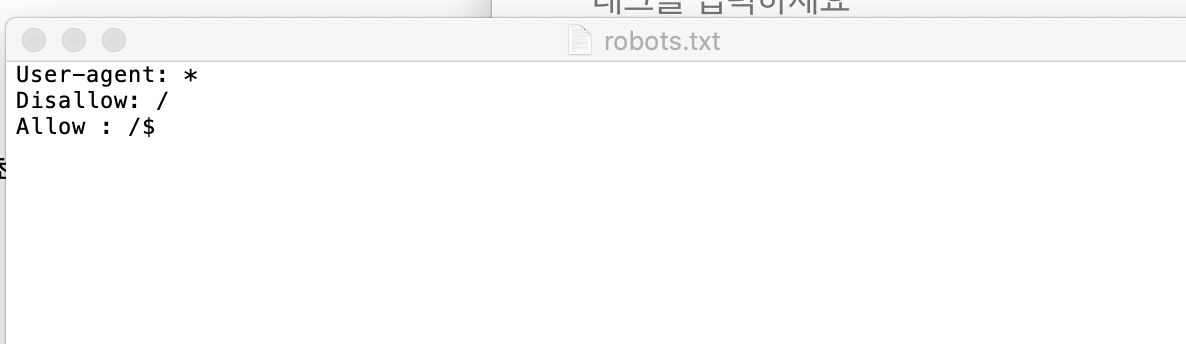
User-agent: 허용하는 검색봇 이름
Allow: 허용하는 경로
Disallow: 접근 불가능한 경로
예시) 모든 검색봇을 차단
User-agents: * 모든 검색봇
Disallow: / (모든 디렉토리)
예시) 모든 검색봇을 허용
User-agents: * 모든 검색봇 차단
Disallow:
2. code내에서
1. User-Agents 설정하기(header에 넣어줄 부분)
2. sleep으로 페이지마다 쉬어주기 **time.sleep(3)**
3. 동일한 시간이 아니라 random함수를 사용해서 쉬는시간을 랜덤하게 바꾸어주기 **time.sleep(random.uniform(2,4)) :2~4초 사이의 랜덤한 float 수**
4. 반복횟수가 많을수록 더 많이 쉬어주기로그인 크롤링 기본 코드
import requests
url = "http://example.com"
login_info = {
"userID": "your_id",
"userpw": "your_password"
}
#세션 만들기
session = requests.session()
response=sessioin.get(url,data=login_info) #get,post,put
#로그인 실행
response.raise_for_status()
print(response.text)실제 적용한 자동로그인 코드
가상브라우저를 처음 사용해봤는데 코드를 실행하면 자동으로 gui가 만들어져서 내가 짠 코드대로 페이지가 움직인다! 완전 신기🙂👍
자동화 프로그램을 처음 짜보았는데 요거요거 재밌고만👩💻
#자동 로그인
import selenium
from selenium import webdriver as wd
import time
import pandas as pd
import random
#에브리타임 자동 로그인
#가상브라우저 사용
options = wd.ChromeOptions()
options.add_argument("no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("user-agent={Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36}")
driver = wd.Chrome(executable_path='/usr/local/bin/chromedriver', options = options)
driver.maximize_window()
baseURL = 'https://test.com'
rand_value = random.uniform(2,4) #랜덤한 시간으로
time.sleep(rand_value) #sleep걸어주기
driver.get(baseURL) #페이지가 넘어갈 때마다 sleep걸어주어서 서버에 무리가 가지 않게 해야함
rand_value = random.uniform(2,4)
time.sleep(rand_value)
driver.find_element_by_css_selector('#account > a:nth-child(1)').click()
driver.find_element_by_name('userid').send_keys('자신의 id를 입력해주세요')
driver.find_element_by_name('password').send_keys('자신의 password를 입력해주세요')
rand_value = random.uniform(2,4)
time.sleep(rand_value)
driver.find_element_by_xpath('//*[@class="submit"]/input').click()크롤링 코드
import re
from bs4 import BeautifulSoup
#강의 -> 강의평가
lecture_review_list=[]
url_id_list = lecture.url_id.astype(str)
for url_id in url_id_list[600:]:
#강의 페이지로 넘어가기
url = "https://everytime.kr/lecture/view/"+url_id
rand_value = random.uniform(2,5)
time.sleep(rand_value)
driver.get(url)
#하나의 강의 평가 페이지 bs로 데이터 수집
time.sleep(3)
html = driver.page_source
soup = BeautifulSoup(html,'html.parser') #정적텍스트 분석을 사용하는 BS이 selenium보다 빠름 -> 페이지접근에는 동적 수집, 데이터 수집은 정적수집적
lecture_name = soup.select_one("#container > div.side.head > h2").text
professor_name = soup.select_one("#container > div.side.head > p:nth-of-type(1) > span").text
review_list = soup.select("article")
print(lecture_name, professor_name)
#강의리뷰
index = 0
for review in review_list:
if review.select_one('div.pay') == None: #강의평가가 아니라 중간,기말고사 족보
rate = review.select_one('p.rate > span > span')["style"] #str사용해야 re사용가능
rate = float(rate[-5:-2]) #숫자만 (리스트형태로 return되는데 [0]하면 오류뜸...)
semester = review.select_one('p.info > span.semester').text
semester = int(semester[0:2])
text = review.select_one('p.text').text
like = review.select_one("p.info > span.posvote")
if like == None:
like = 0
else:
like = int(like.text)
lecture_review_list.append({
"url_id" : url_id,
"index" : index,
"lecture_name" : lecture_name,
"professor_name" : professor_name,
"rate" : rate,
"semester" : semester,
"like" : like,
"text" : text
}
)
index+=1- (에브리타임 강의평가) like를 수집하는데 Like에 대한 정보가 있는 데이터도 있고 없는 데이터도 있다. 클래스로 select했을 때 None이 들어가므로 if data == None 으로 해당부분은 처리해주면 된다.
tip) beautifulsoup -> select에 들어갈 tag 쉽게 찾기

