
이 과정에 참여하게된 이유
4학년 1학기가 끝나고 계절학기 시작까지 2주정도의 시간이 생겼다. 뭔가 조그마한 프로젝트라도 해보고 싶어 여러가지를 살펴 보던중에 지인이 포스터를 보내주었다.

요즘 마이데이터와 관련된 이야기가 많이 나오면서 데이터의 가명화,비식별화 처리가 각광받고 있다는 소리가 있었다. 이 과정을 통해서 데이터의 가명화, 비식별화 그리고 그 데이터들을 통한 분석까지 배우고, 프로젝트를 진행할 수 있겠다고 생각해 지원하게 되었다.
다른 대학생들보다 종강이 빨라서 별다른 경쟁없이 교육에 지원할 수 있었고, 계절학기 시작 전까지 조그마한 프로젝트를 진행할 수 있었다. (이후 이어진 2,3차 과정들은 경쟁률이 굉장히 높았다고 한다.)
수업은 온라인으로 1주 오프라인으로 2주정도 진행하고, 마지막 2일동안 앞서 배운 과정들을 토대로 2일간 해커톤을 진행하여 순위를 매기게 된다.
프로젝트 진행
1주의 온라인교육과 2주의 오프라인 교육으로 비식별화, 익명화, 데이터분석에 관해 수업을 진행한 후, 프로젝트를 진행하였다. 나는 나혼자 이 프로젝트에 참가하였기 때문에 같이 수업을 듣던 사람과 팀을 꾸려서 진행하였습니다. 이제까지 처음 만나는 사람과 프로젝트를 진행해본적이 없어서 긴장되면서 설레었습니다.
프로젝트는 주최측에서 제공해준 여러가지 데이터를 팀별로 가명화 혹은 익명화를 진행하고 나서 그 데이터들을 가지고 유의미한 스토리를 만들어내는 것이었습니다. 이에 따른 평가기준도 제시해주셨습니다.
- 주어진 데이터를 사용할것.
- 가명화 혹은 익명화를 통해 비식별화할것.
- K-익명성, l-다양성 (필수), t-근접성 (권장)을 사용할것.
- 데이터분석을 통해 스토리를 만들어 낼것.
