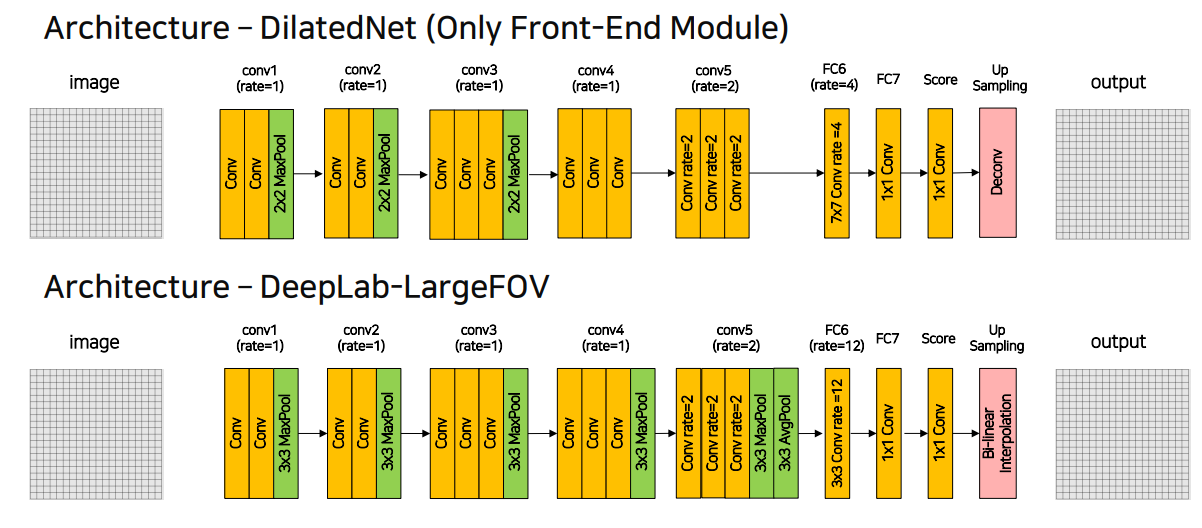
1. DeepLab v2
기존 Architecture
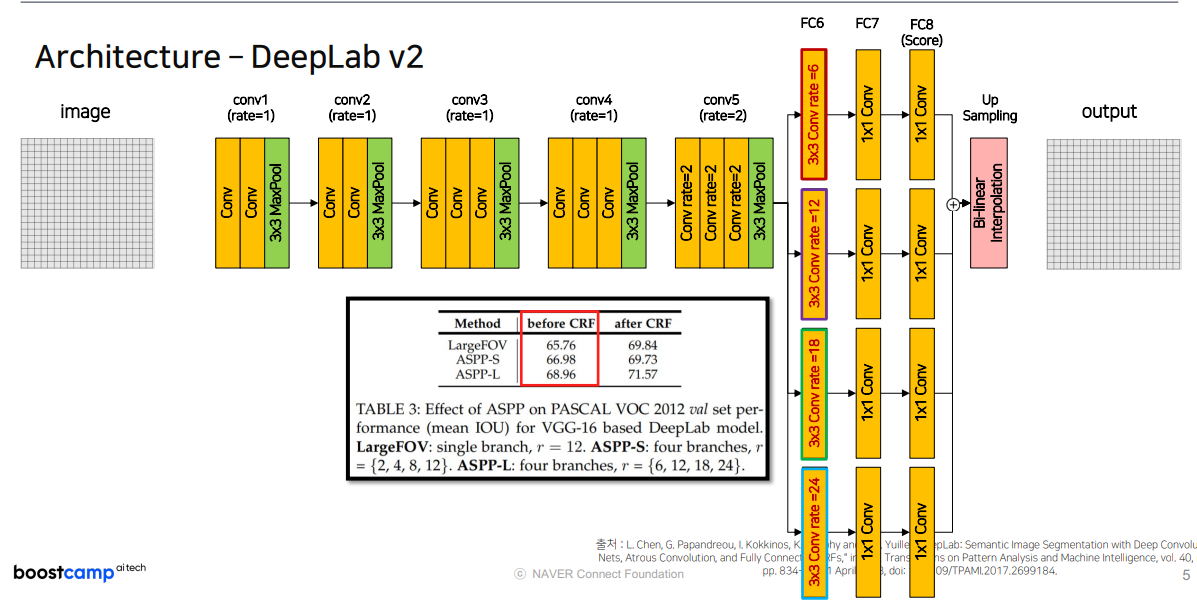
DeepLab v2
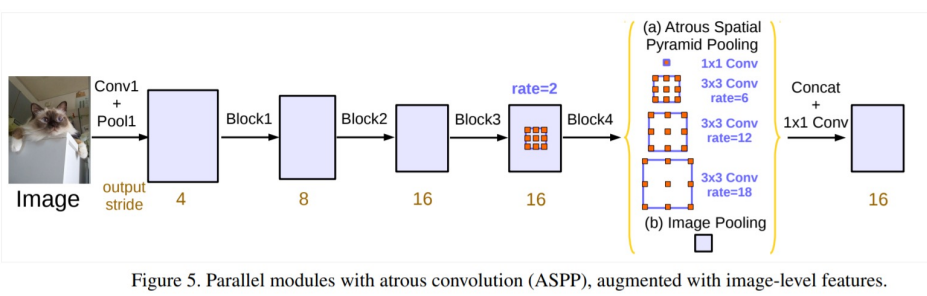
AvgPooling부분이 사라지고, 4가지dilated conv를 가지는 branch형태로 바뀜ASPP:Atrous Spatial Pyramid Poolingdilation rate가 작은 layer은 상대적으로 작은 object에 집중하고,dilation rate가 큰 layer 상대적을 큰 object에 집중함ResNet-101
backbone에ResNet-101을 사용- 단, 기존
ResNet대비conv4와conv5에서
1)down-sampling을 수행하지 않고
2)dilated conv를 사용했다
는 차이가 있음

2. PSPNet
2.1 도입배경
1) Mismatched Relationship
-호수주변의 boat를 car로 예측
