서비스 장애 원인 분석 및 성능 개선기
얼마전에 새로 배포한 서비스에서 서버가 죽었다는 알람을 받게 되었습니다.
이 서버는 사람들이 시승 응모를 하고, 추첨을 통해 일부 사용자들에게 시승 기회를 주는 서비스였는데요.
오후 3시쯤에 갑작스럽게 서버가 죽어서 원인을 분석하게 되었고, 이 과정에서 서버 배포 중 필수적으로 체크해야 하는 값과 조심해야 하는 것들이 무엇이 있을지 알게 되어 정리하고자 글을 쓰게 되었습니다.
1. 장애 발생
다른 일을 하고 있던 중 서버가 갑작스럽게 다운 되었다는 사실을 모니터링을 통해 알게 되었습니다.
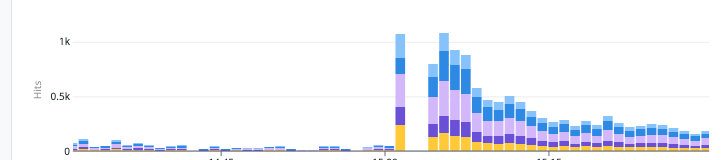

갑자기 많은 요청이 순식간에 들어온 것을 알게 되었고, 요청 spike를 통해 서버가 부하를 이기지 못해 다운되었다는 사실을 파악했습니다.
우선, 서비스를 관리하는 사업팀에게 사실 확인을 했고, 이전 시승 회차 당첨 결과를 발표하면서 순식간에 사람들이 서비스 진입을 하면서 요청이 들어왔다는 것을 파악했습니다.
우선, 갑작스럽게 요청이 몰려서 서버가 죽었지만, 이후에는 요청을 처리하면서 장애 상황이 길게 지속되지는 않았습니다.
2. 원인 분석
우선 Spike 시점 전 후 Trace 정보는 다음과 같았습니다
- 전반부 (14:53~15:00): 트래픽 거의 없음
- 15:01~15:02: 일시적 스파이크 발생
- 15:02~15:04: 서버 다운
- 15:04 이후: 안정적인 트래픽 유입, 평균 150~250 req 수준 유지
요청이 한순간 몰렸다고 해도, 절대적인 수치로 보았을 때 서버가 다운되는 것은 이상했습니다.
현재 저희 서비스에서는 Spring 3.4.3 버전을 쓰고 있었으며, virtual Thread를 사용하고 있었기 때문에, 충분히 받을만한 요청량이었다고 판단 했습니다.
추가로 위와 같이 판단했던 이유는, 대부분의 요청들이 복잡한 계산 로직을 필요로 하지 않고, DB 조회 및 Validation 에 대한 요청들이 전체 요청량의 90% 정도 였습니다.
Spring 3.4.3 버전을 쓰고 있었으며, virtual Thread를 사용하고 있음.
읽기 요청이 대부분인 단순한 API에서 100 RPS를 처리하지 못한 것은 이상함.
추가: 관련 Datadog 지표를 확인해보니 서버의 요청 Trace는 남아 있었지만, 실제 어디서 오래 걸렸는데 확인하기 위한 Profile 기능은 꺼져 있어, 정확한 원인 파악이 어려운 상태였습니다.
3. 가설 수립 및 검증
이번에 작업한 서버는 기존에 사용하고 있던 서버에서 추가 개발한 상태로 다음과 같이 서버가 구성되어 있었습니다
Client(User) -> Backend Server -> Internal API Server

우선 위 Trace에서 확인한 것처럼 실제 요청을 처리하기 전에
Backend Server - Internal API Server 에서 실제로 처리하지 못하고 대기한 시간이 길다는 것을 확인했습니다.

다만, 추가로 Internal 서버에서도 실제 비즈니스 로직을 처리하기 전에 잡아먹는 시간이 꽤 있었습니다.
위와 같은 지표들을 통해 요청이 몰렸을 때 서버가 실제로 처리하지 못하고, 대기한 것들이 많다는 것만 추측할 수 있었습니다.
그렇지만 위에서 설명 했듯이 virtual Thread 옵션이 켜져 있기 때문에, 요청이 들어왔을 때 실제 기능들이 수행하면서 I/O bound가 발생하는 시점에 스케쥴링이 되었을 것이라 생각했고, 그럼 병목 지점은 DB를 조회하는 부분이라 생각을 먼저 하게 되었고, Thread Pool 설정이 있는지 확인 했습니다.
