
데이터 분석
이전 회고에서는 데이터를 선별하고 그 데이터들의 속성을 중요도에 따라서 식별자, 준식별자, 민감정보로 나누어서 삭제, 범주화, 다양성을 고려하여 데이터를 비식별화 처리하였습니다.
2일차에는 이렇게 비식별화된 데이터를 이용하여 고객이탈율을 어떻게 하면 줄일 수 있는지 데이터를 분석하였습니다.
첫번째로 주어진 속성중 연속형 데이터와 라벨값과의 상관관계를 나타낼 수 있는 표를 작성하였습니다. 파이썬의 Seaborn heatmap을 사용하였습니다.

위의 표에서 1열을 통해서 라벨과 각 변수간의 상관관계를 찾아볼 수 있었습니다.
눈에 띄는 변수는 -26%의 상관관계를 나타내는 총 리볼빙대금(tot_revolving_bal)변수, -37%의 상관관계를 나타내는 총 거래 횟수(total_trans_ct), -29%의 상관관계를 나타내는 1분기부터 4분기까지 총 거래 횟수 변화(total_ct_chng_q4_q1)가 있다.
한계점
하지만 위의 표는 연속형 변수에 대해서만 상관관계를 나타내고 범주형 변수(성별, 부양자녀 등)에 대해서는 상관관계를 나타내지 못하고 있다. 그렇다고 해서 범주형 변수를 아예 무시할 수 없었기에 범주형 변수에 대한 상관관계를 나타낼 수 있는 방법을 여러방면으로 알아보았고 현장에 계시던 조교님께 R의 varimpplot을 이용하여 범주형 변수에 대해서도 상관관계는 아니지만 변수의 중요도를 측정할 수 있다는 사실을 알게되었습니다. varimpplot은 랜덤포레스트를 이용하여 분석할때 평균 지니불순도 감소량을 plot형태로 표현해줍니다. 그 속성값이 모델을 분류하는데 있어 중요하게 작용할수록 이 값은 커지는 성질을 가지고 있습니다.
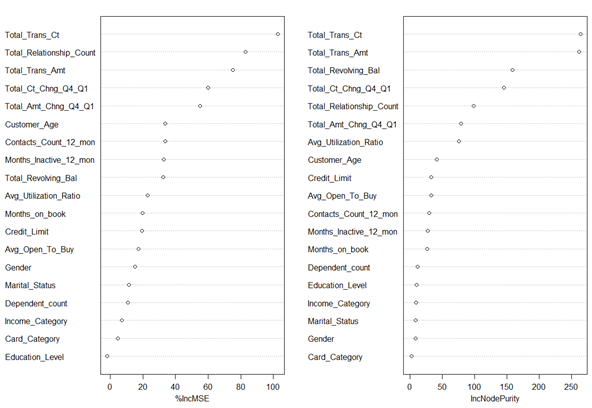
위와 같은 varimpplot을 그렸습니다. 오른쪽 IncNodePurity에 나와 있듯이 범주형 데이터(Gender, Marital_Status, Education_Level, Card_Category, Income_Category)은 대체적으로 중요도가 낮은 것을 알 수 있었습니다. 이를 확인하기 위해서 모든 변수들에 대해 라벨값에 따라서 그래프를 작성해보았습니다.
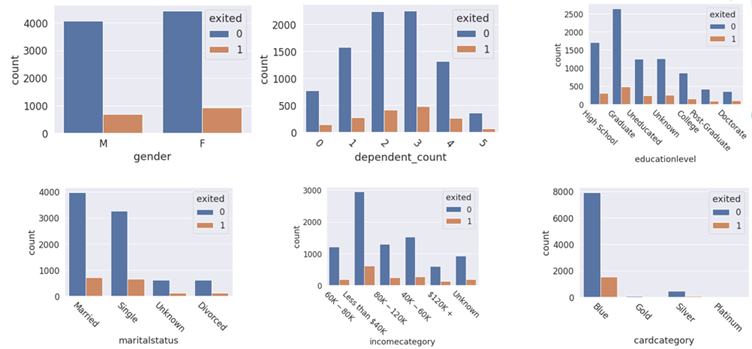
범주형 데이터들에 대해서 각각 그래프를 작성해 보았습니다. 위 표에서 나타나다시피 각 범주별로 0과 1의 비율이 크게 차이가 나지 않습니다.