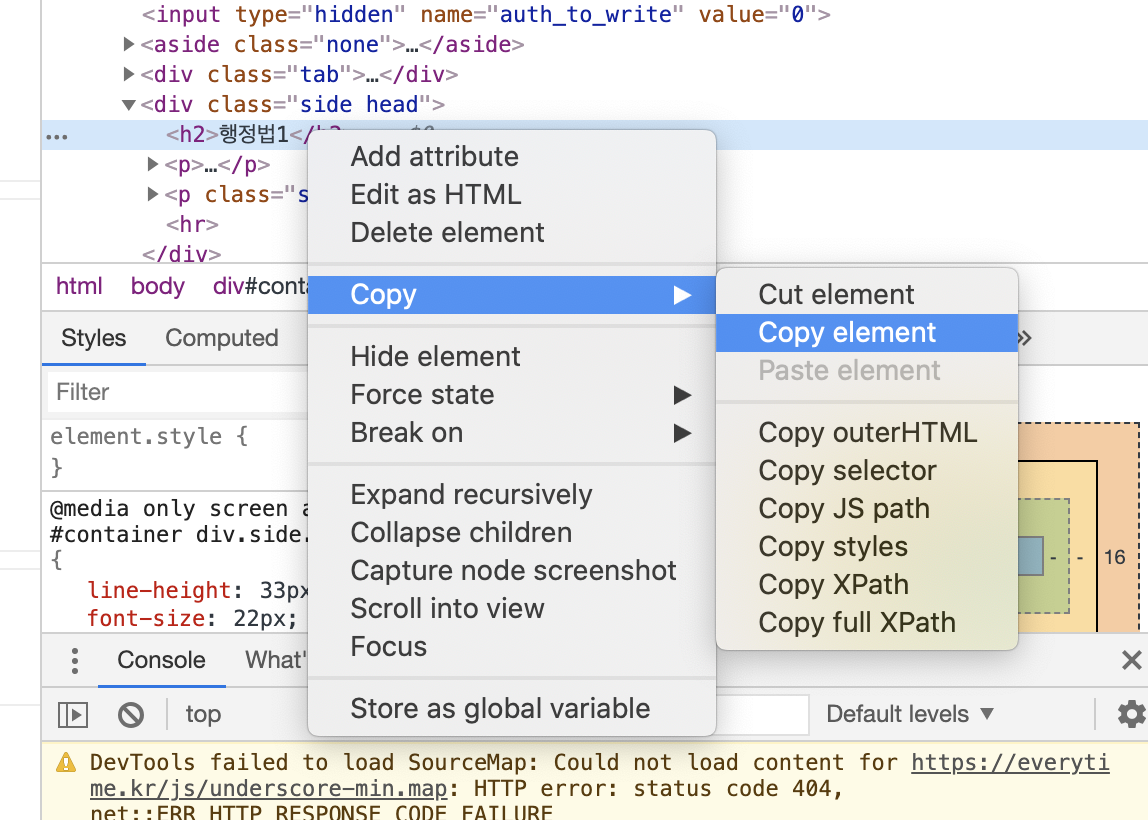
우클릭 > copy > copy element
![]()

데이터사이언스 학부생



안녕하세요, 크롤링 차단 혹시 며칠 후에 풀리는지 알 수 있을까요? 계속해서 403만 뜨는데, 급하게 에브리타임 써야할 일이 있어서 미치겠네용 ㅠ