-idea: 주변의 특징을 고려(ex. water 위의 boat)
2) Confusion Categories
-skyscraper와 building을 혼돈하여 예측
-idea: category간 관계를 사용하여 해결(global contextual information)
3) Inconspicuous Classes
-작은 객체인 pillow를 bad sheet으로 잘못예측
-idea: 작은 객체들도global contextual information사용2.2 도입배경2
FCN이 가지는 이론적인receptive field와 실제receptive field가 다르다.
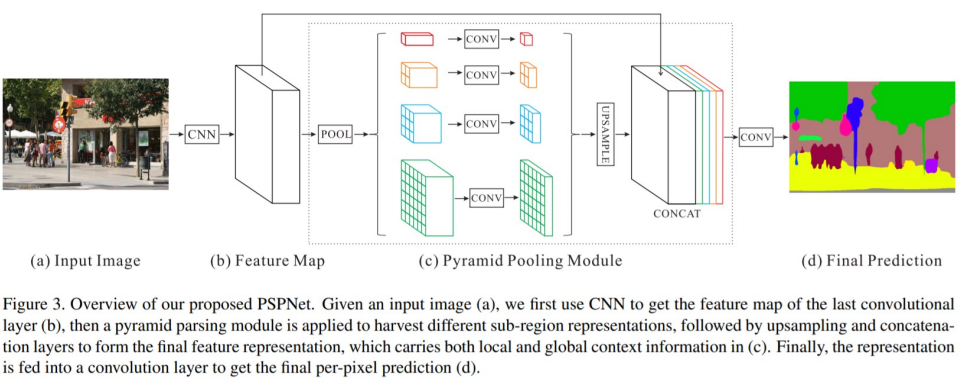
2.3 Architecture
Average Pooling을 적용해1x1,2x2,3x3,6x6의 사이즈의 map을 얻어냄- 그 후,
1x1 conv->upsample->concat(skip-connection)->conv의 과정을 통해segmentation map을 얻어냄.