하지만 위의 상관관계 표에서 라벨과 -26%의 상관관계를 나타내던 총 리볼빙대금의 분포는 0(이탈하지 않음)과 1(이탈함)에서 확연한 차이가 존재하였습니다. 이 표를 통해서 어림짐작 할수 있는것은 리볼빙 대금이 많은 사람은 이탈하지 않는다는 것, 대부분의 이탈자(1)는 리볼빙대금이 없다는것.
리볼빙이란? 이번달의 신용카드 대금의 일부만을 지급하고 나머지를 다음달로 미루는 것.

총 거래횟수에서도 0과 1의 분포가 확연하게 차이가 났다. 이 그래프를 통해서 거래량이 많을 수록 이탈하는 사람이 적고, 거래량이 적을수록 이탈율이 높다는 것을 어림짐작 할 수 있었다.
모델링
모델링 부분에서는 현재 가지고있는 비식별화된 데이터들을 랜덤 포레스트로 훈련하여서 미래의 잠재적인 이탈고객들을 식별하는 모델을 만들어낼 계획입니다. 결과적으로 잠재적인 이탈고객들을 타겟팅한 마케팅 전략을 세워서 카드이탈율을 줄이고자 합니다.
여러가지 방법으로 분석모델을 작성해보았습니다.
- 범주형 속성을 제외하고 연속형 속성의 Feature Importance를 측정한뒤 가장 importance가 높은 다섯가지의 변수로 모델링.
- 범주형 데이터를 임의로 Label Encoding하여 모델링.
- Oversampling 하여 데이터의 불균형을 해소한 뒤 모델링.
- Suppressed Records 삭제 후 모델링.
첫번째로 연속형 속성의 Feature Importance를 측정하였습니다.
model = RandomForestClassifier()
model.fit(X, y)
importance = model.feature_importances_그 결과로 아래와 같은 막대그래프를 얻을 수 있었습니다.

위와 같이 sklearn의 feature_importances를 사용하여 coef 값을 얻어 낼 수 있었습니다.

위 그래프의 막대가 각각 어떤것인지 왼쪽부터 설명해놓았습니다. 이중 1,5,8,9,10 의 속성만 가지고 분석을 진행하였습니다. 랜덤 포레스트 알고리즘을 사용하였으며 training_set과 test_set의 비율은 70:30 비율로 진행하였습니다.
그 결과 정확도는 95.3%가 측정되었습니다. 하지만 Confusion_Matrix를 작성해보니