이 때 확인해보니 기본 Hikari Pool Config 설정으로 되어 있었고, Thread는 10개로 설정되어 있었습니다.
물론, 2대의 서버가 떠있었고 요청량 대비 적게 설정된 값을 아니지만, 이 값을 올리면 우선 성능을 높일 수 있다는 기대감으로 DB 팀과 논의하여 30으로 설정하기로 했습니다.
DB Maximum Pool Size를 30으로 조정.
4. 문제 해결?
그럼 이제 문제가 해결되었을까요?
실제 운영 환경에 적용하기 전, 이 값이 실제로 효과가 있는지 로컬 및 개발 환경에서 테스트를 해보기로 했습니다.
이후, 서비스가 성숙해지면 초당 300~500 TPS 요청이 들어올 수 있다고 판단했고, 이를 고려하여 테스트 환경을 만들었습니다.
부하 테스트 환경
Locust 서비스 활용 / 초당 300 TPS 요청
Hikari Pool Config
- maximum pool size: 30
- minimum-idle: 9
위와 같이 셋팅을 하고 실제로 테스트를 진행했는데, 일부 요청량이 넘어가는 시점부터 응답이 똑같이 밀리기 시작했고, 대략 200 TPS를 넘어가는 시점부터 문제가 생긴다는 것을 파악했습니다.
위 설정이 제대로 동작하지 않는다는 것은 명확하지만, 어디에서 요청이 밀리기 시작했는지 정확한 파악이 필요했습니다.
DB Pool Config를 조정했지만 의미있는 효과가 보이지 않았고, 추가 확인이 필요.
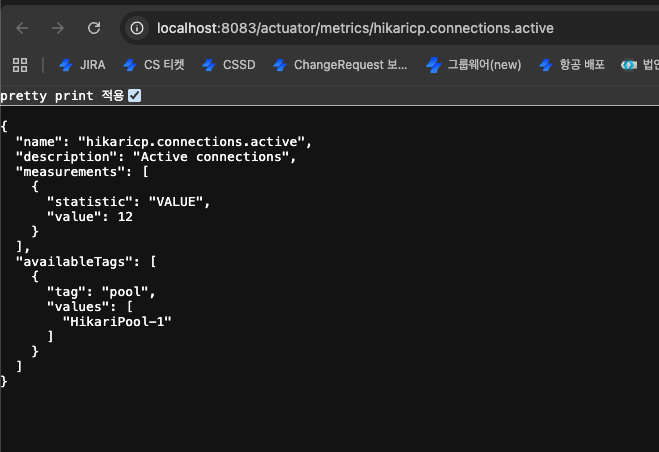
추가: Spring Actuator로 확인했을 때 DB Connection Active도 9~10정도만 처리되고 있었으며, 의도한 만큼 Connection을 활용하지 못한 부분도 확인
5. 실제 병목 지점 확인
그렇다면 실제 병목 지점이 어디인지 확인하기 위해 Metric을 확인했는데요.
뚜렷한 문제가 확인되지 않아, Thread Dump를 떠서 어디가 문제인지 확인을 했습니다.
그러자 문제가 확인되었는데요.
Internal Server에서는 Auth 인증 시 BCrypt 해싱을 통해 인증을 하고 있었습니다.
1. Internal Server 는 실행 시 Redis에 저장된 (User, Password) 정보를 Inmemory에 저장.
2. Backend Server 및 Admin 등 서버에서 요청 시 매번 Basic Authentiaction을 확인.
3. 이 과정에서 BCrypt 해싱을 통해 비밀번호 검증.단, BCrypt의 연산이 매우 비싸고(요청당 약 80~100ms 걸림), 순수 CPU 계산이기 때문에 Thread 스케쥴링이 되지 않고 병목이 되고 있었습니다.
즉, Internal Server에서 인증 처리 방법 수정이 필요했습니다.
이를 처리하기 위해서, 2가지 방법을 고민했습니다.
- 인증에 사용하는 Token을 Jwt 토큰으로 만들어서 Service Token으로 활용한다.
- 한번 처리된 (User, Password) 값은 메모리에서 관리하여, 동일한 요청이 온 경우 인증되었다고 판단한다.
물론 1의 방법이 가장 이상적이고, 최종적으로 가야 하는 목표라고 생각했습니다만, Internal 서버를 호출하는 모든 부분에서도 같이 대응해야 하고, 다른 프로젝트로 인해 이를 대응할 시간이 부족하다고 판단했습니다.
즉, 우선 2번으로 처리하는 것으로 하고, 추후 백로그 티켓에 1번과 같은 방식으로 개선하는 작업을 추가해두었습니다.