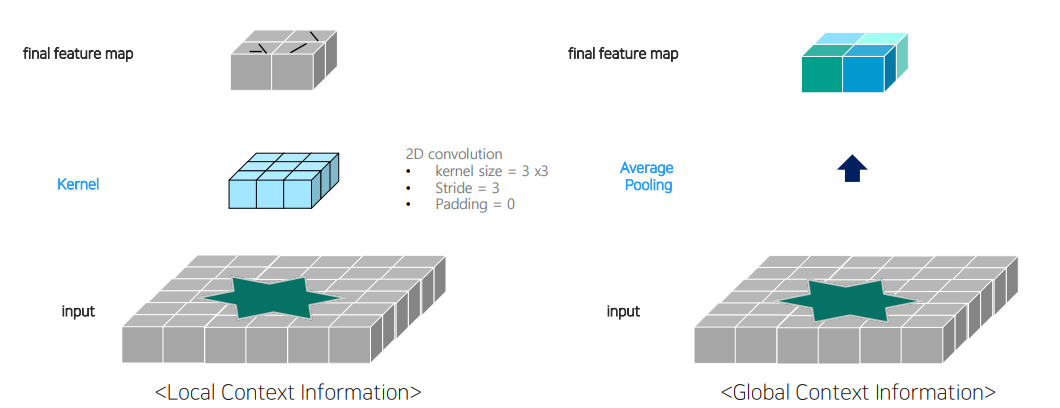
conv에 비해pooling을 사용할경우local contect information이 아닌Global context information을 얻을 수 있다고 함.2.4 performance
- 기존
DeepLab에 비해 오분류를 줄이고 좀 더 깔끔한 segmentation이 가능해짐



3. DeepLab v3
- 기존
ASPP(Astrous Spatial Pyramid Pooling)에dilation rate=24를 빼고Pooling을 추가- 이전 버전 모델들과 다르게
sum이 아닌concat을 통해 여러feature map을 합침
4. DeepLab v3+
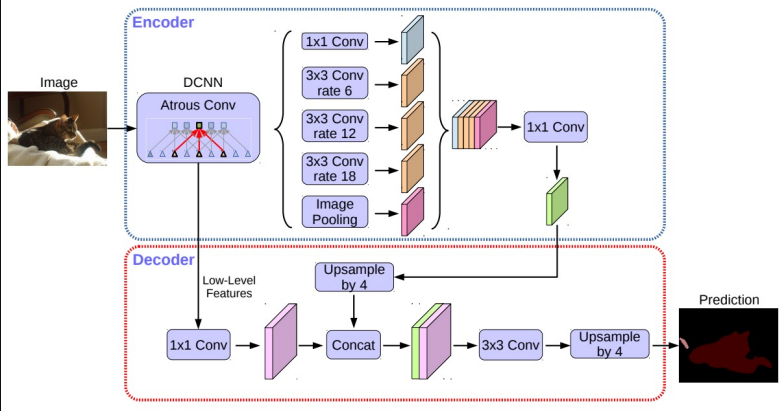
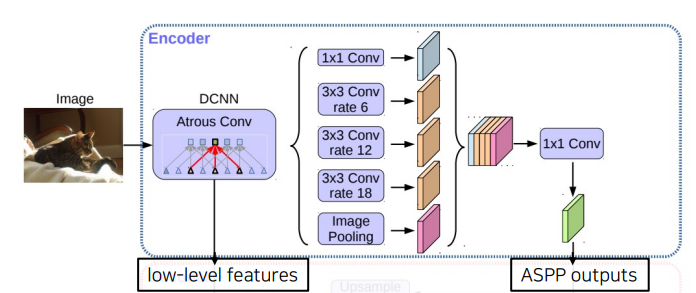
Encoder - Decoder구조Encoder에서spatial dimension의 축소로 인해 손실된 정보를Decoder에서 점진적으로 복원Encoder와Decoder사이에skip-connection추가4.1 Encoder
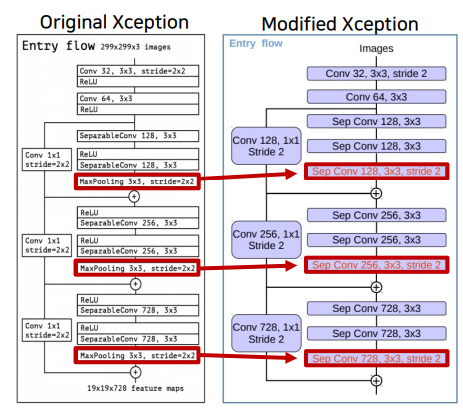
- 수정된
Xception을backbone으로 사용atrous separable conv를 사용한ASPP모듈 사용low-level feature와ASPP모듈 출력을decoder에 전달
4.3 modified Xception Backbone