이 중에서 모델이 1이라고 예측한 값이 실제로 1인 비율을 나타내는 Precision값은 393 / 67+393 입니다. 이를 계산하였을때 Precision값은 85.4%로 나타내어 집니다. 5개의 속성만을 이용해서 모델링을 진행하였음으로 이 정도의 Precision이 도출되었다고 생각하였습니다. 이를 개선하기 위해 모든 속성 (연속+범주)를 사용하여 모델링을 진행하고자 하였습니다.
범주형 데이터 Encoding
모든 속성을 사용하기 위해서는 범주형 데이터들을 모두 컴퓨터가 인식할 수 있는 값들로 변경해주어야 합니다. 현재의 범주형 데이터들은 아래와 같은 형식으로 구성되어 있습니다.
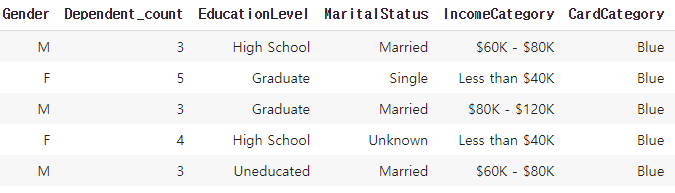
위와 같은 형식의 범주형 데이터들을 컴퓨터가 인식할 수 있는 값들로 변경시키는 방법은 두가지 방법이 존재합니다. Label Encoding 과 One-hot Encoding입니다.
Label Encoding은 우리가 흔히 생각할 수 있는 인코딩 방법입니다. 위의 표에서 한가지 속성을 예로 들면, EducationLevel의 High School을 0, Graduate를 1, Uneducated를 2로 각각 Encoding 하게됩니다. 이는 굉장히 직관적이고 쉽게 사용가능합니다.
하지만 Label Encoding의 문제점으로는 High School, Graduate, Uneducated 모두 같은 가중치를 가지게 되지만 Label Encoding을 사용하게 되면 Uneducated이 2로 인코딩되면서 가장 높은 가중치를 가지게 됩니다. 이를 보완하는 인코딩 방식이 One-hot Encoding 입니다. 가중치를 없애기 위해서 아래와 같은 방식으로 인코딩을 진행합니다.
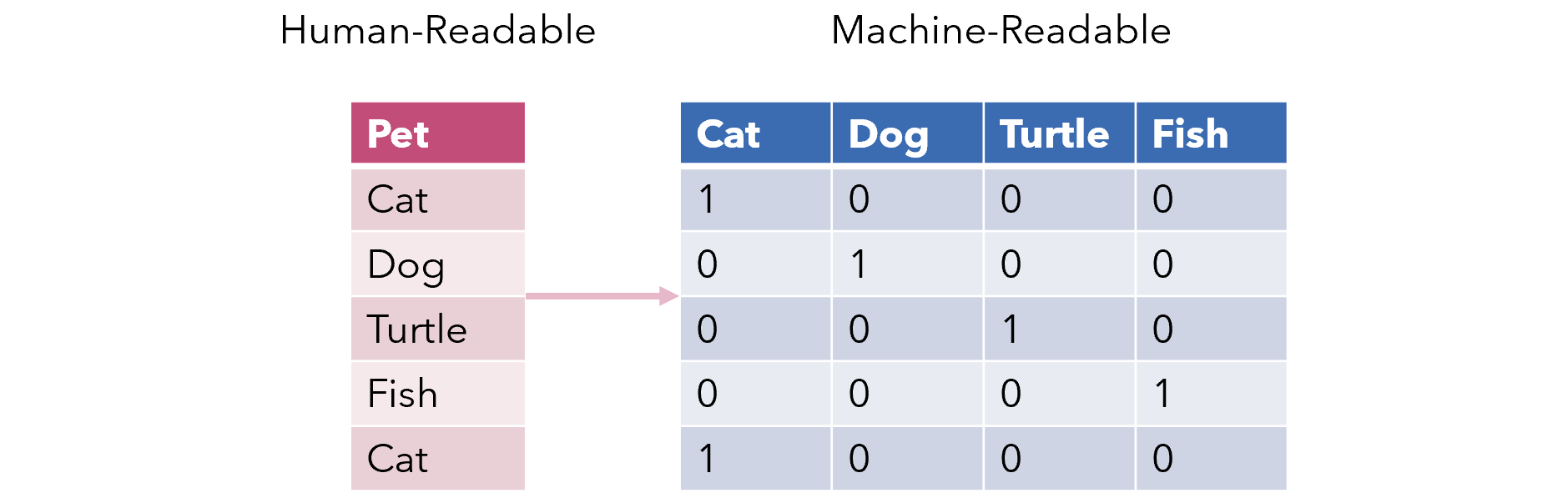
위와 같은 방식으로 인코딩하게 되면 각 값들의 가중치가 사라집니다. Label Encoding은 숫자의 차이가 모델에 영향을 주지 않는 트리 계열 모델(의사 결정 트리, 랜덤 포레스트)에 사용되어지고, One-hot Encoding은 숫자의 차이가 모델에 영향을 미치게 되는 선형 계열 모델(로지스틱 회귀,SVM)에 사용된다.
우리는 랜덤포레스트를 사용하기 때문에 Label Encoding을 사용하여 인코딩을 하였습니다. 그 결과 위의 표가 아래와 같이 바뀌었습니다.
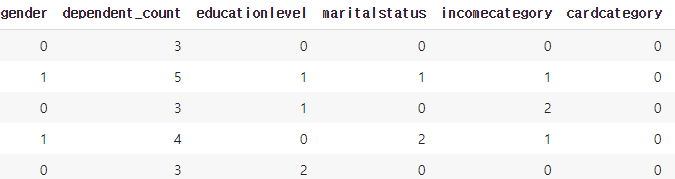
위의 표와 다르게 성별, 교육수준, 결혼상태, 카드종류, 수입종류가 인코딩되었습니다. 이 데이터를 이용하여 모든 속성들로 모델링을 진행하였습니다. 그 결과 96%의 정확도와