위 작업을 하고, 로컬 환경에서 테스트 한 결과는 다음과 같았습니다.
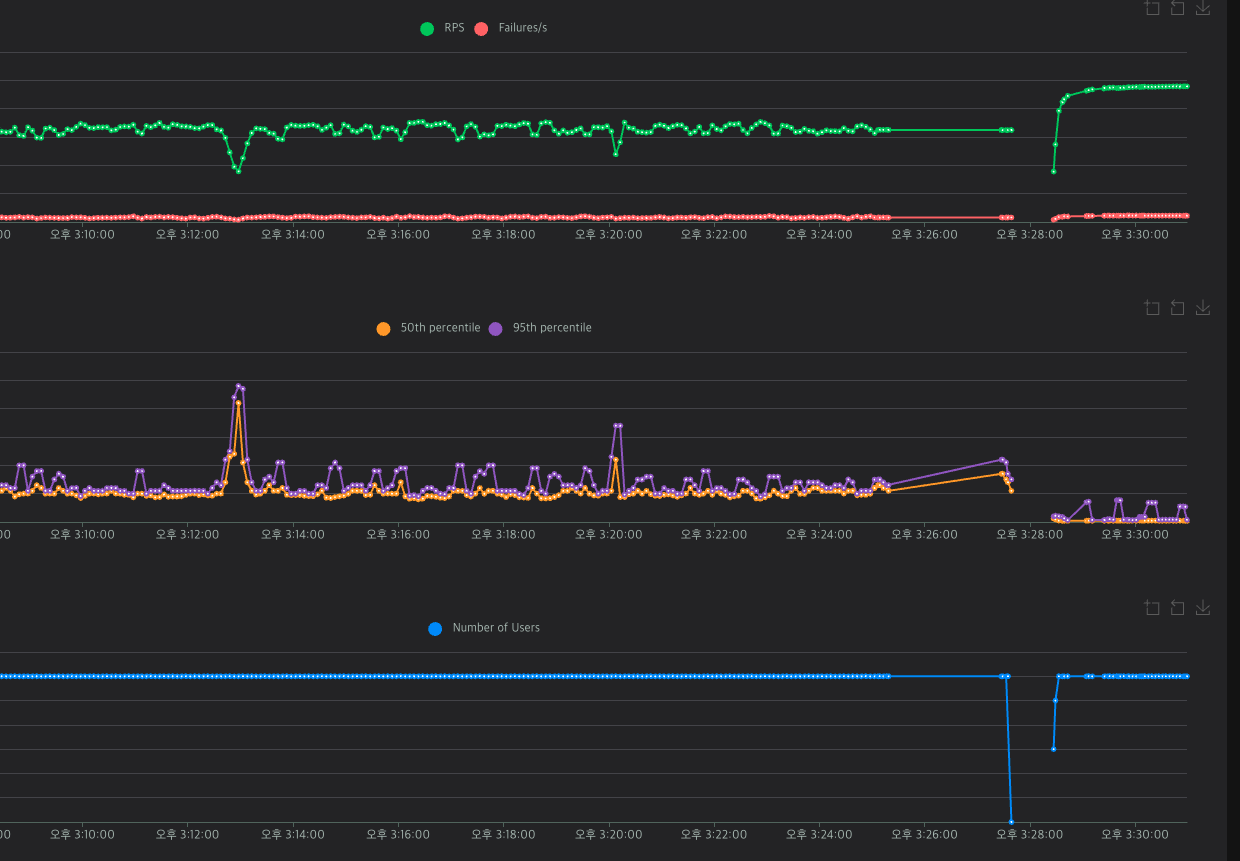
더 많은 요청이 들어옴에도 안정적이고 빠르게 응답하는 것을 볼 수 있었습니다.
6. 추가 디버그
인증 부분에서 작업한 이후 어느정도 성능 개선이 되었다고 판단했지만,
우리가 목표했던 DB Connection이 의도한 만큼 잘 연결되는지 확인이 필요했습니다.
Metrics 정보를 확인했지만, 요청이 계속 증가하는 상황에서도 DB의 Connection은 10~12로 유지되고 있었으며, 의도한 Max Connection Pool 크기만큼 증가하지 않는 것을 확인했습니다.
이 때, Virtual Thread를 한창 공부하면서 알게된 내용 중, synchronized 키워드가 있으면 Thread Pinning이 발생하여 원하는 성능이 나오지 않을 수 있다는 것이 떠올랐습니다.