- 비식별화된 데이터의 결과와 raw데이터의 결과가 유사할것.
✏️상황설정
우리팀은 Bankchurner 데이터를 사용하였는데, 이 데이터는 카드사 고객들의 이탈여부를 Label로 하는 라벨링되어진 데이터셋이었다. 우리는 데이터를 사용하기전에 상황을 설정하였습니다.
- 현재 한 카드사의 직원입장에서 고객들이 전과 다르게 빠른속도로 이탈하고 있다.
- 이에 대해 경영진들은 현재 가지고 있는 고객 데이터를 활용하여 회사 내부에서 데이터를 추출하고 분석하고자 한다. 그리고 분석결과에 맞는 마케팅전략을 수립하여 고객의 이탈율을 줄이고자 한다.
- 따라서 Raw 데이터를 가명화처리하여 사내에서 분석하고자 한다.
이런 상황 설정을 통해 주어진 과제에 더욱 몰입하고 더 나은 결과를 내기위해 노력했던 것 같다. 또한 발표시에 스토리를 제공함으로써 다른팀들보다 우위를 가질 수 있었습니다.
✏️메타데이터 작성
첫 번째로 데이터셋의 속성들이 각각 어떤 뜻인지 어떤 도메인을 가지는지 표로 작성하였습니다.
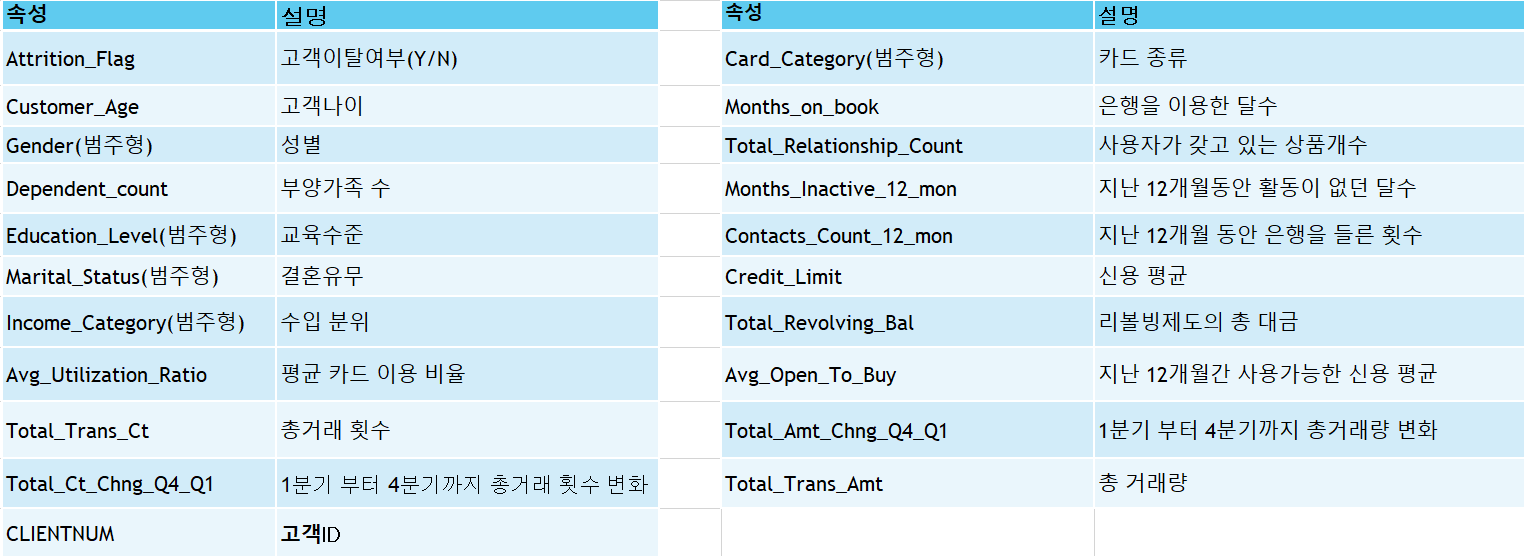
메타데이터를 작성할 때 연속형데이터와 범주형데이터를 구분하여 서로 다르게 비식별화처리를 진행하였습니다.
데이터를 식별수준에 따라서 식별자, 준식별자, 민감정보로 구분한뒤 식별자로 판단되었던 CLIENTNUM 삭제처리하였습니다. 그 다음 준식별자로 판단된Customer_Age, Dependant_count, Education_Level, Martial_Status는 각각 레벨별로 ARX를 이용하여 범주화 하였습니다. 그 결과 아래 사진과 같이 범주화하였습니다. 또한 민감정보로 구분되었던 Income_Category 유지하였습니다.