Precision = 417/ 45+417 값으로 90.25%의 Precision 값을 나타내었습니다.
만족스럽지 못한 Precision
모든 속성들을 이용하여 모델링을 진행했으나, 만족스럽지 못한 Precision값이 도출되었습니다. 어떤 부분에서 더 발전할 수 있는지에 대해서 고민하였습니다. 그래서 데이터들을 천천히 몇번 살펴보니 Label 값의 0과 1의 데이터의 개수가 아주 불균형하다 라는 것을 발견 하였습니다.
불균형한 Label의 값
주어진 Label 값중에서 0의 개수는 8500개, 1의 개수는 1627개 였습니다. 이런 경우 모델이 치우친 학습을 할 수 있기 때문에 부정확한 결과를 낼 수 있고 Precision 값에 영향을 미칠 수 있다고 생각하였습니다. 이를 해결하기 위한 방법으로 Label이 1인 행을 복사하여 0의 개수와 같게 하는 Oversampling을 진행하기로 결정하였습니다.
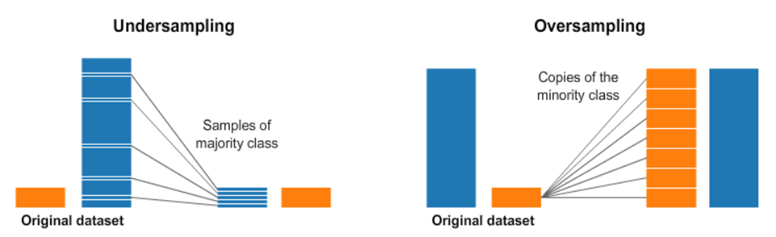
위의 그림과 같이 minor한 개수를 가지고 있는 데이터 속성의 row를 major한 개수를 가지고 있는 속성의 개수와 동일하게끔 복사합니다.

왼쪽이 Oversampling을 진행하기 전의 데이터 개수입니다. ( 8500+1627 ) 그리고 오른쪽이 Oversampling을 진행한 데이터의 개수입니다. ( 8500 + 8500 ) 이 데이터 셋을 이용하여 모델링을 진행하였습니다.
그 결과 98.6%의 정확도를 나타내었으며,

Precision = 2575 / 66 + 2575 값으로 97.3%의 Precision 값을 나타내었습니다.
Suppressed Records 삭제
회고-1의 과정에서 K = 5, L = 2 ,{2,0,0,0,1} 수준의 가명처리 과정에서 371개의 Suppressed records들이 발생했다는 것을 보았으며, 높은 수준의 가명처리를 위해 3.6프로의 정보손실을 감내하기로 하였음을 알 수 있습니다.
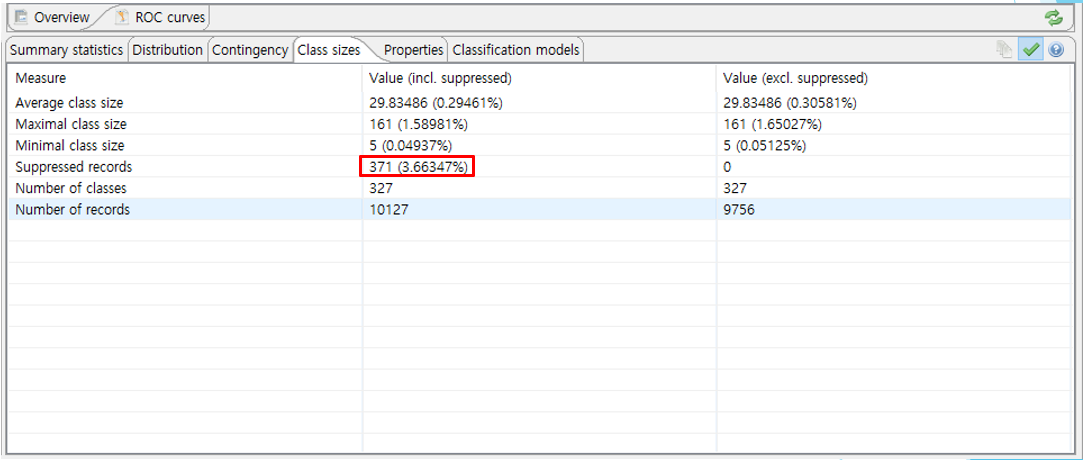
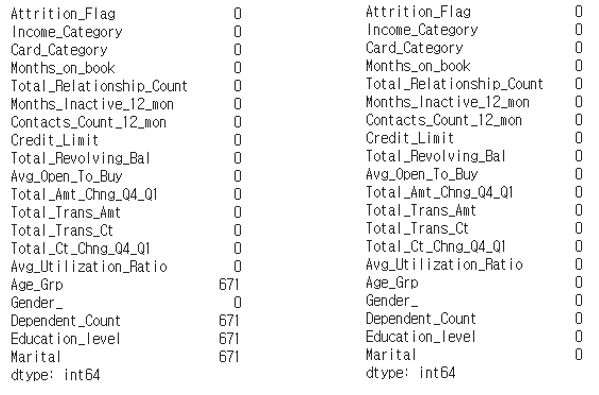
이 값들이 Oversampling 과정에서 671개로 증가하였습니다. 아래와 같이 671개로 NUll이 포함된 레코드들이 증가하였음을 알 수 있습니다. 이 값들은 삭제하기로 결정되어 있었으므로 삭제 처리해주었습니다.
Final Data Modeling
2일동안 저희 팀은 주어진 Bankchurner 데이터를 가장 합리적인 정보 손실을 감수하고 가명처리를 진행하였으며, 각 데이터의 상관관계와 변수 중요도를 측정하였으며, Label Encoding, Oversampling, Suppressed records 삭제 등을수행하였습니다. 위와 같은 전처리 과정을 겪은 데이터를 모델링 해봤습니다.
그 결과 98.9% 정확도를 가지며,