이에, 현재 사용하고 있는 DB Driver 와 Virtual Thread의 지원 여부를 확인했고, 역시나 사용중인 org.mariadb.jdbc:mariadb-java-client:2.7.11 버전은 내부적으로 synchronized로 처리되는 부분이 있어서, virtual Thread를 제대로 지원하지 못한다는 것을 확인 했습니다.
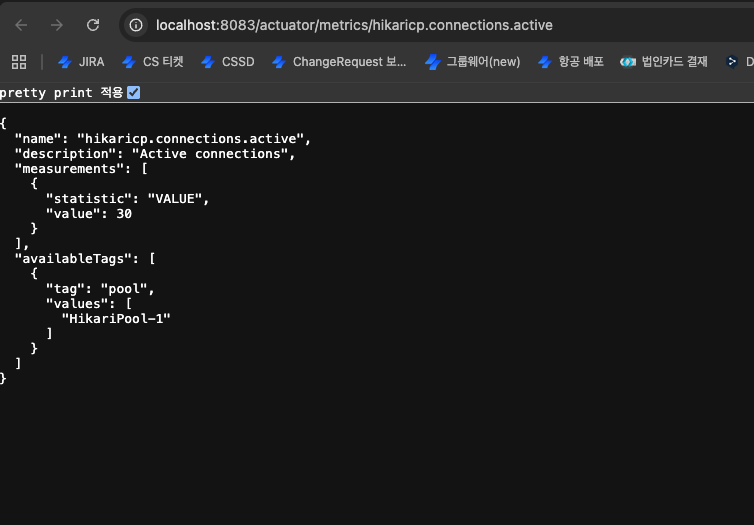
이를 확인하여, mariaDB jdbc driver의 버전을 업데이트하여 ReentrantLock을 사용하는 3.x 버전으로 업데이트 했으며, 이후 확인한 지표에서는 Connection Pool을 최대로 사용하면서, 더 좋은 성능을 내는 것까지 확인 했습니다.
6-1. DB Driver Version Update 전
6-2. DB Driver Version Update 후
6-3. 전/후 성능 비교
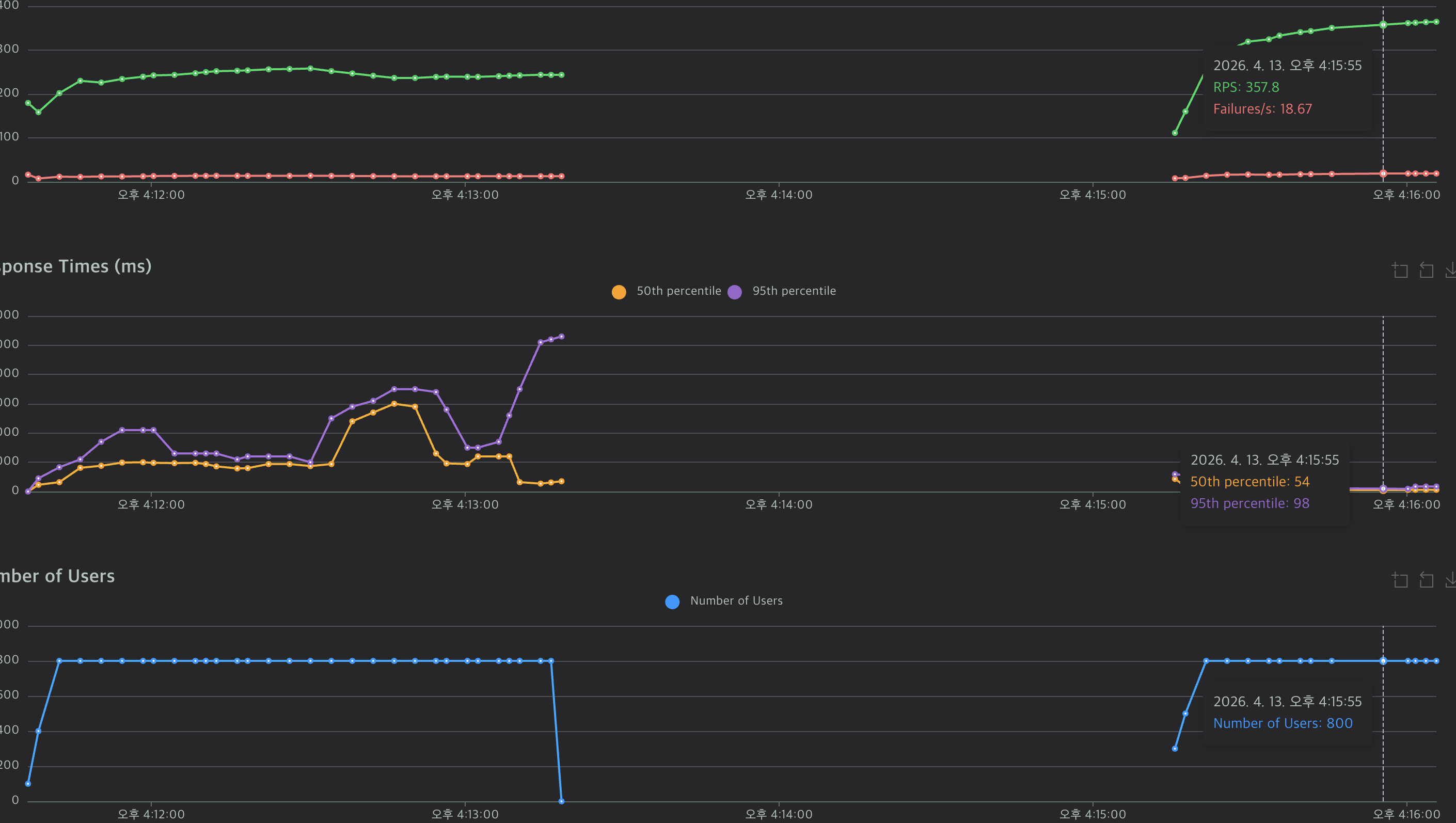
7. 배포 및 모니터링
Internal 서비스 개선 이후 실제 운영 환경에 배포하여, 평시 들어오던 요청들도 약 100ms -> 10ms 정도로 개선된 것을 확인할 수 있었습니다.
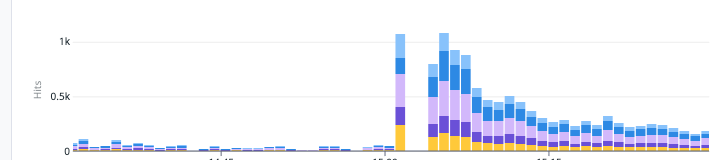
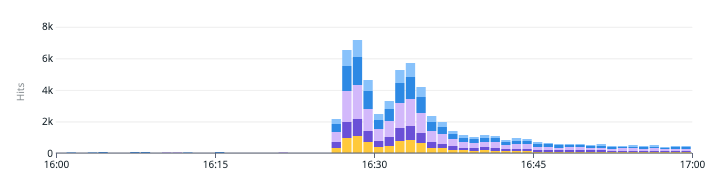
추가로, 다음 추첨 결과 발표 시점에 초기 장애가 발생헀던 요청량보다 약 6~7배 정도가 들어왔음에도 안정적으로 처리되었습니다.