classification task에서는 5번의 연산을 거쳐1/32배 사이즈의map을 사용- 반면,
segmentation task에서는 4번의 연산을 거쳐1/16배 사이즈의map을 사용4.3.1
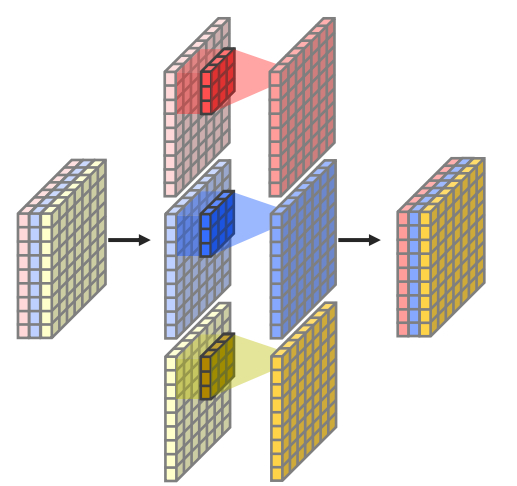
Depth Separable Convolution을 사용하는 구조1)
Depthwise conv
- 채널별 파라미터를 통해 연산한 후 concat을 통해 합쳐줌
nn.Conv2d내의group(=채널을 몇개의 그룹으로 나눌건 지)파라미터를 사용해 적용할 수 있음nn.Conv2d(in_channels=128, out_channels, kernel_size, stride, group=128)2)
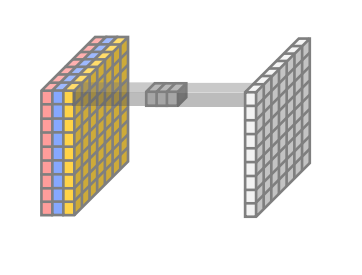
Pointwise conv
1x1 conv와 동일1x1 kernel을 사용해 는 그대로 두고 채널크기만 변경함.
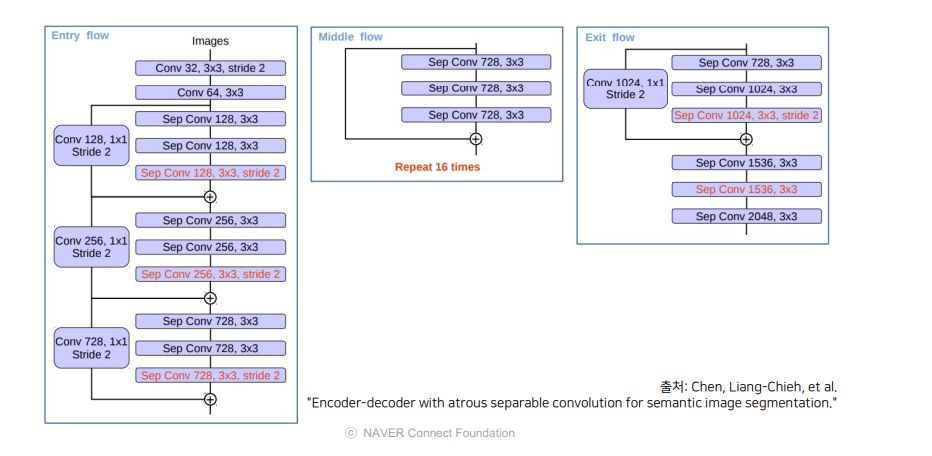
4.3.2 모델 구조
- 크게
Entry flow,Middle flow,Exit flow로 나눌 수 있음Entry Flow
Maxpooling연산을Depthwise Separable conv(stride=2) + BatchNorm + ReLU로 변경첫번째 block의 출력(low-level feature)을decoder에 전달함
Middel Flow
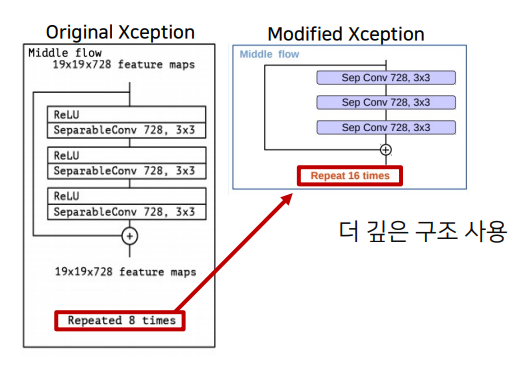
block repeat횟수를 8에서 16으로 증가시키면서 더 깊은 구조를 사용