Precision = 2436 / 48+2436 으로 98.1%의 Precision값을 가지게 되었습니다. 이 결과가 의미하는 것은 새로운 Record가 들어왔을 경우 모델이 "이 고객은 곧 이탈한다"(라벨 1) 라고 예측했을 경우 이 예측이 맞을 확률이 98.1%라는 것이다. 상당히 괜찮은 수준으로 예측함을 알 수있다.
결과
우리가 '회고-1'에서 했던 가정을 생각해보면,
"우리는 카드사의 개발자이고, 회사 경영진들은 내부 데이터를 이용해 가명처리된 분석모델을 만들어서 미래의 이탈자들을 구분해내고 그 다음 이탈자로 분류된 고객들을 타겟으로 개인화된 새로운 마케팅 전략을 펼치고자 한다."
우리는 주어진 데이터들을 가명처리, Label Encoding, Oversampling, Suppressed record 삭제처리 해서 개인정보유출의 걱정 없이 분석하게끔 경영진에게 제공하였습니다.
이와 더불어 경영진의 입장에서 사용가능한 마케팅 전략 몇가지 역시 제시하였습니다.
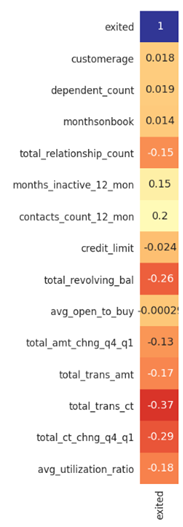
위 상관관계표에서 숫자의 절대값이 가장 높은 total_revolving_bal, total_trans_ct, total_ct_chng_q4_q1 을 이용하여 마케팅 전략을 수립해보았습니다.



위와 같은 아주 단순한 마케팅전략을 나름대로 세워서 발표해보았습니다.
15분간의 긴 발표를 듣고 난 후 심사위원으로 와주신 인하대학교 데이터 사이언스학과 교수님들의 질문에 간단히 답하였습니다. 또한 여러가지 아주 좋은 조언들 역시 받을 수 있었습니다.
모든 발표가 끝난 이후 20분간 평가시간을 가지고 난 후 상을 시상하였습니다.
그 결과

100점 만점에 97점으로 2등과 13점 차이로 1등을 차지하였습니다. 부상으로 30만원의 상품권을 받았습니다! 헣
개인적으로 정말 뜻 깊은 과정이었습니다. 학교에서 데이터분석과 관련해서 배우고 실습하였지만 이렇게 많은 속성을 가지는 값들을 비식별화 + 모델링하고, 결과적으로 창의적인 마케팅 전략까지 수립하는 과정까지 해봤다는 점에서 뿌듯하였습니다. 또한 데이터 분석의 한 생명주기를 처음부터 끝까지 돌아봤다는 느낌이 들었습니다. 분명 이것보다 훨씬 복잡한 과정으로 진행 되겠지만 저같은 초보자로써는 뿌듯했습니다. 강사(교수)님들도 정말 잘 가르쳐 주시고 도움을 아끼지 않아주셨습니다.
재밌게 잘 배우고 갑니다! 끝!

취업어케하죠