✏️K-익명성과 L-다양성 설정
K-익명성은 공개되어진 데이터 집합에서 준식별자 속성값들이 동일한 레코드가 최소 K개를 가져야 한다는 것입니다. 이는 연결공격을 막기 위한 방법입니다.
L-다양성은 동질집합의 민감정보가 최소 L개의 다양한 속성을 갖도록 하여 K-익명성의 취약점 (동질성/ 배경지식 공격)을 보완한 프라이버시 보호모델입니다.

위와 같은 방식으로 비식별화 처리하였습니다.
✏️Suppressed Records
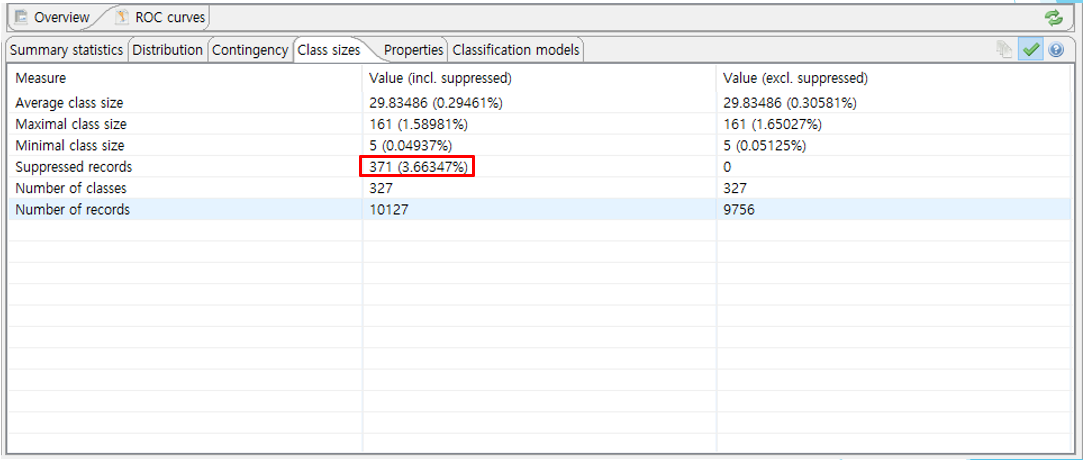
이러한 비식별화 과정을 거치면서 위의 10127개의 데이터중 비식별화 조건에 만족하지 않는 327개의 데이터들이 발생하였습니다. 우리는 재식별이 불가능한 수준의 데이터를 원했기 때문에 3.6프로의 Information Loss를 감수하기로 결정하였습니다. 이 레코드값들은 가명처리를 완료하게 되면 Null 값을 가지게된다.
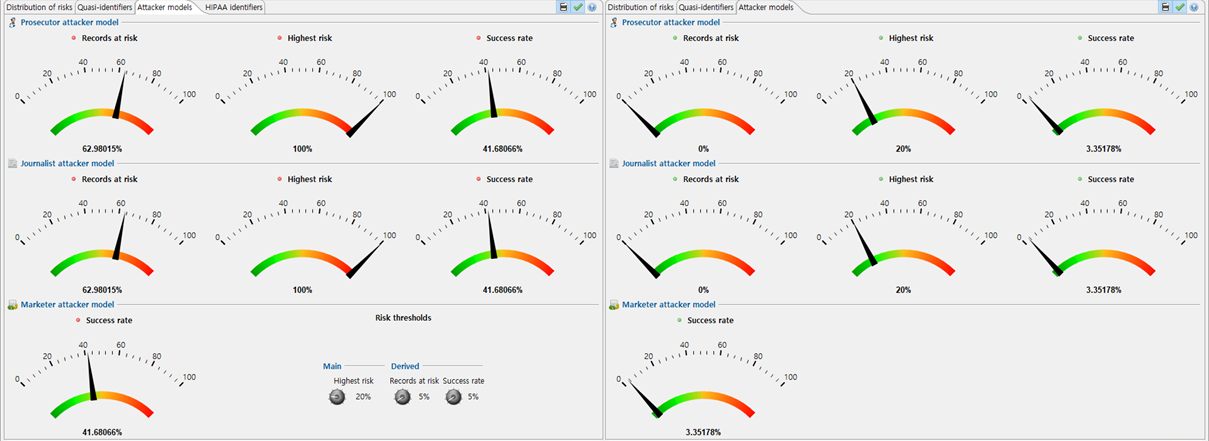
이 경우 오른쪽의 게이지를 보게 되면 재식별 가능성이 거의 없다는 것을 알 수 있었습니다.

이를 토대로 가명처리 검토 결과 보고서를 작성하였습니다. 이 데이터는 회사내에서 처리되는 정보이지만 혹시 모를 개인정보 사고를 대비하여 비식별화를 진행하였습니다. 이렇게 1일차에 목표하였던 가명처리 후 보고서 작성을 완료하였습니다.
✏️Day1 후기
해커톤 첫째날을 진행하면서 세웠던 목표는 창의적으로 어떠한 것을 만들어낸다기 보다는 주어진 데이터를 안전하고 재식별이 불가능하게 처리하고자 하였습니다. 또한 앞서 2주동안 배웠던 비식별화 절차를 모두 지켜서 진행하고자 하였습니다.
이어서

취업어케하죠