Exit Flow
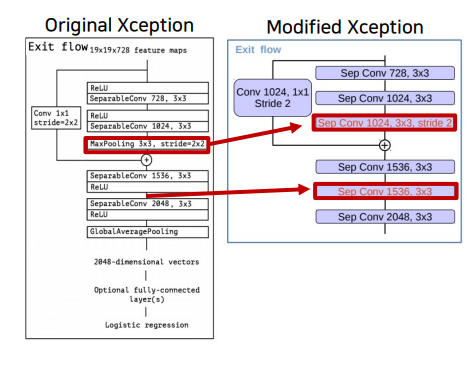
Maxpooling연산을Depthwise Separable conv(stride=2) + BatchNorm + ReLU로 변경- 구조 변경
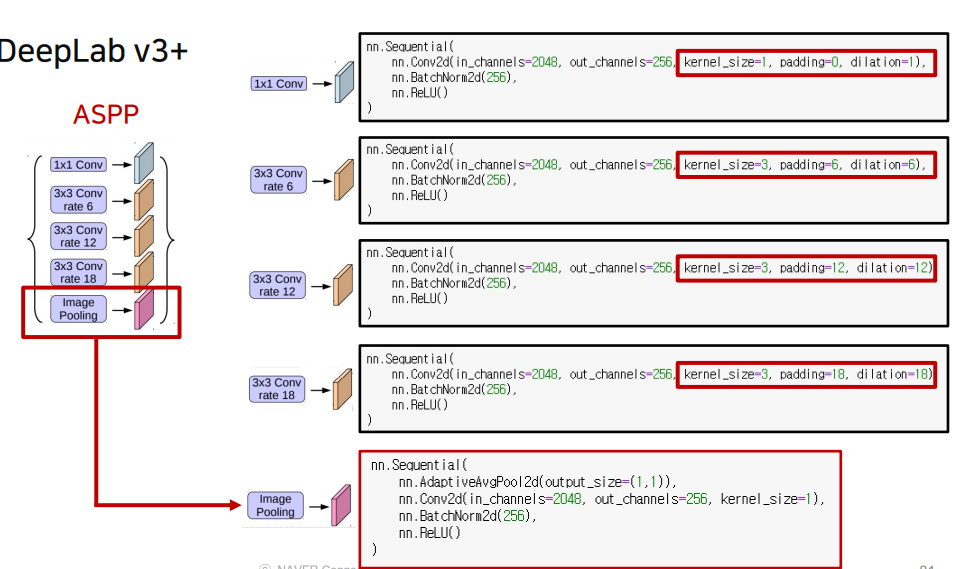
4.4 ASPP(Astrous Spatial Pyramid Pooling)
- 다양한
dilation rate를 통해 다른receptive field를 가지지만 똑같은 사이즈를 가지는 여러개의feature map을 얻어냄GlobalAveragePooling을 사용해 의 출력크기를 가지는feature map을 얻고1x1 conv와bilinear interpolation을 통해 다른feature map들과 동일한 사이즈로 맞춰줌
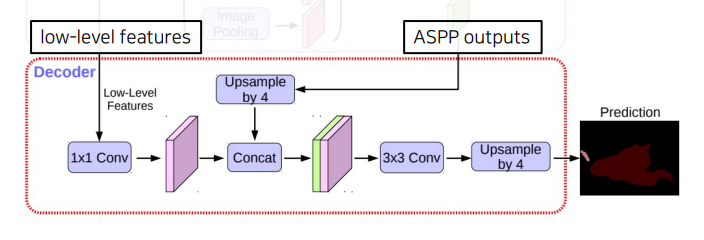
4.2 Decoder
ASPP모듈의 출력을up-sampling하여low-level feature와 결합- 기존의 단순한
up-sampling연산을 개선시켜 detail이 유지되도록 함low-level features와ASPP output을concat한 결과에bilinear interpolation을 적용해 최종prediction도출
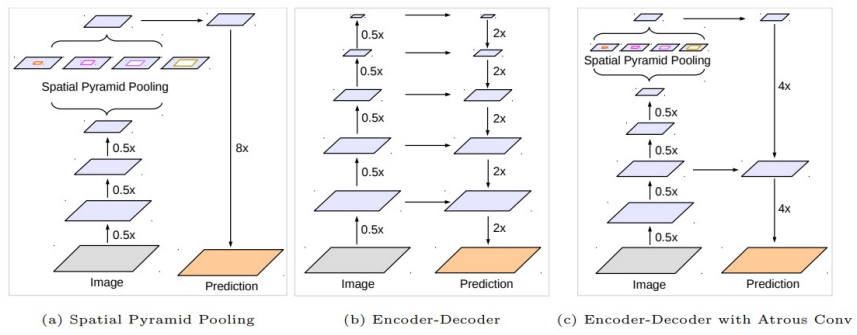
결론
FCN-DeepLab v1-Dilated Conv-DeepLab v2-PSPNet-DeepLab v3-DeepLab v3+

인공지능 꿈나무