머신러닝 파이프라인을 살펴보고 데이터를 어떻게 텐서 표현 정리
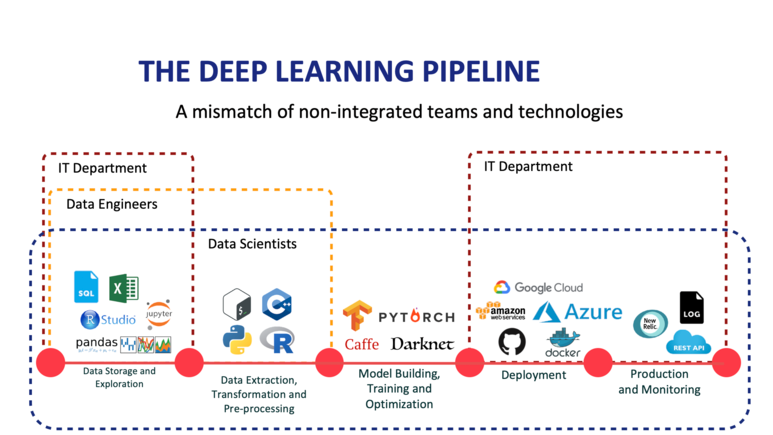
Deep learning pipeline
지금까지 배운 수 체계에는 스칼라, 벡터, 행렬, 텐서가 있었다.
그리고 많은 머신러닝 책에서는 아래와 같이 표기된다.
여러 모듈과 메소드를 통해 파이토치에서 어떻게 텐서를 조작하는지 알아보겠습니다

torch의 여러가지 텐서모듈을 통해 위의 데이터타입을 가지는 텐서를 생성할 수 있습니다
1. 스칼라
dtype과 device를 지정하지 않으면 자동으로 dtype을 식별하고 device는 cpu로 할당하게 됩니다.
scalar = tensor(3)
print(scalar)
print(scalar.dtype)
print(scalar.device).item()을 통하여 텐서 객체 내의 단일 스칼라 값을 뽑아낼 수 있습니다. item 메소드는 반드시 스칼라 텐서에서 호출
print(scalar.item())real = ftensor([3])
imag = ftensor([2])
c = torch.complex(real, img)
print(c)
print(c.real)
print(c.imag)2. 벡터
import numpy as npdata에 들어갈 수 있는 컨테이너는 List, Tuple, Numpy array입니다.
파이토치에서 텐서 객체를 만드는 방법은 기존의 numpy와 매우 유사합니다.
vec1 = ftensor([1.0, -1.1, 3.9]) # list data
vec2 = dtensor((1.0, -1.1, 3.9)) # Tuple data
vec3 = tensor(np.array([1, 2, 3, 4])) # numpy array
vec4 = tensor([1.0, -1.1, 3.9], dtype=int)
print(vec1)
print(vec1.dtype)
print(vec2)
print(vec3)
print(vec4)import numpy as np
vec1 = ftensor([1.0,-1.1,3.9])
vec2 = dtensor((1.0, -1.1, 3.9))
vec3 = tensor(np.array([1,2,3,4]))
print(vec2)
print(vec3)3. 행렬
이제 행렬 텐서를 만들어보겠습니다.
데이터타입을 행렬로 다루기 시작한다면 device를 gpu로 지정하는게 좋습니다.
이제 데이터를 일일히 생성하기 힘드므로 rand를 사용하겠습니다.
rand를 잘 활용하기 위해 시드를 고정하겠습니다.
th.manual_seed(1)
mat = th.rand([2, 2], device='cpu') # cuda
print(mat)
print(mat.device)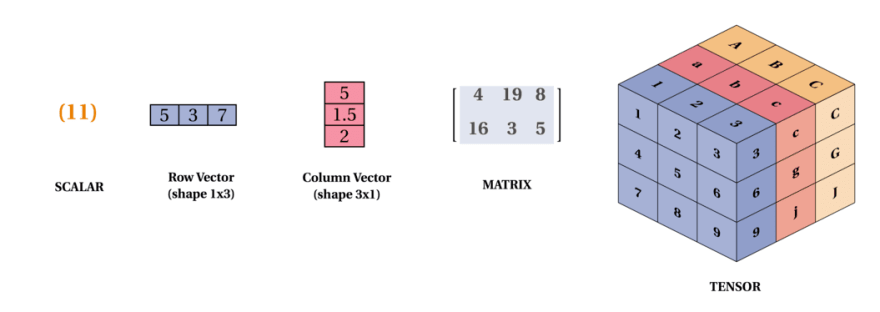
4. 텐서
이제 3차원 이상의 텐서를 만들어보겠습니다.
th.manual_seed(2)
T = th.rand([64, 64, 3], device='cpu')
#T = th.randint(255, (64, 64, 3))
T = T * 256
T = T.to(int)
print(T)
# 이미지 출력 해보기퀴즈 (Easy)
1) !nvidia-smi 를 통해 현재 gpu의 메모리 사용량을 확인하세요
2) 크기가 (100, 100, 100)인 3차원 랜덤 텐서를 gpu 메모리에 할당하세요
3) 다시 !nvidia-smi를 통해 gpu 메모리 사용량이 얼마나 늘었는지 계산해보세요