7-1. 이전 지표

7-2. 이후 지표

팀 내 공유 및 세미나 진행
이후 성능 개선을 진행하면서 마주한 문제들은 팀 내 꾸준히 공유하였고, 팀장님께서 다른 분들도 같이 이러한 내용들을 알고 있으면 좋을 것 같다고 하여 따로 세미나도 진행 했습니다.
제가 성능 개선을 하면서 풀어간 내용들도 정리하고, 다른 분께 공유하기 위한 내용들을 정리하며, 추가로 이런 상황을 대비하기 위한 방법 및 추가로 개선할 부분이 있는지 같이 정리해보는 시간을 가졌습니다.
위 세미나를 진행하면서 같이 논의했을 때 나온 주제들은 다음과 같습니다.
- CPU 및 Thread를 잡아먹는 Batch 서비스의 분리
- HPA가 CPU 및 Memory 기반으로 처리되었을 때의 한계
- 새 기술 도입 시 연관 설정 검토
서비스 장애를 단순히 해결하는 것을 넘어 다음 스텝들도 같이 논의해보는 좋은 자리가 되었던 것 같아 즐거운 경험이 되었습니다
위와 같은 과정을 겪으면서 다양한 내용들을 알게 되었고, 실제 문제 해결하는 과정을 거쳐가면서 값진 경험을 했다고 생각합니다.
virtual Thread가 좋다고 알고 있었지만, 이를 무작정 사용한다고 모든 상황에서 만능은 아닌것이 이번 경험에서 몸소 느꼈으며, 관련하여 다른 설정들도 꼼꼼하게 검토하고 병목 지점을 디버그 하는 습관이 있어야 한다고 생각 했습니다.
궁금한 부분이 있다면 댓글로 작성 부탁드리겠습니다.
긴 글 읽어주셔서 감사합니다.
